







Spark MLlib数据挖掘4–分类与回归
一、分类与回归简介
MLlib支持多种方法用来处理二分类,多分类以及回归分析,如下是MLlib能够支持的分类和回归的场景及对应的算法。

二、线性模型
模型回顾:

损失函数回顾:
数据挖掘中常用损失函数,用于最优化问题的求解。

分类问题回顾:
分类问题旨在将数据分为不同的类别。根据类别数量分为二分类和多分类问题。
MLlib支持两个线性方法:线性支持向量机(SVM)和逻辑回归,这两种方法都支持L1和L2正则化变体。
在MLlib中训练数据集表示为LabeledPoint(标签化的样本点)的一个RDD,在本文的数学表达式中,训练标签 y 表示为 + 1 (正)和 - 1 (负),而在MLlib中使用 0 来表示负的。
线性支持向量机回顾:
线性SVM是大规模分类任务的标准方法,它是由损失函数组成的线性方法:
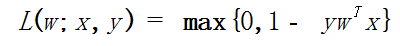
线性SVM使用L2正则化来进行训练,也支持使用L1正则化。线性SVM算法输出一个SVM模型,给定表示为 x 的新数据点,那么模型可通过 wTx 的支持向量进行预测,默认如果 w T x ≥ 0 那么输出的是正的,否则是负的。
Spark MLlib中线性支持向量机样例代码:
import org.apache.spark.mllib.classification.{
SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, “/tmp/sample_libsvm_data.txt")
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
// Run training algorithm to build the model
val numIterations = 100
//创建支持向量机的随机梯度模型进行分类模型训练
val model = SVMWithSGD.train(training, numIterations)
model.clearThreshold()
val scoreAndLabels = test.map {
point =>val score = model.predict(point.features) (score, point.label)}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
val auROC = metrics.areaUnderROC()
println("Area under ROC = " + auROC)
回归问题回顾:
对于回归问题主要采用线性最小二乘法,Lasso和Ridge回归等三种方式进行求解。线性最小二乘法是回归问题最常用的求解方法。其公式如下:
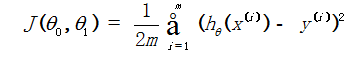
不同的回归算法(包括Lasso和Ridge)采用的是不同的模型优化方法和约束方法进行最优化问题的求解,如批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降。
逻辑回归算法回顾:
逻辑线性回归在二分类中广泛使用,其表达式为:
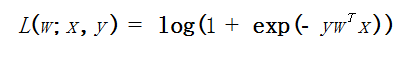
逻辑回归算法输出一个逻辑回归模型,对于给定的 x 数据点,模型可通过应用逻辑函数。
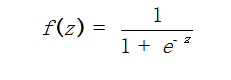
用于预测,其中 z=wTx 。默认如果 f (wTx) > 0.5 则输出正的,否则输出负的。
Spark MLlib逻辑线性回归随机梯度下降算法样例代码:
Spark MLlib中模型优化参数说明
Gradient :梯度函数。
Updater :更新器。
stepSize:步长尺度。
numIterations :迭代次数。
regParam:正则化参数。
miniBatchFraction:小批量迭代尺度。
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.regression.LinearRegressionModel
import org.apache.spark.mllib.regression.LinearRegressionWithSGD
import org.apache.spark.mllib.linalg.Vectors
val data = sc.textFile("data/mllib/ridge-data/lpsa.data")
val parsedData = data.map {
line => val parts = line.split(',' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1239
1239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









