本文基于 Centos6.x + CDH5.x
Oozie是什么
简单的说Oozie是一个工作流引擎。只不过它是一个基于Hadoop的工作流引擎,在实际工作中,遇到对数据进行一连串的操作的时候很实用,不需要自己写一些处理代码了,只需要定义好各个action,然后把他们串在一个工作流里面就可以自动执行了。对于大数据的分析工作非常有用
安装Oozie
Oozie分为服务端和客户端,我现在选择host1作为服务端,host2作为客户端。
所以在host1上运行
配置Oozie使用的MapReduce版本,MapReduce版本有两个一个是 MRv1 和 YARN。因为我们选择的是YARN,而且我为了方便上手暂时不用SSL,所以切换成不带SSL并且使用YARN
- alternatives --set oozie-tomcat-conf /etc/oozie/tomcat-conf.http
设置Oozie使用的数据库
这里提到的数据库是关系型数据库,用来存储Oozie的数据。Oozie自带一个Derby,不过Derby只能拿来实验的玩玩,不能上战场的。这里我选择mysql作为Oozie的数据库
我假设你已经安装好了mysql数据库,接下来就是创建Oozie用的数据库
- $ mysql -u root -p
- Enter password: ******
-
- mysql> create database oozie;
- Query OK, 1 row affected (0.03 sec)
-
- mysql> grant all privileges on oozie.* to 'oozie'@'localhost' identified by 'oozie';
- Query OK, 0 rows affected (0.03 sec)
-
- mysql> grant all privileges on oozie.* to 'oozie'@'%' identified by 'oozie';
- Query OK, 0 rows affected (0.03 sec)
编辑 oozie-site.xml 配置mysql的连接属性
- <property>
- <name>oozie.service.JPAService.jdbc.driver</name>
- <value>com.mysql.jdbc.Driver</value>
- </property>
- <property>
- <name>oozie.service.JPAService.jdbc.url</name>
- <value>jdbc:mysql://localhost:3306/oozie</value>
- </property>
- <property>
- <name>oozie.service.JPAService.jdbc.username</name>
- <value>oozie</value>
- </property>
- <property>
- <name>oozie.service.JPAService.jdbc.password</name>
- <value>oozie</value>
- </property>
把mysql的jdbc驱动做一个软链到 /var/lib/oozie/
- $ sudo yum install mysql-connector-java
- $ ln -s /usr/share/java/mysql-connector-java.jar /var/lib/oozie/mysql-connector-java.jar
第一行,如果你已经装过 mysql-connector-java 可以跳过这步
创建oozie需要的表结构
- $ sudo -u oozie /usr/lib/oozie/bin/ooziedb.sh create -run
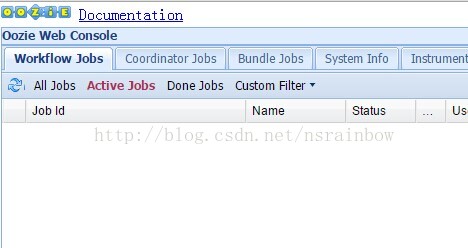
打开Web控制台
Step1
Step2
解压开 ext-2.2.zip 并拷贝到 /var/lib/oozie.
- # unzip ext-2.2.zip
- # mv ext-2.2 /var/lib/oozie/
在HDFS上安装Oozie库
为oozie分配hdfs的权限,编辑所有机器上的 /etc/hadoop/conf/core-site.xml ,增加如下配置
- <property>
- <name>hadoop.proxyuser.oozie.hosts</name>
- <value>*</value>
- </property>
- <property>
- <name>hadoop.proxyuser.oozie.groups</name>
- <value>*</value>
- </property>
并重启hadoop的service(namenode 和 datanode 就行了)
拷贝Oozie的Jars到HDFS,让DistCp, Pig, Hive, and Sqoop 可以调用
- $ sudo -u hdfs hadoop fs -mkdir /user/oozie
- $ sudo -u hdfs hadoop fs -chown oozie:oozie /user/oozie
- $ sudo oozie-setup sharelib create -fs hdfs://mycluster/user/oozie -locallib /usr/lib/oozie/oozie-sharelib-yarn.tar.gz
这里的mycluster请自行替换成你的clusterId
启动Oozie
- $ sudo service oozie start
使用Oozie
连接Oozie的方法
连接Oozie有三个方法
用客户端连接
由于我的client端装在了host2上,所以在host2上运行
- $ oozie admin -oozie http://host1:11000/oozie -status
- System mode: NORMAL
为了方便,不用每次都输入oozie-server所在服务器,我们可以设置环境变量
- $ export OOZIE_URL=http://host1:11000/oozie
- $ oozie admin -version
- Oozie server build version: 4.0.0-cdh5.0.0
用浏览器访问
打开浏览器访问 http://host1:11000/oozie
用HUE访问
上节课我们讲了HUE的使用,现在可以在hue里面配置上Oozie的参数。用HUE来使用Oozie。
编辑 /etc/hue/conf/hue.init 找到 oozie_url 这个属性,修改为真实地址
- [liboozie]
- # The URL where the Oozie service runs on. This is required in order for
- # users to submit jobs. Empty value disables the config check.
- oozie_url=http://host1:11000/oozie
重启hue服务
访问hue中的oozie模块
点击 Workflow 可以看到工作流界面
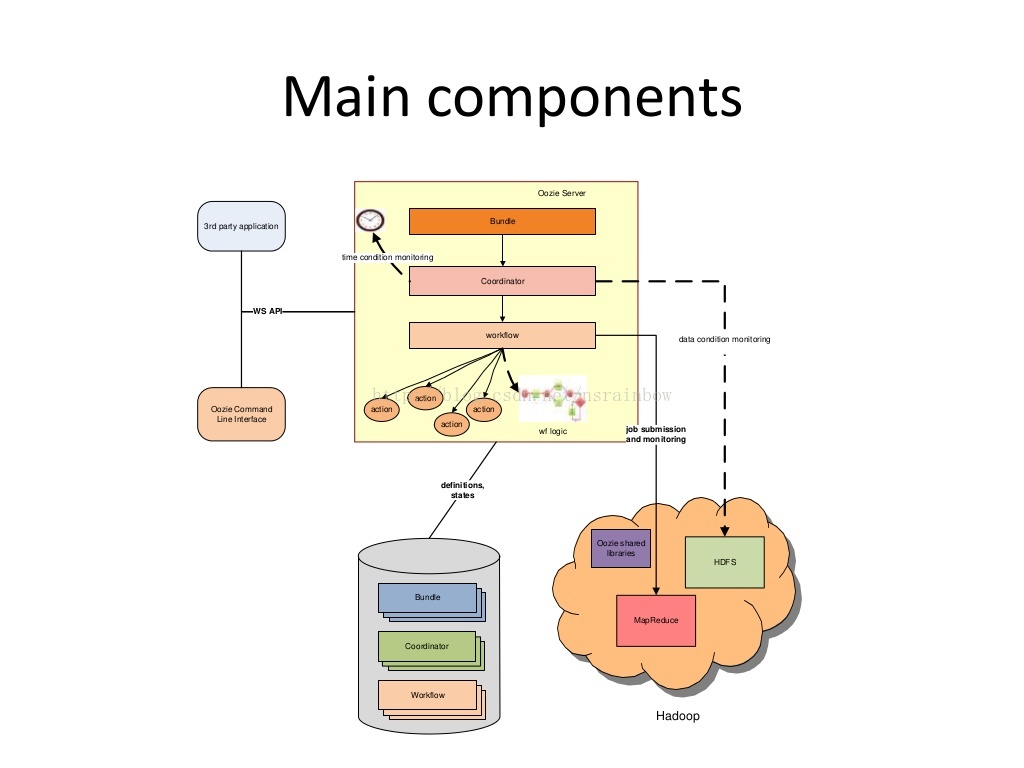
Oozie的3个概念
Oozie有3个主要概念
- workflow 工作流
- coordinator 多个workflow可以组成一个coordinator,可以把前几个workflow的输出作为后一个workflow的输入,也可以定义workflow的触发条件,来做定时触发
- bundle 是对一堆coordinator的抽象
以下这幅图解释了Oozie组件之间的关系
hPDL
oozie采用一种叫 hPDL的xml规范来定义工作流。
这是一个wordcount版本的hPDL的xml例子
- <workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.1">
- <start to='wordcount'/>
- <action name='wordcount'>
- <map-reduce>
- <job-tracker>${jobTracker}</job-tracker>
- <name-node>${nameNode}</name-node>
- <configuration>
- <property>
- <name>mapred.mapper.class</name>
- <value>org.myorg.WordCount.Map</value>
- </property>
- <property>
- <name>mapred.reducer.class</name>
- <value>org.myorg.WordCount.Reduce</value>
- </property>
- <property>
- <name>mapred.input.dir</name>
- <value>${inputDir}</value>
- </property>
- <property>
- <name>mapred.output.dir</name>
- <value>${outputDir}</value>
- </property>
- </configuration>
- </map-reduce>
- <ok to='end'/>
- <error to='end'/>
- </action>
- <kill name='kill'>
- <message>Something went wrong: ${wf:errorCode('wordcount')}</message>
- </kill/>
- <end name='end'/>
- </workflow-app>
这个例子可以用以下这幅图表示
一个oozie job的组成
一个oozie 的 job 一般由以下文件组成
- job.properties 记录了job的属性
- workflow.xml 使用hPDL 定义任务的流程和分支
- class 文件,用来执行具体的任务
任务启动的命令一般长这样子
- $ oozie job -oozie http://localhost:11000/oozie -config examples/apps/map-reduce/job.properties -run
可以看到 任务开始是通过调用 oozie job 命令并传入oozie服务器地址和 job.properties 的路径开始。job.properties 是一个任务的执行入口
做个MapReduce例子
这里使用官方提供的例子。
Step1
在 host1 上下载oozie包
- wget http://apache.fayea.com/oozie/4.1.0/oozie-4.1.0.tar.gz
解压开,里面有一个 examples文件夹,我们将这个文件夹拷贝到别的地方,并改名为
oozie-examples
进入这个文件夹,然后修改pom.xml,在plugins里面增加一个plugin
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-surefire-plugin</artifactId>
- <version>2.5</version>
- <configuration>
- <skipTests>false</skipTests>
- <testFailureIgnore>true</testFailureIgnore>
- <forkMode>once</forkMode>
- </configuration>
- </plugin>
然后运行 mvn package 可以看到 target 文件夹下有 oozie-examples-4.1.0.jar
Step2
编辑 oozie-examples/src/main/apps/map-reduce/job.properties
修改 namenode为hdfs 的namenode地址,因为我们是搭成ha模式,所以写成 hdfs://mycluster 。修改 jobTracker为 resoucemanager 所在的地址,这边为 host1:8032
改完后的 job.properties 长这样
- nameNode=hdfs://mycluster
- jobTracker=host1:8032
- queueName=default
- examplesRoot=examples
-
- oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/map-reduce
- outputDir=map-reduce
这里的 user.name 就是你运行oozie的linux 用户名,我用的是root,所以最后的路径会变成 hdfs://mycluster/user/root/examples/apps/map-reduce
Step3
根据上面配置的路径,我们在hdfs上先建立出 /user/root/examples/apps/map-reduce/ 目录
- hdfs dfs -mkdir -p /user/root/examples/apps/map-reduce
然后把 src/main/apps/map-reduce/workflow.xml 传到 /user/root/examples/apps/map-reduce 下面
- hdfs dfs -put oozie-examples/src/main/apps/map-reduce/workflow.xml /user/root/examples/apps/map-reduce/
在 /user/root/examples/apps/map-reduce/ 里面建立 lib 文件夹,并把 打包好的 oozie-examples-4.1.0.jar 上传到这个目录下
- hdfs dfs -mkdir /user/root/examples/apps/map-reduce/lib
- hdfs dfs -put oozie-examples/target/oozie-examples-4.1.0.jar /user/root/examples/apps/map-reduce/lib
在hdfs上建立 /examples 文件夹
- sudo -u hdfs hdfs dfs -mkdir /examples
把examples 文件夹里面的 src\main\apps 文件夹传到这个文件夹底下
- hdfs dfs -put examples/src/main/apps /examples
建立输出跟输入文件夹并上传测试数据
- hdfs dfs -mkdir -p /user/root/examples/input-data/text
- hdfs dfs -mkdir -p /user/root/examples/output-data
- hdfs dfs -put oozie-examples/src/main/data/data.txt /user/root/examples/input-data/text
Step4
运行这个任务
- oozie job -oozie http://host1:11000/oozie -config oozie-examples/src/main/apps/map-reduce/job.properties -run
任务创建成功后会返回一个job号比如 job: 0000017-150302164219871-oozie-oozi-W
然后你可以采用之前提供的 3 个连接oozie 的方法去查询任务状态,这里我采用HUE去查询的情况,点击最上面的 Workflow -> 仪表盘 -> Workflow
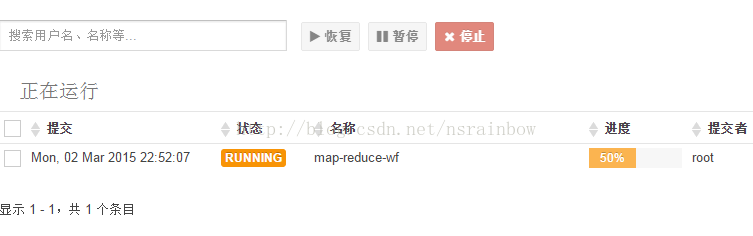
会看到有一个任务正在运行
点击后,可以实时的看任务状态,完成后会变成SUCCESS
这时候去看下结果 /user/root/examples/output-data/map-reduce/part-00000
- 0 To be or not to be, that is the question;
- 42 Whether 'tis nobler in the mind to suffer
- 84 The slings and arrows of outrageous fortune,
- 129 Or to take arms against a sea of troubles,
- 172 And by opposing, end them. To die, to sleep;
- 217 No more; and by a sleep to say we end
- 255 The heart-ache and the thousand natural shocks
- 302 That flesh is heir to ? 'tis a consummation
- 346 Devoutly to be wish'd. To die, to sleep;
- 387 To sleep, perchance to dream. Ay, there's the rub,
- 438 For in that sleep of death what dreams may come,
- 487 When we have shuffled off this mortal coil,
- 531 Must give us pause. There's the respect
- 571 That makes calamity of so long life,
- 608 For who would bear the whips and scorns of time,
- 657 Th'oppressor's wrong, the proud man's contumely,
- 706 The pangs of despised love, the law's delay,
- 751 The insolence of office, and the spurns
- 791 That patient merit of th'unworthy takes,
- 832 When he himself might his quietus make
- 871 With a bare bodkin? who would fardels bear,
- 915 To grunt and sweat under a weary life,
- 954 But that the dread of something after death,
- 999 The undiscovered country from whose bourn
- 1041 No traveller returns, puzzles the will,
- 1081 And makes us rather bear those ills we have
- 1125 Than fly to others that we know not of?
- 1165 Thus conscience does make cowards of us all,
- 1210 And thus the native hue of resolution
- 1248 Is sicklied o'er with the pale cast of thought,
- 1296 And enterprises of great pitch and moment
- 1338 With this regard their currents turn awry,
- 1381 And lose the name of action.
workflow.xml解析
我们把刚刚这个例子里面的workflow.xml打开看下
- <workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf">
- <start to="mr-node"/>
- <action name="mr-node">
- <map-reduce>
- <job-tracker>${jobTracker}</job-tracker>
- <name-node>${nameNode}</name-node>
- <prepare>
- <delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}"/>
- </prepare>
- <configuration>
- <property>
- <name>mapred.job.queue.name</name>
- <value>${queueName}</value>
- </property>
- <property>
- <name>mapred.mapper.class</name>
- <value>org.apache.oozie.example.SampleMapper</value>
- </property>
- <property>
- <name>mapred.reducer.class</name>
- <value>org.apache.oozie.example.SampleReducer</value>
- </property>
- <property>
- <name>mapred.map.tasks</name>
- <value>1</value>
- </property>
- <property>
- <name>mapred.input.dir</name>
- <value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>
- </property>
- <property>
- <name>mapred.output.dir</name>
- <value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>
- </property>
- </configuration>
- </map-reduce>
- <ok to="end"/>
- <error to="fail"/>
- </action>
- <kill name="fail">
- <message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
- </kill>
- <end name="end"/>
- </workflow-app>
最重要的就是里面的action 节点。
中间那段action 可以有支持几种类型的action
- Map-Reduce Action
- Pig Action
- Fs(HDFS) Action
- Java Action
- Email Action
- Shell Action
- Hive Action
- Sqoop Action
- Ssh Action
- DistCp Action
- 自定义Action
- sub-workflow (这个可以嵌套另外一个workflow.xml文件的路径)
具体见 http://oozie.apache.org/docs/4.1.0/WorkflowFunctionalSpec.html#a3.2_Workflow_Action_Nodes
这个简单的map-reduce 其实什么也没干,只是把文本一行的读取并打印出来。接下来我要把这个例子改成我们熟悉的WordCount例子
WordCount例子
Step1
先改一下我们的Mapper 和 Reducer 代码
修改SampleMapper为
- package org.apache.oozie.example;
-
- import java.io.IOException;
- import java.util.StringTokenizer;
-
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Mapper;
-
-
- public class SampleMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
-
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
-
-
- public void map(LongWritable key, Text value, Context context)
- throws IOException, InterruptedException {
-
- String line = value.toString();
- StringTokenizer tokenizer = new StringTokenizer(line);
-
- while (tokenizer.hasMoreTokens()) {
- word.set(tokenizer.nextToken());
- context.write(word, one);
- }
- }
-
- }
然后再把Reducer修改为
- package org.apache.oozie.example;
-
- import java.io.IOException;
-
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Reducer;
-
- public class SampleReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
-
- public void reduce(Text key, Iterable<IntWritable> values, Context context)
- throws IOException, InterruptedException {
-
- int sum = 0;
-
- for (IntWritable val : values) {
- sum += val.get();
- }
-
- context.write(key, new IntWritable(sum));
- }
-
- }
改好后用 mvn clean package 打包好,还是上传到 /user/root/examples/apps/map-reduce/lib 覆盖之前的那份jar
这边说一点题外话,关于MapReduce的old API跟new API的区别,这个跟我们这次的教程没关系,如果不感兴趣的同学可以直接跳过下面这一段
MapReduce 的 old API 跟 new API 区别
mapreduce 分为 old api 和 new api , new api废弃了 org.apache.hadoop.mapred 包下的 Mapper 和 Reducer,新增了org.apache.hadoop.mapreduce包,如果你手头有用旧api写的mp(mapreduce)任务可以通过以下几个改动修改为新的mp写法
- 将implements Mapper/Reducer 改为 extends Mapper/Reducer,因为new API 里 Mapper 和 Reducer不是接口,并且包的位置变成 org.apache.hadoop.mapreduce.Mapper
- OutputCollector 改为 Context
- map方法改成 map(LongWritable key, Text value, Context context) reduce 方法改成
具体见
Hadoop WordCount with new map reduce api
Step2
我们把之前的 src/main/apps/map-reduce/workflow.xml 修改一下成为这样
- <workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf">
- <start to="mr-node"/>
- <action name="mr-node">
- <map-reduce>
- <job-tracker>${jobTracker}</job-tracker>
- <name-node>${nameNode}</name-node>
- <prepare>
- <delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}"/>
- </prepare>
- <configuration>
-
- <property>
- <name>mapred.mapper.new-api</name>
- <value>true</value>
- </property>
- <property>
- <name>mapred.reducer.new-api</name>
- <value>true</value>
- </property>
-
- <property>
- <name>mapred.output.key.class</name>
- <value>org.apache.hadoop.io.Text</value>
- </property>
- <property>
- <name>mapred.output.value.class</name>
- <value>org.apache.hadoop.io.IntWritable</value>
- </property>
-
- <property>
- <name>mapreduce.inputformat.class</name>
- <value>org.apache.hadoop.mapreduce.lib.input.TextInputFormat</value>
- </property>
- <property>
- <name>mapreduce.outputformat.class</name>
- <value>org.apache.hadoop.mapreduce.lib.output.TextOutputFormat</value>
- </property>
-
- <property>
- <name>mapred.job.queue.name</name>
- <value>${queueName}</value>
- </property>
- <property>
- <name>mapreduce.map.class</name>
- <value>org.apache.oozie.example.SampleMapper</value>
- </property>
- <property>
- <name>mapreduce.reduce.class</name>
- <value>org.apache.oozie.example.SampleReducer</value>
- </property>
- <property>
- <name>mapred.map.tasks</name>
- <value>1</value>
- </property>
- <property>
- <name>mapred.input.dir</name>
- <value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>
- </property>
- <property>
- <name>mapred.output.dir</name>
- <value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>
- </property>
- </configuration>
- </map-reduce>
- <ok to="end"/>
- <error to="fail"/>
- </action>
- <kill name="fail">
- <message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
- </kill>
- <end name="end"/>
- </workflow-app>
我把中间的action 里面的属性替换了,我说明一下几个重要属性
- mapred.mapper.new-api 和 mapred.reducer.new-api 意思是是否要使用new API,我们这边设置为true
- mapred.output.key.class 和 mapred.output.value.class 意思是 mapper的输出类型
- mapreduce.map.class 和 mapreduce.reduce.class 这两处连属性名都修改了,可能很多人会发现不了,之前是 mapred.mapper.class 和 mapred.reducer.class ,如果你只改了value就会出错,说new API的属性里面没有这两个属性
然后我们把workflow.xml上传到hdfs上
- hdfs dfs -put -f oozie-examples/src/main/apps/map-reduce/workflow.xml /user/root/examples/apps/map-reduce/
Step3
我们把素材准备一下,还是之前做 wordcount 用的 file0 和 file1
- $ echo "Hello World Bye World" > file0
- $ echo "Hello Hadoop Goodbye Hadoop" > file1
- $ hdfs dfs -put file* /user/root/examples/input-data/text
顺便把之前的data.txt删掉
- hdfs dfs -rm /user/root/examples/input-data/text/data.txt
Step4
我们来运行一下这个job
- oozie job -oozie http://host1:11000/oozie -config oozie-examples/src/main/apps/map-reduce/job.properties -run
执行完后到 / user/ root/ examples/ output-data/ map-reduce/ part-r-00000 查看我们的结果
- Bye 1
- Goodbye 1
- Hadoop 2
- Hello 2
- World 2
完成!
参考资料
- http://www.infoq.com/cn/articles/introductionOozie
- http://www.infoq.com/cn/articles/oozieexample
- https://github.com/yahoo/oozie/wiki/Oozie-Coord-Use-Cases
- https://oozie.apache.org/docs/3.1.3-incubating/CoordinatorFunctionalSpec.html#a2._Definitions
- http://oozie.apache.org/docs/4.1.0/DG_Examples.html
- https://github.com/jrkinley/oozie-examples
- http://codesfusion.blogspot.com/2013/10/hadoop-wordcount-with-new-map-reduce-api.html
- https://support.pivotal.io/hc/en-us/articles/203355837-How-to-run-a-Map-Reduce-jar-using-Oozie-workflow


























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









