








前言:使用python+scrapy框架爬取蚂蜂窝旅游攻略
Git代码地址:https://github.com/qijingpei/mafengwo
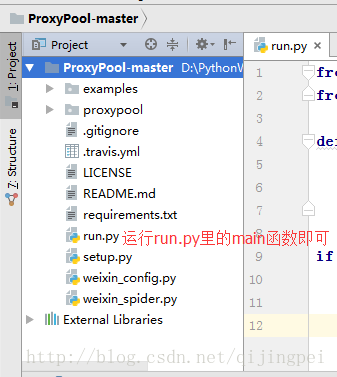
获取代理IP地址的开源项目ProxyPool-master(地址应该是这个):
https://github.com/Sylor-huang/ProxyPool-master
运行步骤:
1.配置好代码中连接mysql数据库的用户名和密码,按项目中的sql文件创建数据库和表
2.运行run.py获取动态代理IP
3.在Pycharm的terminal命令行窗口输入:Scrapy crawl mfw来启动爬虫
3.等数据库中的数据足够时,运行parse_str_url来获取每个攻略的时间等信息
爬取策略分析
1.第一步:爬取中国所有的城市
(1)中国城市界面:http://www.mafengwo.cn/mdd/citylist/21536.html
在这里获取城市id和每个城市的链接

(2)然后对城市进行“翻页”:
利用浏览器的开发者工具,可以看到请求的两个参数:middid代表国家,page代表页数,所以我们通过改变page来翻页
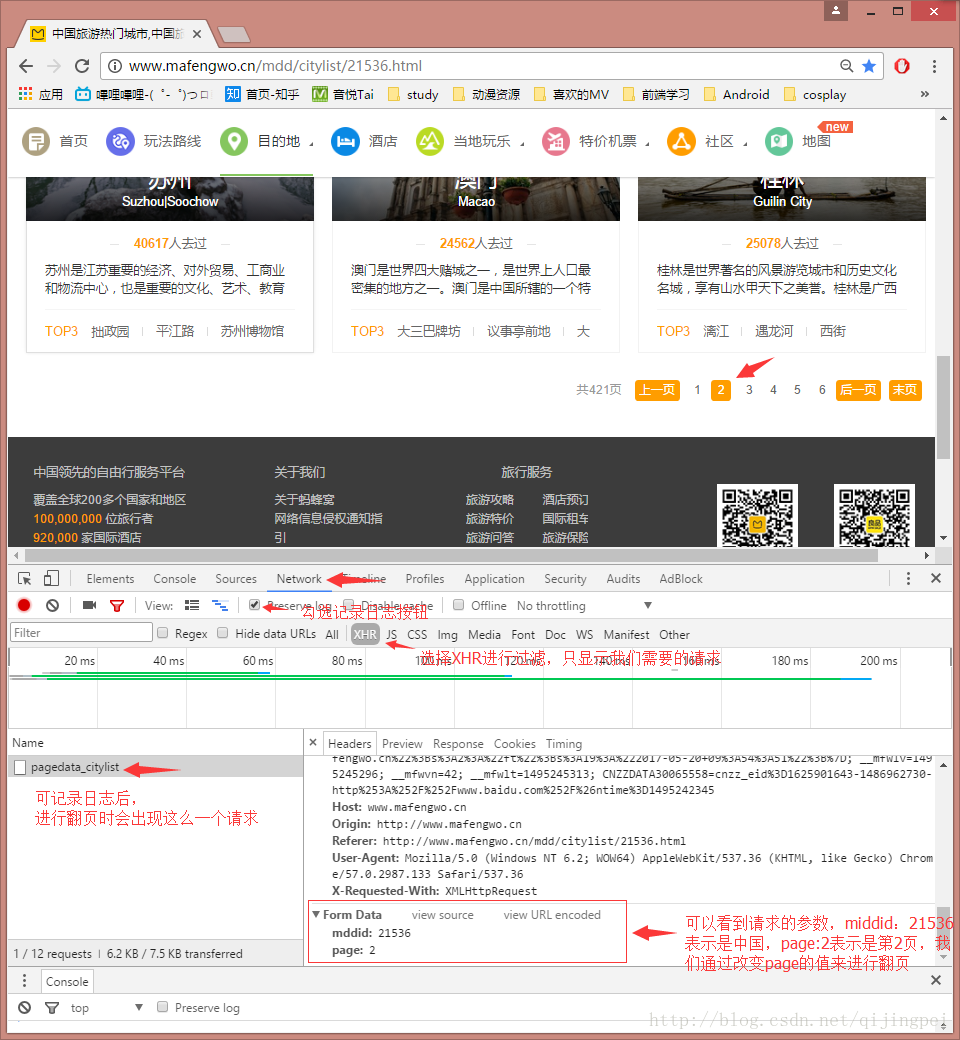
即将url链接拼凑成这个样子:

2.第二步:获取所有的攻略的链接
(1)我们不从城市的介绍页面获取攻略,而是从攻略界面直接获取,因为这样更简单一些,攻略界面的url为:
http://www.mafengwo.cn/yj/10189/1-0-4.html
yj表示攻略,10189是城市id,1-0-4中的最后一位是页数,范围为1~200
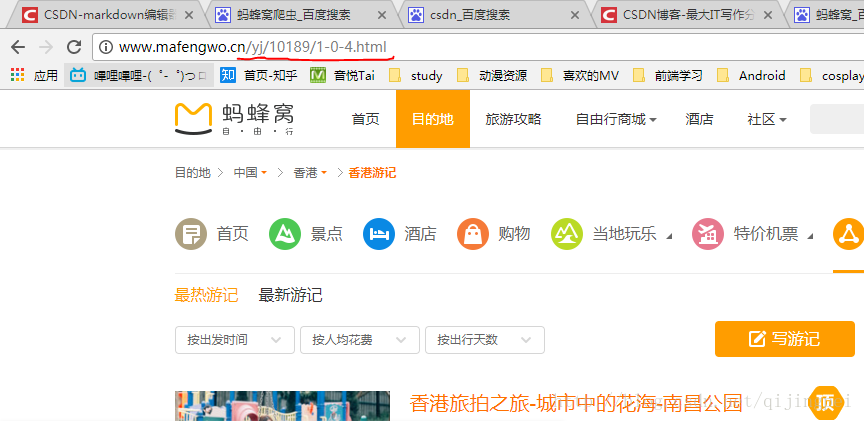
3.第三步:得到攻略的链接后,
(1)让爬虫访问这个链接,就可以获取到旅游攻略、花费、出行天数等信息了:
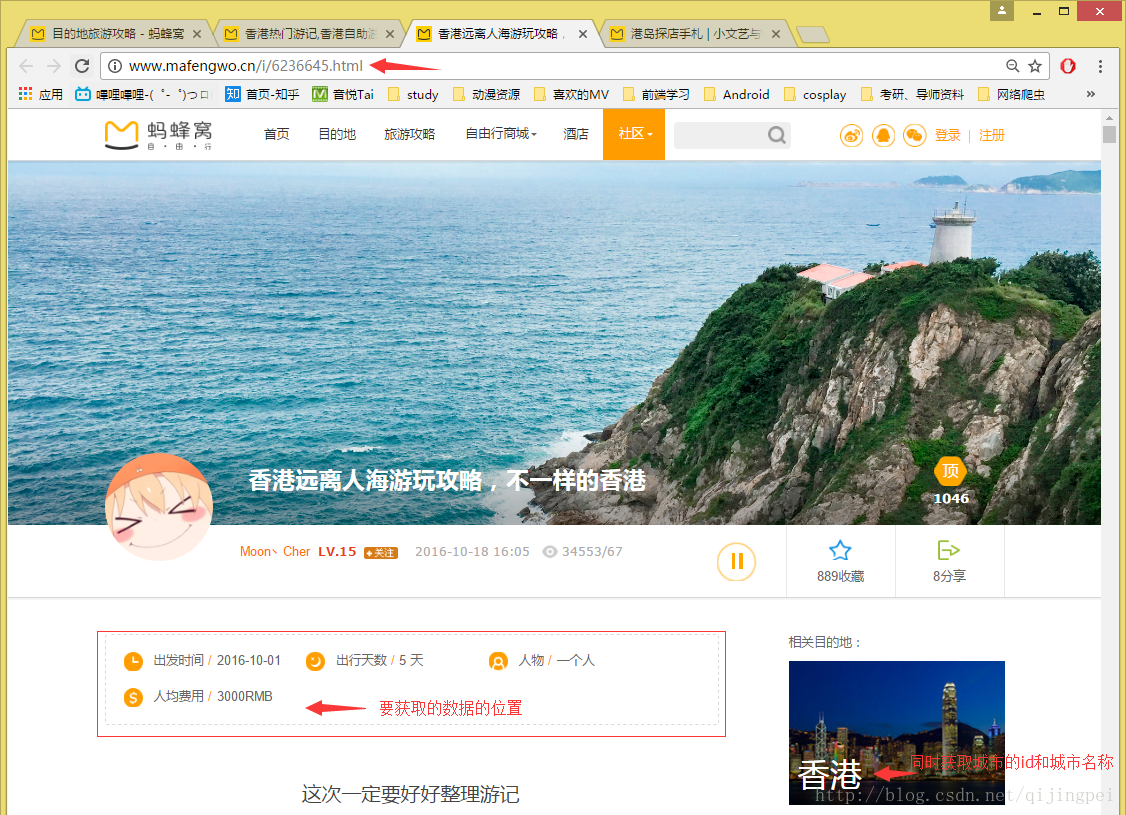
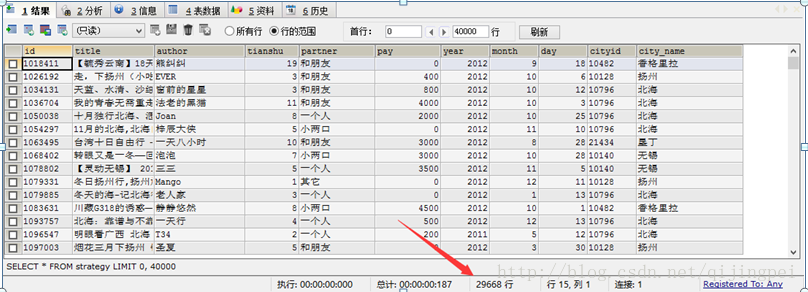
(2)存储到数据库,我使用的是MySQL数据库,也可以用mongoDB,都可以~
存储结果是:(我没有存攻略的文章内容,只存了时间等,可以根据自己的需求调整)
Scrapy框架相关的代码解读
包结构:
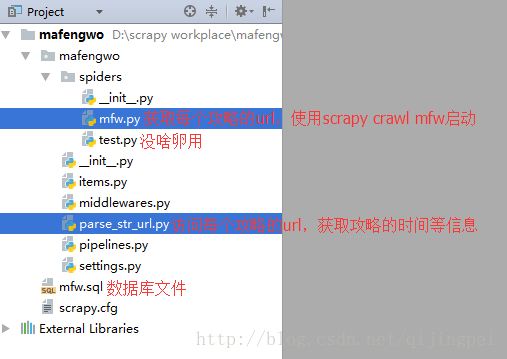
我们通过一个开源项目ProxyPool-master来获取代理IP地址:
主要的代码(可读性较差,时隔半年有些也忘记了):
mfw.py(获取所有攻略的url):
# -*- coding: utf-8 -*-
import json
import re
import requests
from scrapy import Request, Spider
from mafengwo.items import StrategyItem, CityItem, Str_urlItem
'''
注明:控制台最后输出的大量的403错误,是正常的,这些403错误的网页已经被再次访问直到爬取到数据,
所以不用担心
'''
class MfwSpider(Spider):
name = "mfw"
allowed_domains = ["www.mafengwo.cn"]
start_urls = ['http://www.mafengwo.cn/']#这里要写成....cn而不是.com,不然解析不了攻略
cities_url = 'http://www.mafengwo.cn/mdd/citylist/21536.html?mddid=21536&page={page}'
test_str_url = 'http://www.mafengwo.cn/i/6536459.html'#单个攻略的url
test_str_url2 = 'http://www.mafengwo.cn/i/5320703.html'#没有静态显示而是用js显示的出发时间的攻略
test_str_list_url = 'http://www.mafengwo.cn/yj/10065/1-0-1.html'
PROXY_POOL_URL = 'http://127.0.0.1:5000/get'
MAX_COUNT = 5
proxy = None# 建立一个全局的变量,来存代理
#proxy = '185.35.67.191:1189'
#proxy = '127.0.0.1:5000'
# proxy = '163.172.211.176:3128'
# proxies = {
# 'http': 'http://' + proxy # requests.get()方法中代理用字典类型,而scrapy的代理则稍有不同
# }
str_count = 0
def get_proxy(self):#获得代理
try:
response = requests.get(self.PROXY_POOL_URL)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
print('获取代理时发生异常')
return None
def get_html(self, url, count=1):# count默认值为1,如果有赋值则不使用默认值
print('正在抓取', url)
print('Trying Count', count)
if count >= self.MAX_COUNT:
print('Tried Too Many Counts')
return None
try:
if self.proxy==None :# 如果代理不存在
self.proxy = self.get_proxy()
proxies = {
'http': 'http://' + self.proxy
}
print('使用了代理:', self.proxy)
response = requests.get(url, allow_redirects=False, proxies=proxies)#可以设定超时时间30s
if response.status_code == 200:
return response.text
else:
# 更换代理,重新访问
print('302/403等错误')
self.proxy = self.get_proxy()#获得新代理
if self.proxy:
print('Using Proxy', self.proxy)
count = count + 1
return self.get_html(url, count)#更改后的代理,也可能不能用
else:
print('Get Proxy Failed')
return None# 没有可用代理的时候返回none
except ConnectionError as e:
print('Error Occurred', e.args)# 输出错误信息
self.proxy = self.get_proxy()
count += 1
return self.get_html(url, count)
# 构建scrapy初始的请求
def start_requests(self):
#self.get_total_city_pages()
self.proxy = self.get_proxy()
#total = self.get_total_city_pages()#获取城市总页数
total = 400
print('城市总页数:'+str(total))#能够正确输出,注意如果不提交请求的话系统会报错误:TypeError: 'NoneType' object is not iterable,先不用管
#测试用url= 'http://www.mafengwo.cn/mdd/citylist/21536.html?mddid=21536&page=1'
for i in range(6, 7):#左闭右开
print('正在获取第'+str(i)+'/'+str(total)+'页城市的信息')
'''
if self.proxy: # 如果代理存在
proxies = {
'http': 'http://' + self.proxy # requests.get()方法中代理用字典类型,而scrapy的代理则稍有不同
}
# 如果当前代理不行了,更换一下代理
try:
print('1.1')
response = requests.get('http://www.mafengwo.cn/', allow_redirects=False, proxies=proxies)
print('1.2')
while response.status_code != 200:
print('1.3')
self.proxy = self.get_proxy()
print('93行:更换了代理:', self.proxy)
proxies = {
'http': 'http://' + self.proxy # requests.get()方法中代理用字典类型,而scrapy的代理则稍有不同
}
response = requests.get('http://www.mafengwo.cn/', allow_redirects=False, proxies=proxies)
except Exception as e:
print('100行,解析每一页城市前,检测代理是否可用时出错了', e.args)
continue
yield Request(self.cities_url.format(page=i), callback=self.parse_one_page_cities,
meta={'proxy': 'http://' + self.proxy})#解析每页城市
'''
yield Request(self.cities_url.format(page=i), callback=self.parse_one_page_cities,
meta={'proxy': 'http://' + self.proxy}) # 不使用动态代理解析每页城市
#测试解析一页攻略:通过
#yield Request(self.test_str_list_url, self.parse_one_page_strategies_url)
# 测试解析单个攻略:通过
#yield Request(self.test_str_url, self.parse_strategy)
#获取城市列表总页数,成功
def get_total_city_pages(self):
html = self.get_html('http://www.mafengwo.cn/mdd/citylist/21536.html')
#response.encoding = response.apparent_encoding
#print(html)
pattern = re.compile(r'count">共(.*?)页</span>')
total = re.search(pattern, html).group(1) # 获取总页数
if total:
#print('城市总页数:'+total)
return int(total)
else:
print('没有获取到城市总页数:')
return self.get_total_city_pages()
# 解析一页的城市,小于等于9个
def parse_one_page_cities(self, response):#解析一页的城市,小于等于9个
#print(response.text)
pattern = re.compile(r'class="item ".*?href="(.*?)".*?data-id="(.*?)".*?title">(.*?)<p.*?<b>(.*?)</b>[\s\S]*?'
+ r'class="detail">(.*?)</div>.*?TOP3</span>'
+ r'.*?href="(.*?)".*?title="(.*?)".*?</a>'
+ r'.*?href="(.*?)".*?title="(.*?)".*?</a>'
+ r'.*?href="(.*?)".*?title="(.*?)".*?</a>'
+ r'\s*?</dd>',
re.S) # 这是获取了3个景点的,基本上热门城市都是3个景点,不是的先不考虑了
items = re.findall(pattern, response.text) # 从中获取所有的城市
if items:
for item in items:
city = CityItem()
city['city_url'] = 'http://www.mafengwo.cn' + item[0].strip() # item[i]的话从0开始,而如果是item.group(i)的话从1开始!!!
city['cityid'] = item[1]
city['city_name'] = item[2].strip() # 城市名字
city['nums'] = int(item[3]) # 人数
city['detail'] = item[4].strip() # 城市介绍
city['top1_url'] = 'http://www.mafengwo.cn' + item[5]
city['top1'] = item[6]
city['top2_url'] = 'http://www.mafengwo.cn' + item[7]
city['top2'] = item[8]
city['top3_url'] = 'http://www.mafengwo.cn' + item[9]
city['top3'] = item[10]
#(city)
#print('这个城市的URL是:'+city.get('url'))
#请求一个城市下的所有攻略,
# 1.获取一个城市的所有攻略的总页数
index = city['cityid'] # 获取一个城市的标识
#str_total = self.get_strategy_total_page(index)#获取一个城市的所有攻略的总页数
str_total = 100
# 2.调用解析一“页”攻略的方法,解析这个城市下的每一页攻略
print('获取到城市的索引:'+index)
yield city
#continue #先不存攻略,只存城市
if str_total >= 100:
page = 100
else:
page = int(str_total)
for i in range(1, page): # 左闭右开
str_list_url = 'http://www.mafengwo.cn/yj/' + index + '/1-0-' + \
str(i) + '.html' # 攻略strategy列表的url
print('攻略列表的url:' + str_list_url)
#print('正在解析第'+str(i)+'/'+str(str_total)+'页攻略')
print('正在解析第' , str(i) , '/' , page , '页攻略')
'''
if self.proxy: # 如果代理存在
proxies = {
'http': 'http://' + self.proxy # requests.get()方法中代理用字典类型,而scrapy的代理则稍有不同
}
# 如果当前代理不行了,更换一下代理
try:
response = requests.get('http://www.mafengwo.cn/', allow_redirects=False, proxies=proxies)
while (response.status_code != 200):
self.proxy = self.get_proxy()
print('184行:更换了代理:', self.proxy)
proxies = {
'http': 'http://' + self.proxy # requests.get()方法中代理用字典类型,而scrapy的代理则稍有不同
}
response = requests.get('http://www.mafengwo.cn/', allow_redirects=False, proxies=proxies)
except Exception as e:
print('190行,解析每一页攻略前,检测代理是否可用时出错了',e.args)
continue
#yield Request(str_list_url, callback=self.parse_one_page_strategies,
# meta={'proxy': 'http://' + self.proxy}) # 提交请求,解析这个城市下的每一页攻略
yield Request(str_list_url, callback=self.parse_one_page_strategies_url,
meta={'proxy': 'http://' + self.proxy}) # 提交请求,解析这个城市下的每一页攻略
'''
yield Request(str_list_url, callback=self.parse_one_page_strategies_url,
meta={'proxy': 'http://' + self.proxy}) # 不使用代理解析这个城市下的每一页攻略
#break#先测试一个城市
#获取一个城市的所有攻略的总页数
def get_strategy_total_page(self, index): # 获取一个城市的所有攻略的总页数, index是一个城市的标识
#print('index:' + index)
# 凑出攻略列表界面的类型:http://www.mafengwo.cn/yj/10189/1-0-1.html',10189是城市标识,1-0-1中最后1个1是攻略列表页面的标识,通过修改他们俩获得所有攻略
str_url = 'http://www.mafengwo.cn/yj/' + index + '/1-0-1.html' # 攻略列表的url
html = self.get_html(str_url)
pattern = re.compile(r'class="count">共<span>(.*?)</span>页')
total = re.search(pattern, html)
if total:
print('这个城市攻略总页数:' + total.group(1)) # 获取攻略总页数,这里的“.group(1)”会从中提取出页数
return int(total.group(1))
else:
print('获取这个城市的攻略的总页数失败或者这个城市没有攻略')
return 0
#解析一页攻略(现在不用到这个函数)
def parse_one_page_strategies(self, response):
#print('1.3开始解析一页攻略')
#url = 'http://www.mafengwo.cn/yj/10065/1-0-1.html' #测试用的用例
#print('response.text'+response.text[0:100])
html = response.text
# print(html)
# 网页中攻略的网址:href="/i/6536459.html" ,匹配之
pattern = re.compile(r'href="(/i/.*?.html)"\s{1}target="_blank">[\s\S]*?</h2>')
# \s:表示空白字符,\s{1}:表示1个空格,可以用来处理去掉“宝藏”这种url
items = re.findall(pattern, html)
print(items)
if items:
for item in items:
item = 'http://www.mafengwo.cn' + item
print('捕获到每个攻略:'+item)
#break # 用于测试,先让后面的代码不运行了
if self.proxy: # 如果代理存在
proxies = {
'http': 'http://' + self.proxy # requests.get()方法中代理用字典类型,而scrapy的代理则稍有不同
}
# 如果当前代理不行了,更换一下代理
try:
response = requests.get(item, allow_redirects=False, proxies=proxies, timeout=40)
while (response.status_code != 200):
self.proxy = self.get_proxy()
print('232行:更换了代理:', self.proxy)
proxies = {
'http': 'http://' + self.proxy # requests.get()方法中代理用字典类型,而scrapy的代理则稍有不同
}
response = requests.get(item, allow_redirects=False, proxies=proxies, timeout=40)
except:
print('237行,解析单个攻略前,检测代理是否可用时出错了')
continue
yield Request(item, callback=self.parse_strategy,
meta={'proxy': 'http://' + self.proxy})#解析单个攻略
# 解析一页攻略,并且只把每个攻略的url存储到数据库就结束
def parse_one_page_strategies_url(self, response):
html = response.text
# print(html)
# 网页中攻略的网址:href="/i/6536459.html" ,匹配之
#pattern = re.compile(r'href="(/i/.*?.html)"\s{1}target="_blank">[\s\S]*?</h2>')
# \s:表示空白字符,\s{1}:表示1个空格,可以用来处理去掉“宝藏”这种url
pattern = re.compile(r'href="/i/(.*?).html"\s{1}target="_blank">[\s\S]*?</h2>')
items = re.findall(pattern, html)
print(items)
if items:
for item in items:
str_url = Str_urlItem()
str_url['id'] = item
str_url['url'] = 'http://www.mafengwo.cn/i/' + item + '.html'
print('捕获到每个攻略的url:http://www.mafengwo.cn/i/' + item + '.html')
yield str_url
# 解析单个攻略的url进行解析,得到出发时间、天数、标题、城市等信息(现在不用到这个函数)
def parse_strategy(self, response):
try:
# url = 'http://www.mafengwo.cn/i/2996543.html'
# url='http://www.mafengwo.cn/i/6536459.html'
#url = 'http://www.mafengwo.cn/i/3313604.html'
# url='http://www.mafengwo.cn/i/5320703.html'#没有静态显示的出发时间的攻略
#response.encoding = response.apparent_encoding#注意!!:如果是request库的话需要转编码格式,但是scrapy已经帮我们弄好了一切
#print(response.text)
item = StrategyItem()
# 获取标题和作者
pattern_title = re.compile(
r'<title>(.*?)</title>[\s\S]*?name="author"\s{1}content="(.*?),(.*?)"') # [\s\S]*?能匹配任意的包括空格换行在内的字符
# pattern = re.compile(r'<title>(.*?)</title>')
str = re.search(pattern_title, response.text)
if str:
item['title'] = str.group(1)
item['id'] = str.group(2)
item['author'] = str.group(3)
# 获取天数、出发时间、人物
pattern_tianshu = re.compile(
r'出发时间<span>/</span>(.*?)<i></i></li>[\s\S]*?出行天数<span>/</span>(\d*?)\s{1}天</li>'
+ r'[\s\S]*?人物<span>/</span>(.*?)</li>[\s\S]*?</li>')
str = re.search(pattern_tianshu, response.text)
# 如果没有获取得到天数,先不存储这条数据了
if str == None:
print('抓取不到出发时间,尝试下一条')
return# 有循环时用continue1!
if str:
date = str.group(1) # 出发的日期,把它分解开再存
item['tianshu'] = str.group(2)
item['partner'] = str.group(3)
# item['pay'] = str.group(4)
# 把出发时间分解成年、日、月,方便后续计算
pattern_date = re.compile(r'^(\d*?)-(\d*?)-(\d*?)$') # 注意要匹配字符结尾,不然最后一个最小匹配会匹配到空
result = re.search(pattern_date, date)
if result:
item['year'] = result.group(1)
item['month'] = result.group(2)
item['day'] = result.group(3)
# 获取费用(有的攻略有,有的攻略没有)
pattern_pay = re.compile(r'人均费用<span>/</span>(.*?)RMB') # 正则表达式要按照response.text来写,而不是浏览器显示的html代码来写,它俩不完全一样
str = re.search(pattern_pay, response.text)
if str:
item['pay'] = str.group(1)
# print('花销是:', str.group(1))
else:
item['pay'] = 0
print('没有花销,设置花销为0')
# 获取城市索引、城市名称
pattern_city_info = re.compile(r'相关目的地[\s\S]*?travel-scenic-spot/mafengwo/(\d*?).html"[\s\S]*?title="(.*?)"')
# pattern_city_info = re.compile(r'相关目的地[\s\S]*?travel-scenic-spot/mafengwo/(.*?).html"')
str = re.search(pattern_city_info, response.text)
if str:
item['cityid'] = str.group(1)
item['city_name'] = str.group(2)
#print(item)
print('使用了代理:', self.proxy)
print('提交给pipeline')
self.str_count += 1
print('捕获的攻略条数:', self.str_count)
yield item
except:
print('解析一个攻略出现了异常,放弃这个攻略,解析下一个攻略')
return
--------------------------------------------------------------parse_str_url.py代码:
'''
1.从数据库mysql中获得str_url记录
2.进行访问并解析出各种信息,并置visited为true
3.存储到攻略表中(以攻略id为主键)
'''
import pymysql as MYSQLdb
import re
import requests
from multiprocessing import Pool#multi processing
from requests.packages.urllib3.exceptions import ConnectTimeoutError
from mafengwo.items import StrategyItem
proxy = None
proxies = None
MAX_COUNT = 5
PROXY_POOL_URL='http://127.0.0.1:5000/get'
def get_proxy(): # 获得代理
try:
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
print('获取代理时发生异常')
return None
def save_str_to_mysql():
url_query = "select * from str_url where visited =FALSE"
url_visited = "update str_url set visited=TRUE where id= %s"
proxy = get_proxy()
proxies = {
'http': 'http://' + proxy
}
try:
conn = MYSQLdb.connect(host='localhost', user='root', passwd='123', db='mfw', port=3306, charset='utf8')#如果mysql没有密码:把这两个注释掉
cur = conn.cursor()
cur_update = conn.cursor() #这个游标用于更新
count = cur.execute(url_query)# 执行查询操作
print(count)
update_count=0
while count > 0:
count -= 1
str_url = cur.fetchone()#把这一行记录存下来
url = str_url[1]
#url='http://www.mafengwo.cn/i/5451641.html' #测试没有pay的网页
print('设置标志位为True,表示已经访问过.更新了', update_count,'/',count,'条记录')
print('攻略的url是:', url)
print('使用的代理是:',proxy)
try:
# url = 'http://www.mafengwo.cn/i/2996543.html'
# url='http://www.mafengwo.cn/i/5320703.html'#没有静态显示的出发时间的攻略
response = requests.get(url, allow_redirects=False, proxies=proxies, timeout=30)
cur_update.execute(url_visited, str_url[0]) # 设置这条记录已经访问,置访问标志位visited=TRUE
update_count += 1
conn.commit() # !!!这里:事务别忘了提交
#print(html)
response.encoding = response.apparent_encoding#注意!!:如果是request库的话需要转编码格式,但是scrapy已经帮我们弄好了一切
html = response.text
# print(response.text)
item = StrategyItem()
# 获取标题和作者
pattern_title = re.compile(
r'<title>(.*?)</title>[\s\S]*?name="author"\s{1}content="(.*?),(.*?)"') # [\s\S]*?能匹配任意的包括空格换行在内的字符
# pattern = re.compile(r'<title>(.*?)</title>')
str = re.search(pattern_title, html)
if str:
item['title'] = str.group(1)
item['id'] = str.group(2)
item['author'] = str.group(3)
# 获取天数、出发时间、人物
pattern_tianshu = re.compile(
r'出发时间<span>/</span>(.*?)<i></i></li>[\s\S]*?出行天数<span>/</span>(\d*?)\s{1}天</li>'
+ r'[\s\S]*?人物<span>/</span>(.*?)</li>[\s\S]*?</li>')
str = re.search(pattern_tianshu, html)
# 如果没有获取得到天数,先不存储这条数据了
if str == None:
print('抓取不到出发时间,尝试下一条')
continue
if str:
date = str.group(1) # 出发的日期,把它分解开再存
item['tianshu'] = str.group(2)
item['partner'] = str.group(3)
#item['pay'] = str.group(4)
# 把出发时间分解成年、日、月,方便后续计算
pattern_date = re.compile(r'^(\d*?)-(\d*?)-(\d*?)$') # 注意要匹配字符结尾,不然最后一个最小匹配会匹配到空
result = re.search(pattern_date, date)
if result:
item['year'] = result.group(1)
item['month'] = result.group(2)
item['day'] = result.group(3)
# 获取费用(有的攻略有,有的攻略没有)
pattern_pay = re.compile(r'人均费用<span>/</span>(.*?)RMB')#正则表达式要按照response.text来写,而不是浏览器显示的html代码来写,它俩不完全一样
str = re.search(pattern_pay, html)
if str:
item['pay'] = str.group(1)
#print('花销是:', str.group(1))
else:
item['pay'] = 0
print('没有花销,设置花销为0')
# 获取城市索引、城市名称
pattern_city_info = re.compile(
r'相关目的地[\s\S]*?travel-scenic-spot/mafengwo/(\d*?).html"[\s\S]*?title="(.*?)"')
# pattern_city_info = re.compile(r'相关目的地[\s\S]*?travel-scenic-spot/mafengwo/(.*?).html"')
str = re.search(pattern_city_info, html)
if str:
item['cityid'] = str.group(1)
item['city_name'] = str.group(2)
print(item)
save(item)
except requests.exceptions.ConnectTimeout as e:
print(e.args)
print('访问时间过长,更换代理')
proxy = get_proxy()
proxies = {
'http': 'http://' + proxy
}
print('更换后的代理是:', proxy, proxies)
continue
except requests.exceptions.Timeout as e:
print(e.args)
print('访问时间过长,更换代理')
proxy = get_proxy()
proxies = {
'http': 'http://' + proxy
}
print('更换后的代理是:', proxy, proxies)
continue
except Exception as e:
print(e.args)
print('解析一个攻略出现了异常,放弃这个攻略,解析下一个攻略')
continue
conn.commit()
except MYSQLdb.Error as e:
print(e.args)
finally:
cur.close()
conn.close()
def save(item):#存储一个攻略的各种信息到数据库中
str_insert = "insert into strategy(id,title,author,tianshu,partner,pay," \
"year, month, day, cityid, city_name)" \
"VALUES (%s,%s,%s, %s,%s,%s, %s,%s,%s,%s,%s)" # 攻略的mysql语句
'''
proxy = get_proxy()
proxies = {
'http': 'http://' + proxy
}
'''
try:
conn = MYSQLdb.connect(host='localhost', user='root', passwd='123', db='mfw', port=3306,
charset='utf8') # 没有密码:把这两个注释掉
cur = conn.cursor()
cur.execute(str_insert, (item['id'], item['title'], item['author'], item['tianshu'],
item['partner'], item['pay'], item['year'], item['month'],
item['day'], item['cityid'], item['city_name'])) # 执行插入操作
conn.commit()#经过验证,攻略能存进去
print('提交了一次攻略的存储操作')
except MYSQLdb.Error as e:
print(e.args)
finally:
cur.close()
conn.close()
def main():
print('')
save_str_to_mysql()
if __name__=='__main__':
main()
#pool = Pool()
#pool.map(main, [i*10 for i in range(10)])#开启多线程
mysql数据库配置:
SHOW TABLES;
CREATE TABLE strategy(#攻略表
id VARCHAR(20) PRIMARY KEY,
title VARCHAR(50),
author VARCHAR(20),
tianshu INT,
partner VARCHAR(20),
pay INT,
`year` INT,
`month` INT,
`day` INT,
cityid VARCHAR(20),
city_name VARCHAR(20)
);
SELECT * FROM strategy;
SELECT * FROM strategy GROUP BY cityid;
SELECT COUNT(*) FROM strategy;
SELECT * FROM strategy WHERE id ='5321199';
SELECT * FROM strategy WHERE city_name ='呼伦贝尔';
DESC strategy;
INSERT INTO strategy(id,title) VALUES('1','题目1');
#delete from student where sno=7;
CREATE TABLE str_url(#攻略的url表
id VARCHAR(20) PRIMARY KEY,
url VARCHAR(100),
visited BOOLEAN DEFAULT FALSE# 0 表示false
);
#SELECT count(*) FROM str_url
SELECT * FROM str_url ORDER BY visited;
SELECT * FROM str_url WHERE id='3289473';
SELECT * FROM str_url WHERE visited=TRUE;
SELECT * FROM str_url WHERE visited=FALSE;
UPDATE str_url SET visited=FALSE;
INSERT INTO str_url(url,visited) VALUES ('攻略1', FALSE);
# delete from str_url;
# drop table str_url;
CREATE TABLE city(
cityid VARCHAR(20) PRIMARY KEY,
city_name VARCHAR(20),
city_url VARCHAR(100),
nums INT, #去过的人数
detail VARCHAR(200),#介绍
image VARCHAR(200),-- 图片
top1 VARCHAR(40),#top3景点,每个景点有自己的url链接,链接到蚂蜂窝上
top1_url VARCHAR(100),
top2 VARCHAR(40),
top2_url VARCHAR(100),
top3 VARCHAR(40),
top3_url VARCHAR(100)
);
#drop table city;
SELECT * FROM city ORDER BY nums DESC;
SELECT city_name,nums FROM city ORDER BY nums DESC LIMIT 10;
SELECT city_name AS city_name2,nums FROM city ORDER BY nums DESC LIMIT 11,10;
SELECT * FROM strategy ORDER BY city_name;
SELECT * FROM strategy WHERE id='5342577';
SELECT COUNT(*) FROM strategy WHERE city_name='北京1';
#DELETE FROM strategy;
SELECT COUNT(*) AS nums ,city_name,cityid FROM strategy GROUP BY city_name ORDER BY COUNT(*) DESC LIMIT 10;# 找在攻略表中访问城市出现最多的10条
SELECT COUNT(*) AS nums,`month`,cityid FROM strategy WHERE cityid = '10186' GROUP BY MONTH ;#丽江每个月的访问量
/*
select * from(
SELECT * FROM strategy WHERE cityid='10186' AND pay>0 order by pay desc limit 10,SELECT count(*) FROM strategy WHERE cityid='10186' AND pay>0
)
*/
SELECT AVG(pay) AS pay,cityid FROM strategy WHERE cityid='10186' AND pay>0 ;#某城市总的平均旅游花费
SELECT AVG(pay) AS pay,MONTH,cityid FROM strategy WHERE cityid='10186' AND pay>0 GROUP BY MONTH;#某城市每个月的平均旅游花费(不和月访问量一起查询是因为有些攻略没写花费,即花费是0)
#找到所有的满足月份的攻略
SELECT COUNT(*) AS nums ,city_name,cityid FROM strategy
WHERE id IN
(SELECT id FROM strategy WHERE MONTH = 1)
GROUP BY city_name ORDER BY COUNT(*) DESC LIMIT 10;
#>找到所有的满足开始时间和结束时间的攻略:
SELECT COUNT(*) AS nums ,city_name,cityid FROM strategy
WHERE id IN
(SELECT id FROM strategy WHERE (MONTH >1 AND MONTH<3) OR(MONTH=1 AND DAY>=22) OR(MONTH=3 AND DAY<=2) )
GROUP BY city_name ORDER BY COUNT(*) DESC LIMIT 10;
运行步骤:
1.配置好代码中连接mysql数据库的用户名和密码,按项目中的sql文件创建数据库和表
2.运行run.py获取动态代理IP
3.在Pycharm的terminal命令行窗口输入:Scrapy crawl mfw来启动爬虫
3.等数据库中的数据足够时,运行parse_str_url来获取每个攻略的时间等信息
运行结果:
mfw.py运行结果:
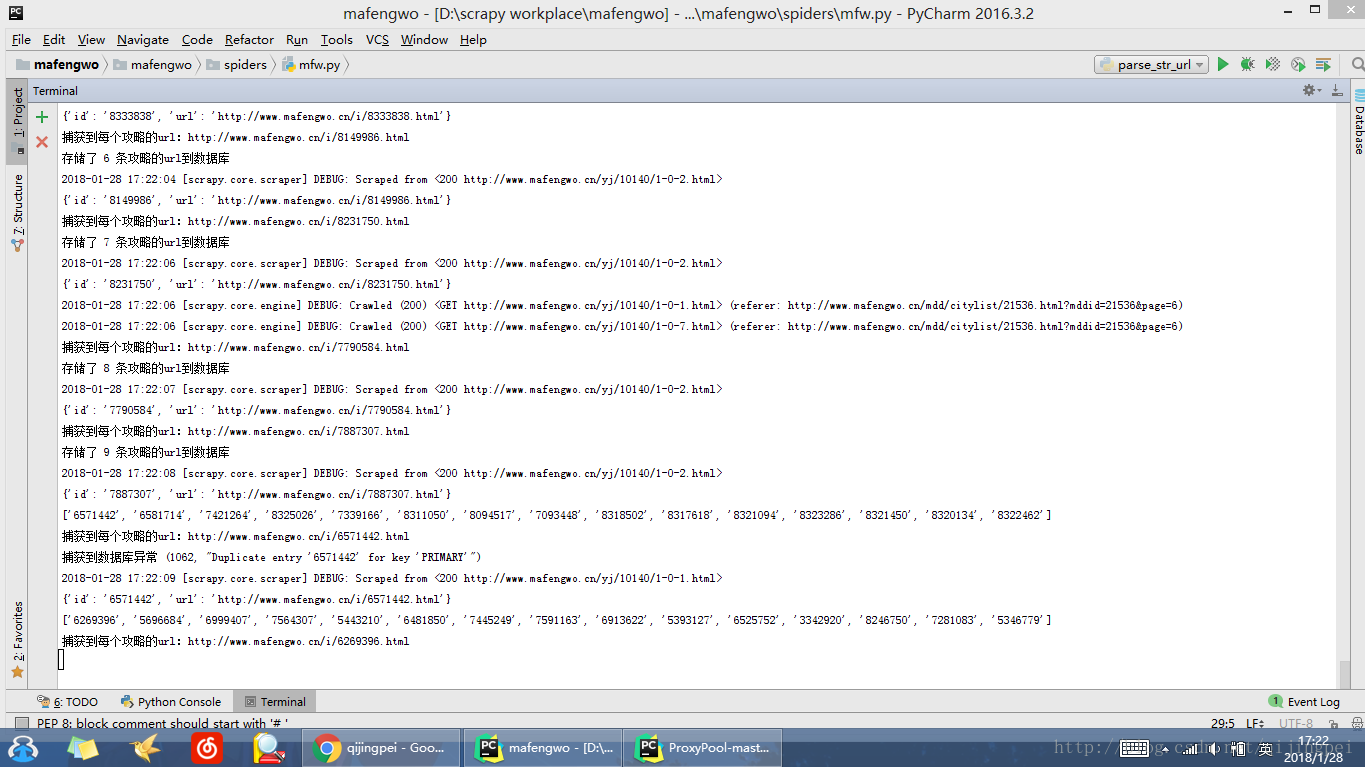
parse_str_url运行结果:
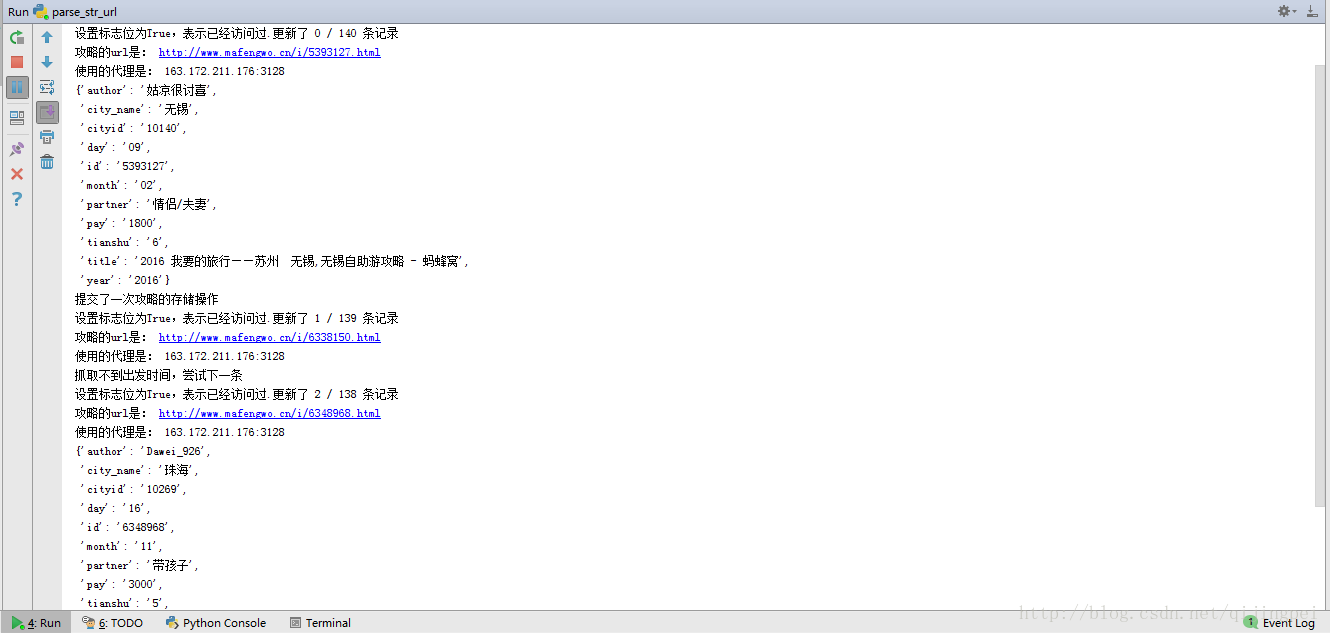















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









