







今天想介绍一下有关SQL查询的语句,因为是关系到select的语法比较多,不想insert,delete,update这么单一。
select语句由几个组件或者说子句构成。不过在MySQL中,只有一种子句是必不可少的(select子句),通常的查询语句会至少包含6个子句中的2~3个。子句如下:
| 子句名称 | 使用目的 |
| select | 确定结果集中应该包含哪些列 |
| where | 过滤不需要的数据 |
| group by | 用于对具有相同列值的行进行分组 |
| having | 过滤掉不需要的组 |
| order by | 按一个或多个列,对最后结果集中的行进行排序 |
select子句:
如果只是需要执行一个内建函数或者对简单的表达式求值可以完全省略from子句,例如:

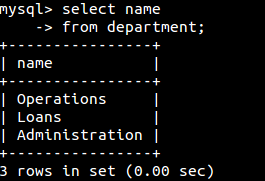
select子句主要还是用户在所以可能的列中,选择查询结果集要包含哪些列:
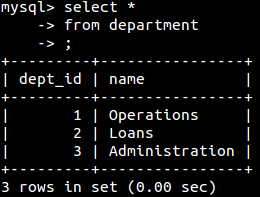
其中*号表示包含所以列: 也可以选择特定的列:
我们也可以在select子句中加上一些“调料”,例如:
| “调料” | 例子 |
| 字符 | 如数字或字符串 |
| 表达式 | 如transaction.amount*-1 |
| 调用内建函数 | 如ROUND(transaction.amount,2) |
| 用户自定义的函数调用 |
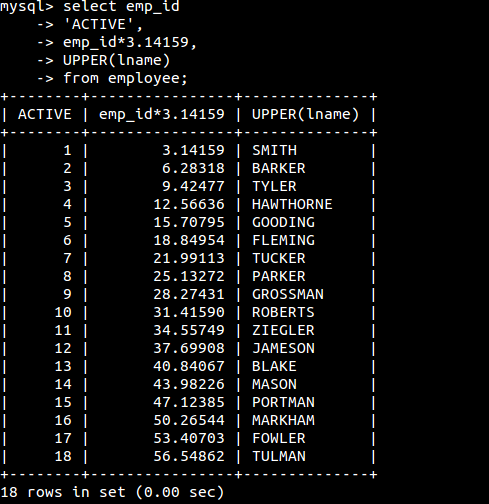
例子:
列的别名(as关键字):
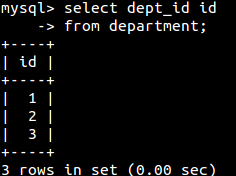
该句等于select dept_id as id from department;
去除重复行(distinct):
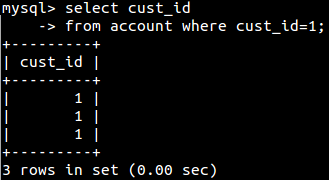
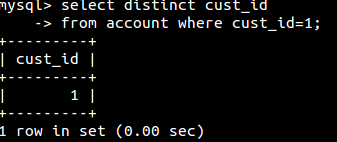
from子句:
from子句定义了查询中所用的表,以及连接这些表的方式:
这里的表有三种类型:
- 永久表(使用create table语句创建的表);
- 临时表(子查询所返回的表);
- 虚拟表(使用create view子句所创建的视图);
子查询产生的表的例子(其中e是表的别名,定义别名的方式与select子句中相同):
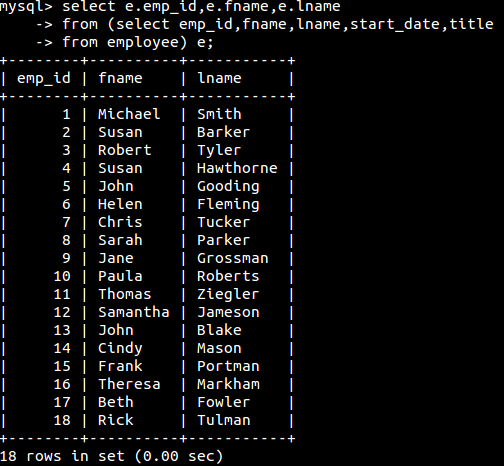
这个还是挺简单的,相信不需要我解释了。
下面详细介绍一下子查询:
子查询是指包含在另一个SQL语句(也称包含语句)内部的查询。子查询总是由括号包围,并且通常在包含语句之前执行。子查询如果基于是否与被单独执行分为:
非关联子查询:单独执行而不需要引用包含语句中的任何内容(如上面的子查询)。
一些与子查询有关的运算符:
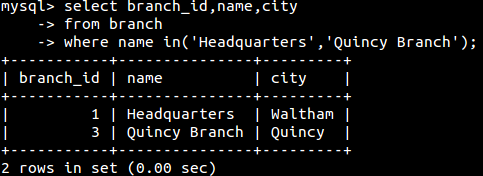
in和not in(包含和非包含):
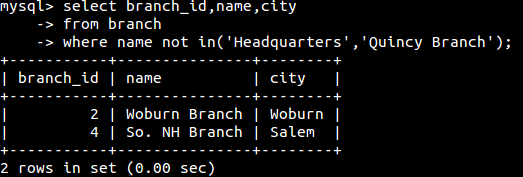
all(用于将某单值与集合中的每个值进行比较。构建这样的条件需要将其中一个比较运算符(=,<>,<,>等)与all运算符配合使用):
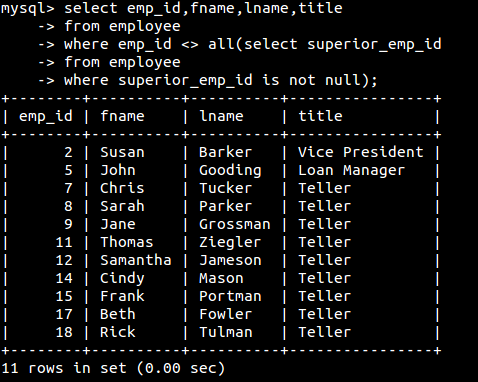
这个子查询再次返回所有主管的ID,同时包含查询返回ID不等于子查询结果集中所有ID的每个雇员数据。
any(any运算符也是将一个值与值集中每个成员相比较,与all不同是重要一个比较成立,则条件为真;使用all运算符时,只有与集合中的所有成员比较都成立时条件才为真):
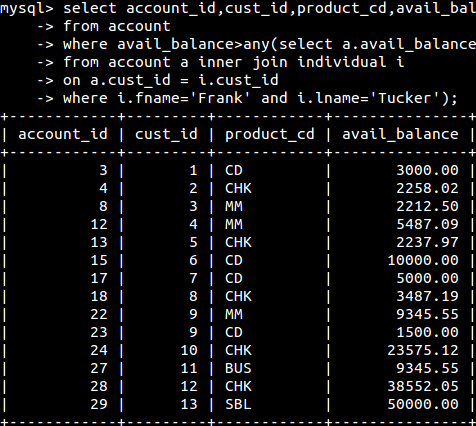
Frank有两个余额分别为$1057.75和$2212.50的账户,那么账户的余额最少为$1057.75时才能称为它的余额大于这两个账户中的任意一个。
关联子查询(与非关联子查询不同,关联子查询不是在包含语句执行之前一次执行完毕,而是为每一个候选行(这些行可能会包含在最终结果里)执行一次。)如:

这个查询首先利用关联查询计算每个客户的账户数,接着包含查询检索出那些拥有两个账户的用户。
exists运算符(用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False):

视图跟连接有机会再谈。
where子句:
where子句用于在结果集中过滤掉不需要的行。where语句后的判断为true的行才会包含在结果集中。
一些操作符:
and(和)与or(或)用于连接多个条件。
not(非操作)。
<,>,<>(不相等),=,!=。
between...and...(二者之间)
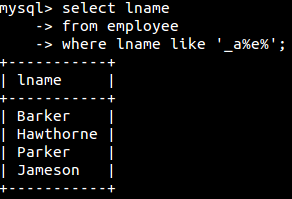
like(通常是使用通配符时候用到的,意思为提供的这种形式的行)
通配符:
| 通配符 | 匹配 |
| _ | 正好1个字符 |
| % | 任意数目的字符(包括0) |
regexp(后面使用正则表达式),如:
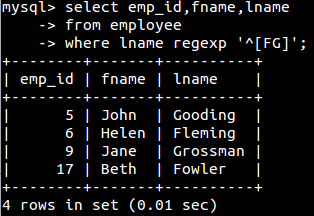
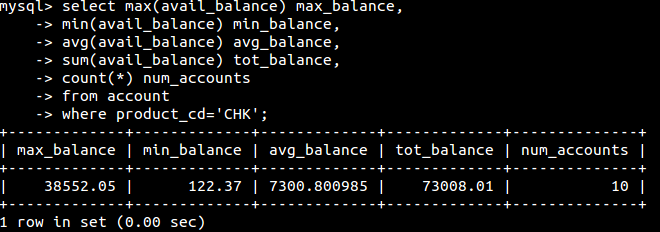
group by与having子句:
先看一个例子来理解分组:
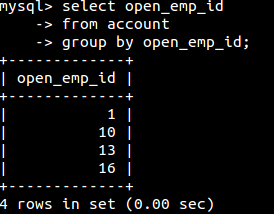
如果要知道分组后每组各有多少,可以使用count(),如:

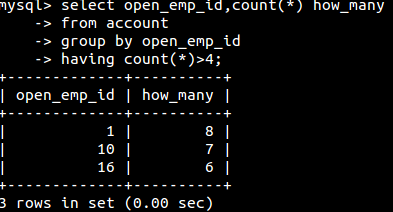
如果需要在使用聚焦函数作为过滤条件,不应该使用where(因为where执行时候分组还未被创建),而是使用having,如:

其中聚焦函数有:
| 函数名称 | 函数结果 |
| max() | 返回集合中的最大值 |
| min() | 返回集合中的最小值 |
| avg() | 返回集合中的平均值 |
| sum() | 返回集合中所有值的和 |
| count() | 返回集合中值的个数 |
如:
order by子句:
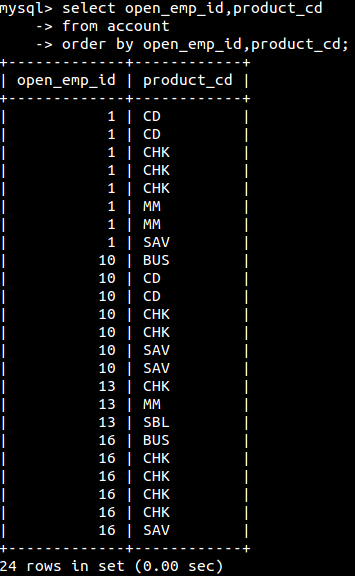
order by子句用于对结果集中的原始列数据或是根据列数据计算的表达式结果进行排序。
默认排序为升序(asc)。如果是字母升序则是按照字母排列升序(念一遍:ABCDEFG……):
降序(desc):
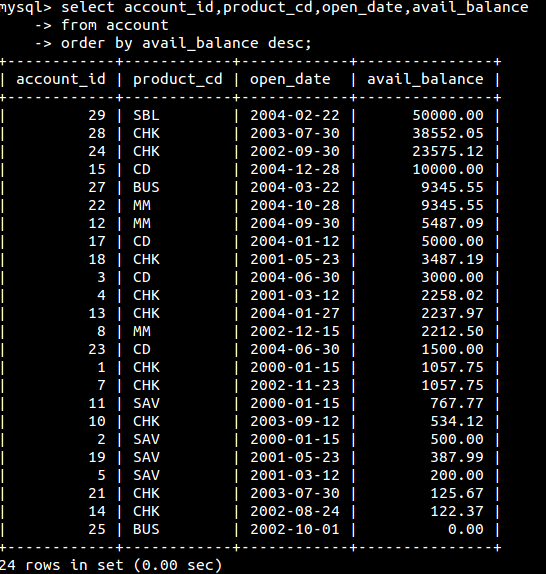
还可以根据表达式排序(right(n,m)是提取字段n中的最后m个字符):

还可以根据数字占位符进行排序:
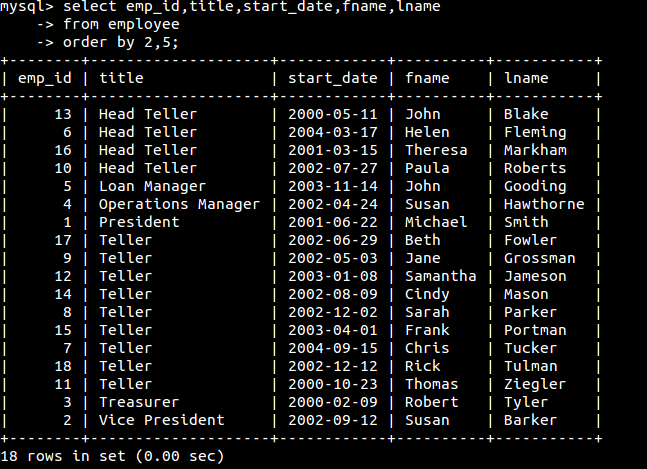
其中的2,5是指第二列跟第五列。















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









