







1.1.问题
在快速排序中使用插入排序能否提高快速排序的效率?
1.2.设计
1.2.1.插入排序
每次在前面的有序序列中找第一个小于等于当前元素的位置,把当前元素插入到那个位置的后面,并且此间的元素都后移一位
void InsertSort(int arr[], int l, int r)
{
for (int i = l + 1; i < r - l + 1; i++) {
int val = arr[i];
int j;
for (j = i - 1; j >= l; j--) {
if (arr[j] <= val) break; //<=直接break 这样若遇到相同元素 插入元素始终在相同元素的右边 相对顺序不变 稳定
arr[j + 1] = arr[j];
}
arr[j + 1] = val; //j为第一个<=val的位置 在j+1处插入val
}
}
尽管可以使用二分查找减少比较次数,但因为使用的是数组,交换次数依旧是 O ( n ) O(n) O(n)的时间复杂度,无法从量级上降低时间复杂度,所以这里的实现就不用二分了。如果不使用二分在快速排序中使用插入排序还是能提高不俗的效率,更能说明这样优化确实可行,符合期望。
1.2.2.快速排序
每次选择基准数,把小于基准数的放到基准数的左边,把大于基准数的放在基准数的右边,采用“分治思想”处理剩余的序列元素,直至整个序列变为有序序列.
假设我们选择序列的中间值作为基准,我们写出以下代码:
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l, j = r, x = q[l + r >> 1];
while (i < j)
{
while(q[i]<x) i++;
while(q[j]>x) j--;
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
如代码所示,我们每次找到中间值作为基准,在 i i i和 j j j交汇之前,不断地把左边 ≥ x \geq x ≥x的元素与右边 ≤ x \leq x ≤x的元素交换,从而实现 j j j左边都是 ≤ x \leq x ≤x的元素,右边都是 ≥ x \geq x ≥x的元素,然后递归进入下一层处理两个子问题。以上代码咋一看没有问题,但是实际上是有漏洞的。
1.2.3.分析错误原因
例如用以下数据执行代码:
-
选择基准 x=5
1 2 4 5 2 5 3
-
一次交换后
1 2 4 3 2 5 5
i i i会停留在第一个5的位置, j j j会停留在第二个5的位置,因为x=5,所以 i i i和 j j j都不动了,从而陷入死循环
所以这里我们可以使用do-while,先移动再判断
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1]; //因为用do-while 会先无条件执行一次 所以i和j向两边偏移
while (i < j)
{
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
1.3.证明时间复杂度
1.3.1.最好情况
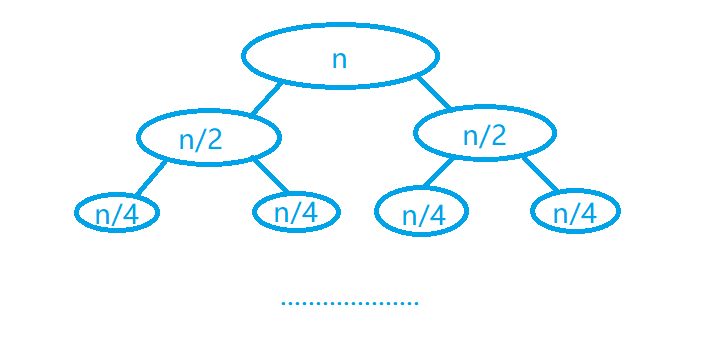
由图可知:一共会递归 O ( l o g 2 n ) O(log_2{n}) O(log2n)层,每次处理序列总长度为 n n n,所以快速排序的时间复杂度真的就是 O ( l o g 2 n ∗ n ) O(log_2{n}*n) O(log2n∗n)吗?
由上图我们一般会联想到归并排序,因为归并排序是先分治再比较,所以可以保证每次的子问题处理的序列长度是相等的,但快速排序显然不是这样的。
1.3.2.最坏情况
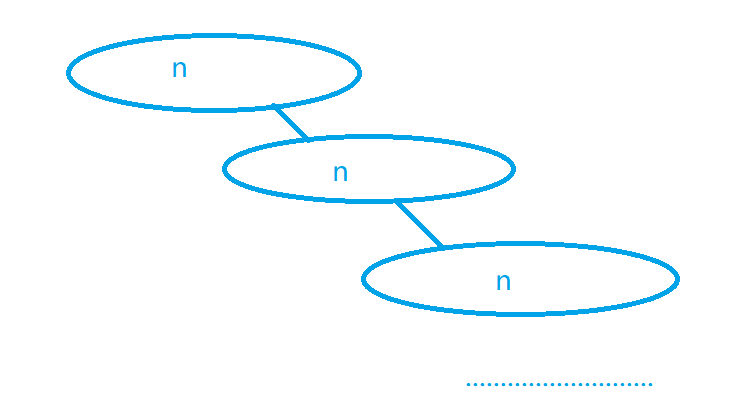 快速排序只能保证左子问题的所有元素都小于等于x,右子问题的所有元素都大于等于x,所以极端情况下可能出现这样的情况。
快速排序只能保证左子问题的所有元素都小于等于x,右子问题的所有元素都大于等于x,所以极端情况下可能出现这样的情况。
据上图所示,可能存在基准值为整个区间最大或最小,使得子问题依旧是一个长度为 n n n的子问题,这样快速排序的树形递归结构就会退化为 n n n层,每层长度为 n n n的链形,时间复杂度为 O ( n 2 ) O(n^2) O(n2)
| 排序算法 | 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 快速排序 | O ( n ∗ l o g 2 n ) O(n*log_2{n}) O(n∗log2n) | O ( n ∗ l o g 2 n ) O(n*log_2{n}) O(n∗log2n) | O ( n 2 ) O(n^2) O(n2) | O ( l o g 2 n ) O(log_2{n}) O(log2n)~ O ( n ) O(n) O(n) |
| 归并排序 | O ( n ∗ l o g 2 n ) O(n*log_2{n}) O(n∗log2n) | O ( n ∗ l o g 2 n ) O(n*log_2{n}) O(n∗log2n) | O ( n ∗ l o g 2 n ) O(n*log_2{n}) O(n∗log2n) | O ( n ) O(n) O(n) |
快速排序和归并排序类似空间换时间的关系
1.3.2.最坏情况
快速排序在面对乱序的时候效果显著,而面对趋于有序的序列的时候依旧需要依次遍历数组元素拿来和基准值比较,时间开销比较大,且可能退化,而插入排序在面对趋于有序的序列时,可以大大减小交换次数,所以想要提高快速排序的效率可以从两个点出发:
-
对于小段趋于有序的序列采用插入排序
因为左子问题中的元素总是小于等于基准,右子问题的元素总是大于等于基准,所以当序列长度越来越小时,序列一定是趋于有序的,考虑使用插入排序。
-
三数取中法,旨在挑选合适的基准数,防止快排退化成冒泡排序
这个如果不是被人专门用数据卡,一般很难退化为冒泡排序,且我们这里主要想讨论优化一成不成立,所以使用控制变量法,后面的实践中,基准都是取序列的中间值
1.4.实践
在快速排序中使用插入排序
核心代码
void quick_sort(int q[], int l, int r) //快速排序
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
if (r - l <= 1000) {
InsertSort(q, l, r);
return;
}
/*if (r - l <= 1000) {
ShellSort(q, l, r);
return;
}*/
while (i < j)
{
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
完整代码
#include <iostream>
#include<cstdlib>
#include<time.h>
using namespace std;
void ShellSort(int arr[], int l,int r) //希尔排序
{
int size = r - l + 1;
for (int gap = size / 2; gap > 0; gap /= 2) {
for (int i = gap; i < size; i++) { //从gap开始从前往后枚举
int val = arr[i];
int j;
for (j = i - gap; j >= 0; j -= gap) { //和下标差为gap的同组元素进行插入排序
if (arr[j] <= val) break;
arr[j + gap] = arr[j];
}
arr[j + gap] = val;
}
}
}
void InsertSort(int arr[], int l, int r) //插入排序
{
for (int i = l + 1; i < r - l + 1; i++) {
int val = arr[i];
int j;
for (j = i - 1; j >= l; j--) {
if (arr[j] <= val) break; //<=直接break 这样若遇到相同元素 插入元素始终在相同元素的右边 相对顺序不变 稳定
arr[j + 1] = arr[j];
}
arr[j + 1] = val; //j为第一个<=val的位置 在j+1处插入val
}
}
void quick_sort(int q[], int l, int r) //快速排序
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
if (r - l <= 1000) {
InsertSort(q, l, r);
return;
}
/*if (r - l <= 1000) {
ShellSort(q, l, r);
return;
}*/
while (i < j)
{
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
int main()
{
const int N = 50000000;
int* arr = new int[N];
srand(time(NULL));
for (int i = 0; i < N; i++) {
int val = rand() % N;
arr[i] = val;
}
clock_t begin, end;
begin = clock();
quick_sort(arr, 0, N - 1);
end = clock();
delete[]arr;
cout << (end - begin) * 1.0 /1000 << "s" << endl;
return 0;
}
1.4.1.插入排序与希尔排序的对照
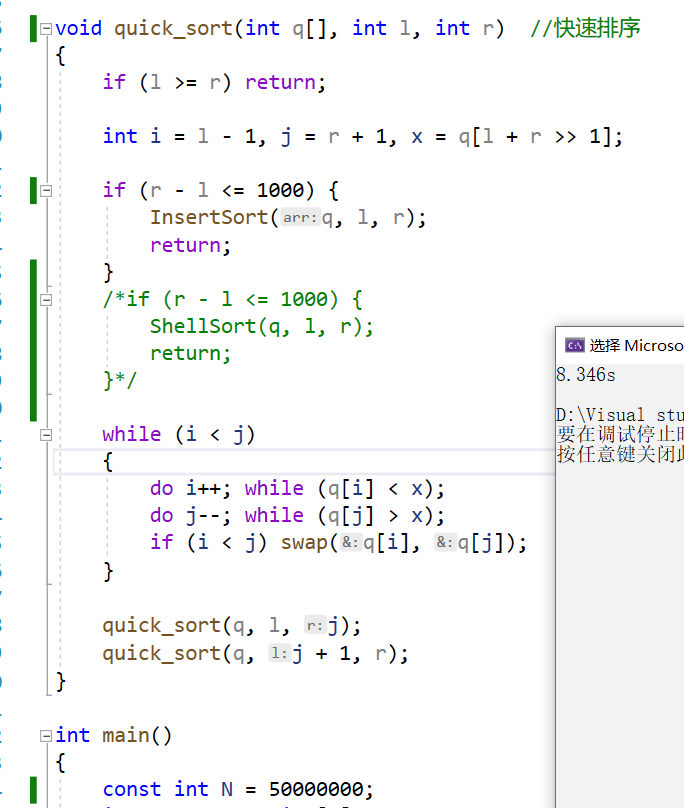
快排内嵌插入排序表现
快排内嵌希尔排序的表现
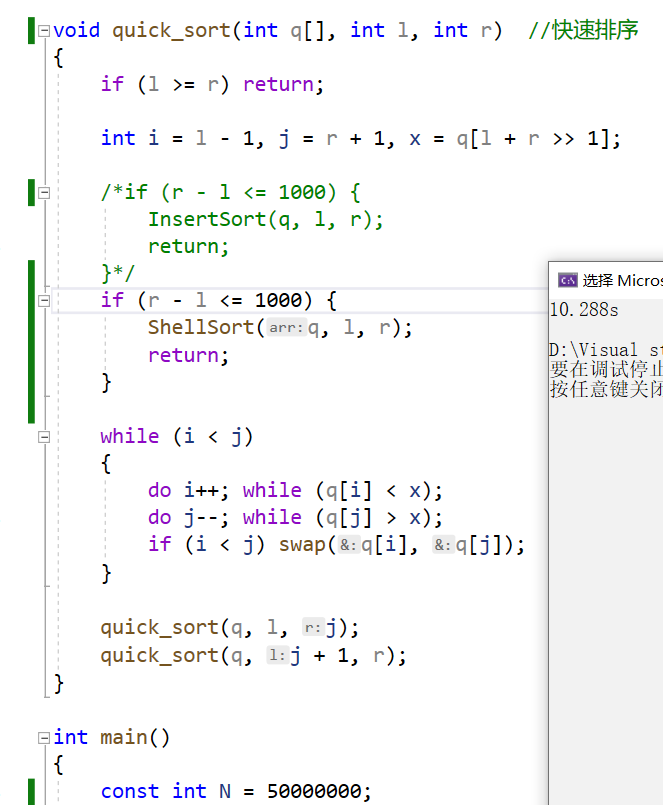
这里其实跑了很多遍,插入排序耗时在 7.783 s 7.783s 7.783s到 8.689 s 8.689s 8.689s,而希尔排序耗时在 10.132 s 10.132s 10.132s到 11.569 s 11.569s 11.569s,而数据量是 5 ∗ 1 0 7 5*10^7 5∗107比较大,且是随机数据,所以可以抛开因为特殊数据的偶然性的这种可能。
1.4.2.优化前
| 排序算法\数据量 | 5 ∗ 1 0 7 5*10^7 5∗107 | 3 ∗ 1 0 7 3*10^7 3∗107 | 1 0 7 10^7 107 | 8 ∗ 1 0 6 8*10^6 8∗106 |
|---|---|---|---|---|
| 快速排序(裸) | 15.317 s 15.317s 15.317s | 8.960 s 8.960s 8.960s | 3.128 s 3.128s 3.128s | 2.512 s 2.512s 2.512s |
1.4.3.优化后
1.优化区间长度为1000时
| 排序算法\数据量 | 5 ∗ 1 0 7 5*10^7 5∗107 | 3 ∗ 1 0 7 3*10^7 3∗107 | 1 0 7 10^7 107 | 8 ∗ 1 0 6 8*10^6 8∗106 |
|---|---|---|---|---|
| 快速排序(插入排序优化) | 8.346 s 8.346s 8.346s | 5.241 s 5.241s 5.241s | 1.756 s 1.756s 1.756s | 1.370 s 1.370s 1.370s |
| 快速排序(希尔排序优化) | 10.288 s 10.288s 10.288s | 6.029 s 6.029s 6.029s | 2.046 s 2.046s 2.046s | 1.622 s 1.622s 1.622s |
2.优化区间长度为500时
| 排序算法\数据量 | 5 ∗ 1 0 7 5*10^7 5∗107 | 3 ∗ 1 0 7 3*10^7 3∗107 | 1 0 7 10^7 107 | 8 ∗ 1 0 6 8*10^6 8∗106 |
|---|---|---|---|---|
| 快速排序(插入排序优化) | 9.836 s 9.836s 9.836s | 5.480 s 5.480s 5.480s | 1.932 s 1.932s 1.932s | 1.516 s 1.516s 1.516s |
| 快速排序(希尔排序优化) | 10.840 s 10.840s 10.840s | 6.400 s 6.400s 6.400s | 2.488 s 2.488s 2.488s | 1.718 s 1.718s 1.718s |
3.优化区间长度为100时
| 排序算法\数据量 | 5 ∗ 1 0 7 5*10^7 5∗107 | 3 ∗ 1 0 7 3*10^7 3∗107 | 1 0 7 10^7 107 | 8 ∗ 1 0 6 8*10^6 8∗106 |
|---|---|---|---|---|
| 快速排序(插入排序优化) | 11.191 s 11.191s 11.191s | 6.522 s 6.522s 6.522s | 2.219 s 2.219s 2.219s | 1.746 s 1.746s 1.746s |
| 快速排序(希尔排序优化) | 11.729 s 11.729s 11.729s | 6.859 s 6.859s 6.859s | 2.382 s 2.382s 2.382s | 1.878 s 1.878s 1.878s |
注意: 以上所有耗时数据仅为5次取平均值
折线图更直观一些
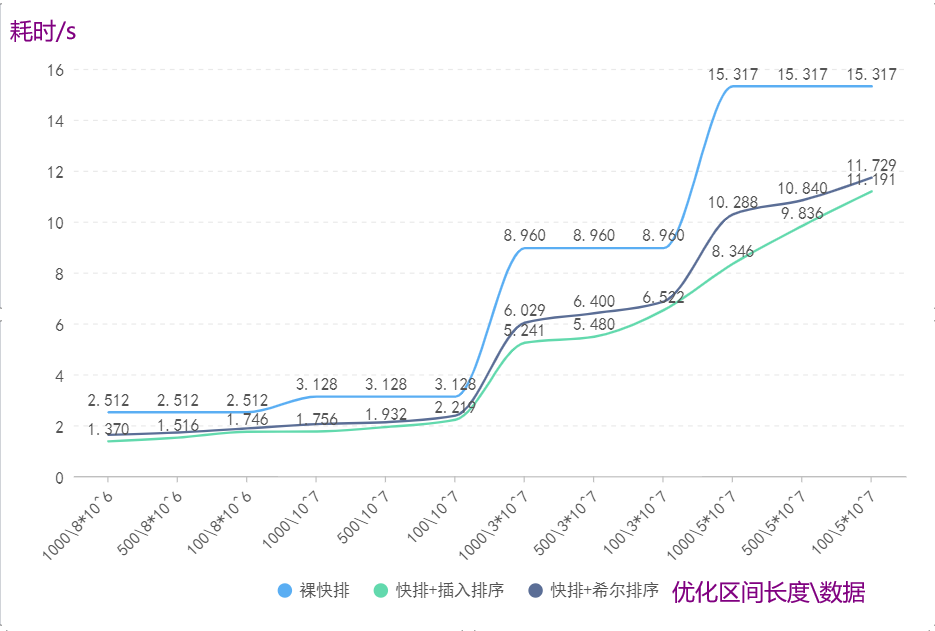
1.4.4.结论分析
希尔排序相当于分组插入排序,就是从全局的角度把乱序数组处理得趋于有序,从而提高插入排序的效率。然而通过对比上图我们发现在控制变量的情况下,插入排序在随机数据上的效率居然超过了希尔排序,这说明了什么?
通过上图,我们可以很直观的看到整个插入排序优化的耗时都是低于希尔排序优化和裸快排的,并且我们可以看出,随着数据量和优化区间的增大,希尔排序和插入排序的效率差距在拉大,这说明了随着数据量的增大,希尔排序相对于插入排序的优化越来越疲软,进一步说明了快排中子问题越往下划分,序列越是趋于有序,所以这里插入排序的表现才能超过希尔排序也可能是本蒟蒻电脑计算能力不行)。然后再对比裸快速排序和快速排序(插入排序优化)或快速排序(希尔排序优化),可以看到使用插入排序或希尔排序优化的效果是很显著的。
这里我们可以发现随着优化区间变大优化效果也在变强,所以这并不是最佳区间优化长度,这个应该和数据量有关,不过这不是重点啦!















 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









