



 文章介绍了如何在Node.js环境中利用Crawlee和Playwright库创建网络抓取爬虫。首先,确保安装Node.js16或更高版本,然后通过npm安装Crawlee和Playwright。接着,创建并运行示例代码,该代码会抓取页面标题,将结果保存为JSON,并自动将链接添加到抓取队列。在遇到错误时,需修改package.json文件以解决运行问题。
文章介绍了如何在Node.js环境中利用Crawlee和Playwright库创建网络抓取爬虫。首先,确保安装Node.js16或更高版本,然后通过npm安装Crawlee和Playwright。接着,创建并运行示例代码,该代码会抓取页面标题,将结果保存为JSON,并自动将链接添加到抓取队列。在遇到错误时,需修改package.json文件以解决运行问题。
一、简介
crawlee——一个用于 Node.js 的网络抓取和浏览自动化库,可帮助您构建可靠的,快速的爬虫。
二、安装nodejs
Crawlee 需要Node.js 16 或更高版本。
三、安装crawlee
#创建文件夹
mkdir crawlee
#进入目录
cd creawlee
#初始化
npm init
运行结果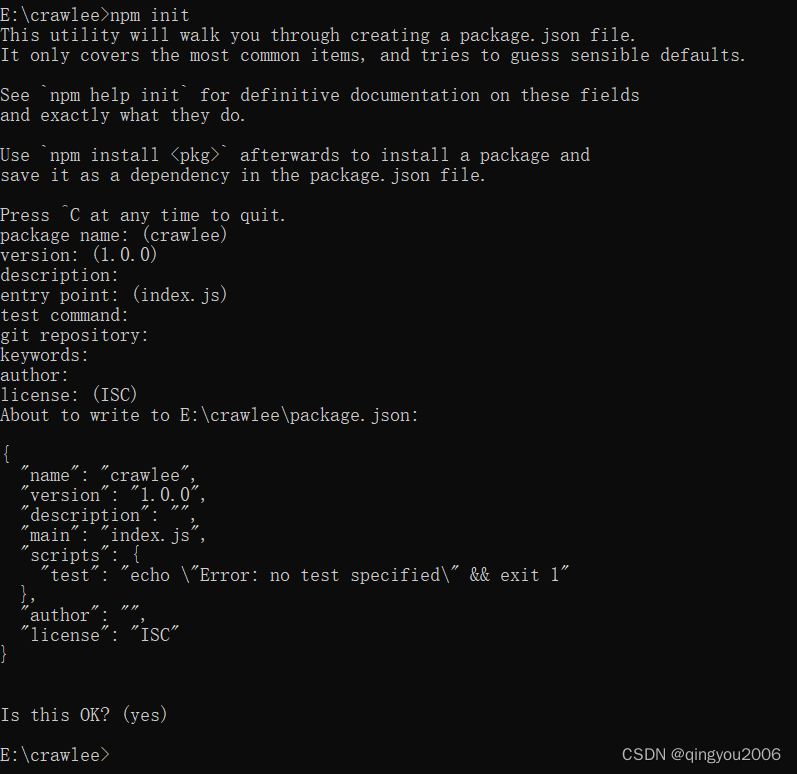
npm install crawlee playwright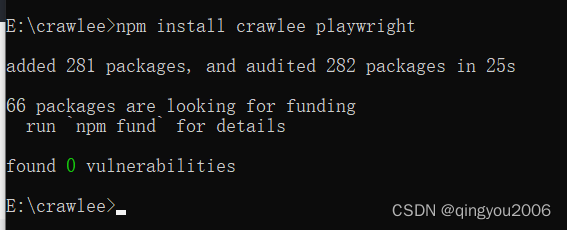
四、运行
创建index.js 文件,文件内容如下:
import { PlaywrightCrawler, Dataset } from 'crawlee';
// PlaywrightCrawler crawls the web using a headless
// browser controlled by the Playwright library.
const crawler = new PlaywrightCrawler({
// Use the requestHandler to process each of the crawled pages.
async requestHandler({ request, page, enqueueLinks, log }) {
const title = await page.title();
log.info(`Title of ${request.loadedUrl} is '${title}'`);
// Save results as JSON to ./storage/datasets/default
await Dataset.pushData({ title, url: request.loadedUrl });
// Extract links from the current page
// and add them to the crawling queue.
await enqueueLinks();
},
// Uncomment this option to see the browser window.
// headless: false,
});
// Add first URL to the queue and start the crawl.
await crawler.run(['https://crawlee.dev']);保存,运行程序
node index.js报错: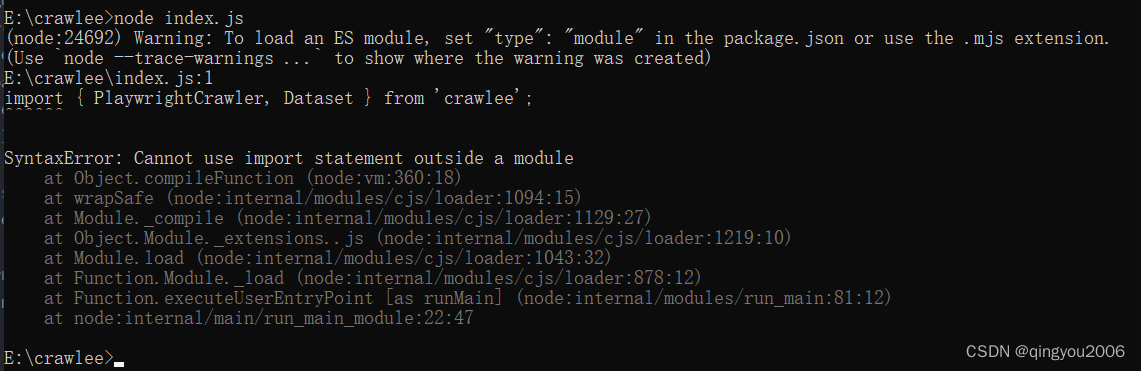
修改package.json文件,增加 "type":"module" 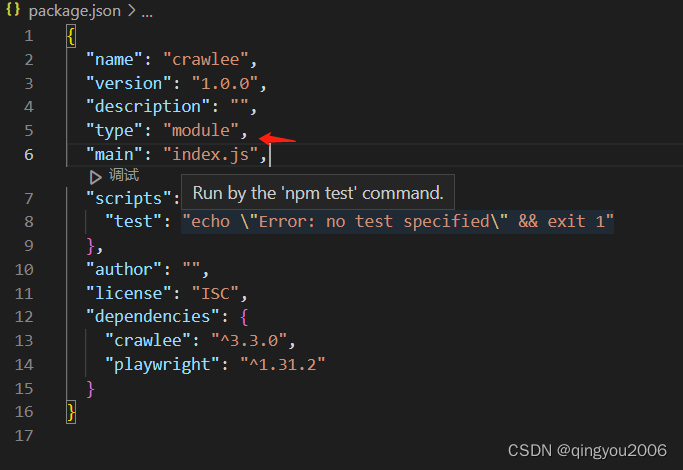
再次运行
node index.js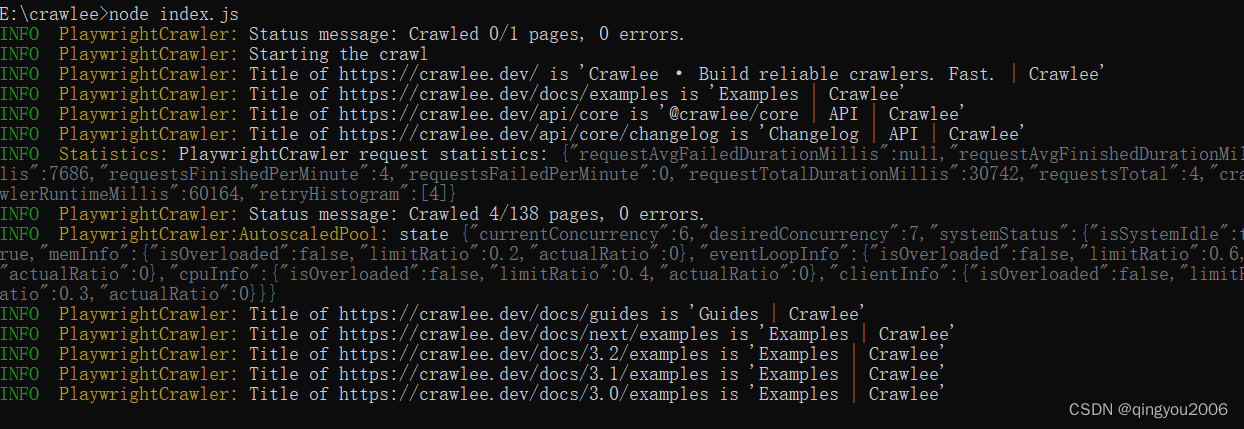 能获取出数据就说明运行成功了
能获取出数据就说明运行成功了


















 5754
5754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











