







一、背景
一个完整的数据分析系统通常是由大量的任务单元组成,Shell脚本、Java程序、MapReduce程序、Hive脚本等等,各个任务单元之间存在时间先后及前后依赖关系。
为了很好的组织这样的复杂执行计划,需要一个工作流调度系统来调用执行。
简单的工作流调度:Liunx的crontab来定义
复杂的工作流调度:Oozie、Azakaban等。
在没有工作流调度系统之前,公司里面的任务都是通过 crontab 来定义的,时间长了后会发现很多问题:
1.大量的crontab任务需要管理
2.任务没有按时执行,各种原因失败,需要重试
3.多服务器环境下,crontab分散在很多集群上,光是查看log就很花时间
而在大数据领域,现在市面上常用的工作流调度工具有Oozie, Azkaban,Cascading等,
Oozie和Azkaban来做对比:
两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
- 工作流定义: Oozie是通过xml定义的,而Azkaban为properties来定义。
- 部署过程: Oozie的部署相对困难些,同时它是从Yarn上拉任务日志。
- 任务检测: Azkaban中如果有任务出现失败,只要进程有效执行,那么任务就算执行成功,这是BUG,但是Oozie能有效的检测任务的成功与失败。
- 操作工作流: Azkaban使用Web操作。Oozie支持Web,RestApi,Java API操作。
- 权限控制: Oozie基本无权限控制,Azkaban有较完善的权限控制,供用户对工作流读写执行操作。
- 运行环境: Oozie的action主要运行在hadoop中,而Azkaban的actions运行在Azkaban的服务器中。
- 记录workflow的状态: Azkaban将正在执行的workflow状态保存在内存中,Oozie将其保存在Mysql中。
- 出现失败的情况: Azkaban会丢失所有的工作流,但是Oozie可以在继续失败的工作流运行
二、什么是Oozie?
Oozie(驯象人)是一个基于工作流引擎的开源框架,用在一个工作流内以一个特定顺序运行一组工作或流程。
Oozie在集群中扮演的是定时调度任务,多任务,并开源按照业务逻辑顺序调度。
组成
Workflow:顺序执行流程节点,执行分支多节点或合并多分点为一个分支。
Coordinator:定时触发Workflow
BundleJob:绑定多个Coordinator
Oozie节点
控制流节点(Control Flow Nodes):一般都是定义在工作流开始或结束,比如start、end、kill等,以及提供工作流的执行路径。
动作节点(Action Nodes):执行具体动作的节点。
三、Oozie的基本操作:
# 运行一个应用:
bin/oozie job -oozie http://nameNode:11000/oozie -config examples/apps/map-reduce/job.properties -run
# 杀掉一个job
bin/oozie job -oozie http://nameNode:11000/oozie -kill 0000001-160702224410648-oozie-beif-W
# 查看job的日志信息
bin/oozie job -oozie http://nameNode:11000/oozie -log 0000001-160702224410648-oozie-beif-W
# 查看job的信息
bin/oozie job -oozie http://nameNode:11000/oozie -info 0000001-160702224410648-oozie-beif-W操作准备;
| job.properties | 任务的一些配置文件,绑定多个 Coordinator。例如运行的HDFS以及JobTracker(ResourceManager)等 |
| Workflow.xml | 工作流的依赖,配置顺序执行流程节点,支持 fork(分支多个节点),join(合并多个节点为一个) |
| coordinator.xml | 定时触发 workflow,在这里可以设定触发oozie任务的时间和间隔 |
| ****.jar | 执行任务的jar包(自定义的文件) |
oozie工作流调度的设置总结
1 解压
cd /export/servers/oozie-4.1.0-cdh5.14.0
tar -zxf oozie-examples.tar.gz
2 拷贝该任务的模板
3 修改job.properties 文件
4 修改workfolw.xml的文件
5 上传已配置好的文件上传的hdfs上
6 执行任务
案例
job.properties
#NameNode地址
nameNode=hdfs://node01:8020 #端口8082
#ResourceManager地址,默认端口8032
jobTracker=node01:8032
#内部的Event队列名称
queueName=default
examplesRoot=oozie-apps #这是一个参数变量 在workflow.xml中会用到
#是否使用系统依赖包 一般都是填true
oozie.use.system.libpath=true
#程序位置hdfs // workflow.xml的地址
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shell
#coordinator.xml在hdfs的位置
#oozie.coord.application.path=${nameNode}/home/ssh_jobs/test_init_and_load
#执行这个脚本
EXEC1=test1.sh
EXEC2=test2.sh
#任务开始时间与结束时间 以UTC时区为准(start:必须设置为未来时间,否则任务失败)
start=2020-12-25T10:10+0800
end=2026-12-21T23:59+0800workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.3" name="shell-wf">
<start to="get_var"/>
<action name="get_var">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC1}</exec>
<file>/user/admin/oozie-apps/shell/${EXEC1}#${EXEC1}</file>
<capture-output/>
<argument>hi shell in oozie</argument>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
<workflow-app xmlns="uri:oozie:workflow:0.4" name="cip_poi_etl_workflow">
<start to="get_var"/>
<action name="get_var">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC1}</exec>
<file>/user/admin/oozie-apps/shell/${EXEC1}#${EXEC1}</file>
<!--
<exec>input.sh</exec>
<file>input.sh</file>
-->
<capture-output/> <!--它的作用是是告诉oozie,这个action的输出要被oozie运行存储下来。 -->
</shell>
<ok to="use_var" />
<error to="send_email" />
</action>
<action name="use_var">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>output.sh</exec>
<!--它的作用是说我要调用“get_var”这个action捕捉到的那个输出的其中一个参数。 -->
<argument>${wf:actionData('get_var')['var']}</argument>
<file>output.sh</file>
</shell>
<ok to="end" />
<error to="send_email" />
</action>
<action name="send_email">
<email xmlns="uri:oozie:email-action:0.1">
<to>${emailTo}</to>
<subject>Status of workflow ${wf:id()}</subject>
<body>The workflow ${wf:id()} had issues and was killed. The error message is: ${wf:errorMessage(wf:lastErrorNode())}</body>
</email>
<ok to="fail"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Failed, Error Message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>input.sh
echo var=var_test_result
output.sh
hadoop fs -mkdir /user/hue/$1test1.sh
#!/bin/bash
/usr/bin/date > /tmp/test.log
/usr/bin/date > /tmp/test.log执行:
上传到HDFS:
hdfs dfs -put oozie-apps/* /user/admin/oozie-apps/shell/执行任务:
bin/oozie job -oozie http://node01:11000/oozie -config oozie-apps/shell/job.properties -run使用注意事项
[if !supportLists]1. [endif]启动不了,则到oozie-server/temp查看是否有*.pid文件,有就删除后在启动。
[if !supportLists]2. [endif]如果无法关闭oozie则kill掉。
[if !supportLists]3. [endif]Mysql配置如果没有生效的话,默认使用derby数据库
[if !supportLists]4. [endif]在本地修改完成的job配置,必须重新上传到HDFS。
[if !supportLists]5. [endif]Linux用户名和Hadoop的用户名不一致。
[if !supportLists]6. [endif]时区
四、在hue当中操作ooize的操作,如何使用Hue上创建一个完整Oozie工作流
在hue当中操作ooize的操作:
Hue是一个可快速开发和调试Hadoop生态系统各种应用的一个基于浏览器的图形化用户接口。
Hue可实现对oozie任务的开发,监控,和工作流协调调度 。使的oozie的操作变得更加的简单快捷。
(1)创建工作流
(1)添加到定制执行任务。指定定时任务。
一、在hue当中操作ooize的操作
进入hue首页:

Workflow是工作流,Schedule是调度工作流的,如设置工作流何时跑,周期是多久,等等,下面会详细介绍,Bundle是绑定多个调度,暂时我没有用上
等使用后再更新
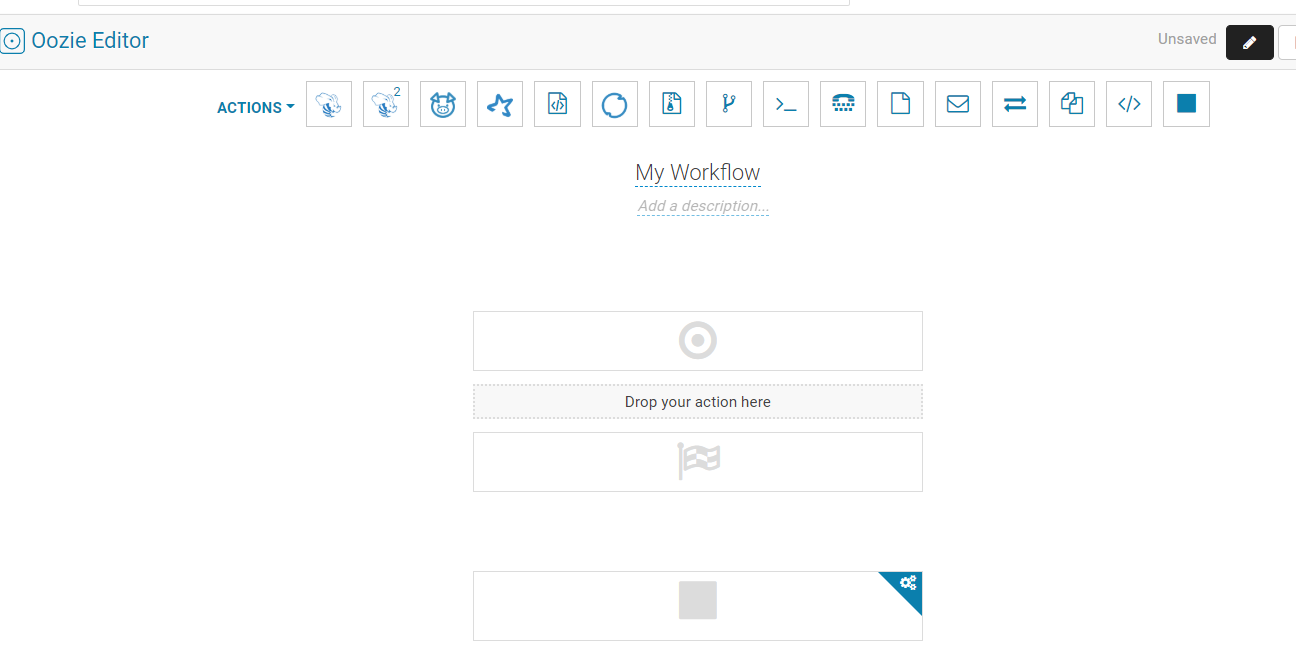
上面有一栏,有hive,hive2,spark,java,shell等等,直接拖入到Drop your action here这个阴影框中即可
下面的都以hive2为例,
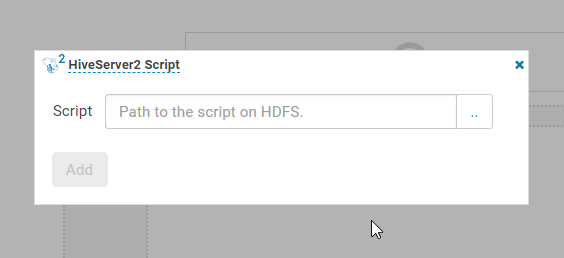
选择文件添加即可,同时下面还有很多选项
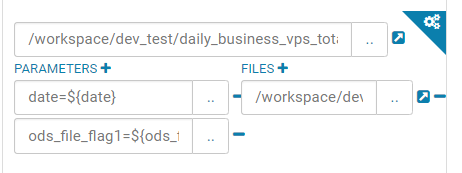
友情提示,虽然已经选择了文件,但是我建议还是在选择一次,右边的是添加文件依赖,
左边是参数设置,比如工作流按时间跑,设置是时间等等,根据需求设置即可

工作流建立完成之后,单个脚本或者代码可以单独执行,进行测试,再右上角
或者整个工作流进行运行,也是在右上角
这是工作流的配置,下面讲调度
进入调度

选择一个workflow工作流
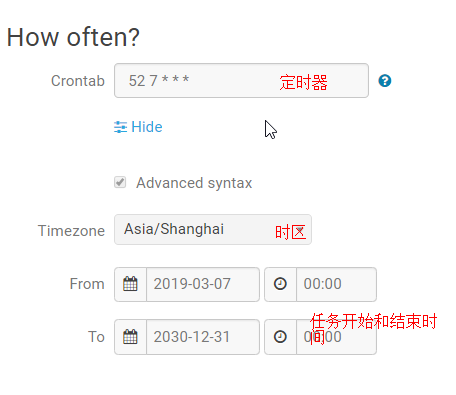
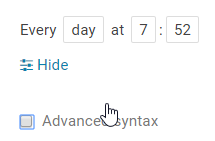
注意hue,oozie是有时区的设置的,默认是零时区时间,换成东八区时间要+8小时,设置配置时间同步
由于公司没有设置,所以是在建立调度上自己注意的,这里的时间都是零时区的时间
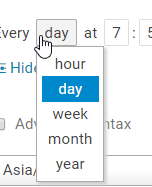 可以按小时,天,周,月,年进行定时调度
可以按小时,天,周,月,年进行定时调度
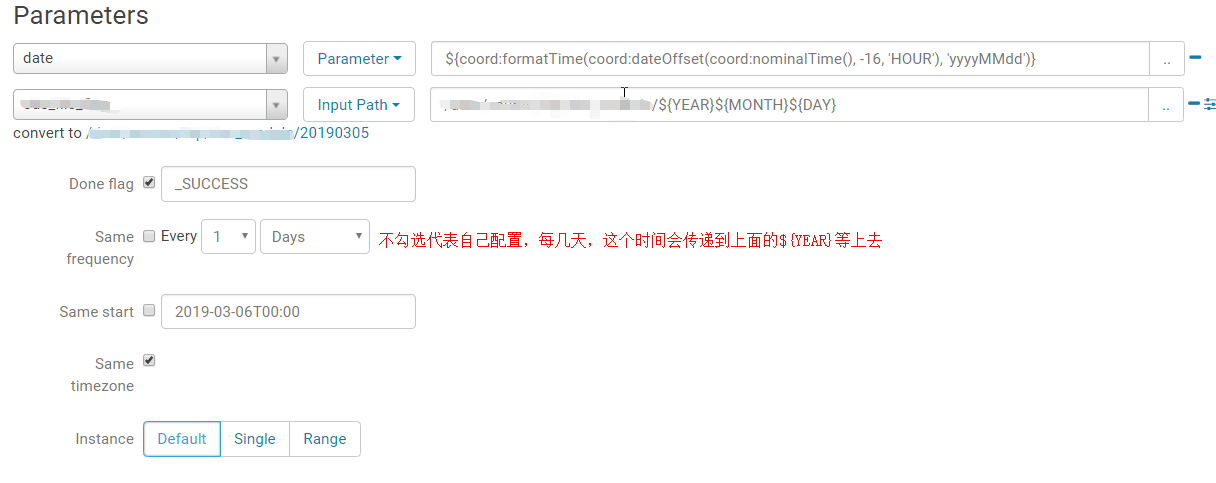
因为是今天跑昨天的数据,所以数据是昨天的,时间要减,因为是零时区的时间和东八区的时间差了8个小时,所以减了16个小时
下面的是输入文件,起到标识作用,有了这个文件任务才能启动,也是一种依赖文件
还有一种情况
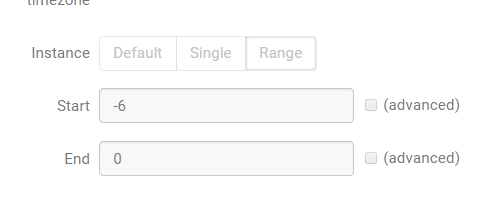
如果是周计划,或者月计划,需要依赖多个,如7个,30个文件,不可能一一配置
选择上面的range,-6代表从任务执行的是时间-6,因为时区原因,如果是星期一启动任务,则到了上周星期一,0到了上周日
这是跑周计划中依赖一周的文件,其他情况可以参考上面的,可能会一些时区或者平台的问题有一些出入,配置根据具体情况而定
任务运行后可以查看执行情况: 在右上角,
在右上角,

自己选择查看类型,里面也有日志,执行task,执行参数,时间等等
二、本篇文章主要讲述如何使用Hue创建一个以特定顺序运行的Oozie工作流。
本文工作流程如下:

2.创建一个Parquet格式的Hive表
创建一个Hive表,该表用于Spark作业保存数据,注意这里创建的Parquet格式的表
create table testaaa (
'_age' bigint COMMENT '',
'_id' bigint COMMENT '',
'_name' string COMMENT ''
) STORED AS parquet3.Sqoop抽数作业
这里的Sqooop抽数以MySQL为例。
1.创建一个MySQL的测试账号及准备测试数据
CREATE USER 'testuser'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON *.* TO 'testuser'@'%';
FLUSH PRIVILEGES;

向表中插入数据
insert into test_user (name,age) values('user1', 12);
insert into test_user (name,age) values('user2', 13);
insert into test_user (name,age) values('user3', 14);
insert into test_user (name,age) values('user4', 15);
insert into test_user (name,age) values('user5', 16);
insert into test_user (name,age) values('user6', 17);
insert into test_user (name,age) values('user7', 18);
insert into test_user (name,age) values('user8', 19);
2.Sqoop抽数脚本
sqoop import \
--connect jdbc:mysql://ip-172-31-22-86.ap/test_db
--username username \
--password password \
--table test_user \
--target-dir /tmp/sqoop \
-m 14.Spark ETL作业
将Sqoop抽取的数据通过Python的Spark作业进行ETL操作写入Hive表中
1.编写Spark脚本
#!/usr/local/anaconda3/bin/python
#coding:utf-8
# 初始化sqlContext
from pyspark import SparkConf,SparkContext
from pyspark.sql import HiveContext,Row
conf=(SparkConf().setAppName('PySparkETL'))
sc=SparkContext(conf=conf)
sqlContext = HiveContext(sc)
# 加载文本文件并转换成Row.
lines = sc.textFile("/tmp/sqoop/part-*")
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: Row(id=int(p[0]),name=p[1], age=int(p[2])))
# 将DataFrame注册为table.
schemaPeople = sqlContext.createDataFrame(people)
schemaPeople.registerTempTable("people")
sqlContext.cacheTable("people")
# 执行sql查询,查下条件年龄在13岁到16岁之间
teenagers = sqlContext.sql("SELECT * FROM people WHERE age >= 13 AND age <= 16")
teenagers.write.saveAsTable("testaaa", mode="append")5.Hive查询作业
将Spark作业处理后的数据写入hive表中,使用Hive对表进行查询操作
编写hive-query.sql文件,内容如下:
select * from testaaa where age>=10 and age<=15
6.创建工作流
1、进入Hue界面,选择”Workflows” => “Editors”=> “Workflows”

2、在以下界面中点击“Create”按钮创建工作流

3.然后进入WrokSpace

4.在工作流中添加Sqoop抽数作业

5.添加PySpark ETL工作流

5.添加Hive工作流

如下是一个完成的工作流

7.工作流运行
1.工作流保存成功后,点击运行

2.Oozie调度任务执行成功
 8.作业运行结果查看
8.作业运行结果查看
Sqoop抽数结果查看

Spark ETL执行成功查看Hive表testaaa数据

Hive作业执行结果查看

















 1724
1724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











