







 这篇博客介绍了如何使用Python3重构WSWP的网络爬虫,从识别网站技术、寻找网站所有者开始,逐步构建下载网页、处理异常、设置用户代理、链接爬虫等功能,并探讨了高级特性如解析robots.txt、支持代理、下载限速和避免爬虫死循环。通过示例代码展示了如何实现这些功能。
这篇博客介绍了如何使用Python3重构WSWP的网络爬虫,从识别网站技术、寻找网站所有者开始,逐步构建下载网页、处理异常、设置用户代理、链接爬虫等功能,并探讨了高级特性如解析robots.txt、支持代理、下载限速和避免爬虫死循环。通过示例代码展示了如何实现这些功能。
wswp中的代码是通过python2的语法来写的,在学习的过程中个人比较喜欢python3,因此准备将wswp的示例代码用python3重写一遍,以加深映像。
开始尝试构建爬虫
识别网站所用技术和网站所有者
构建网站所使用的技术类型的识别和寻找网站所有者很有用处,比如web安全渗透测试中信息收集的环节对这些信息的收集将对后续的渗透步骤有很重要的作用。对于爬虫来说,识别网站所使用的技术和网站所有者虽然不是很重要,但也能从中获取到很多信息。
检查构建网站的技术类型可通过一个很有用的模块builtwith中的函数来实现。
pip install builtwith需要注意的是,python3中安装好builtwith以后需对builtwith的__init__.py文件进行纠错处理,写一个测试代码根据代码运行报错进行修改就行了。修改完成后,便能使用其中的函数进行解析处理了。
import builtwith
print(builtwith.parse('http://example.webscraping.com')结果如下:

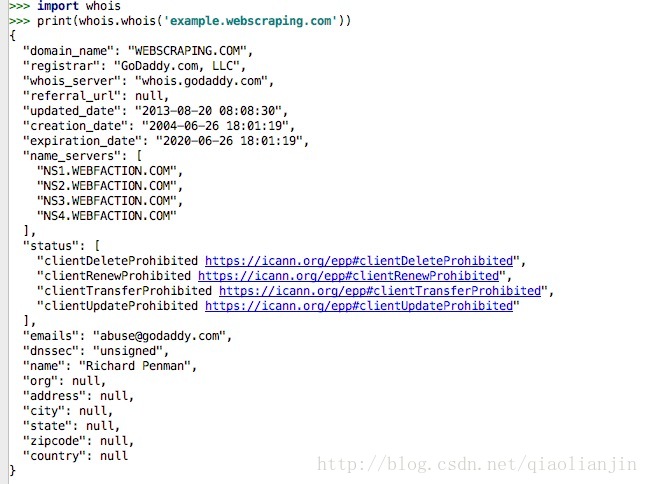
寻找网站所有者可通过python-whois模块中的函数进行解析。
pip install python-whois测试代码如下:
import whois
print(whois.whois('example.webscraping.com')结果如下:
第一个爬虫
python3中将urllib2模块的函数集成到了urllib模块中,通过不同的分类进行更细化的管理。
下载网页
爬虫进行网页数据爬取的第一个步骤便是先将网页下载下来。
# download_v1
import urllib.request
def download(url):
return urllib.request.urlopen(url).read()当传入需要下载的url时,上述函数可将对应的网页下载并返回其html。但是上述函数并没有对可能遇到的异常情况进行处理,比如页面不存在,为了避免这些异常,改进版如下:
# downloader.py
# download_v2
import urllib.request
import urllib.error
def download(url):
print("正在下载:", url)
try:
html = urllib.request.urlopen(url).read()
except urllib.error.URLError as e:
print("下载错误:", e.reason)
html = None
return html将上述代码写进一个文件,将此文件当做模板使用即可进行测试。
通过mian文件引入上述函数,对一个不存在的网页进行访问:
# main.py
from downloader import download
if __name__ == '__main__':
url = 'http://www.freebuf.com/articles/rookie/151327.html'
html = download(url)
print(html)结果如下:

重试下载
爬虫在爬取数据时遇到某些错误是临时性的,比如 503 Service Unavailable错误。对于临时错误可通过尝试重新下载。
添加重试下载功能的下载函数如下:
# downloader.py
# download_v3
import urllib.request
import urllib.error
def download(url, num_retries=3):
print("正在下载:", url)
try:
html = urllib.request.urlopen(url).read()
except urllib.error.URLError as e:
print("下载错误:", e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500<=e.code<600:
# 只对5xx错误进行重新下载尝试
return download(url, num_retries - 1)
return html测试url:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









