







在微服务机制下,势必涉及服务注册与发现,一个应用部署多个副本,需要通过负载均衡技术转发客户端发送过来的请求。负载均衡实现有多种思路,可分为集中式负载均衡和进程内负载均衡。
集中式负载均衡指服务者和消费者间有一个独立的LB,LB上有所有服务的地址映射表,通常由运维配置,当服务消费方调用某个目标服务时,它向LB发起请求,由LB以某种策略(例如Round-Robin)做负载均衡后将请求转发到目标服务。LB一般还具备健康检查能力,能自动剔除不健康的服务实例。服务消费方通过DNS发现LB,运维人员为服务配置一个DNS域名,指向LB。集中式LB方案实现简单,但是存在单点问题,另外LB在服务消费方和服务提供方之间增加了一跳(hop),有一定性能开销。但是这个方案目前仍然是业界主流。
进程内的LB方案是将LB的功能以库的形式集成到服务消费方进程里,该方案也被叫做客户端负载方案。服务注册表(Service Registry)配合支持服务自注册和自发现,服务提供方启动时,将服务地址注册到服务注册表,同时定期报心跳到服务注册表以表明服务的存活状态。服务消费方访问某个服务时,通过内置的LB组件向服务注册表查询目标服务地址列表,然后以某种负载均衡策略选择一个目标服务地址,然后向目标服务发起请求。这一方案对服务注册表的可用性要求很高,一般采用能满足高可用分布式一致的组件,例如zookeeper,Consul等来实现。
进程内的LB是一种分布式模式,LB和服务发现能力被分散到每一个服务消费者进程内不,该方案以客户库(client Library)的方式集成到服务调用方进程里面,如果企业有多种技术栈,那么需要配合开发多种不同的客户端,有一定的研发成本。且如果生产环境需要进行版本升级等,那么需要所有客户端修改代码进行配合。
为了解决进程内负载均衡实现思路带来的弊端,演进出了另外一种方式,即独立LB进程服务发现模式。即LB和服务发现功能从进程内移出来,变成了主机上的一个独立进程,当主机上的服务要访问目标服务时,会通过独立的LB进程做服务发现和负载均衡。
上面是对负载均衡实现原理的一个简单理解,当在k8s集群中创建多个pod后,可以通过创建service来实现简单的负载均衡,那么service是如何完成负载均衡的呢?在理解service实现负载均衡原理前,先看看kube-proxy,在拉起集群后,每个node节点上都会运行一个kube-proxy的pod,它监听API server中service和endpoint的变化情况,并通过iptables等来为服务配置负载均衡(仅支持TCP和UDP)。
下面通过实际例子来看看是如何通过iptables中的规则完成包转发的。首选创建nginx的pod,创建2个pod,然后创建nginx的service,具体yaml文件如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginxapiVersion: v1
kind: Service
metadata:
name: nginx-basic
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginxpod和service创建成功,可以查看pod的ip地址信息和service的ip地址信息,信息如下所示
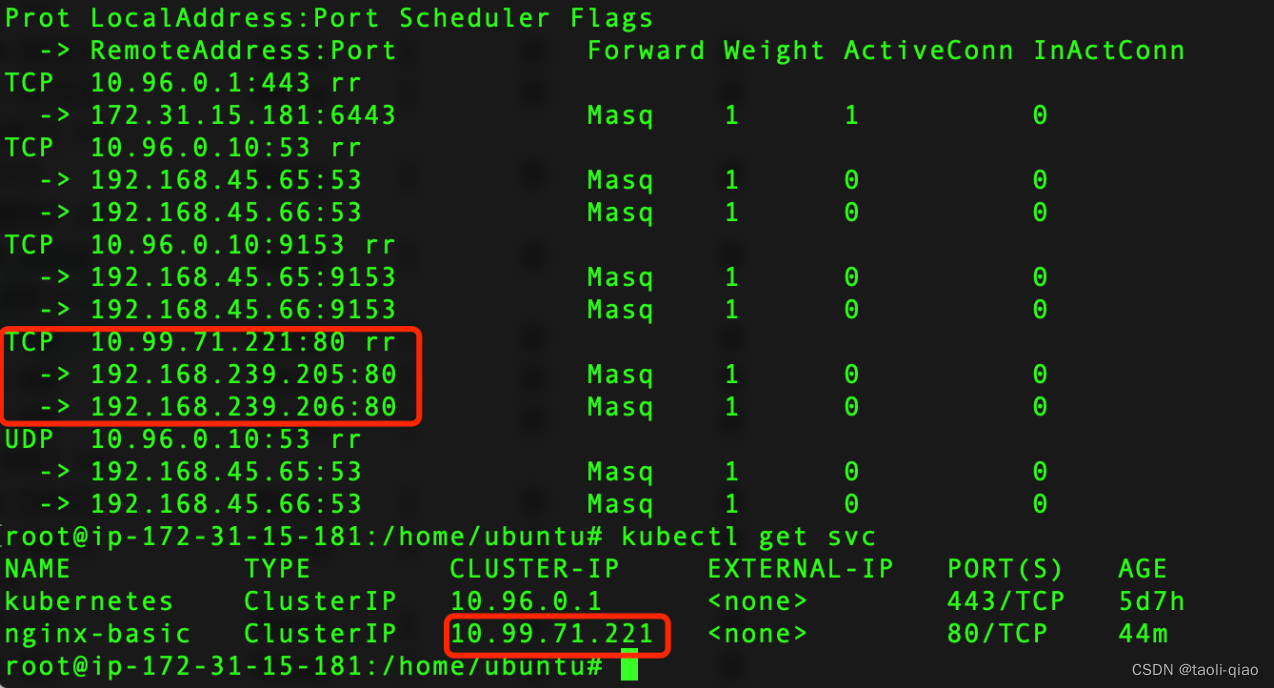
pod的ip地址分别是:192.168.239.205,192.168.239.206
service的ip地址是:10.99.71.221.service是Cluster类型。
关于service的详细信息可以查看这篇博客。

通过命令(iptable-save -t nat)查看iptables中的规则信息,因为规则信息很多,那么可以通过cluser-ip进行检索,查看需要的关键信息。这条规则的含义是:当-d(destination)目标地址是service的clusterIP地址时,那么执行下一步action(KUBE-SVC-WWRFY3PZ7W3FGMQW)

接着检索action(KUBE-SVC-WWRFY3PZ7W3FGMQW)会发现如下的iptables规则

这两条规则的含义是:50%的概率执行action(KUBE-SEP-3AFGQSHI6OV6DGDB),如果不match,那么100%的概率执行action(KUBE-SEP-T2ZBVRM3XSRHZ5J7) 。接着再用这两个action进一步检索,得到如下结果,可以看到最终转发到了连个pod的ip地址上。

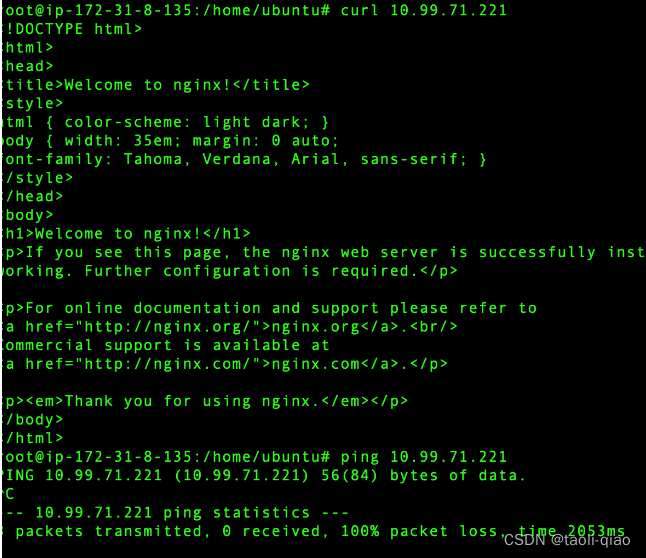
需要注意一点,ClusterIP类型的service中的clusterIP只是一个虚拟IP,并没有任何物理设备和这个IP绑定,例如如果在集群的node节点上ping clusterIP,不会通,但是如果用curl clusterIP能返回信息,因为curl是发送一个具体的请求,这个请求能通过iptables的规则转发到后面的pod上进行处理。例如上面部署的nginx,在node节点上curl能通,ping是不同的,另外,master节点上至下curl命令不通,因为服务是部署在node节点上。结果如下所示:
通过iptables规则可以完成集群内部的请求转发,但是也可以看到负载均衡的规则很粗暴,后端有2个pod服务,那么就按50%和100%的概率进行很简单的负载均衡。另外,当集群中的service很多时,iptables的规则也会激增,另外,iptables的规则也不支持增量添加,所以当有新的service加入或者pod重启后导致iptables规则更新,那么是把原来的信息全部清理掉,然后写入最新的规则信息。
除了iptables的方式,集群还支持ipvs方式转发请求。执行如下命令修改kube-proxy的配置信息,将mode设置为ipvs。
kubectl edit configmap kube-proxy -n kube-system
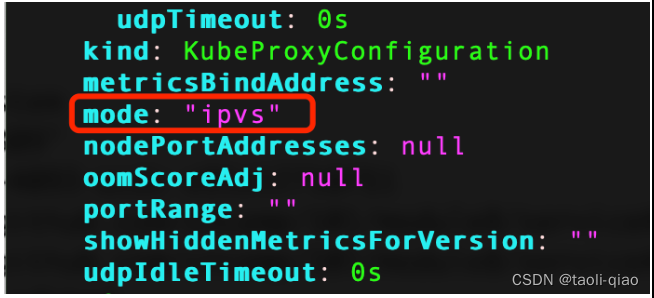
修改成ipvs模式后,为了让模式生效。那么需要删除kube-proxy的pod,删除pod后,kube-proxy会自动重启。另外执行iptables flush关闭iptables模式。
通过ipvs的命令查看net信息,ipvsadm -L -n,具体信息如下所示,可以看到service得clusterIP下关联了后端服务pod的ip地址。
另外,因为clusterIP地址是一个分配的虚拟地址,为了让请求能转发成功,那么会把clusterIP配置的网络地址信息中,ip a命令查看网络配置信息,可以看到有一个kube-ipvs0的配置,里面配置了集群中service的ip地址信息。
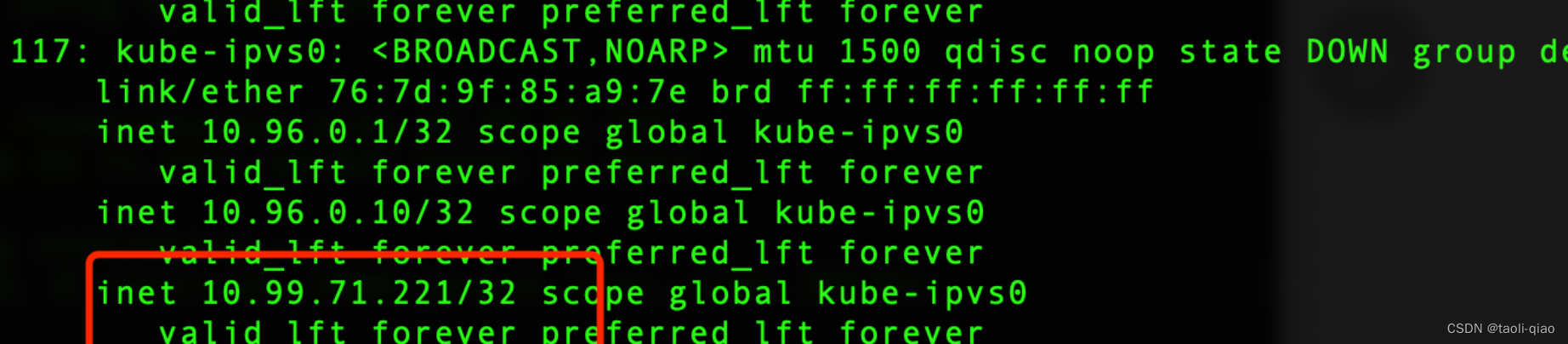
因为将clusterIP地址信息配置到了网络信息,故通过ping命令也能ping通clusterIP,在master节点和node节点上执行ping命令都痛,在node节点上执行curl命令也能访问到部署的nginx服务。

关于iptables和ipvs,在实际项目中,建议能用ipvs就使用ipvs模式。
















 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











