







Given preorder and inorder traversal of a tree, construct the binary tree.
Note:
You may assume that duplicates do not exist in the tree.
假设我们的二叉树长这样。
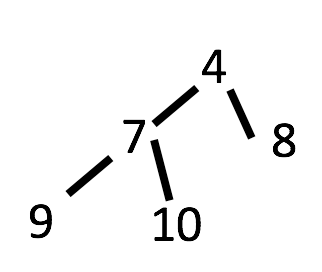
它的前序遍历为:4,7,9,10,8
它的中序遍历为:9,7,10,4,8
我们可以看到前序遍历的第一个节点4, 正是root。
看看4在中序遍历中的位置:9,7,10,4,8
4将中序遍历分成了左子树节点和右子树节点两部分。
我们再看看4节点的左子树:
9,7,10,前序遍历的下一个值7, 又是这个序列的root。
又将子树分成9, 10 两部分。
前序遍历的下一个值9,对于7节点左子树序列 9,(因为左子树序列只有9了,没有左右子树了)。
前序遍历中的值负责对中序遍历节点值进行左右子树划分。
这便是我们递归建树的思想。
先看未优化的运行时间:
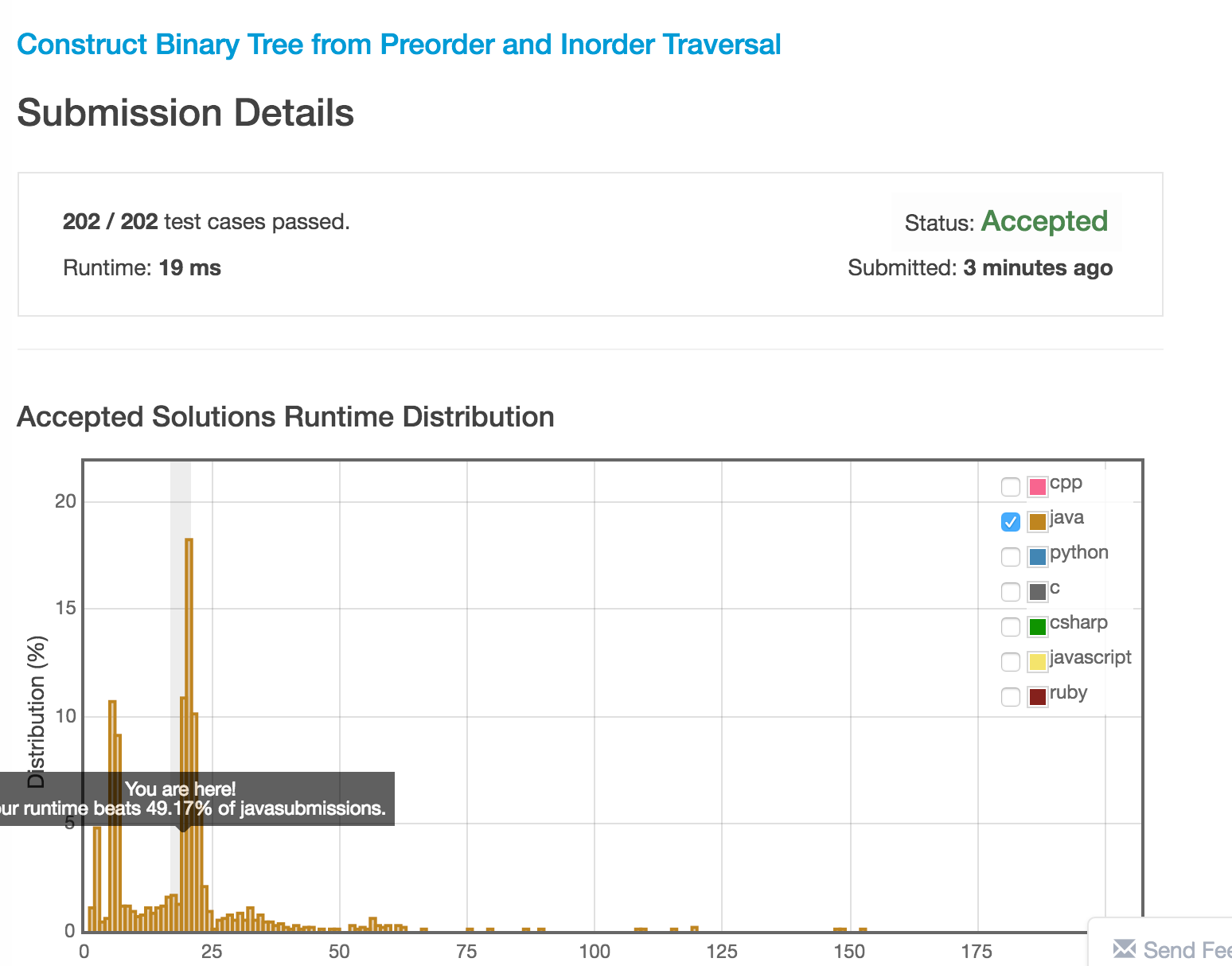
代码:
private int preIndex = 0;
public TreeNode buildTree(int[] preorder, int[] inorder) {
return doBuildTree(preorder, inorder, 0, inorder.length - 1);
}
public TreeNode doBuildTree(int[] preorder, int[] inorder, int inBeigin, int inEnd) {
if (inBeigin > inEnd) {
return null;
}
int mid = finIndex(inorder, inBeigin, inEnd, preorder[preIndex]);
TreeNode root = new TreeNode(preorder[preIndex]);
preIndex++;
root.left = doBuildTree(preorder, inorder, inBeigin, mid - 1);
root.right = doBuildTree(preorder, inorder, mid + 1, inEnd);
return root;
}
public int finIndex(int[] arr, int begin, int end, int val) {
for (int i = begin; i <= end; i++) {
if (arr[i] == val) {
return i;
}
}
return -1; // will not happen
}之前查找前序遍历中的值在中序遍历的下标,是进行线性查找。
现在我们将值与下标的信息放到map中,使查找的时间复杂度从 O (n) 变成 O (1)。
运行时间:
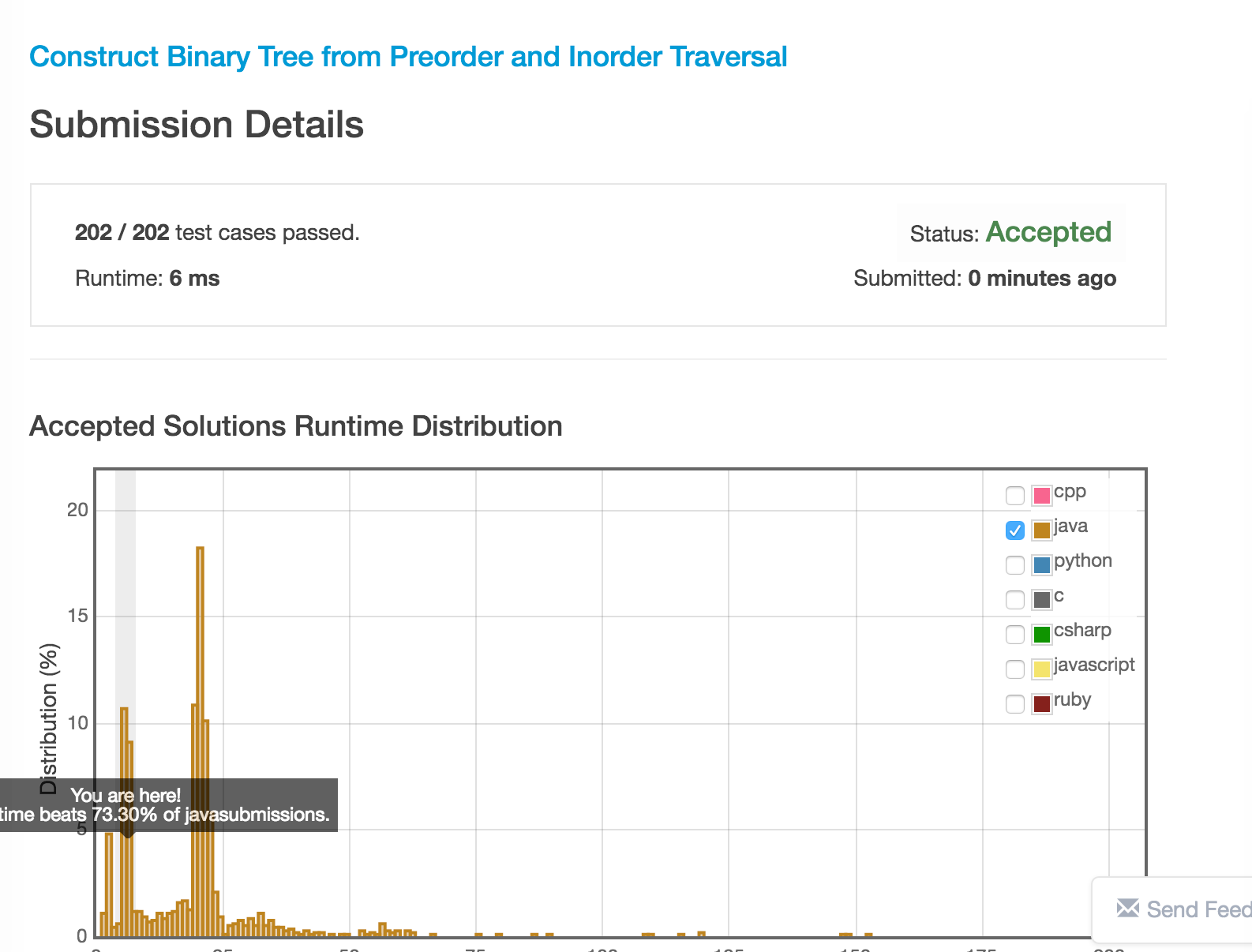
代码:
public class ConstructBinaryTreefromPreorderandInorderTraversal {
private int preIndex = 0;
private Map<Integer, Integer> valueToIndex = new HashMap<>();
public TreeNode buildTree(int[] preorder, int[] inorder) {
for (int i = 0; i < inorder.length; i++) {
valueToIndex.put(inorder[i], i);
}
return doBuildTree(preorder, inorder, 0, inorder.length - 1);
}
public TreeNode doBuildTree(int[] preorder, int[] inorder, int inBeigin, int inEnd) {
if (inBeigin > inEnd) {
return null;
}
int mid = valueToIndex.get(preorder[preIndex]);
TreeNode root = new TreeNode(preorder[preIndex]);
preIndex++;
root.left = doBuildTree(preorder, inorder, inBeigin, mid - 1);
root.right = doBuildTree(preorder, inorder, mid + 1, inEnd);
return root;
}
}















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









