






【1701H1】【穆晨】【180127】第109天总结
图片也是文件,也是用二进制数据组成的,用wb写入
写了一个爬取placekitten网站的一张猫图的代码
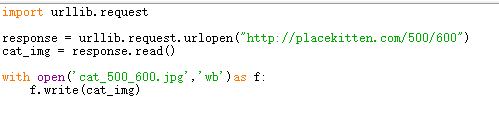
urlopen后面可以是字符串也可以是地址,详情docs里面搜索
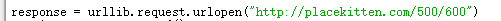


geturl获取的是具体的地址
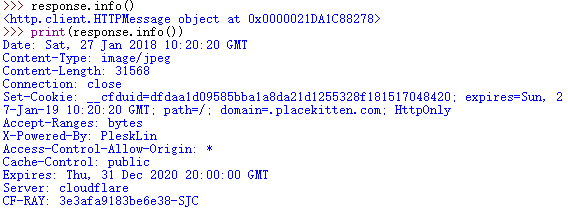
info获得是HTTPMessage的一个对象,可以把它打印出来,得到远程服务器返回的head信息

getcode得到http的状态码,200(OK)
游览器自带审查元素(检查)
爬取网站需要URL和data需要从headers寻找
get是从服务器请求获得数据
post是向指定服务器提交被处理的数据
user agent识别浏览器访问还是代码访问
windows NT 6.3-> windows 8.1
5.1->windows XP
6.1->windows 7
下面写一个爬取百度翻译的代码


error。。。反扒。。。
百度不行就有道

有道也反扒,出来的也是error,但网上网友表示url改下就可以了

出来的是json,导入模块,提取我们需要的东西

然后改进代码,做成能给用户用的东西

















 4656
4656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









