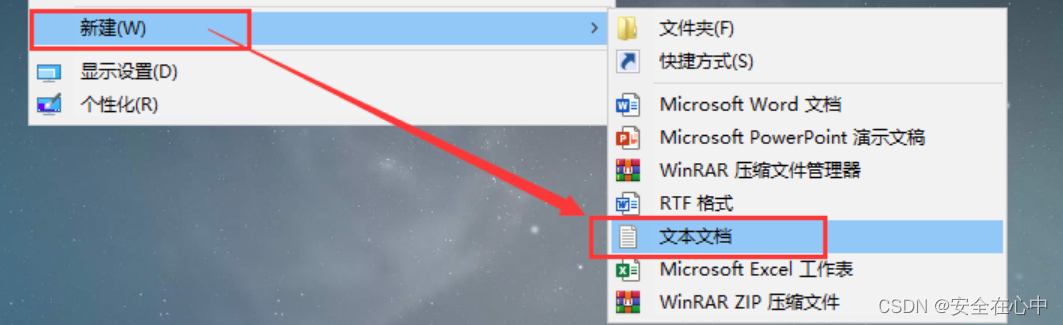
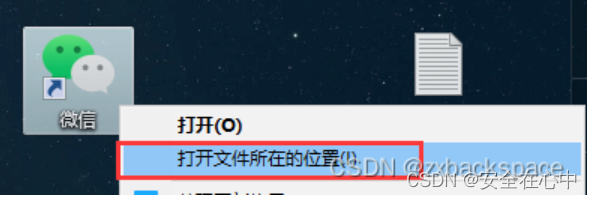
前言 工作需要,在一台电脑登录多个微信账号 一、快速回车 鼠标单击桌面微信快捷方式,快速按键盘回车键。 (需要开几个微信就回车几次,例如我想打开两个微信,快速按两次回车键) 二、创建批处理文件 1.桌面右键空白处,选择【新建】-【文本文档】新建的文本文档,如图: 新建的文本文档,如图: 2.右击桌面的微信快捷方式图标,选择【打开文件所在的位置】 3.如果打开的文件夹中微信图标左下角带有这个小箭头,说明这还不是微信程序的文件夹路径 此时出现的是此快捷方式所在目录,再次右键该快捷方式,选择【打开文件所在的位置】








 这篇博客提供了详细步骤教你如何在Windows 10/11上实现微信双开或多开。通过创建批处理文件和更换图标,轻松在电脑上同时登录多个微信账号。
这篇博客提供了详细步骤教你如何在Windows 10/11上实现微信双开或多开。通过创建批处理文件和更换图标,轻松在电脑上同时登录多个微信账号。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






