






Java8之重构代码
第7章 并行数据处理与性能
1、将顺序流转换为并行流
1)parallel方法:
public static long parallelSum(long n) {
return Stream.iterate(1L, i -> i + 1)
.limit(n)
.parallel()
.reduce(0L, Long::sum);
}- 转换成并行流之后的图解
2) 当然也可以转回来-sequential方法
stream.parallel()
.filter(...)
.sequential()
.map(...)
.parallel()
.reduce();并行流内部使用了默认的ForkJoinPool(7.2节会进一步讲到分支/合并框架),它默认的 线程数量就是你的处理器数量,这个值是由 Runtime.getRuntime().availableProcessors()得到的。 但是你可以通过系统属性 java.util.concurrent.ForkJoinPool.common. parallelism来改变线程池大小,如下所示: System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12"); 这是一个全局设置,因此它将影响代码中所有的并行流。反过来说,目前还无法专为某个 并行流指定这个值。一般而言,让ForkJoinPool的大小等于处理器数量是个不错的默认值。
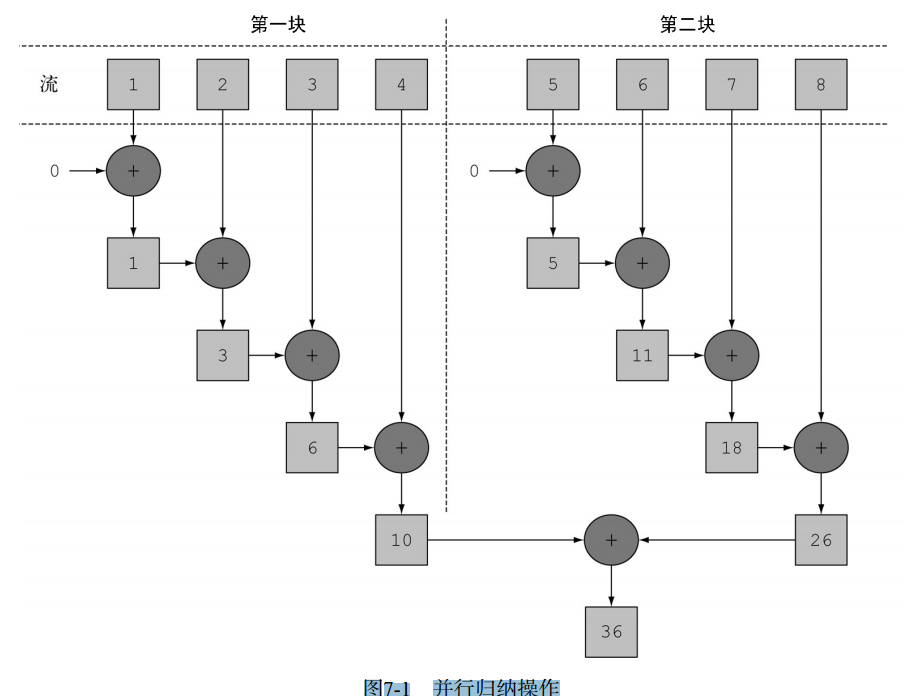
* 并行处理的性能-流的数据源和可分解性
按照可分解性总结了一些流数据源适不适于并行。

- 调并行流背后使用的基础架构是Java 7中引入的分支/合并框架。
2、分支/合并框架-Java7的框架
> 分支/合并框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任 务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配给 线程池(称为ForkJoinPool)中的工作线程。1) 使用 RecursiveTask
要把任务提交到这个池,必须创建RecursiveTask的一个子类,其中R是并行化任务(以 及所有子任务)产生的结果类型,或者如果任务不返回结果,则是RecursiveAction类型(当 然它可能会更新其他非局部机构)。
- 要定义RecursiveTask,只需实现它唯一的抽象方法 compute:
protected abstract R compute();上面的方法实现大概如下:
if (任务足够小或不可分) {
顺序计算该任务
} else {
将任务分成两个子任务
递归调用本方法,拆分每个子任务,等待所有子任务完成
合并每个子任务的结果
}- Java7的框架暂不做记录,本篇将专注Java8
3、Spliterator接口
Spliterator是Java 8中加入的另一个新接口;这个名字代表“可分迭代器”(splitable iterator)。和Iterator一样,Spliterator也用于遍历数据源中的元素,但它是为了并行执行 而设计的。
Java 8已经为集合框架中包含的所有数据结构提供了一个 默认的Spliterator实现。集合实现了Spliterator接口,接口提供了一个spliterator方法。 这个接口定义了若干方法,如下面的代码清单所示。
- Spliterator接口
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
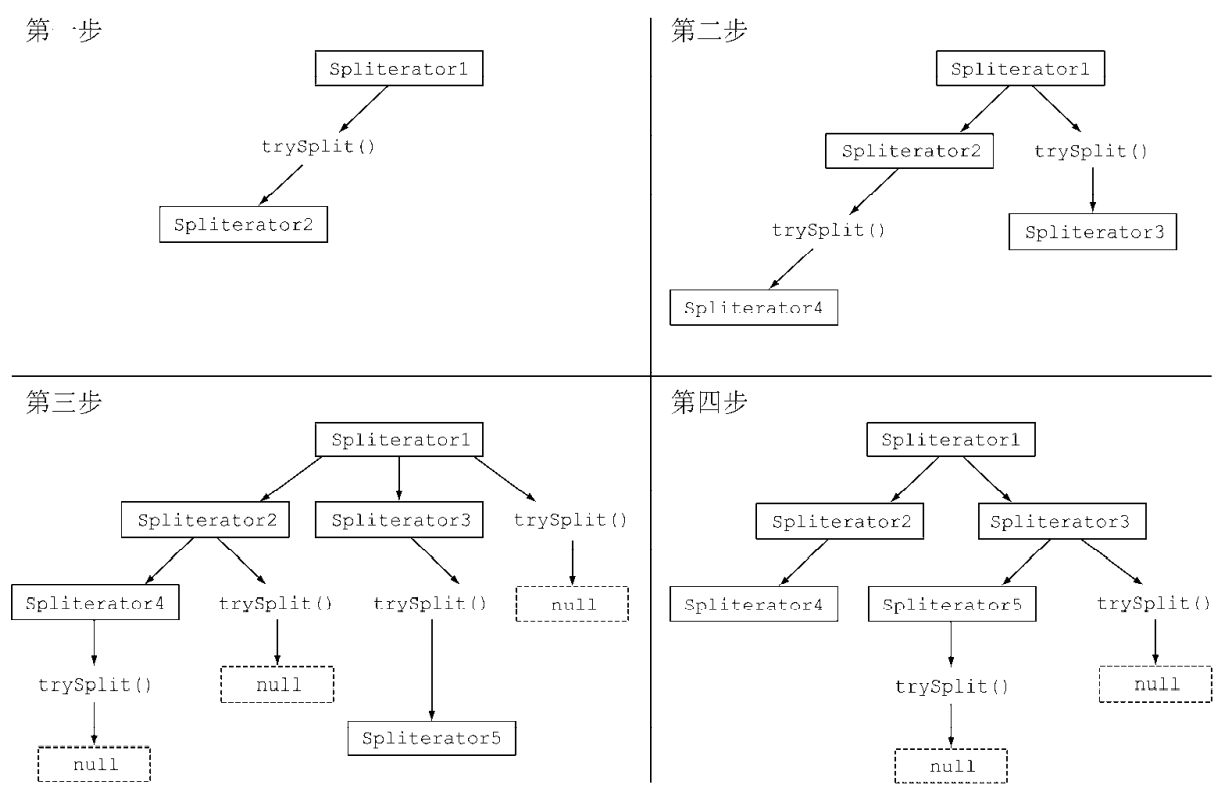
}1) 拆分过程
将Stream拆分成多个部分的算法是一个递归过程,第一步是对第一个 Spliterator调用trySplit,生成第二个Spliterator。第二步对这两个Spliterator调用 trysplit,这样总共就有了四个Spliterator。这个框架不断对Spliterator调用trySplit 直到它返回null,表明它处理的数据结构不能再分割,如第三步所示。最后,这个递归拆分过 程到第四步就终止了,这时所有的Spliterator在调用trySplit时都返回了null。
** 第三部分 **
第八章 高效Java8编程
1、为改善可读性和灵活性重构代码
1) 改善代码的可读性
通常的理解是,“别人理解这段代码的难易程度”
利用Lambda表达式、方法引用以及Stream改善程序代码的 可读性:
-
重构代码,用Lambda表达式取代匿名类
-
用方法引用重构Lambda表达式
-
用Stream API重构命令式的数据处理
2) 从匿名类到 Lambda 表达式的转换
i、 Runnable
- 创建 Runnable对象的匿名类
这段代码及其对应的Lambda表达式实现如下:
//传统方法
Runnable r1 = new Runnable(){
public void run(){
System.out.println("Hello");
}
};
//Java8
Runnable r2 = () -> System.out.println("Hello");- 请注意,Lambda形式的匿名类里面不可使用与外部同名的局部变量,否则会报错
如下:
int a = 10;
Runnable r1 = () -> {
int a = 2;
System.out.println(a);
};3) 从 Lambda 表达式到方法引用的转换
Lambda表达式非常适用于需要传递代码片段的场景。不过,为了改善代码的可读性,也请 尽量使用方法引用。因为方法名往往能更直观地表达代码的意图。
i、提取方法
- 比如按照食物的热量级别对菜肴进行分类:groupingBy
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel =
menu.stream()
.collect(
groupingBy(dish -> {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}));- 可以将if提取出来作为方法,这样调用更为直观,比如:
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel =
menu.stream().collect(groupingBy(Dish::getCaloricLevel));public class Dish{
…
public CaloricLevel getCaloricLevel(){
if (this.getCalories() <= 400) return CaloricLevel.DIET;
else if (this.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}
}ii、静态辅助方法,比如comparing、maxBy。
比如
- 原来代码
inventory.sort(
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()));- 可以写成
inventory.sort(Comparator.comparing(Apple::getWeight));再比如,
很多通用的归约操作,比如sum、maximum,都有内建的辅助方法可以和方法引用结 合使用。比如,在我们的示例代码中,使用Collectors接口可以轻松得到和或者最大值
- 原来代码
int totalCalories =
menu.stream().map(Dish::getCalories)
.reduce(0, (c1, c2) -> c1 + c2);- 可以写成
int totalCalories = menu.stream().collect(Collectors.summingInt(Dish::getCalories));4) 从命令式的数据处理切换到 Stream
比如
- 原来代码
List<String> dishNames = new ArrayList<>();
for(Dish dish: menu){
if(dish.getCalories() > 300){
dishNames.add(dish.getName());
}
}- 可以改成
menu.parallelStream()
.filter(d -> d.getCalories() > 300)
.map(Dish::getName)
.collect(toList());2、使用 Lambda 重构面向对象的设计模式
对设计经验的归纳总结被称为设计模式①。设计软件时,如果你愿意,可以复用这些方式方 法来解决一些常见问题。这看起来像传统建筑工程师的工作方式,对典型的场景(比如悬挂桥、 拱桥等)都定义有可重用的解决方案。
- 例如,访问者模式常用于分离程序的算法和它的操作对象。
- 单例模式一般用于限制类的实例化,仅生成一份对象。
1) 策略模式
- 策略模式代表了解决一类算法的通用解决方案,你可以在运行时选择使用哪种方案。
策略模式包含三部分内容:
- 一个代表某个算法的接口(它是策略模式的接口)。
- 一个或多个该接口的具体实现,它们代表了算法的多种实现(比如,实体类ConcreteStrategyA或者ConcreteStrategyB)。
- 一个或多个使用策略对象的客户。

假设希望验证输入的内容是否根据标准进行了恰当的格式化(比如只包含小写字母或 数字)。
- 你可以从定义一个验证文本(以String的形式表示)的接口入手:
public interface ValidationStrategy {
boolean execute(String s);
}- 其次,定义该接口的一个或多个具体实现
public class IsAllLowerCase implements ValidationStrategy {
public boolean execute(String s){
return s.matches("[a-z]+");
}
}
public class IsNumeric implements ValidationStrategy {
public boolean execute(String s){
return s.matches("\\d+");
}
}- 验证策略
public class Validator{
private final ValidationStrategy strategy;
public Validator(ValidationStrategy v){
this.strategy = v;
}
public boolean validate(String s){
return strategy.execute(s);
}
}
//使用
Validator numericValidator = new Validator(new IsNumeric());
boolean b1 = numericValidator.validate("aaaa");
Validator lowerCaseValidator = new Validator(new IsAllLowerCase ());
boolean b2 = lowerCaseValidator.validate("bbbb");其实ValidationStrategy已经是一个函数接口,与Predicate<String>具有同样的函数描述
- 所以可以将上面的代码修改成:
Validator numericValidator =
new Validator((String s) -> s.matches("[a-z]+"));
boolean b1 = numericValidator.validate("aaaa");
Validator lowerCaseValidator =
new Validator((String s) -> s.matches("\\d+"));
boolean b2 = lowerCaseValidator.validate("bbbb");- 这个地方,其实就是省掉了impl接口实现方法了,如果用实现方法的话,万一需要大量的策略就得创建大量的实现方法,这其实也是策略模式的弊端,这时候直接用Lambda表达式来代替实现方法,Lambda表达式避免了采用策略设计模式时僵化的模板代码。
2) 模板方法
模板方法模式在你“希望使用这个算法,但是需要对其中的某些行进行改进,才能达到希望的效果” 时是非常有用的。
假设需要编写一个简单的在线银行 应用。通常,用户需要输入一个用户账户,之后应用才能从银行的数据库中得到用户的详细信息, 最终完成一些让用户满意的操作。不同分行的在线银行应用让客户满意的方式可能还略有不同, 比如给客户的账户发放红利,或者仅仅是少发送一些推广文件。你可能通过下面的抽象类方式来 实现在线银行应用:
abstract class OnlineBanking {
public void processCustomer(int id){
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy(c);
}
abstract void makeCustomerHappy(Customer c);
}- Lambda表达式方式
向processCustomer方法引入了第二个参数,它是一个Consumer类型的参数,与前文定义的makeCustomerHappy的特征保持一致:
public void processCustomer(int id, Consumer<Customer> makeCustomerHappy){
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy.accept(c);
}- 现在可以通过传递Lambda表达式,直接插入不同的行为,不再需要继承 OnlineBanking类了:
new OnlineBankingLambda().processCustomer(1337, (Customer c) ->
System.out.println("Hello " + c.getName());3) 观察者模式
观察者模式是一种比较常见的方案,某些事件发生时(比如状态转变),如果一个对象(通 常我们称之为主题)需要自动地通知其他多个对象(称为观察者),就会采用该方案。

好几家报纸机构,比如《纽约时报》《卫报》以及《世 界报》都订阅了新闻,他们希望当接收的新闻中包含他们感兴趣的关键字时,能得到特别通知。
下面是原始的方式实现新闻通知,根据新闻的内容通知不同的观察者(新闻机构)
- 首先定义一个观察者接口
interface Observer {
void notify(String tweet);
}- 再定义不同的观察者实现上面的接口
class NYTimes implements Observer{
public void notify(String tweet) {
if(tweet != null && tweet.contains("money")){
System.out.println("Breaking news in NY! " + tweet);
}
}
}
class Guardian implements Observer {
public void notify(String tweet) {
if(tweet != null && tweet.contains("queen")){
System.out.println("Yet another news in London... " + tweet);
}
}
}
class LeMonde implements Observer{
public void notify(String tweet) {
if(tweet != null && tweet.contains("wine")){
System.out.println("Today cheese, wine and news! " + tweet);
}
}
}- 然后再定义一个接口主题接口,用来提供注册观察者和实现通知
interface Subject{
void registerObserver(Observer o);
void notifyObservers(String tweet);
}- 实现上面的接口
class Feed implements Subject {
private final List<Observer> observers = new ArrayList<>();
public void registerObserver(Observer o) {
this.observers.add(o);
}
public void notifyObservers(String tweet) {
observers.forEach(o -> o.notify(tweet));
}
}- 最后就可以进行注册并通知
Feed f = new Feed();
f.registerObserver(new NYTimes());
f.registerObserver(new Guardian());
f.registerObserver(new LeMonde());
f.notifyObservers("The queen said her favourite book is Java 8 in Action!");这个时候Guardian会收到消息,即打印内容
以上是观察者模式的一个完整的步骤,但是应该也能发现,依然需要定义很多的方法去实现观察者接口,所以可以用Lambda表达式来简化他们。
- 比如
f.registerObserver((String tweet) -> {
if(tweet != null && tweet.contains("money")){
System.out.println("Breaking news in NY! " + tweet);
}
});
f.registerObserver((String tweet) -> {
if(tweet != null && tweet.contains("queen")){
System.out.println("Yet another news in London... " + tweet);
}
});- 当然,以上不的意思并不是希望让所有的观察者模式都简化成Lambda表达式这样,因为当观察者的逻辑有可能十分复杂时,它们可能还持有状态,抑或定义了多个方法,在这些情形下,还是应该继续使用类的方式。
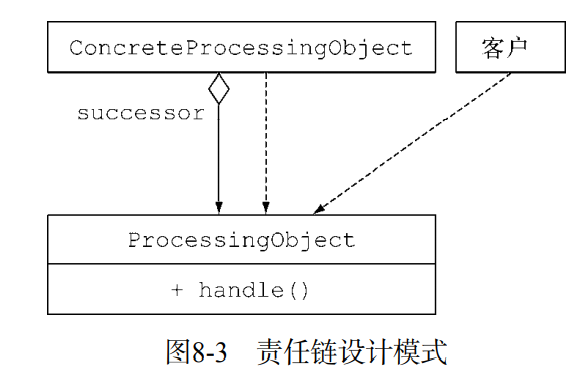
4) 责任链模式
责任链模式是一种创建处理对象序列(比如操作序列)的通用方案。一个处理对象可能需要 在完成一些工作之后,将结果传递给另一个对象,这个对象接着做一些工作,再转交给下一个处 理对象,以此类推。
代码示例
- 先定义一个抽象类,来控制
public abstract class ProcessingObject<T> {
protected ProcessingObject<T> successor;
public void setSuccessor(ProcessingObject<T> successor){
this.successor = successor;
}
public T handle(T input){
T r = handleWork(input);
if(successor != null){
return successor.handle(r);
}
return r;
}
abstract protected T handleWork(T input);
}handle方法提供了如何进行 工作处理的框架。不同的处理对象可以通过继承ProcessingObject类,提供handleWork方法 来进行创建。
- 创建两个处理对象,它们的功能是进行一些文 本处理工作。
public class HeaderTextProcessing extends ProcessingObject<String> {
public String handleWork(String text){
return "From Raoul, Mario and Alan: " + text;
}
}
public class SpellCheckerProcessing extends ProcessingObject<String> {
public String handleWork(String text){
return text.replaceAll("labda", "lambda");
}
}- 将这两个处理对象结合起来,构造一个操作序列
ProcessingObject<String> p1 = new HeaderTextProcessing();
ProcessingObject<String> p2 = new SpellCheckerProcessing();
p1.setSuccessor(p2);
String result = p1.handle("Aren't labdas really sexy?!!");
System.out.println(result);打印结果为:打印输出“From Raoul, Mario and Alan: Aren't lambdas really sexy?!!”
请注意labdas已经变化为lambdas
- 接下来使用Lambda表达式--andthen方法
UnaryOperator<String> headerProcessing =
(String text) -> "From Raoul, Mario and Alan: " + text;
UnaryOperator<String> spellCheckerProcessing =
(String text) -> text.replaceAll("labda", "lambda");
Function<String, String> pipeline =
headerProcessing.andThen(spellCheckerProcessing);
String result = pipeline.apply("Aren't labdas really sexy?!!");5) 工厂模式
使用工厂模式,你无需向客户暴露实例化的逻辑就能完成对象的创建。
比如,我们假定你为 一家银行工作,他们需要一种方式创建不同的金融产品:贷款、期权、股票,等等。 通常,你会创建一个工厂类,它包含一个负责实现不同对象的方法,如下所示:
public class ProductFactory {
public static Product createProduct(String name){
switch(name){
case "loan": return new Loan();
case "stock": return new Stock();
case "bond": return new Bond();
default: throw new RuntimeException("No such product " + name);
}
}
}
Product p = ProductFactory.createProduct("loan");- 使用Lambda表达式
引用贷款 (Loan)构造函数的示例:
Supplier<Product> loanSupplier = Loan::new;
Loan loan = loanSupplier.get();所以通过这种方式,就可以将最上面的代码重构,创建一个Map,将产品名映射到对应的构造函数:
final static Map<String, Supplier<Product>> map = new HashMap<>();
static {
map.put("loan", Loan::new);
map.put("stock", Stock::new);
map.put("bond", Bond::new);
}像之前使用工厂设计模式那样,利用这个Map来实例化不同的产品:
public static Product createProduct(String name){
Supplier<Product> p = map.get(name);
if(p != null) return p.get();
throw new IllegalArgumentException("No such product " + name);
}- 当然如果工厂方法createProduct需要接收多个传递给产品构造方法的参数,这种方式的扩展性不是很 好。
为了完成这个任务,你需要创建一个特殊的函数接口TriFunction。最终 的结果是Map变得更加复杂。
public interface TriFunction<T, U, V, R>{
R apply(T t, U u, V v);
}
Map<String, TriFunction<Integer, Integer, String, Product>> map
= new HashMap<>();3、调试Lambda 表达式--peek
peek的设计初衷就是在流的每个元素恢复运行之 前,插入执行一个动作。但是它不像forEach那样恢复整个流的运行,而是在一个元素上完成操 作之后,它只会将操作顺承到流水线中的下一个操作。
- 使用peek输出了Stream流水线操作之前和操作之后的中间值:
List<Integer> result =
numbers.stream()
.peek(x -> System.out.println("from stream: " + x))
.map(x -> x + 17)
.peek(x -> System.out.println("after map: " + x))
.filter(x -> x % 2 == 0)
.peek(x -> System.out.println("after filter: " + x))
.limit(3)
.peek(x -> System.out.println("after limit: " + x))
.collect(toList());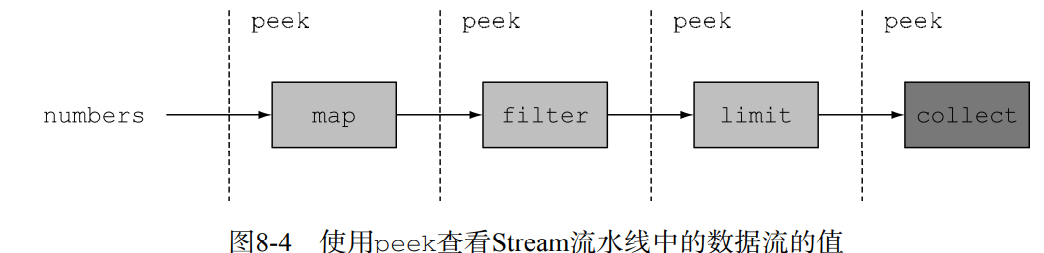
Q.E.D.
















 1922
1922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











