







一、总述
决策树可用于分类和回归,主要是用于分类。
决策树包含结点(内结点代表特征,外结点代表类)和有向边,将决策树转换为if-then规则,是互斥且完备的。
目标:构建与训练数据矛盾较小的决策树。损失函数是正则化的极大似然函数。决策树的生成只考虑局部最优(这一次选择的特征有最好的分类能力),剪枝考虑全局最优。找出最优树是完全NP问题,找出次优树是一种启发式过程。
包含三个步骤:特征选择,决策树的生成和决策树的修剪。
二、特征选择(准则是:信息增益或者信息增益比)
熵(经验熵)的公式如下图,值越大,不确定性就越大。
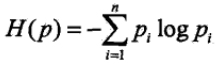
条件熵(条件经验熵)表示,X给定条件下Y的条件概率分布的熵对X的期望,如下图
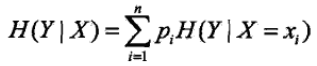
信息增益表示得知X的信息,使Y的不确定性减少的程度。
g
(
Y
,
X
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
g(Y,X)=H(Y)-H(Y|X)
g(Y,X)=H(Y)−H(Y∣X)
来看一个例子(李航的《统计学习方法》):

第一步,计算经验熵:
H
(
Y
)
=
−
(
9
/
15
)
(
l
o
g
9
/
15
)
−
(
6
/
15
)
(
l
o
g
6
/
15
)
=
0.971
H(Y)=-(9/15)(log9/15)-(6/15)(log6/15)=0.971
H(Y)=−(9/15)(log9/15)−(6/15)(log6/15)=0.971
第二步,计算各特征对数据集的信息增益,分别以X1,X2,X3,X4表示年龄、有工作、有自己的房子和信贷情况4个特征。
g
(
Y
∣
X
1
)
=
H
(
Y
)
−
[
(
5
/
15
)
H
(
Y
1
)
+
(
5
/
15
)
H
(
Y
2
)
+
(
5
/
15
)
H
(
Y
3
)
]
=
H
(
Y
)
−
{
(
5
/
15
)
[
−
(
2
/
5
)
l
o
g
(
2
/
5
)
−
(
3
/
5
)
l
o
g
(
3
/
5
)
]
+
(
5
/
15
)
[
−
(
3
/
5
)
l
o
g
(
3
/
5
)
−
(
2
/
5
)
l
o
g
(
2
/
5
)
]
+
(
5
/
15
)
[
−
(
4
/
5
)
l
o
g
(
4
/
5
)
−
(
1
/
5
)
l
o
g
(
1
/
5
)
]
}
=
0.971
−
0.888
=
0.083
g(Y|X1)=H(Y)-[(5/15)H(Y1)+(5/15)H(Y2)+(5/15)H(Y3)]=H(Y)-\{(5/15)[-(2/5)log(2/5)-(3/5)log(3/5)]+(5/15)[-(3/5)log(3/5)-(2/5)log(2/5)]+(5/15)[-(4/5)log(4/5)-(1/5)log(1/5)]\} =0.971-0.888=0.083
g(Y∣X1)=H(Y)−[(5/15)H(Y1)+(5/15)H(Y2)+(5/15)H(Y3)]=H(Y)−{(5/15)[−(2/5)log(2/5)−(3/5)log(3/5)]+(5/15)[−(3/5)log(3/5)−(2/5)log(2/5)]+(5/15)[−(4/5)log(4/5)−(1/5)log(1/5)]}=0.971−0.888=0.083
g
(
Y
∣
X
2
)
=
.
.
.
=
0.324
g(Y|X2)=...=0.324
g(Y∣X2)=...=0.324
g
(
Y
∣
X
3
)
=
.
.
.
=
0.420
g(Y|X3)=...=0.420
g(Y∣X3)=...=0.420
g
(
Y
∣
X
4
)
=
.
.
.
=
0.363
g(Y|X4)=...=0.363
g(Y∣X4)=...=0.363
比较,特征X3(有自己的房子)的信息增益值最大,所以选择X3最为最优特征。
信息增益比:
g
R
(
Y
,
X
)
=
g
(
Y
,
X
)
/
H
(
Y
)
g_R(Y,X)=g(Y,X)/H(Y)
gR(Y,X)=g(Y,X)/H(Y)
三、生成决策树
3.1 ID3算法:在决策树的各个结点用信息增益准则选择特征点,递归地构建决策树。
接着上面的例子。由于特征X3的信息增益最大,所以选择X3最为根节点的特征,将训练集分为两个子集:是(Y1)和否(Y2),对于Y1,只有同一类的样本点,所以成为一个叶结点。对于Y2,需要从X1,X2,X3中选取新的特征。
计算其余三个特征的信息增益:
g
(
Y
2
,
X
1
)
=
H
(
Y
2
)
−
h
(
Y
2
∣
X
1
)
=
[
−
(
6
/
9
)
l
o
g
(
6
/
9
)
−
(
3
/
9
)
l
o
g
(
3
/
9
)
]
−
{
(
4
/
9
)
[
−
(
3
/
4
)
l
o
g
(
3
/
4
)
−
(
1
/
4
)
l
o
g
(
1
/
4
)
]
+
(
2
/
9
)
[
−
(
0
/
2
)
l
o
g
(
0
/
2
)
−
(
2
/
2
)
l
o
g
(
2
/
2
)
]
+
(
3
/
9
)
[
−
(
2
/
3
)
l
o
g
(
2
/
3
)
−
(
1
/
3
)
l
o
g
(
1
/
3
)
]
}
=
0.918
−
0.667
=
0.251
g(Y2,X1)=H(Y2)-h(Y2|X1) =[-(6/9)log(6/9)-(3/9)log(3/9)]-\{(4/9)[-(3/4)log(3/4)-(1/4)log(1/4)]+(2/9)[-(0/2)log(0/2)-(2/2)log(2/2)]+(3/9)[-(2/3)log(2/3)-(1/3)log(1/3)]\}=0.918-0.667=0.251
g(Y2,X1)=H(Y2)−h(Y2∣X1)=[−(6/9)log(6/9)−(3/9)log(3/9)]−{(4/9)[−(3/4)log(3/4)−(1/4)log(1/4)]+(2/9)[−(0/2)log(0/2)−(2/2)log(2/2)]+(3/9)[−(2/3)log(2/3)−(1/3)log(1/3)]}=0.918−0.667=0.251
g
(
Y
2
,
X
2
)
=
.
.
.
=
0.918
g(Y2,X2)=...=0.918
g(Y2,X2)=...=0.918
g
(
Y
2
,
X
4
)
=
.
.
.
=
0.474
g(Y2,X4)=...=0.474
g(Y2,X4)=...=0.474
选择信息增益最大的X2(有工作)最为节点的特征,到此,就可以完成分类任务了。(如果没有完成,那么接着往下算)

3.2 C4.5算法:在选择特征的时候,用信息增益比作为准则。
3.3 CART算法:是一颗二叉树,内部结点特征取值为“是”(左分支)或“否”(右分支)。使用基尼指数(Gini index)作为特征选择的标准。
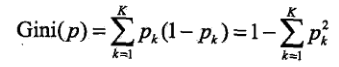

对于 二 中的例子,X1={1(青年),2(中年),3(老年)],X1={1,2},X2={1,2},X3={1(非常好),2(好),3(一般)}
第一步,求特征X1的基尼指数:
G
i
n
i
(
Y
,
X
1
=
1
)
=
(
5
/
15
)
{
2
∗
(
2
/
5
)
∗
[
1
−
(
2
/
5
)
]
+
(
10
/
15
)
[
2
∗
(
7
/
10
)
∗
[
1
−
(
7
/
10
)
]
)
]
}
=
0.44
Gini(Y,X1=1)=(5/15)\{2*(2/5)*[1-(2/5)]+(10/15)[2*(7/10)*[1-(7/10)])]\}=0.44
Gini(Y,X1=1)=(5/15){2∗(2/5)∗[1−(2/5)]+(10/15)[2∗(7/10)∗[1−(7/10)])]}=0.44
G
i
n
i
(
Y
,
X
1
=
2
)
=
.
.
.
=
0.48
Gini(Y,X1=2)=...=0.48
Gini(Y,X1=2)=...=0.48
G
i
n
i
(
Y
,
X
1
=
3
)
=
.
.
.
=
0.44
Gini(Y,X1=3)=...=0.44
Gini(Y,X1=3)=...=0.44
基尼指数最小的是最优切分点。
第二步,计算X2和X3的基尼指数
G
i
n
i
(
Y
,
X
2
=
1
)
=
0.32
Gini(Y,X2=1)=0.32
Gini(Y,X2=1)=0.32
G
i
n
i
(
Y
,
X
3
=
1
)
=
0.27
Gini(Y,X3=1)=0.27
Gini(Y,X3=1)=0.27
X2和X3只有一个切分点,都是最优切分点
第三步 计算X4的基尼指数
G
i
n
i
(
Y
,
X
4
=
1
)
=
.
.
.
=
0.36
Gini(Y,X4=1)=...=0.36
Gini(Y,X4=1)=...=0.36
G
i
n
i
(
Y
,
X
4
=
2
)
=
.
.
.
=
0.47
Gini(Y,X4=2)=...=0.47
Gini(Y,X4=2)=...=0.47
G
i
n
i
(
Y
,
X
4
=
3
)
=
.
.
.
=
0.32
Gini(Y,X4=3)=...=0.32
Gini(Y,X4=3)=...=0.32
基尼指数最小的是最优切分点。
第四步
Gini(Y,X3=1)=0.27最小,选择特征X3进行划分,一个是叶结点,对另一个节点继续用以上方法在X1,X2,X3中选择基尼指数最小的作为结点进行划分。
四、决策树的剪枝(防止过拟合)
4.1 预剪枝
对划分前后的泛化性能进行估计,计算信息增益之后,计算:以信息增益最大值所对应的特征进行数据划分,看划分精度。精度与划分前相比,是否增大,如果没有增大,不进行划分。
优点:预剪枝使得很多分支没有展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间。
缺点:有些分支虽当前不能提升泛化性。甚至可能导致泛化性暂时降低,但在其基础上进行后续划分却有可能导致显著提高,因此预剪枝的这种贪心本质,给决策树带来了欠拟合的风险。
4.2 后剪枝
(1)后剪枝先从训练集生成一颗完整的决策树。
(2)计算当前决策树的精度。
(3)挑选某一子树,只留下该子树的根节点,即该子树根节点变为整棵决策树的叶子节点。计算剪枝后的精度,如果提升了,则进行剪枝。
优点:保留了更多分支,欠拟合风险小。泛化能力好。
缺点:需要先生成一棵完整的决策树,训练时间和内存比较大。
五、优缺点
优点:易于理解和实现;对缺失值不敏感;一次构建可反复使用。
缺点:难以预测连续性字段;类别较多时,错误增加得快;特征间关联比较强的话,效果欠佳。














 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









