






【1701H1】【穆晨】【180126】第108天总结
URL:
统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。它最初是由蒂姆·伯纳斯·李发明用来作为万维网的地址。现在它已经被万维网联盟编制为互联网标准RFC1738了。
一般格式:
protocol://hostname[:port]/path/[;parameters][?query]#fragment
://分隔第一第二部分,第一个/分隔第二第三部分,第三部分可以忽略,【】内容也可以忽略
url由3部分组成:
1.协议:http,https,ftp,file,ed2k……
2.存放资源的服务器的域名系统或IP地址(有时候要包含端口号,各种传输协议都有默认的端口号,如http的默认端口为80)
3.资源的具体地址,如目录或文件名等
LIB:
LIB有两种,一种是静态库,比如C-Runtime库,这种LIB中有函数的实现代码,一般用在静态连编上,它是将LIB中的代码加入目标模块(EXE或者DLL)文件中,所以链接好了之后,LIB文件就没有用了。一种LIB是和DLL配合使用的,里面没有代码,代码在DLL中,这种LIB是用在静态调用DLL上的,所以起的作用也是链接作用,链接完成了,LIB也没用了。至于动态调用DLL的话,根本用不上LIB文件。 目标模块(EXE或者DLL)文件生成之后,就用不着LIB文件了。
python的urllib:
这是一个包详情看docs

urllib.request打开和读取urls
urllib.error包含由urllib.request引发的异常
urllib.parse解析urls
urllib.robotparser解析文本文件(二进制)
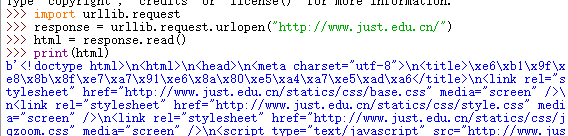
太多了,我就截了一部分,这是获取我们学校官网的网页代码(二进制的数据,我们可以对他进行解码操作)
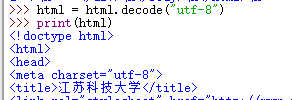
很长就不都截了,获取网页代码(二进制)会卡,建议获取一个小网站,解码的时候还好















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









