







ZeroMQ的研究与学习
- 简介
- 工作模式
- 层级模型
- 实现原理
- 核心特点
- 与其他MQ的简单比较

ZeroMQ的一百字概括
ZeroMQ看起来想一个可嵌入的网络库,但其作用就像是一个并发框架。它为你提供了各种传输工具,如进程内,进程间,TCP和组播中进行原子消息传递的套接字。你可以使用各种模式实现N对N的套接字连接,这些模式包括发布订阅,请求应答,扇出模式,管道模式。它的速度足够快,因此可以充当集群产品的结构,他的异步IO模型提供了可扩展的多核应用程序,用异步消息来处理任务。它虽然是以C为源码进行开发,但是可以绑定多种语言。
1. 简介
ZeroMQ号称是“史上最快的消息队列”,基于c语言开发的,实时流处理sorm的task之间的通信就是用的zeroMQ。
引用官方说法,“ZMQ(以下ZeroMQ简称ZMQ)是一个简单好用的传输层,像框架一样的一个socket library,他使得Socket编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ的明确目标是“成为标准网络协议栈的一部分,之后进入Linux内核”。现在还未看到它们的成功。但是,它无疑是极具前景的、并且是人们更加需要的“传统”BSD套接字之上的一 层封装。ZMQ让编写高性能网络应用程序极为简单和有趣。” 确实,它跟RabbitMQ,ActiveMQ之类有着相当本质的区别,ZeroMQ根本就不是一个消息队列服务器,更像是一组底层网络通讯库,对原有的Socket API加上一层封装,是我们操作更简便。使用时只需要引入相应的jar包即可。
2. 工作模式
ZeroMQ与其他MQ类似,也实现了3中最基本的工作模式:发布-订阅,请求-应答,管道
1.发布-订阅

“发布-订阅”模式下,“发布者”绑定一个指定的地址,例如“192.168.10.1:5500”,“订阅者”连接到该地址。该模式下消息流是单向的,只允许从“发布者”流向“订阅者”。且“发布者”只管发消息,不理会是否存在“订阅者”。上图只是“发布-订阅”的最基本的模型,一个“发布者”可以拥有多个订阅者,同样的,一个“订阅者”也可订阅多个发布者。下面给出“发布-订阅”模型的样例程序:
发布者:
import org.zeromq.ZMQ;
public class Publisher {
public static void main(String args[]) {
ZMQ.Context context = ZMQ.context(1); //创创建包含一个I/O线程的context
ZMQ.Socket publisher = context.socket(ZMQ.PUB); //创建一个publisher类型的socket,他可以向所有订阅的subscriber广播数据
publisher.bind("tcp://*:5555"); //将当前publisher绑定到5555端口上,可以接受subscriber的订阅
while (!Thread.currentThread ().isInterrupted ()) {
String message = "fjs hello"; //最开始可以理解为pub的channel,subscribe需要订阅fjs这个channel才能接收到消息
publisher.send(message.getBytes());
}
publisher.close();
context.term();
}
} 订阅者
import org.zeromq.ZMQ;
public class Subscriber {
public static void main(String args[]) {
for (int j = 0; j < 100; j++) {
new Thread(new Runnable(){
public void run() {
// TODO Auto-generated method stub
ZMQ.Context context = ZMQ.context(1); //创建1个I/O线程的上下文
ZMQ.Socket subscriber = context.socket(ZMQ.SUB); //创建一个sub类型,也就是subscriber类型的socket
subscriber.connect("tcp://127.0.0.1:5555"); //与在5555端口监听的publisher建立连接
subscriber.subscribe("fjs".getBytes()); //订阅fjs这个channel
for (int i = 0; i < 100; i++) {
byte[] message = subscriber.recv(); //接收publisher发送过来的消息
System.out.println("receive : " + new String(message));
}
subscriber.close();
context.term();
}
}).start();
}
}
} 虽然我们知道“发布者”在发送消息时是不关心“订阅者”的存在于否,所以先启动“发布者”,再启动“订阅者”是很容易导致部分消息丢失的。那么可能会提出一个说法“我先启动‘订阅者’,再启动‘发布者’,就能解决这个问题了?” 对于ZeroMQ而言,这种做法也并不能保证100%的可靠性。在ZeroMQ领域中有一个叫做“慢木匠”的术语,就是说即使我是先启动了“订阅者”,再启动“发布者”,“订阅者”总是会丢失第一批数据。因为在“订阅者”与端点建立TCP连接时,会包含几毫秒的握手时间,虽然时间短,但是是存在的。再加上ZeroMQ后台IO是以一部方式执行的,所以若不在双方之间施加同步策略,消息丢失是不可避免的。
关于“发布-订阅”模式在ZeroMQ中的一些其他特点:
1.公平排队,一个“订阅者”连接到多个发布者时,会均衡的从每个“发布者”读取消息,不会出现一个“发布者”淹没其他“发布者”的情况。
2.ZMQ3.0以上的版本,过滤规则发生在“发布方”. ZMQ3.0以下的版本,过滤规则发生在“订阅方”。其实也就是处理消息的位置。
2.请求-应答

说到“请求-应答”模式,不得不说的就是它的消息流动模型以及数据包装模型。
消息流动模型指的是该模式下,必须严格遵守“一问一答”的方式。
在源代码中Req存在两个重要的标志位:
private boolean receiving_reply; //标志位,如果是ture的话,表示request已经发送了,正在等待reponse
private boolean message_begins; //如果是true的话,那么表示这里还需要发送第一个标志的空msg 发出消息后,若没有收到回复,再发出第二条消息时就会抛出异常。同样的,对于Rep也是,在没有接收到消息前,不允许发出消息。基于此构成“一问一答”的响应模式。
对于消息发送时的具体数据格式,引入两个图作为参照:
含有识别码:

不含识别码:

这种数据结构ZeroMQ称之为“封包”。一个封包由0个或多个“帧”组成。对于“请求-应答”模式,一个元封包一般由2-3个帧组成,可以看出,差别就是第一帧的存在与否。
对于含有目标地址的封包,第一帧存放消息接收端的身份识别码,该码在ZeroMQ内部维护的一个Map中作为key,Value是对应的地址。第二帧是一个分隔帧,没有任何意义,仅仅起分隔作用。第三帧是发送的数据。对于这类封包,通常第一帧,也就是识别码需要我们手动指定。
相比于前者,不含识别码的封包内的帧的含义还是一样,只是它的识别码直接有ZeroMQ默认生成,无需手动指定。
发送时,根据识别码在内存Map中对应的地址,将消息投递过去。
示例程序:
服务端
import org.zeromq.ZMQ;
public class Response {
public static void main (String[] args) {
ZMQ.Context context = ZMQ.context(1); //这个表示创建用于一个I/O线程的context
ZMQ.Socket socket = context.socket(ZMQ.REP); //创建一个response类型的socket,他可以接收request发送过来的请求,其实可以将其简单的理解为服务端
socket.bind ("tcp://*:5555"); //绑定端口
int i = 0;
int number = 0;
while (!Thread.currentThread().isInterrupted()) {
i++;
if (i == 10000) {
i = 0;
System.out.println(++number);
}
byte[] request = socket.recv(); //获取request发送过来的数据
//System.out.println("receive : " + new String(request));
String response = "world";
socket.send(response.getBytes()); //向request端发送数据 ,必须要要request端返回数据,没有返回就又recv,将会出错,这里可以理解为强制要求走完整个request/response流程
}
socket.close(); //先关闭socket
context.term(); //关闭当前的上下文
}
} 客户端
import org.zeromq.ZMQ;
public class Request {
public static void main(String args[]) {
for (int j = 0; j < 5; j++) {
new Thread(new Runnable(){
public void run() {
// TODO Auto-generated method stub
ZMQ.Context context = ZMQ.context(1); //创建一个I/O线程的上下文
ZMQ.Socket socket = context.socket(ZMQ.REQ); //创建一个request类型的socket,这里可以将其简单的理解为客户端,用于向response端发送数据
socket.connect("tcp://127.0.0.1:5555"); //与response端建立连接
long now = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
String request = "hello";
socket.send(request.getBytes()); //向reponse端发送数据
byte[] response = socket.recv(); //接收response发送回来的数据 正在request/response模型中,send之后必须要recv之后才能继续send,这可能是为了保证整个request/response的流程走完
// System.out.println("receive : " + new String(response));
}
long after = System.currentTimeMillis();
System.out.println((after - now) / 1000);
}
}).start();;
}
}
} “请求-应答”模式中Req套接字是同步的,每次只跟一个节点交流,如果Req套接字连接了多个节点,请求会同时分发到每一个节点。
相应的Rep套接字也是同步的,每次只跟一个节点交流,如果连接了多个节点,则以公平的方式以此从每个节点读取请求,但是最先响应的是最后读取的请求。
在接下来的内部结构分析时,将以“请求-应答”模式为例。
3.管道模式

在说明“管道模式”前,需要明确的是在ZeroMQ中并没有绝对的服务端与客户端之分,所有的数据接收与发送都是以连接为单位的,只区分ZeroMQ定义的类型。就像套接字绑定地址时,可以使用“bind”,也可以使用“connect”,只是通常我们将理解中的服务端“bind”到一个地址,而理解中的客户端“connec”到该地址。
“管道模式”一般用于任务分发与结果收集,由一个任务发生器来产生任务,“公平”的派发到其管辖下的所有worker,完成后再由结果收集器来回收任务的执行结果。
任务发生器
import org.zeromq.ZMQ;
public class Push {
public static void main(String args[]) {
ZMQ.Context context = ZMQ.context(1);
ZMQ.Socket push = context.socket(ZMQ.PUSH);
push.bind("ipc://fjs");
for (int i = 0; i < 10000000; i++) {
push.send("hello".getBytes());
}
push.close();
context.term();
}
} Worker
import java.util.concurrent.atomic.AtomicInteger;
import org.zeromq.ZMQ;
public class Pull {
public static void main(String args[]) {
final AtomicInteger number = new AtomicInteger(0);
for (int i = 0; i < 5; i++) {
new Thread(new Runnable(){
private int here = 0;
public void run() {
// TODO Auto-generated method stub
ZMQ.Context context = ZMQ.context(1);
ZMQ.Socket pull = context.socket(ZMQ.PULL);
pull.connect("ipc://fjs");
//pull.connect("ipc://fjs");
while (true) {
String message = new String(pull.recv());
int now = number.incrementAndGet();
here++;
if (now % 1000000 == 0) {
System.out.println(now + " here is : " + here);
}
}
}
}).start();
}
}
} 结果收集器
import org.zeromq.ZMQ;
public class Pull {
public static void main(String args[]) {
ZMQ.Context context = ZMQ.context(1);
ZMQ.Socket pull = context.socket(ZMQ.PULL);
pull.bind("ipc://fjs");
int number = 0;
while (true) {
String message = new String(pull.recv());
number++;
if (number % 1000000 == 0) {
System.out.println(number);
}
}
}
}整体流程比较好理解,Worker连接到任务发生器上,等待任务的产生,完成后将结果发送至结果收集器。如果要以客户端服务端的概念来区分,这里的任务发生器与结果收集器是服务端,而worker是客户端。
前面说到了这里任务的派发是“公平的”,因为内部采用了LRU的算法来找到最近最久未工作的闲置worker。但是公平在这里是相对的,当任务发生器启动后,第一个连接到它的worker会在一瞬间承受整个任务发生器产生的tasks。
3. 层级模型与交互逻辑
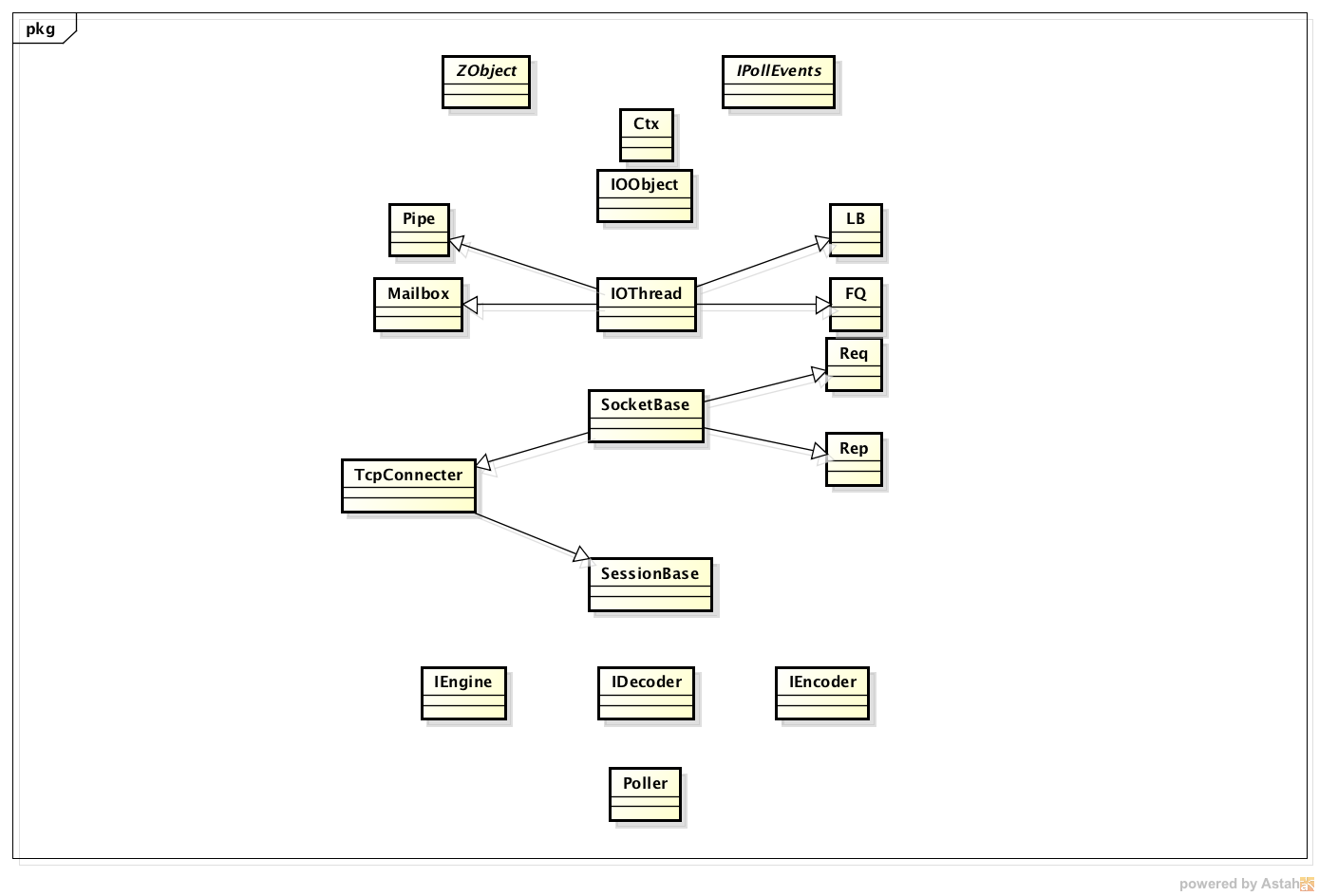
这是ZeroMQ的主要的层级模型,以“请求-应答”为例。
由上而下,最顶层的是ZObject与IPollEvent。
ZObject是所有ZeroMQ体系中类的父类,它存在的意义是发送与接收命令(有别于消息,命令是告诉ZeroMQ该做什么,需要做什么)。
IPollEvent则是一个接口,定义了若干操作,包括读操作,写操作,客户端请求连接,服务端应答连接,超时操作等供5个操作,该操作的实现类包括Req,Rep等具体Socket。该接口的目的是定义终端间发生操作时的行为。
Ctx是一个上下文类,通常一个终端只需要创建一个上下文。
IOObject本身并没有太多的属性,主要是其内维护了一个IOThread。
IOThread是用于处理命令的一个类,内部持有一个MailBox实例与Poller实例。
MailBox是一个重要的类,它被用作处理命令,包括命令的发送与接收,需要注意的是,这里的命令其实是本地发送,也就是自己跟自己发,而不是端点间发送。
Pipe用于处理接收到或者需要发送的数据,是实际存储待处理数据的数据结构,其内部是用队列的形式实现。
LB、FQ这两者在官方给出的全名是“LoadBalance”,“FairQueue”。也就是负载均衡与公平排队,分别用于处理要发送的数据与要接收的数据。
SocketBase是例如Req,Rep,Pull等包装后Socket的父类。其内含有一对Pipe(与SessionBase公用),用于在SocketBase与SessionBase之间传递消息,具体传递过程在接下去或说明。
SessionBase是创建SocketChannel并与目标终端进行连接的地方,是与底层Poller最先进行交互的一层。具有超时重连,断线重连等功能。
Poller是整个ZeroMQ的核心,它实现了命令的发送与接收,数据的发送与接收。由他来真正的发送数据到其他终端,也是他处理来自其他终端的数据后交给SessionBase。
基于此层级模型的交互逻辑:
发送消息
Socket -> Session -> StreamEngine -> Poller
接收消息
Poller -> StreamEngine -> Session -> Socket
4. 实现原理
这部分将说明从创建一个Socket开始到发送或者接收数据的整个过程,ZeroMQ内部的处理流程。
不过我个人觉得先了解一些在底层的原理,对于整体的实现理解会有更好的帮助。
先看一下Poller的一些重要定义
private static class PollSet {
protected IPollEvents handler; //事件的回调
protected SelectionKey key; //注册之后的key
protected int ops; //注册的事件
protected boolean cancelled; //是否已经取消
protected PollSet(IPollEvents handler) {
this.handler = handler;
key = null;
cancelled = false;
ops = 0;
}
}
final private Map<SelectableChannel, PollSet> fd_table; //记录所有的注册,key是channel
private boolean retired; //当前注册的对象是否有更新,如果有更新的话,在执行select之前需要先更新注册
volatile private boolean stopping; //如果是true的话,那么执行线程将会停止
volatile private boolean stopped; //是否已经停止
private Thread worker; //worker线程
private Selector selector; //selector
final private String name; //名字 PollerSet是Poller的一个嵌套类,所有需要注册到selector上的channel都会先构建这个对象,将其当做附件注册到selector上。其中handler是事件回调(一般是一个IOObject实例),key是selector注册后取得的key,ops是注册的事件类型
fd_table用于维护注册的channel对象与其的PollSet对象之间的映射关系。
retired用于标识当前的注册的channel什么的是否有更新,若是需要更新,则可能会重新生成key。
接下来来看看如何在poller对象上面注册channel吧,有几个比较重要的方法:
//用于在当前的集合里面添加需要注册的channel,第一个参数是channel,第二个参数是事件回调
public final void add_fd (SelectableChannel fd_, IPollEvents events_) {
fd_table.put(fd_, new PollSet(events_)); //直接把放到map里面就好了
adjust_load (1); //增加load值,这里所谓的负载其实就是在当前poller里面注册的channel的数量
}
//在key上面注册事件,如果negate为true的话,那么表示是取消事件
private final void register (SelectableChannel handle_, int ops, boolean negate) {
PollSet pollset = fd_table.get(handle_); //获取pollset对象
if (negate) {
pollset.ops = pollset.ops &~ ops; //取反,相当于取消事件
} else {
pollset.ops = pollset.ops | ops; //注册事件
}
if (pollset.key != null) { //如果有key了,那么表示已经注册到selector上面了,那么只需要更新key就好了
pollset.key.interestOps(pollset.ops);
} else {
retired = true;
}
} 可见在Poller里注册一个事件主要分为两步 1.放入map中 2.设置PollerSet的相应属性
Poller本身作为一个线程,来看看它的run方法
public void run () {
int returnsImmediately = 0;
while (!stopping) {
long timeout = execute_timers (); //执行所有的超时,并且获取下一个超时的时间
if (retired) { //这里表示注册的东西有更新
Iterator <Map.Entry <SelectableChannel,PollSet>> it = fd_table.entrySet ().iterator ();
while (it.hasNext ()) { //遍历所有需要注册的
Map.Entry <SelectableChannel,PollSet> entry = it.next ();
SelectableChannel ch = entry.getKey (); //获取channel
PollSet pollset = entry.getValue (); //获取pollset
if (pollset.key == null) { //这里没有key的话,表示当前channel并没有注册到selector上面去
try {
pollset.key = ch.register(selector, pollset.ops, pollset.handler); //注册
} catch (ClosedChannelException e) {
}
}
if (pollset.cancelled || !ch.isOpen()) { //如果是取消注册,那么直接取消掉就可以了
if(pollset.key != null) {
pollset.key.cancel();
}
it.remove ();
}
}
retired = false;
}
// Wait for events.
int rc;
long start = System.currentTimeMillis (); //select之前的时间
try {
rc = selector.select (timeout);
} catch (IOException e) {
throw new ZError.IOException (e);
}
if (rc == 0) { //出错啦,好像
// Guess JDK epoll bug
if (timeout == 0 ||
System.currentTimeMillis () - start < timeout / 2)
returnsImmediately ++;
else
returnsImmediately = 0;
if (returnsImmediately > 10) {
rebuildSelector (); //重建selector
returnsImmediately = 0;
}
continue;
}
Iterator<SelectionKey> it = selector.selectedKeys().iterator(); //所有select出来的key
while (it.hasNext()) { //遍历
SelectionKey key = it.next();
IPollEvents evt = (IPollEvents) key.attachment();
it.remove();
try { //接下来就是判断事件的类型执行相应的方法就好了
if (key.isReadable() ) { //有数据可以读取了
evt.in_event();
} else if (key.isAcceptable()) { //有新的连接进来了
evt.accept_event();
} else if (key.isConnectable()) { //连接建立
evt.connect_event();
}
if (key.isWritable()) { //可写
evt.out_event();
}
} catch (CancelledKeyException e) {
// channel might have been closed
}
}
}
stopped = true;
} 这部分还是好理解的,首先是检查fd_table是否需要更新,其实就是有没有新插入的channel或者有channel已经失效,由retired标志位决定。如果需要更新,遍历map中每个元素,检查PollerSet里的key,如果没有,则在Selector上进行注册。
然后调用selector.select(),若是有事件到来,根据其事件类型以及注册事件时一并传入的handle来决定执行何种操作。
简单来说Poller就是一个轮询器,我们在它的Selector上注册相应的channel与事件。而Poller定期扫描来捕获channel的状态。同时我们也了解到一点,Poller才是真正的IO线程持有者。
粗浅的说明了Poller之后,再来看看MailBox
同样,先是介绍一些重要的属性
private final YPipe<Command> cpipe; //一个用来保存command的队列,内部以链表的形式实现
private final Signaler signaler; //其实也是一个实现了一个SocketChannel,但是不对外发送消息,而是向Poller发送空白消息,以提醒command队列中有命令需要处理
private final Lock sync; //只有一个线程从mailbox里面收命令,但是会有很多线程向mialbox里面发送命令,用这个锁来进行同步
public SelectableChannel get_fd () {
return signaler.get_fd (); //这里其实获取的是signal用到的pipe的读channel
}
//向当前的mailbox发送命令,其实就是写到command队列里面去而已
public void send (final Command cmd_) {
boolean ok = false;
sync.lock ();
try {
cpipe.write (cmd_, false);
ok = cpipe.flush (); //pipeflush,这里将会被selector感应到,从而可以执行相应的处理,在执行线程里面执行命令
} finally {
sync.unlock ();
}
if (!ok) {
signaler.send (); //通过写端写数据,这样子的话会被读端收到
}
}
//收取命令,如果这里无法立刻获取命令的话,还可以有一个超时时间
public Command recv (long timeout_) {
Command cmd_ = null;
// Try to get the command straight away.
if (active) {
cmd_ = cpipe.read (); //从队列里面获取命令
if (cmd_ != null) {
return cmd_;
}
// If there are no more commands available, switch into passive state.
active = false;
signaler.recv (); //这里会从读端不断的读数据
}
// Wait for signal from the command sender.
boolean rc = signaler.wait_event (timeout_);
if (!rc)
return null;
// We've got the signal. Now we can switch into active state.
active = true;
// Get a command.
cmd_ = cpipe.read ();
assert (cmd_ != null);
return cmd_;
} MailBox,就像之前说过的,只是用于处理命令的一个东西。命令的读写都是对本地的一个队列进行操作。需要注意的是在写命令与读命令之间需要有Signaler来充当信号通知者。
Signaler内部有一组变量:
private Pipe.SinkChannel w; 数据写入端
private Pipe.SourceChannel r; 数据读取端将SourceChannel 注册到了poller内。 这样,当命令写入到队列中,会触发SinkChannel的write操作,通过SinkChannel向SourceChannel写数据,此时会被poller内的selector感知到。
由于IOThred在向poller注册时,传入的回调是“this”,也就是本身,在发生in_event(读事件)时,实际调用的时IOThread的in_event。
然后IOThread中的in_event从MailBox中读取数据,实质是从YPipe中读取command。
对于Signaler的作用,只是用于提醒poller有命令,它向SinkChannel内写入的数据其实是一个大小为1没有意义的ByteBuffer。只是用于触发在poller内注册的SourceChannel的Readable事件。
需要明确的是,command都是针对于本地的。不会在两台不同的机器间传送command,因为send_command并没有走socketchannel,所以不可能通过网络发送。
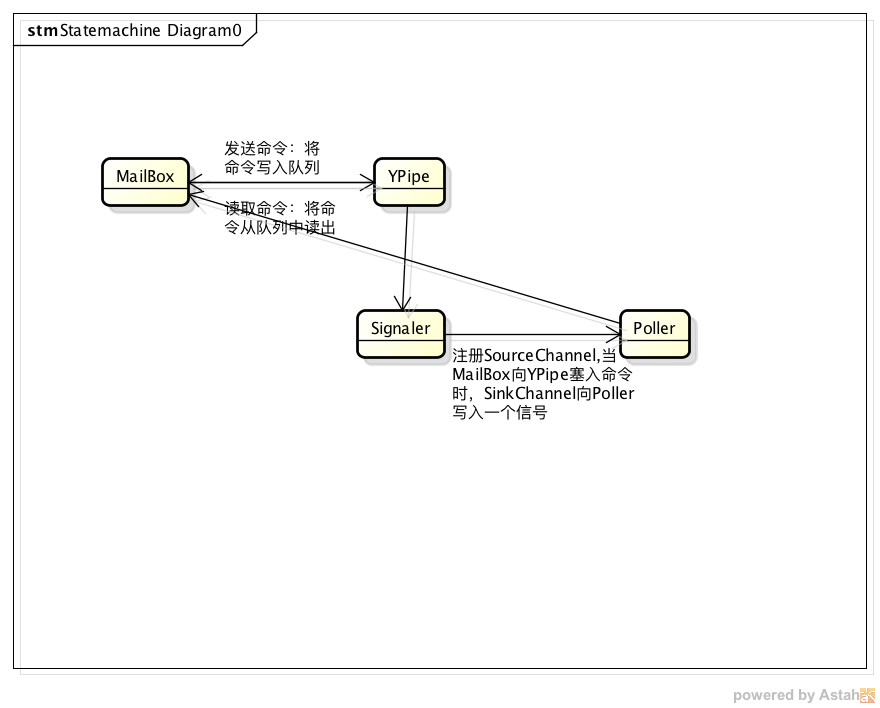
MailBox里面的逻辑大致就是如此:
1.命令写入YPipe
2.Signaler提醒Poller,激活in_event
3.MailBox从YPipe读取命令并执行
ok,一些基本的概念说的差不多了,接下来开始说明Socket的创建以及消息的发送过程。
//这是一个创建上下文,Socket,与目标端进行连接,发送数据以及接收数据的客户端代码
Context context = ZMQ.context(1);
Socket worker = context.socket(ZMQ.REQ);
worker.connect("tcp://localhost:5671");
worker.send ("Hi Boss");
String workload = worker.recvStr ();
Sysout.out.println(workload);1.创建上下文
private final List<SocketBase> sockets;
private final Deque<Integer> empty_slots;
private volatile boolean starting;
private boolean terminating;
private final Lock slot_sync;
private Reaper reaper;
private final List<IOThread> io_threads;
private int slot_count;
private Mailbox[] slots;
private final Mailbox term_mailbox;
private final Lock endpoints_sync;
private static AtomicInteger max_socket_id = new AtomicInteger(0);
private int max_sockets;
private int io_thread_count;
private final Lock opt_sync;
public static final int term_tid = 0;
public static final int reaper_tid = 1;
上面给出了Ctx内的一些重要的成员变量,初始化过程中调用了init_ctx(),返回一个Ctx对象,此时仅仅只是对部分成员变量做了一个初始赋值,并没有特殊操作。
2.创建Socket
//截取部分代码,基本上能表示整个过程
if (starting) {
starting = false;
opt_sync.lock ();
int mazmq = max_sockets;
int ios = io_thread_count;
opt_sync.unlock ();
slot_count = mazmq + ios + 2;
slots = new Mailbox[slot_count];
slots [term_tid] = term_mailbox;
reaper = new Reaper (this, reaper_tid);
slots [reaper_tid] = reaper.get_mailbox ();
reaper.start ();
//以上部分创建的Reaper对象与两个MailBox是作用于上下文销毁的时候处理剩余消息以及释放占用资源。
//下面是需要关注的部分,ios是在创建Ctx时我们指定需要创建的IO线程数,通常情况1个就足够了。根据我们指定的数量创建相应的IOThread,每个IOThread都有他子身的MailBox。
for (int i = 2; i != ios + 2; i++) {
//创建IOThread对象的时候会创建一个Poller,以及一个MailBox,同时,将MailBox对应的Signaler的SourceChannel注册到Poller中以监听有无command需要执行。
IOThread io_thread = new IOThread (this, i);
io_threads.add(io_thread);
slots [i] = io_thread.get_mailbox ();
//启动Poller
io_thread.start ();
}
for (int i = (int) slot_count - 1;
i >= (int) ios + 2; i--) {
empty_slots.add (i);
slots [i] = null;
}
}
//以上为if部分,只会在Ctx已经创建好,第一次创建Socket会进入的分支,由于是第一次创建Socket,所以需要对一些Ctx成员进行初始化。而之后只需要创建每个Socket对应的IOThread以及必要属性即可。
int slot = empty_slots.pollLast();
int sid = max_socket_id.incrementAndGet();
//这一步比较重要,先创建一个SocketBase,它是所有Socket的父类
s = SocketBase.create (type_, this, slot, sid);
if (s == null) {
empty_slots.addLast(slot);
return null;
}
sockets.add (s);
slots [slot] = s.get_mailbox ();来看看SocketBase.create(type_,this,slot,sid)都做了些什么。
//省略了部分操作,实际是先根据我们要创建的Socket类型调用构造函数,然后在构造函数中用super调用父类也就是SocketBase的构造函数...
//给出部分重要成员
private int tag;
private boolean ctx_terminated;
private boolean destroyed;
private final Mailbox mailbox;
private final List<Pipe> pipes;
private Poller poller;
private SelectableChannel handle
private SocketBase monitor_socket;
protected SocketBase (Ctx parent_, int tid_, int sid_)
{
//调了ZObject的构造函数,因为ZObject是所有类的父类
super (parent_, tid_);
tag = 0xbaddecaf;
ctx_terminated = false;
destroyed = false;
last_tsc = 0;
ticks = 0;
rcvmore = false;
monitor_socket = null;
monitor_events = 0;
options.socket_id = sid_;
endpoints = new MultiMap<String, Own>();
//这个pipes在后期会起到非常大的作用
pipes = new ArrayList<Pipe>();
//创建了一个MailBox
mailbox = new Mailbox("socket-" + sid_);
errno = new ValueReference<Integer>(0);
...
return s;
}那到这里为止,我们已经获得了所需的Socket,但是需要注意的是现在只是获得Socket,但是该Socket还没有跟地址进行绑定或者链接。
现在说connect部分,这部分比较长,所以分开说明。
//这里就是先去看看有没有需要执行的command,有的话先执行。这样做的目的应该是假如我们关闭了上下文,理论上来说是不再处理任何请求。但是关闭上下文也是一个动作,发出一个command,经过之前对MailBox的讲解,我们知道处理一个command其实是先放到一个队列中,等待Poller的信号在从队列中取出command然后执行。这样如果Poller要处理较多事件时,可能会推迟command的执行,个人认为在ZeroMQ中,command的优先级是大于消息的。所以基本在执行大部分动作前会先去看看队列中有没有待执行的command。以避免command等待过久而不执行的尴尬。
boolean brc = process_commands (0, false);
if (!brc)
return false;
...
//这里没什么需要特别说明的,我们知道终端url的形式是像tcp://192.168.1.1:8000 这样的形式存在的。所以这里做的只是获取IP,端口以及协议。
String protocol = uri.getScheme();
String address = uri.getAuthority();
String path = uri.getPath();
if (address == null)
address = path;
check_protocol (protocol);
...
//创建一个与该Socket对应的Session,一个Socket可以绑定多个Session
SessionBase session = SessionBase.create (io_thread, true, this, options, paddr);在SessionBase中才是发生SocketChannel对接的地方,下面来看看它做了些什么。
//与SocketBase类似,也是进行了一些基本的初始化工作
private boolean connect;
private Pipe pipe;
private final Set<Pipe> terminating_pipes;
private boolean incomplete_in;
private boolean pending;
private SocketBase socket;
private IOThread io_thread;
private boolean identity_sent;
private boolean identity_received;
private final Address addr;
private IOObject io_object;
public SessionBase(IOThread io_thread_, boolean connect_,
SocketBase socket_, Options options_, Address addr_) {
super(io_thread_, options_);
io_object = new IOObject(io_thread_);
connect = connect_;
pipe = null;
incomplete_in = false;
pending = false;
engine = null;
socket = socket_;
io_thread = io_thread_;
has_linger_timer = false;
identity_sent = false;
identity_received = false;
addr = addr_;
terminating_pipes = new HashSet <Pipe> ();
}继续看connect的过程。
...
if (options.delay_attach_on_connect != 1 || icanhasall) {
//这个parents在回收资源的时候起作用,维护层级关系
ZObject[] parents = {this, session};
Pipe[] pipes = {null, null};
//这是一个高水位线数组,由于Socket根据不同类型会存在发送缓冲区,接收缓冲区,或者一个公用缓冲区。虽然ZeroMQ没有持久化操作。但是比如Req套接字,如果在Rep建立连接前就发送消息,实质是不会发出去的,会先缓存在本地发送缓存区。同时,接收缓冲区也一样,如果收到消息还没来的及处理,就会一直对方在接收缓存区中。高水位线的作用就是给缓冲区定义一个大小,防止撑爆内存。
int[] hwms = {options.sndhwm, options.rcvhwm};
boolean[] delays = {options.delay_on_disconnect, options.delay_on_close};
//OK,接下去的3步操作,直接为Socket与Session进行数据交互奠定了基础。我们仔细看下。
Pipe.pipepair (parents, pipes, hwms, delays);
attach_pipe (pipes [0], icanhasall);
session.attach_pipe (pipes [1]);
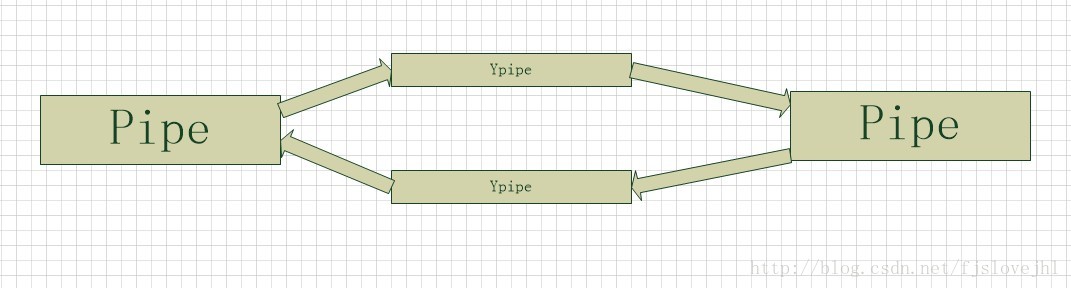
}public static void pipepair(ZObject[] parents_, Pipe[] pipes_, int[] hwms_, boolean[] delays_) {
//从以下代码可以看到一个数据结构,它创建了2个YPipe对象(实质就是链表),然后又创建了2个Pipe,一般的1个Pipe需要一个写端一个读端,在这里这两个Pipe公用了2个YPipe。
//也就是说,现有2个Pipe,分别是A,B;2个YPipe,分别是Y1,Y2 。A,B公用Y1,Y2,Y1作为A的读端,作为B的写端;Y2作为B的读端,作为A的写端。结构图如下
YPipe<Msg> upipe1 = new YPipe<Msg>(Msg.class, Config.message_pipe_granularity.getValue());
YPipe<Msg> upipe2 = new YPipe<Msg>(Msg.class, Config.message_pipe_granularity.getValue());
pipes_ [0] = new Pipe(parents_ [0], upipe1, upipe2,
hwms_ [1], hwms_ [0], delays_ [0]);
pipes_ [1] = new Pipe(parents_ [1], upipe2, upipe1,
hwms_ [0], hwms_ [1], delays_ [1]);
//两个Pipe相互持有对方的引用
pipes_ [0].set_peer (pipes_ [1]);
pipes_ [1].set_peer (pipes_ [0]);
}
继续看剩下的两个操作
//这两部操作就比较好说,因为我们有2个Pipe,但最后是SocketBase持有一个Pipe,另一个由SessionBase持有。这样,SessionBase才能通过此与SocketBase进行数据交互,而实际上,发送数据或者接收数据就是通过这两个Pipe来流动的。
attach_pipe (pipes [0], icanhasall);
session.attach_pipe (pipes [1]);发送时,Pipe1通过LB向YPipe1写入要发送的数据,并发送read_activated命令,传入参数为Pipe2,SessionBase中其实持有的就是Pipe2,所以Pipe2从YPipe读取数据后由StreamEngine发送
接收时,StreamEngine将消息写会SessionBase的Pipe,也就是Pipe2,从Pipe2写入数据,其实是写入到YPipe2,然后通知SocketBase中的Pipe1,Pipe1从YPipe2读取数据
其实我觉得比如直接把Pipe设计成队列的形式,同样是两个Pipe,SocketBase与SessionBase同时持有双方引用,也能做到一样的功能,也许是因为这样做的话双方要维护的Pipe对的引用数会加倍,所以没有采用这种做法。
继续讲connect的最后一步。
add_endpoint (addr_, session);
//调用了 launch_child (endpoint_);方法
protected void launch_child (Own object_)
{
//这步是设置层级关系,回收资源时用到
object_.set_owner (this);
//其实质就是发送了一个plug命令,因为传进来的object_是SessionBase,所以plug操作最后由SessionBase来完成。
send_plug (object_);
send_own (this, object_);
}
//SessionBase中的process_plug操作
protected void process_plug ()
{
io_object.set_handler(this);
if (connect)
start_connecting (false);
}
//看到这里似乎要发现了连接操作将要执行的细节了。
private void start_connecting (boolean wait_)
{
assert (connect);
assert (io_thread != null);
// Create the connecter object.
if (addr.protocol().equals("tcp")) {
TcpConnecter connecter = new TcpConnecter (
io_thread, this, options, addr, wait_);
//alloc_assert (connecter);
//没错,又是 launch_child,不过这次传进去的对象是上面创建的 TcpConnecter。同样的一会来看看 TcpConnecter里的process_plug操作。
launch_child (connecter);
return;
}
if (addr.protocol().equals("ipc")) {
IpcConnecter connecter = new IpcConnecter (
io_thread, this, options, addr, wait_);
//alloc_assert (connecter);
launch_child (connecter);
return;
}
assert (false);
}
简要说明下TcpConnector的重要成员以及部分操作
private final static int reconnect_timer_id = 1;
private final IOObject io_object;
private final Address addr;
private SocketChannel handle;
private boolean handle_valid;
private boolean delayed_start;
private boolean timer_started;
private SessionBase session;
private int current_reconnect_ivl;
private String endpoint;
private SocketBase socket;
//观察下发现他持有一个SessionBase引用,以及含有IOThread的一个IOObject
public TcpConnecter (IOThread io_thread_,
SessionBase session_, final Options options_,
final Address addr_, boolean delayed_start_) {
super (io_thread_, options_);
io_object = new IOObject(io_thread_);
addr = addr_;
handle = null;
handle_valid = false;
delayed_start = delayed_start_;
timer_started = false;
session = session_;
current_reconnect_ivl = options.reconnect_ivl;
assert (addr != null);
endpoint = addr.toString ();
socket = session_.get_soket ();
}
//接下去,我们要来看TcpConnector里的process_plug
protected void process_plug ()
{
//设置了回调句柄为TcpConnector
io_object.set_handler(this);
if (delayed_start)
add_reconnect_timer();
else {
start_connecting ();
}
}
//开始进行Socket连接
private void start_connecting ()
{
try {
//open()操作,执行真正的连接
boolean rc = open ();
if (rc) {
//若是连接成功,那该SocketChannel注册到Poller中
io_object.add_fd (handle);
handle_valid = true;
//ok,这里不用说,实际上肯定是执行了事件回调,在之前的process_plug里看到, io_object.set_handler(this);说明在IOObject内的回调句柄就是该TcpConnector,所以这里执行的就是TcpConnector的connect_event(),具体执行在下面有所介绍。
io_object.connect_event();
}
else {
//进入该分支那明显就是说明连接未成功,采取的策略是延迟一段时间后继续尝试连接。
io_object.add_fd (handle);
handle_valid = true;
io_object.set_pollconnect (handle);
socket.event_connect_delayed (endpoint, -1);
}
} catch (IOException e) {
// Handle any other error condition by eventual reconnect.
if (handle != null)
close ();
add_reconnect_timer();
}
}
//到此,终于看到了真正的Socket连接
private boolean open () throws IOException
{
assert (handle == null);
handle = SocketChannel.open();
//设置为非阻塞模式
Utils.unblock_socket(handle);
boolean rc = handle.connect(addr.resolved().address());
return rc;
}这里说明下connect_event()
public void connect_event ()
{
boolean err = false;
SocketChannel fd = null;
try {
//确认连接是否完成,因为之前将SocketChannel设置成了非阻塞模式,所以我们并不知道连接是否已经成功建立。
fd = connect ();
} catch (){
...
}
//这里是将成功连接得到的SocketChannel从Poller中主注销,可能大家觉得奇怪,都成功连接了干啥要注销呢,因为之前注册的时候监听的是connect_event,现在既然成功连接了,当然不再需要监听connect_event了。
io_object.rm_fd (handle);
handle_valid = false;
if (err) {
//这里做的是失败重连机制,具体做法是延迟再尝试,指数式延迟。比如第一次延迟2s,第二次延迟4s...
//至于close()执行的目的,那肯定就是关闭由于之前成功连接所打开的一些资源。
close ();
add_reconnect_timer();
return;
}
handle = null;
try {
Utils.tune_tcp_socket (fd);
Utils.tune_tcp_keepalives (fd, options.tcp_keepalive, options.tcp_keepalive_cnt, options.tcp_keepalive_idle, options.tcp_keepalive_intvl);
} catch (SocketException e) {
throw new RuntimeException(e);
}
//StreamEngine这个东西之前没有讲过,不过等下会细讲,它是位于Poller与SessionBase之间的一层,用于数据处理。
StreamEngine engine = null;
try {
engine = new StreamEngine (fd, options, endpoint);
} catch (ZError.InstantiationException e) {
socket.event_connect_delayed (endpoint, -1);
return;
}
//上面提到了,StreamEngine是用于SessionBase与Poller之间的,那么需要将SessionBase与StreamEngine联系起来,两者才能进行交互
send_attach (session, engine);
//以下是清扫一些由于connect而留下的未释放的资源。
terminate ();
socket.event_connected (endpoint, fd);
}
ok,讲了很多,那到了这里,Socket的连接基本也就完成了。
回顾一下这个过程:
1. connect的动作最初是发生在SocketBase的
2. 在SocketBase中它创建了一个SessionBase与之对应
3. 同时创建了一对Pipe,SocketBase与SessionBase各持一个,用来在两者间进行数据交互。
4. 调用了SessionBase中的process_plug方法,创建一个TcpConnector用来将SocketChannel进行连接
5. 又调用了TcpConnector中的process_plug方法开始进行真正的连接
6. 在连接过程中我们看到,它将SocketChannel设置成了非阻塞模式,所以需要在后续检查连接是否完成,当然未完成时它也有重连策略(指数后退再重连)。
7. 连接成功后,注销在Poller中原有的SocketChannel,在重新注册一个,因为原先的SocketChannel监听connect事件。
8. 我们看到,在整个过程中MailBox起到了至关重要的部分,因为无论是plug或者是connect_event(),都是通过命令来执行的,而不是直接通过引用调用。
过程大致如上,再来说说这个StreamEngine,之前也没有讲到这个东西。
关于Poller,SessionBase与StreamEngine的交互(数据接收与发送的处理)
通过之前的了解,ZeroMQ自底向上的层级结构是这样的:底层–>Poller–>StreamEngine–>Session–>Socket–>应用程序
Poller与StreamEngine的关系相当于是Poller需要发送的数据是由StreamEngine进行编码处理的,Poller接收到的数据是由StreamEngine来解码处理的。
首先StreamEngine何时被创建?
上面说的Tcp连接过程中,讲到了超时重连机制。如果连接过程中,成功建立连接,则会先删除原先TcpConnector在Poller注册的channel,因为他只针对事件connect,成功建立连接后就没有用了。然后创建StreamEngine对象,没有其余步骤,只是初始化一些基本变量。
接下来是重点
需要将当前的Session与Engine相互联系,这样Engine接收到数据后处理好之后能放到Pipe中供session获取,发送也是同样道理,所以这里需要发送attach命令.命令发送的过程不再赘述,上面已经讲过了。
接收到attach命令后,由SessionBase的process_attach来负责处理,比较重要的是Engine中的plug方法,该方法的作用是将Engine插到Session中,但是比较好理解的说法就是讲Engine与Session相互联系起来,并且在Poller中进行注册。
向poller注册的过程就是用将从tcpconnector中成功连接所获取到的SocketChannel注册到Poller中,Engine本身作为回调方法,里面实现了in_event,out_event事件,到这里poller与Engine已经可以交互,poller在轮询发现有输入或者输出事件时,StreamEngine中的in_event,out_event会去处理。简单来说
StreamEngine与SessionBase的交互,是将一个session赋值给StreamEngine中的SessionBase
StreamEngine与Poller的交互,是将从TcpConnector中成功连接返回的SocketChannel注册到Poller中,并将本身作为回调事件加入其中。
值得一提的是,在StreamEngine中调用plug方法时,不仅仅是连接SessionBase与Poller,也会发生一次“握手”。
那进行到这里,剩下的就是一个发送与接收的过程了。
关于发送过程,入口仍就是SocketBase的send。
代码也有点长,我们还是老办法,分开看。
//public boolean send (Msg msg_, int flags_)这是方法名,Msg是消息载体,封装了要发送的消息。flags_是一个标志位,表示消息是由多段组成,合并后一起发送或者单独发送
public boolean send (Msg msg_, int flags_)
{
...
//之前怎么说的,命令的优先级大于消息,所以在类似发送消息,接收消息之前都会先去看下有没有命令要执行,主要防止一些例如销毁上下文之类的命令被延迟执行。
boolean brc = process_commands (0, true);
if (!brc)
return false;
//没啥意义,设置Msg的初始标志位
msg_.reset_flags (Msg.more);
if ((flags_ & ZMQ.ZMQ_SNDMORE) > 0)
msg_.set_flags (Msg.more);
// 尝试发送消息,经过对ZeroMQ的命名方法的研究,发现带有x都是调用其具体实现类方法。
boolean rc = xsend(msg_);那就来看下具体是哪个子类来执行这个发送动作的
protected boolean xsend(Msg msg_)
{
//lb就是之前说的LB(LoadBalanced 用来管理发送的消息的)
return lb.send(msg_, errno);
}
//Req的父类是Dealer
//来看看LB的send
public boolean send(Msg msg_, ValueReference<Integer> errno) {
...
more = msg_.has_more();
if (!more) {
//flush是对于发送消息的准备
pipes.get(current).flush ();
if (active > 1)
current = (current + 1) % active;
}
return true;
}
public void flush ()
{
if (state == State.terminating)
return;
if (outpipe != null && !outpipe.flush ()) {
//发送了一个command,告知已经有准备好发送的数据,请读取
send_activate_read (peer);
}
}之前提过SessionBase与SocketBase通过一对Pipe来进行数据交互,那到这里,发送数据的过程也已经能看出个大概,首先就是将准备好的数据进行封包,Req需要一个身份帧,一个空帧,一个内容帧。然后将封包后的Msg写入SocketBase的Pipe,同时向Poller发送一个命令,告知在SocketBase端的Pipe中有可读消息需要发送。随即执行SessionBase的read_activated方法,目的是从Pipe中读出要发送的数据后发送出去。
public void read_activated(Pipe pipe_)
{
// Skip activating if we're detaching this pipe
if (pipe != pipe_) {
assert (terminating_pipes.contains (pipe_));
return;
}
if (engine != null)
engine.activate_out ();
else
pipe.check_read ();
}之前也讲过真正的数据发送是发生在StreamEngine中的,那么需要来看下activate_out中发生了什么。
public void out_event ()
{
...
//通过SessionBase的Pipe从SocketBase的Pipe中读取数据
outbuf = encoder.get_data (null);
outsize = outbuf.remaining();
...
//发送数据
int nbytes = write (outbuf);
...
}
private int write (Transfer buf)
{
int nbytes = 0 ;
try {
nbytes = buf.transferTo(handle);
} catch (IOException e) {
return -1;
}
return nbytes;
}
@Override
public final int transferTo (WritableByteChannel s) throws IOException {
return s.write (buf);
}
//那看到这里我们已经看到了真正的发送过程,读取数据后,直接通过WritableByteChannel来想连接节点发送消息。接收过程类似于发送过程,Poller轮询器里注册的channel监听到有事件发生,由于之前channel向selector注册的时候携带的附件基本都是一个IOObject对象,所以从IOObject对象开始逐层向内执行in_event(),最终到了StreamEngine中。
private int read (ByteBuffer buf)
{
int nbytes = 0 ;
try {
nbytes = handle.read (buf);
} catch (IOException e) {
return -1;
}
return nbytes;
}在StreamEngine中的in_event()中通过一个read方法将其读到ByteBuffer中,然后解码后放到SessionBase的Pipe中。SocketBase通过他持有的Pipe来获取SessionBase中Pipe的数据,并最终返回给客户端。
对发送与接收部分的小结:
StreamEngine中的in_event与out_event两个方法,这两个方法是真正读,写数据的地方,抛开一些列数据长度的检查,ByteBuffer的设置填充等,
最终的就是调用了SocketChannel的read与write方法。
但是经过观察,似乎Poller轮询是如果isWriteable为true,走out_event方法时,只有在StreamEngine发送握手信息时才会发生。而其余,无论是客户端发送或者接收信息,走的都是Poller中的isReadable下的in_event。原因之后进行说明。
上面说到客户端的读写在Poller走的都是in_event。
读很好理解,另一个端点直接通过SocketChannel,write一个消息过来,因为我们的SocketChannel在Poller中注册了,所以自然就比较能检测到isReadable信号,从而进入in_event
但是写的话,由于我们表面上的写操作并不是直接通过SocketChannel来发送消息,而是先将要发送的消息放到Pipe中(其实就是放到一个队列中),然后由之前提过的Signaler发出一个activate_read信号,也就是告诉主机本地有需要发送的消息,请从Pipe中读取。上面也提过,Signaler的消息是通过SinkChannel发送的,对应的SourceChannel在Poller中也注册了。
如此,Poller轮询到一个读事件,促发in_event,IOThread从MailBox中读取命令后发现是activate_read命令,触发read_activated事件,该事件由SessionBase开始传播,最终传到StreamEngine中的activate_out事件,由该事件来执行out_event,来真正完成发送数据的过程。
就整个实现过程进行一个小总结
1.MailBox是核心组件,所有所有动作包括读,写最终都要通过命令传递,才会发生我们预期中的操作
2.命令的优先级高于消息,明显的在读写操作前都会先去读MailBox中有没有命令需要执行
3.Socket连接方式采用非阻塞模式,具有断线重连,超时重连的功能,重连方式是以指数退步的方式进行
4.纵观全局,其实所有的内容都包装在了一个IOObject中,所以层级拆分时还是比较容易的
5.整个消息组件用了大量的事件回调,几乎所有的动作都是通过时间回掉来完成的
6.整个发送或者或者接收过程,就像是有消息要发送,先发个命令到MailBox,读取命令后执行具体操作。有消息要接收,先发个命令到MailBox,读取命令后执行具体操作。
5. 核心特点
1.嵌入式消息组件
与rabbitMQ,ActiveMQ有很大的不同,如果说rabbitMQ已经近乎是一个小型操作系统,那么ZeroMQ就像是一个嵌入在操作系统内的一个组件,说白了ZeroMQ就是一组jar包,直接嵌入到项目中就可以运行,它不需要一台独立的服务器来承载整个消息系统。
ZeroMQ关注的不是消息的可靠送达,而是着眼于端到端的发送,接收…它希望的是尽快完成任务,而不介意部分消息的丢失。
但这也并不是说他完全没有持久化的功能,ZeroMQ是具有一定的本地持久化的功能的,但是能保存的数据量比较有限,而且是暂存于内存中的。
2.高的离谱的吞吐量
这是网上找到的一张关于MQ的性能分析的图表

显示的是每秒钟发送和接受的消息数。整个过程共产生1百万条1K的消息,测试环境为Windows Vista。从测试数据可以看出,ZeroMQ的性能远远高于其它3个MQ。或者说ZeroMQ与其他3各MQ根本就不再一个量级上比较合适。
至于这样的原因跟ZeroMQ的定位,以及对消息的处理方式有很大关联。
ZeroMQ对于消息的处理可以说除却请求-应答模式之外,基本就是不关系消息是否丢失,它只管发送。
ZeroMQ的定位,它的创始人一直在其社区表示,团队将立志于把ZeroMQ融入到Linux内核中去。
基于以上两点,高效的处理速度就成了它必不可少的特点之一。
3. 无锁队列与异步模式
之前我们提到了SessionBase与SocketBase之间通过一对Pipe来完成数据交互,在这对Pipe的内部持有的是YPipe的实例,YPipe本质上的实现是一个队列,而且还是一个采用无锁CAS技术的队列。我截出部分代码,供大家参考:
public final boolean flush ()
{
// If there are no un-flushed items, do nothing.
if (w == f) {
return true;
}
// Try to set 'c' to 'f'.
if (!c.compareAndSet(w, f)) {
c.set (f);
w = f;
return false;
}
w = f;
return true;
}类似于这样的操作在YPipe中还有不少。
还是Pipe,我们知道Pipe有一个读端一个写端,这两端均在Poller中注册了异步事件,在该Pipe上发生读写操作时就会触发相应的具体读写事件实现方法。这样的做法提高的程序的响应速度。但是缺点是除非明确在Poller中注册的对象到底是什么,否则比较难判断出将要执行的回调事件将在哪里发生,比如同样是in_event(),IOObject实现了,SocketBase实现了,SessionBase也实现了,如果我们不知道注册时传入的handle是什么,判断起来就有些繁琐了。
4.多核下的线程绑定
传统的多线程并发模式一般会采用锁,临界区,信号量等技术来控制,而ZeroMQ给出的建议是:在创建IO时不要超出CPU核数。
当我们创建一个上下文时都会有这么一句代码“Context context = ZMQ.context(1);”这里就指定了IO线程数。通常来说一个线程足矣。但是如果希望创建多个IO线程,最好不要超出CPU核数,因为此时ZeroMQ会将工作线程其实就是那个Poller绑定到每一个核,免除了线程上下文切换带来的开销。
6. 与其他MQ的对比
关于ZeroMQ与其他几个MQ之间的比较,我们在TPS,并发性,持久化,技术点以及扩展性这几个方面进行展开。
1.TPS
之前提过,这里在说一下。
显示的是每秒钟发送和接受的消息数。整个过程共产生1百万条1K的消息,测试环境为Windows Vista。
明显的ZeroMQ最好,其余三者差不多。
2.持久化消息比较
ZeroMq原生是不支持的,仅支持相当有限的本地缓存,如需要消息持久化需要自己进行扩展。
ActiveMq和rabbitMq都支持。
3.并发性
虽然ZeroMQ在高并发环境下不会出问题,但是有可能会导致本地的缓存区被塞满而导致消息丢失的情况。所以不推荐在并发量较高的情境下使用ZeroMQ.
查了下资料发现,ActiveMQ在发送到queue的消息并发较多时,消费端只能接收一部分,比如100条消息在较短的时间内发入,总有10来条接收不到,存放在服务器上,而且这些消息一直不能主动发送出来,后面继续进入的消息都能正常处理,最终只有重新启动服务消费端才能接收到那部分剩下的消息。
而RabbitMQ,从实现语言来看,它是并发性最好的,原因是它的实现语言是天生具备高并发高可用的erlang语言。
4.技术点以及扩展性
ok,首先就扩展性而言,那毫无疑问的是ZeroMQ最强,其余其中MQ都已经是成形的产品,已经是一款应用程序了。而ZeroMQ说白了就是一组库函数。基于这种情况,我们可以按自己的需要实现IPollEvent以及ZObject来开发适合自己的Socket组件,至于它对于消息持久化的不支持,只是原生不支持,因为它的定位不是吃保证可靠的消息传输。所以在可靠性这部分我们完全可以按自己的需求进行扩展。一组lib的扩展度明显是宽于产品级的rabbitMQ之类的产品。
技术上虽然ZeroMQ立志于成为Linux内核的消息组件,但是不得不说它的开源社区活跃度是远远不及RabbitMQ或者ActiveMQ。或许是处于它的可靠性考虑,它的应用场景比较受限制。
可靠性上虽然ActiveMQ也具备,只是性能上相比于RabbitMQ还是有一定差距,所以大部分的MQ选型都是RabbitMQ。















 3228
3228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









