






正则表达式
正则表达式常用符号
- 一般字符
正则表达式的一般字符有三个
| 字符 | 含义 |
| . | 匹配任意单个字符(不包括换行符\n) |
| \ | 转义字符(把有特殊意义的字符转换成字面意思) |
| […] | 字符集。对应字符集中的任意字符 |
说明:
- “ . ”字符为匹配任意单个字符,例如,a.c可以匹配结果为abc、aic、a&c等,但不包括换行符。
- “ \ “字符为转义字符,可以把字符改变为原来的意思。听上去不是很好理解,例如“ . ”字符是匹配任意单个字符,但有时不需要这个功能,只想让它表示一个点,这时就可以使用“\.”,就能匹配为“.”了。
- […]为字符集,相当于在中括号中任选一个。例如a[bcd],匹配的结果为ab、ac、ad。
- 预定义字符集
正则表达式预定义字符集有6个
| 预定义字符集 | 含义 |
| \d | 匹配一个数字字符。等价于[0-9] |
| \D | 匹配一个非数字字符。等价于[^0-9] |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。等价于[\f\n\r\t\v] |
| \S | 匹配任何空白字符,等价于[^\f\n\r\t\v] |
| \w | 匹配包括下划线的任何单词字符,等价于’[A-Za-z0-9]’ |
| \W | 匹配任何非单词字符。等价于’[^A-Za-z0-9]’ |
正则表达式的预定义字符集易于理解,在爬虫实战中,常常会匹配数字而过滤掉文字部分信息。例如“字数3450”,只需要数字信息,可以通过“\d+”来匹配数据,“+”为数量词,这样便可以匹配到所以的数字
- 数量词
正则表达式中的数量词列表如下
| 数量词 | 含义 |
| * | 匹配前一个字符0或无限次。例如:ab*c匹配ac、abc、abbc和abbbc等 |
| + | 匹配前一个字符1或无限次。例如:ab+c匹配abc、abbc和abbbc等 |
| ? | 匹配前一个字符0或1次。例如:ab?c匹配ac和abc |
| {m} | 匹配前一个字符m次。例如:ab{3}c匹配abbbc。 |
| {m,n} | 匹配前一个字符m至n次。例如:ab{1,3}c匹配abc、abbc和abbbc、 |
- 边界匹配
边界匹配的关键字符:
| 边界匹配 | 含义 |
| ^ | 匹配字符串开头,例如,^abc匹配abc开头的字符串 |
| $ | 匹配字符串结尾。例如:abc$匹配abc结尾的字符串 |
| \A | 仅匹配字符串开头。例如:\Aabc |
| \Z | 仅匹配字符串结尾。例如:abc\Z |
边界匹配在爬虫实战中使用较少,因为爬虫提取的数据大部分为标签中的数据,例如:<span class=”stats-vote”><I class=”number”>186</i> 好笑</span>中提取数字信息,边界匹配在这里没有任何作用。
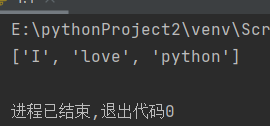
爬虫实战中常用的(.*?),”()”表示括号的内容作为返回结果,”.*?”是非贪心算法,匹配任意的字符。例如,字符串'xxIxxjshdxxlovexxsffaxxpythonxx',可以通过’xx(.*?)xx’匹配符合这种规则的字符串,代码如下:
import re
a = 'xxIxxjshdxxlovexxsffaxxpythonxx'
infos = re.findall('xx(.*?)xx',a)
print(infos)运行结果如下
re模块及方法
re模块使python语言拥有全部的正则表达式功能,这里主要是常用的三种函数使用方法
- search()函数
re模块的search()函数匹配并提取第一个符合规律的内容,返回一个正则表达式对象。
search()函数语法如下:
re.match(pattern,string,flags=0)
其中:
- pattern为匹配的正则表达式。
- string为要匹配的字符串。
- flags为标志位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等
例如:
import re
a = 'one1two2three3'
infos = re.search('\d+',a)
print(infos) #search方法返回的是正则表达式对象
可以看出,search()函数返回的是正则表达式对象,通过正则表达式匹配到了“1”这个字符串,可以通过下面的代码返回匹配到的字符串:
import re
a = 'one1two2three3'
infos = re.search('\d+',a)
print(infos.group())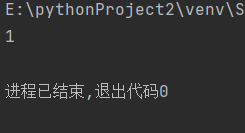
- sub()函数
re模块提供了sub()函数用于替换字符串中的匹配项,sub()函数的语法如下:
re.sub(pattern,repl,string, count=0, flags=0)
其中:
- pattern为匹配的正则表达式。
- repl为替换的字符串。
- string为要被查找替换的原始字符串。
- counts为模式匹配后替换的虽大次数,默认0表示替换所有的匹配。
- flags为标志位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等。
例如,一个电话号码123-4567-1234,通过sub()函数把中间的“-”去除掉,可以通过如下代码实现:
import re
phone = '123-4567-1234'
new_phone = re.sub('\D','',phone)
print(new_phone)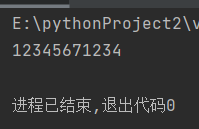
sub()函数的用途类似于字符串中的replace()函数,但sub()函数更加灵活,可以通过正则表达式来匹配需要替换的字符串,而replace()函数却做不到的。在爬虫实战中sub()函数的使用也是极少的,因为爬虫所需的是爬取数据,而不是替换数据。
- findall()函数
findall()函数匹配所有符合规律的内容,并以列表的形式返回结果。例如,前面的’one1two2three3’,通过search()函数只能匹配到第一个符合规律的结果,而通过findall()函数可以返回所有数字。
import re
a = 'one1two2three3'
infos = re.findall('\d+',a)
print(infos)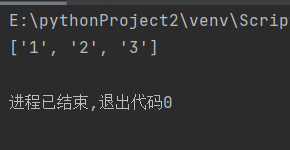
在爬虫实战中,findall()的使用频率最多,下面以前面爬取动漫花园的数据为例,看一下通过正则表达式如何提取所需的信息,通过观察网页源代码可以看出,动漫资源的存储大小都是在<td class="size">(数据量)</td>这个标签中

这时就可以通过构建正则表达式和findall()函数来获取视频资源的存储大小:
import re
import requests
res = requests.get('https://acg.rip/')
prices = re.findall('<td class="size">(.*?)</td>', res.text)
for price in prices:
print(price)结果如图

不难看出,通过正则表达式的方法爬取数据,比之前的方法代码更少也更简单,那是因为少了解析数据这一步,通过Requests库请求返回的Html文件就是字符串的类型,代码可以直接通过正则表达式来获取数据。
- re模块修饰符
re模块中包含一些可选标志修饰符来控制匹配的模式
| 修饰符 | 描述 |
| re.l | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符,这个影响\w,\W,\b,\B |
| re.X | 该标志通过给予更灵活的格式,以便将正则表达式写的更易理解 |
在爬虫中re.S是最常用的修饰符,它能够换行匹配。在这里举个简单的例子,例如提取<div>指数</div>中的文字,可以通过以下代码实现
import re
a = '<div>指数</div>'
word = re.findall('<div>(.*?)</div>',a)
print(word)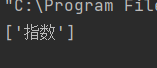
但如果字符串是下面这样的就匹配不到div标签中的文字信息

这是因为findall()函数是逐行匹配的,当第一行没有匹配到数据时,就会从第二行重新匹配,这样就没办法匹配到div标签中的文字信息,这时就可通过re.S来进行跨行匹配。
import re
a = '''<div>指数
</div>'''
word = re.findall('<div>(.*?)</div>',a,re.S)
print(word)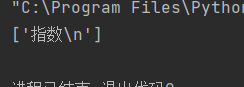
从结果中可以看出,跨行匹配的结果会有一个换行符,这种数据需要清洗才能存入数据库,可以通过strip()方法去除换行符

综合案例———爬取网络小说
利用Requests库和正则表达式方法,爬取飞卢小说网(https://b.faloo.com/1142238_1.html)中该小说的全文信息,并把爬取的数据存储到本地文件
思路:
手动浏览前5章的网址
https://b.faloo.com/1142238_1.html
https://b.faloo.com/1142238_2.html
https://b.faloo.com/1142238_3.html
https://b.faloo.com/1142238_4.html
https://b.faloo.com/1142238_5.html
可以看到有明显的规律,通过数字递加来分页。为避免因为404错误而停止爬取,从第一章开始构造URL,中间有404错误就跳过不怕去。
运用python对文件的操作,把爬取的信息存储在本地txt文本中。
爬虫代码如下:
import requests
import re
import time
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
f = open('E:/python/GUIMI/test.txt','a+')
def get_info(url):
res =requests.get(url,headers=headers)
if res.status_code == 200:
contents = re.findall('<p>(.*?)</p>',res.content.decode('gbk'),re.S)
for content in contents:
f.write(content+'\n')
else:
pass
if __name__ == '__main__':
urls = ['https://b.faloo.com/1142238_{}.html'.format(str(i)) for i in range(1,44)]
for url in urls:
get_info(url)
time.sleep(1)
f.close()运行结果:
















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









