






这里请大家提前安装好python,不过多赘述。
本文章仅仅用作教学,自用,滥用导致的问题与本文章无关。
安装好python,以及编译器后,还需要下载几个包。
安装并且配置完环境变量后。
按住win+r键,打开任务资源管理器,
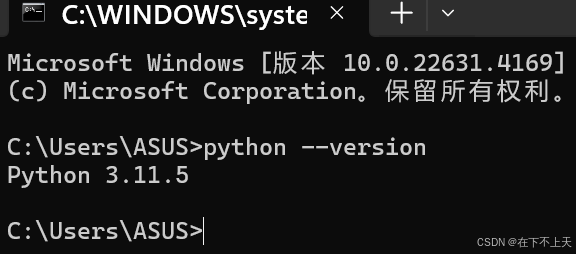
首先输入
python --version如果出现了版本就继续操作。
如果出现了其他的东西,就去找个别的文章,看一下自己的环境变量有没有配置好。
如果正确就可以进行下一步操作。
开始下载beautifulsoup4包
pip install beautifulsoup4之后安装request包
pip install rquests目前就这些,如果有别的大家就按照
pip install+包名就可以进行下载。
接下来直接上代码。
本代码爬取了目标网站,玄幻小说分类的,最好看榜单的前6本小说的第1章。
如果需要修改,大家可以自行进行修改。
from bs4 import BeautifulSoup
import requests
import os
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0',
'cookie': 'Hm_lvt_c4acdf7e2467840afa38b206918ed3f2=1726792181; HMACCOUNT=883136EADA0B6136; Hm_lpvt_c4acdf7e2467840afa38b206918ed3f2=1726792222'
}
html = requests.get(url=url, headers=headers).content.decode('gbk')
soup = BeautifulSoup(html, 'html.parser')
temp = soup.select('div>dl>dt>a')
NameList = []
UrlList = []
for item in temp:
NameList.append(item.get_text())
UrlList.append("http://www.ibiqu.net/" + item.get('href'))
for i in range(len(UrlList)):
ChildUrl = UrlList[i]
ChildHtml = requests.get(url=ChildUrl, headers=headers).content.decode('gbk')
soup = BeautifulSoup(ChildHtml, 'html.parser')
temp = soup.select('div>div>dl>dd>a')
ChildNameList_ = []
ChildUrlList_ = []
start = "第一章"
index = next((i for i, s in enumerate(temp) if s.get_text().startswith(start)), -1)
if index != -1:
ChildNameList = [temp[index].get_text()]
ChildUrlList = ["http://www.ibiqu.net/" + temp[index].get('href')]
GChildUrl = ChildUrlList[0]
GChildHtml = requests.get(url=GChildUrl, headers=headers).content.decode('gbk')
soup = BeautifulSoup(GChildHtml, 'html.parser')
temp = soup.select('div>p')
content = [p.get_text() for p in temp]
GChildContent = "\n".join(content)
# 保存到当前目录
name = NameList[i] + "_第一章.txt"
with open(name, 'w', encoding='utf-8-sig') as f:
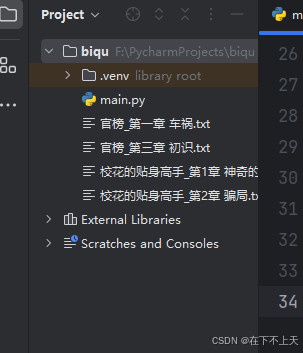
f.write(GChildContent)结果展示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









