







有监督学习2–KNN和决策树
什么是KNN:
KNN(K-Nearest Neighbor)就是k个最近的邻居的意思,即每个样本都可以用它最接近的k个邻居来代表。KNN常用来处理分类问题,但也可以用来处理回归问题。
核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
相似度的衡量标准一般为距离,即距离越近相似度越高,距离越远相似度越小。
注意:在KNN算法模型中,对于K值是敏感的
先举个例子:
下图中的绿色方形图案属于哪一类?

注意:由于对k值敏感,k值不同,分类的结果可能不同。
如上图,K=5, 分类为蓝色; K=10,分类为红色。
KNN的算法三要素:
K值的选取
距离度量的方式
分类决策规则
k值的选择:
对于K值的选择,没有一个固定的经验。
选择较小的K值,就相当于用较小的邻域中的训练实例进行预测,训练误差会减小,容易发生过拟合;
选择较大的K值,就相当于用较大邻域中的训练实例进行预测,其优点是可以减少泛化误差,缺点是训练误差会增大。
K值一般根据样本的分布,选择较小的值,通常通过交叉验证选择一个合适的K值。
距离度量和分类规则
常用的距离度量方式有:
欧氏距离: 距离差的平方和,再开平方根
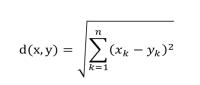
曼哈顿距离:距离差的绝对值,再开平方根
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3532
3532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









