







一、前置介绍
通过分析影响数据库性能的因素,才能找到问题根源,进而才能来进行对应的优化,最终以获得良好的数据库性能。
针对于双11大促来讲,最大压力的是web服务器和数据库服务器,而web服务器可以很容易的进行横向的扩展,但数据库服务器因为要保证数据的完整性和一致性,使得数据库服务器进行横向扩展并不是那么可以轻而易举。
当时公司的数据库架构为1台Master ,15台slave,中间没有任何的主从复制组件,也就是当Master宕机或者发生故障时,只能通过DBA手动的从Slave中选出来一台新Master,同时其他的Slave还要重新的同步新的Master信息,而且这么多从服务器在业务量大的时候对主服务器的网卡容量也是个很大的挑战,很容易引起故障。
接下来我们看下在双十一大促中的监控信息,通过监控信息,我们可以分析下具体是什么因素影响了数据库的性能(以下监控图均为一台主服务器上的数据,该服务器CPU:64核 ;内存:512GB ;磁盘IO:fashion IO):
监控图1(QPS&TPS ):

QPS达到35w,TPS将近10w ,如此性能是进行过大量的优化,最起码的sql性能很好
监控图2(并发量&CPU使用率):

并发量:指同一时间处理请求的数量(这里要与「同时连接数」区分开);
idle(空闲百分比):值越高空闲率越高。
监控图3( 磁盘IO):

因为使用fashion IO 所以吞吐量比普通磁盘要高 。而图中峰值造成的原因是因为数据库备份远程同步计划任务造成的,得到的教训就是:
1.最好不要在主库上数据库备份
2.大型活动过前取消这类的计划
二、影响数据库性能的因素
一、通过以上监控图,我们总结影响数据库性能的比较大的几点因素:
1.sql查询速度
2.服务器硬件(CPU、内存)
3.网卡流量
4.磁盘IO
二、接下来我们具体看看这些因素造成的影响都有哪些:
1.超高的QPS和TPS
风险来源:效率低下的SQL
什么是QPS:每秒钟处理的查询量
当前的MySQL版本中暂时还不支持多CPU并发运算,也就是说一个sql只能用到一个CPU,我们常用QPS和TPS来衡量sql的处理效率。比如我们只有一个CPU,10ms处理了1个sql,那么1s就处理100个sql,此时我们就说QPS<=100;而100ms处理1个sql,那么1s就处理10个sql,QPS<=10,所以一个sql执行10ms和执行100ms是有着天壤之别的。根据经验对数据库造成影响的百分之八十原因都是慢查询造成的,也就是说大部分的数据库性能问题都可以通过sql优化来解决。
2.大量的并发和超高的CPU使用率
风险来源:大量的并发会导致数据库连接数被占满,超高的CPU使用率会使CPU资源耗尽而出现宕机
数据库连接数在MySQL中由max_connections来设置,默认为100
3.磁盘IO
风险来源:磁盘IO性能的突然下降,其他大量消耗磁盘性能的计划任务
磁盘IO性能的突然下降,通常我们解决这个问题是使用更快的磁盘设备。消耗磁盘性能的计划任务,通常我们解决这个问题会调整计划任务,做好磁盘的维护
4.网卡流量
风险来源:网卡IO被占满(1000Mb/8约等于100MB)
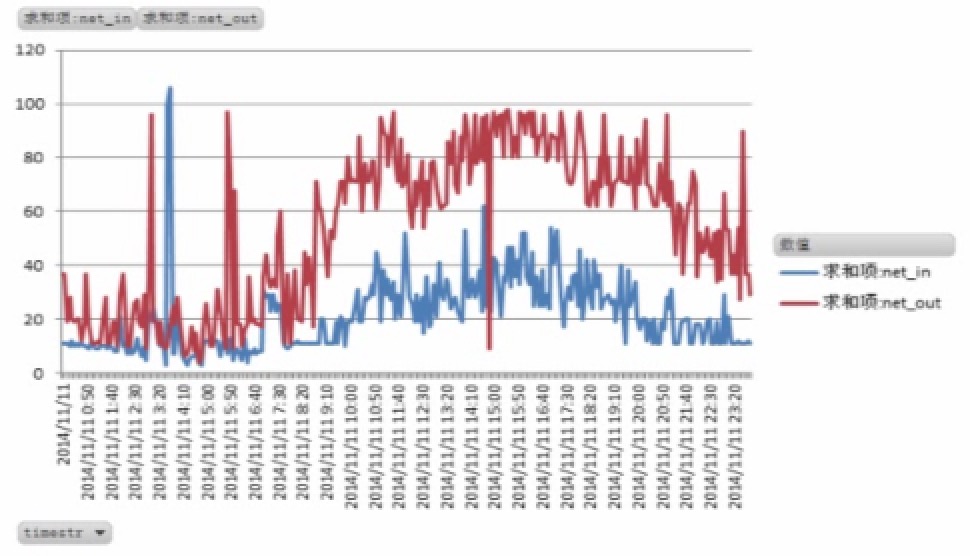
图中网卡IO多次达到峰值,如果有新的连接要查询数据,则会出现无法连接数据库的情况。
如何避免网卡流量造成的无法连接数据库的情况:
1.减少从服务器数量
2.进行分级缓存
3.避免使用“select *”进行查询,查询出没有必要的列也会很耗费流量
4.分离业务网络和服务器网络
三、其他影响数据库性能的问题
一、大表给我们带来的问题
什么样的表称之为大表呢?这是相对而言的,一般来说在我们使用过程中,数据超过千万条的时候,就会对数据库性能造成影响,这样我们就通过两个维度来对大表进行定义:1.记录行数巨大,单表超过千万行;2.表数据文件巨大,表文件数据超过了10G。当然这还是相对而言的,还要根据磁盘IO,业务等来进行判定,比如有张操作日志表,我们只有insert语句,以及极少的select,没有update和delete操作,就算超过了千万行也不会对我们的业务产生什么影响。
1.大表对查询的影响:
慢查询:很难在一定的时间内过滤出所需要的数据
2.大表对DDL操作(数据定义)的影响:
1.建立索引时间需要很长时间
风险:
MySQL版本<5.5建立索引会锁表
MySQL版本>=5.5虽然不会锁表但是会引起主从延迟
2.修改表结构需要长时间锁表
风险:
会造成长时间的主从延迟
影响正常的数据操作
3.如何处理数据库中的大表:
1.分库分表把一张大表分成多个小表
难点:
分表键的选择
分表后跨分区数据的查询和统计
2.大表的历史数据归档(减少了对前后端业务的影响)
难点:
归档时间点的选择
如何进行归档操作(当归档了百万条数据,如何在原来的数据库中安全可靠,不会造成查询阻塞且不影响主从延迟的删除)
二、大事务给我们带来的问题
1.什么是事务
1.事务是数据库系统区别于其他一切文件系统的重要特性之一
2.事务是一组具有原子性的SQL语句,或是一个独立的工作单元
2.事务四个特性:
1.原子性:一个事务必须视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败,对于一个事务来说,不可能只执行其中的一部分操作。
2.一致性:一致性是指事务将数据库从一种一致性状态转换到另一种一致性状态,在事务开始之前和事务结束后数据库中数据的完整性没有被破坏。
3.隔离性:隔离性要求一个事务对数据库中数据的修改,在未提交完成前对于其他的事务是不可见的。SQL标准中定义了四种隔离级别(隔离性由低到高分别为未提交度即“脏读”、已提交读、可重复读、可串行化),隔离性由低到高,并发性却是由高到低。
show variables like '%iso%' 可以查看隔离级别
set session tx_isolation='read-committed' 可以设置隔离级别
4.持久性:一旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,已提交的修改数据也不会丢失。
3.什么是大事务
定义:运行时间比较长,操作的数据比较多的事务。
造成的风险:
1.锁定太多的数据,造成大量的阻塞和锁超时
2.回滚时间比较长,回滚时,数据仍被锁定
3.执行时间长,容易造成主从延迟
当然以上三种风险只是比较重要的风险,实际情况中也会遇到其他的问题。
4.如何处理大事务
1.避免一次处理(增删改查)太多的数据,可以分批次的进行操作
2.移出不必要在事务中的select操作,大部份事务执行时间比较长的情况都是因为事务中使用了大量的查询操作,将不必要的查询操作移出,保证事务中只有必要的写操作
四、总结
直观的展示了数据库在繁忙时的系统状态,简单了解了对性能有影响的一些因素。















 4832
4832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









