







一. 环境准备
1. 三台机器(两个NameNode,三个DataNode)
备注:NameNode节点也可以当做DataNode
172.16.132.136 NameNode DataNode
172.16.132.179 NameNode DataNode
172.16.132.180 DataNode
2. 设置每台机器的主机名
hostnamectl set-hostname node136
hostnamectl set-hostname node179
hostnamectl set-hostname node180
3. 检查每台机器的主机名是否设置成功
hostname
4. 在/etc/hosts文件设置主机名和ip的映射关系

二. 设置机器之间的免密登录
1. 分别在node134 node135 node136生成秘钥(公钥和私钥)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
2. 分别进入node134 node135 node136的/root/.ssh目录下,拷贝公钥到本机器和其他机器(共9次)
以node134为例:
ssh-copy-id -i ~/.ssh/id_rsa.pub node134
ssh-copy-id -i ~/.ssh/id_rsa.pub node135
ssh-copy-id -i ~/.ssh/id_rsa.pub node136
3. 检验免密登录是否成功(每台机器都要测试)
ssh node134 ssh node135 ssh node136

三. zookeeper搭建(资源协调)
四. 集群搭建
1.jdk配置(每台机器配置的目录要一致)
下载jdk包之后解压到相应的目录,我的安装路径位:/opt/jdk1.8
安装后添加如下语句到/etc/profile中:
export JAVA_HOME=/opt/jdk1.8
export JRE_HOME=/opt/jdk1.8/jre
export CLASS_PATH=$CLASS_PATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin

添加完之后保存,使用source /etc/profile命令使配置生效;
2.配置Hadoop环境
下载hadoop的二进制安装包,解压到/opt目录下
安装后添加如下语句到/etc/profile中:
export HADOOP_HOME=/opt/hadoop-3.1.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

3. 修改配置文件(目录:/opt/hadoop-3.1.2/etc/hadoop)
vim hadoop-env.sh vim yarn-env.sh vim mapred-env.sh

4. 配置core-site.xml
<configuration>
<!--指定Hadoop的临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.2/tmp</value>
</property>
<!--指定HDFS中NameNode的地址-->
<!--在HA中需要和hdfs-site.xml中的dfs.nameservices属性保持一致-->
<!--普通集群中配置成:hdfs://node136:9000-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node136:2181,node179:2181,node180:2181</value>
</property>
</configuration>
5. 配置hdfs-site.xml
<configuration>
<!--数据备份数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--hdfs数据权限问题-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--名称自定义-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--这里高可用只配置两个namenode官方推荐3个,不超过5个-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1, nn2</value>
</property>
<!--配置对应的rpc-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node136:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node179:9000</value>
</property>
<!--http的地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node136:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node179:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node136:8485;node179:8485;node180:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-3.1.2/journal</value>
</property>
<!--配置自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(bin/true)
</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<!--name属性dfs.client.failover.proxy.provider.mycluster的mycluster必须和dfs.nameservices属性保持一致-->
<!--否则报错:java.net.UnknownHostException: mycluster-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
6. mapreduce-site.xml配置
<configuration>
<!--指定MapReduce运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--每个job运行完成之后的历史日志信息存入hdfs-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node136:10020</value>
</property>
<!--通过web查看历史作业的运行情况-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node136:19888</value>
</property>
<property>
<name>mapred.jobtracker.address</name>
<value>node136:9001</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADDOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!--指定mapreduce的lib库,否则无法运行wordcount实例-->
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop-3.1.2/share/hadoop/mapreduce/*, /opt/hadoop-3.1.2/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
7. yarn-site.xml
<configuration>
<!--开启高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmha</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node136</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node179</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node136:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node179:8088</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>node136:2181,node179:2181,node180:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8. 配置workers(既DataNode节点)

五. 启动集群
1.在node136上启动journalnode
hadoop-daemons.sh start journalnode
2. 在node136上格式化HDFS
hdfs namenode -format
3. 在node136上启动NameNode
hadoop-daemon.sh start namenode
4. 在node179上同步node136的信息
hdfs namenode -bootstrapStandby
5. 在node136上暂停NameNode
hadoop-daemon.sh stop namenode
6.在node136上格式化zk
hdfs zkfc -formatZK
7. 在node136上启动集群
start-all.sh
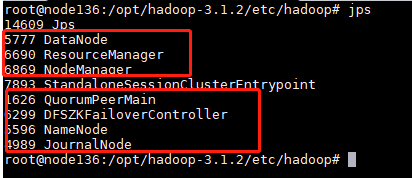
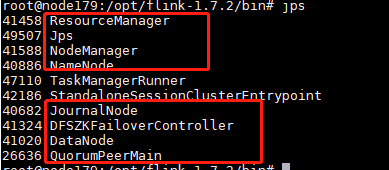
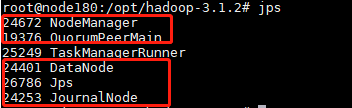
8.启动之后在各个节点查看进程jps
node136
node179
node180
9.查看页面
node136为active状态

node179为standby状态

10. 测试mapreduce功能
在hdfs中创建目录,并上传需要计算的文件(英文txt)

进入到/opt/hadoop-3.1.2/share/hadoop/mapreduce目录(hadoop自带的示例)

执行wordcount示例:hadoop jar hadoop-mapreduce-examples-3.1.2.jar wordcount /in /out
注意:在执行之前out目录一定是不存在的,hadoop不允许计算结果覆盖。

页面查看计算结果(下载到本地查看统计结果)

六. 编写自己的MapReduce功能
下会分享
















 1666
1666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











