







对于IPVS技术,祁祁第一次了解到它是因为Kubernetes中的一个核心组件——kube-proxy。kube-proxy通过采用iptables + ipset + ipvs的方式实现了其提出的Service的概念,即为符合条件的Pod提供负载均衡。如果正在读这篇文章的你也是Kubernetes使用者,那你对我刚才说的这些一定不会陌生。如果你并没有使用过Kubernetes,没关系!因为这篇文章我只想单独对IPVS技术做一个全面的介绍,包括其由来,作用,用法以及工作原理。接下来,让我们先来了解一下IPVS到底是个什么高级东西 😉
一、IPVS跟LVS是什么关系?
1.1 LVS
如果你曾经搜索过有关ipvs的相关资料,那么LVS一定是每一篇介绍ipvs的资料中都会出现的字眼。维基百科用很简单的一句话介绍了LVS是什么:LVS是Linux操作系统中的负载均衡软件。
💡 祁祁有话讲:当我对LVS了解了一段时间后,从个人的角度出发,我并不认为LVS是实际提供负载均衡功能的软件,而是一个致力于为Linux系统提供负载均衡的项目。这点下面的介绍我也会说明。
LVS的概念就这个一句话,里面涉及到的专业术语只有两个:Linux操作系统和负载均衡。
- Linux操作系统:这个术语还需要我解释的话,这边建议先把基础补一补哈~
- 负载均衡:负载均衡的作用还是很容易能理解的,即为应用集群提供统一入口和请求分发的功能。如果你曾接触过
nginx或haproxy等这些负载均衡软件,那么你应该清楚,负载均衡的方式可以根据其作用的网络协议栈位置不同而划分为四层负载均衡和七层负载均衡。
细心的朋友应该会发现,上面维基百科中我还摘录了一段话,这一段话中提到了一个词——project,让我对LVS的真实定义产生了怀疑:LVS到底本身就是一个软件?还是说LVS代表了一个项目?
经过对官网提供的文档的阅读以及对LVS历史的了解,祁祁这里直接给出结论:LVS是一个项目,这个项目的目的是给Linux集群提供一个高性能、高可用的负载均衡服务器。因此,LVS项目有许多产物,例如四层代理——IPVS,七层代理——KTCPVS,此外,集群高可用常用的工具——Keepalived也用到了LVS项目中的IPVS技术。

相关文档📄以及链接🔗我放在下面,想深入了解LVS项目的朋友可以从这些地方入手:
- LVS官网:http://www.linuxvirtualserver.org/index.html
- Linux Virtual Server HOWTOs:http://www.austintek.com/LVS/LVS-HOWTO/HOWTO/
- Linux Virtual Server for Scalable Network Services: http://www.linuxvirtualserver.org/ols/lvs.pdf
综上,有关LVS的定义,可以得出一个结论:LVS代指LVS Project,其由章文嵩博士于1998年提出,该项目致力于为Linux操作系统提供负载均衡的方案,目前该项目已经产出了相关软件:四层代理——IPVS,七层代理——KTCPVS。LVS项目中提供如下的相关组件:

1.2 IPVS
前面我们用了比较大的篇幅介绍了LVS这个名词的具体含义,目的是想让正在读这篇文章的你能够避免对概念的纠结。LVS本质上代表一个项目,那这就意味着,LVS这个名词并不代表任何可用代码,它仅仅提供一种解决Linux系统负载均衡的思路。而真正提供负载均衡的工具,是LVS项目下的若干优秀组件。而IPVS就是LVS项目下为Linux系统提供四层负载均衡的一个工具。
IPVS技术与Netfilter一样,都是工作在内核态,且IPVS是基于Netfilter框架实现的,其可以在数据包到达四层协议栈时对数据包进行处理。
有关IPVS详细的知识点在本文后面的部分会进行详细说明,这里只简单介绍。
1.3 KTCPVS
LVS项目中,为Linux操作系统提供四层代理的是IPVS技术,而提供七层代理的则是KTCPVS技术,即Kernel TCP Virtual Server。这项技术同样是运行在内核态里的,设计的初衷是减少用户态进行7层代理时频繁触发的上下文切换等比较消耗资源的行为。但KTCPVS最后一次的提交记录是2004年12月18日,且祁祁从业以来也一直没有真正使用过这项技术,如果你用过这项技术,欢迎在评论区跟大家分享交流!官网介绍点此跳转。
1.4 Keepalived
为服务器做过高可用的朋友想必对keepalived这个工具并不陌生。keepalived除了通过使用VRRP协议来提供高可用的功能外,还使用到了IPVS技术来提供负载均衡的能力。具体的配置和使用方式本文不做讲解,只简单介绍,官网介绍点此跳转。
二、IPVS介绍
在简单了解了IPVS是什么,从哪里来之后,就可以开始对IPVS进入更深入的学习了。首先,我们从IPVS工作原理开始讲起。
2.1 IPVS与Netfilter
IPVS现在已经成为内核的一部分,内置在了Netfilter框架中。等等!Netfilter不是在之前介绍iptables的时候就介绍过吗?没错,这里的Netfilter框架和iptables使用的Netfilter框架就是一样的。
之前的文章里面我们介绍过,Netfilter为包过滤提供了5个Hook点。而IPVS起作用的方式,也就是将其相关处理函数挂载到Netfilter框架提供的LOCAL_IN、FORWARD和LOCAL_OUT这三个Hook上。可以用下面的图表示引入ipvs后的包过滤流程:

上图是祁祁自制的,为确保其准确性,我这里贴出IPVS注册Hook的相关代码(“什么?😱你有代码恐惧症?”。不用担心,这篇文章不是源码剖析系列的,所以不会通篇都是源码,这里只是做一个事实依据而已。)
static const struct nf_hook_ops ip_vs_ops4[] = {
/* After packet filtering, change source only for VS/NAT */
{
.hook = ip_vs_out_hook,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC - 2,
},
/* After packet filtering, forward packet through VS/DR, VS/TUN,
* or VS/NAT(change destination), so that filtering rules can be
* applied to IPVS. */
{
.hook = ip_vs_in_hook,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC - 1,
},
/* Before ip_vs_in, change source only for VS/NAT */
{
.hook = ip_vs_out_hook,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST + 1,
},
/* After mangle, schedule and forward local requests */
{
.hook = ip_vs_in_hook,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST + 2,
},
/* After packet filtering (but before ip_vs_out_icmp), catch icmp
* destined for 0.0.0.0/0, which is for incoming IPVS connections */
{
.hook = ip_vs_forward_icmp,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_FORWARD,
.priority = 99,
},
/* After packet filtering, change source only for VS/NAT */
{
.hook = ip_vs_out_hook,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_FORWARD,
.priority = 100,
},
};
对上面的源码进行必要的说明:
- 该源码对应的内核版本为:
6.x。为什么特别声明内核版本,是因为不同版本的内核,ipvs的函数名称和注册hook的位置都不一样。比如有hook到POST_ROUTING的,有函数名叫ip_vs_reply4的。如果你想自己琢磨内核源码,看到不一样的请不要慌张,其提供的功能大致都一样。 .priority是起什么作用?之前在介绍iptables的时候我提到过:内置表被Netfilter调用是有先后顺序的。这个先后顺序从哪里来的?就是这个字段规定的。内核源码中与之相关的枚举量我在这里贴出来:
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_RAW_BEFORE_DEFRAG = -450,
NF_IP_PRI_CONNTRACK_DEFRAG = -400,
NF_IP_PRI_RAW = -300,
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_HELPER = 300,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
NF_IP_PRI_LAST = INT_MAX,
};
请记住:数值越小,优先级越高!
通过优先级,你就可以知道ipvs注册进Netfilter框架后,它的相关函数是在哪个流程的后面或者是前面,比如注册在NF_INET_LOCAL_IN位置的ip_vs_out_hook函数,其优先级为NF_IP_PRI_NAT_SRC - 2,即100 - 2 = 98,因此,当包过滤流程执行到LOCAL_IN这个Hook点时,会根据下面的流程来进行过滤:
mangle(-150) --> filter(0) --> security(50) --> ip_vs_out_hook(98) --> ip_vs_in_hook(99)
2.2 IPVS工作原理
在了解了IPVS与Netfilter的关系以及IPVS工作的位置之后,对于IPVS的工作原理其实就比较好理解了:IPVS通过在Netfilter框架中的不同位置注册自己的处理函数来捕获数据包,并根据与IPVS相关的信息表对数据包进行处理,按照IPVS规则中定义的不同的包转发模式,对数据包进行不同的转发处理。
对于上面这个概念,有两个部分需要作说明:
- IPVS相关的信息表由谁维护?毫无疑问是由用户维护,IPVS对应用户空间的管理工具
ipvsadm为用户提供了写入规则的入口。没错,这和iptables / netfilter之间的关系是非常类似的。 - IPVS有哪些包转发模式:
NAT、IP tunneling和Direct Routing。
接下来我们针对这两个部分详细来介绍一下。不过,说了这么多理论概念上的东西,也是时候将这些理论概念落到实际场景中了,所以!我们先来将ipvsadm工具给用起来!
三、ipvsadm
ipvsadm是位于用户空间,为用户提供了向IPVS中写入规则的一个管理IPVS必备的工具。这里简单介绍一下工具的使用。这部分内容建议实操哦~我建议你搭建一套环境,我的环境配置如下:
| 主机名 | 配置 | IP地址 |
|---|---|---|
| my-laptop | 笔记本电脑(MacBook) | 192.168.0.101 |
| loadbalance | 虚拟机(CentOS 7.9) | 192.168.0.102 |
| realserver | 虚拟机(CentOS 7.9) | 192.168.0.105 |
3.1 安装工具
一般来说,ipvsadm工具并不会在安装Linux系统时默认安装,因此我们需要先手动将工具安装进操作系统。不过,你也还是可以先输入ipvsadm来判断系统中是否已经安装好了工具:
[root@loadbalance ~]# ipvsadm
-bash: ipvsadm: command not found
如果提示command not found的话,就以为这命令没有被安装哦~这时我们需要安装一下:
[root@loadbalance ~]# yum install ipvsadm -y
安装完成之后,我们再输入ipvsadm命令:
[root@loadbalance ~]# ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
这时,就意味着命令已经安装成功了!
3.2 man ipvsadm
当我们对一个命令不太熟悉时,看博客当然是一个比较好的学习方式。但祁祁推荐用官方的新手指引:man命令。用man去学习某个命令的时候,一方面你能够了解到这个命令最全面的知识,另一方面,用这机会学专业英语它不香吗😎!下面就让我来带你浅浅了解一下ipvsadm这个工具吧。废话不多说,直接上图!

当你输入man ipvsadm时,你就能看到上图所展示的这些内容,这些内容层次分明,条理清晰,就像祁祁的博客一样🤪。
3.2.1 NAME
这部分介绍ipvsadm这个名词的意义是什么,Linux Virtual Server administration即Linux系统虚拟服务器管理工具
3.2.2 SYNOPSIS
这部分主要给出了一些ipvsadm命令的常见用法,比如ipvsadm -h就是获取帮助文档等,如果你曾经了解过ipvsadm命令,却因为很久没用而忘记了某些用法的格式,通过SYNOPSIS部分的内容你可以很快就捡起来。
3.2.3 DESCRIPTION
这部分就是你了解一个命令最需要细读的部分,因为这部分不仅介绍了这个命令是用来干嘛的,还介绍了这个命令应该怎么用,它的语法格式是什么样子的等等。对于ipvsadm命令,其描述是这个样子的:
- 命令介绍:

ipvsadm是一个用来管理位于Linux内核中virtual server table(虚拟服务器表)的工具。Linux Virtual Server(LVS)可以用来建立基于两个或多个节点的集群的可扩展网络服务。集群中对外提供服务的节点(active node)会将客户端发出的请求转发到实际提供服务的节点上(server hosts)。LVS提供:
两种协议的转发:TCP和UDP。
三种包转发方式:NAT,tunnling,direct routing。
八种负载均衡的算法:round robin,weight round robin,least-connection,weighted least-connection,locality-based least-connection,locality-base least-connection with replication,destination-hashing以及source-hashing。
ok,假设你已经读完了上面的描述,请你回答这几个问题:你是否清楚IPVS提供什么功能?你是否清楚IPVS对哪些协议提供功能?你是否清楚IPVS怎样提供这样的功能?这种小学难度的阅读理解简直不要太简单。假设你已经得到了答案,现在,你是否感受到了man ipvsadm的强大之处😎?
- 命令语法格式:

执行ipvsadm有两种基本格式:
1. ipvsadm COMMAND [protocol] service-address
[scheduling-method] [persistence options]
2. ipvsadm command [protocol] service-address
server-address [packet-forwarding-method] [weight options]
第一种格式用来管理一个虚拟服务对象(virtual service),这个格式的命令可以用来给这个虚拟服务指定后端服务器的均衡算法(algorithm),同时,你也可以通过这种格式的命令为这个虚拟服务配置长链接等参数。总之,这种格式是用来管理虚拟服务对象的。
第二种格式用来在一个已存在的虚拟服务对象(virtual service)里管理其后端真实服务器(real server)。你可以通过这种格式来指定某个后端服务器的转发规则(packet-forwarding method)以及其权重(weight)。如果你不指定的话,就会用默认值。
ok,到这里,我们就一定粗略了解了ipvsadm这个命令的基础用法,有很重要的一点值得我们注意:命令格式。命令格式告诉我们,如果我们要管理处于内核的虚拟服务表(virtual server table)中的数据,那命令的基本格式就一定是这个样子。当我们输入的命令被提示未识别的参数等错误时,命令格式能给我们提供很好的错误自查参考。
再详细的介绍如果你感兴趣的话,可以自己man ipvsadm去学习哦~接下来,让我们把命令用起来!登陆到你的Linux系统,跟着我一起来💪!
3.3 小试牛刀
3.3.1 查看规则
ipvsadm查看规则的参数与iptables很像但又不完全像。iptables查看规则的命令是:
iptables -nL
而ipvsadm查看规则的命令是:
ipvsadm -Ln
这是因为,ipvsadm中,-L属于COMMAND部分,而-n属于PARAMETER部分。结合我们刚才了解到的语法格式,会发现COMMAND部分是紧跟ipvsadm命令后面的,所以-L一定要在-n的前面才行。
如果是裸机的话,那你的输出应该和我的一样,啥都没得~
[root@loadbalance ~]# ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
3.3.2 添加一个虚拟服务器
现在,我们来搞一个虚拟服务器,为了不让你们因为节点信息来回翻页面,我把我的环境配置再贴一次,我都这么贴心了,不给个点赞关注😭?
| 主机名 | 配置 | IP地址 |
|---|---|---|
| my-laptop | 笔记本电脑(MacBook) | 192.168.0.101 |
| loadbalance | 虚拟机(CentOS 7.9) | 192.168.0.102 |
| 虚拟服务器IP:192.168.0.123 | ||
| realserver | 虚拟机(CentOS 7.9) | 192.168.0.105 |
这部分的操作均在
loadbalance机器上进行。
我们先创建一个虚拟IP地址(Virtual IP Address,即VIP):192.168.0.123
[root@loadbalance ~]# ip addr add dev ens33 192.168.0.123/32
[root@loadbalance ~]# ipvsadm -A -t 192.168.0.123:80 -s rr
[root@loadbalance ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.222:80 rr
命令说明:
- -A:append:添加一个虚拟服务器;
- -t:tcp-service:对tcp协议作转发;
- 192.168.0.123:80:service-address:VIP地址以及端口号;
- -s:schduler:均衡算法;
- rr:round robin:将工作平均分配给可用的真实服务器的算法。
你看,是不是符合之前说的基本命令格式:
ipvsadm COMMAND [protocol] service-address [scheduling-method]
3.3.3 添加一个后端真实服务器
接下来我们为上面新增的虚拟服务器添加后端真实服务器。
这部分的操作均在
loadbalance机器上进行。
[root@loadbalance ~]# ipvsadm -a -t 192.168.0.123:80 -r 192.168.0.105:80 -g -w 1
[root@loadbalance ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.123:80 rr
-> 192.168.0.105:80 Route 1 0 0
命令说明:
- -a:append:添加一个后端真实服务器
- -t:tcp-service:转发tcp协议
- 192.168.0.123:80:service-address:刚才新增的虚拟服务器地址
- -r:real-server:后端真实服务器地址
- -g:Direct Routing转发模式
- -w:weight:权重
同样的,这里的命令也跟之前说的命令格式是一样一样的:
ipvsadm command [protocol] service-address server-address [packet-forwarding-method] [weight options]
同时,你有没有注意到,虚拟服务器的添加是-A,后端服务器的添加是-a,你再看看两种基本命令格式的区别,虚拟服务器的管理给的是COMMAND,而后端服务器的管理给的是command。也就是说:同样的字母,大写代表管理虚拟服务器,小写代表管理后端服务器。除了-A/-a之外,还有-E/-e(edit)以及-D/-d(delete)都是这样的。
3.3.4 验证
到这里我们已经成功向loadbalance机器添加了一个虚拟服务器,那我们是不是要验证一下这个玩意儿确实起作用了呢?
现在,我们先在realserver机器上运行一个8080端口的服务:
[root@realserver ~]# python -m SimpleHTTPServer 80
Serving HTTP on 0.0.0.0 port 80 ...
先来验证一下服务是否可用,在my-laptop机器上访问realserver的8080端口:
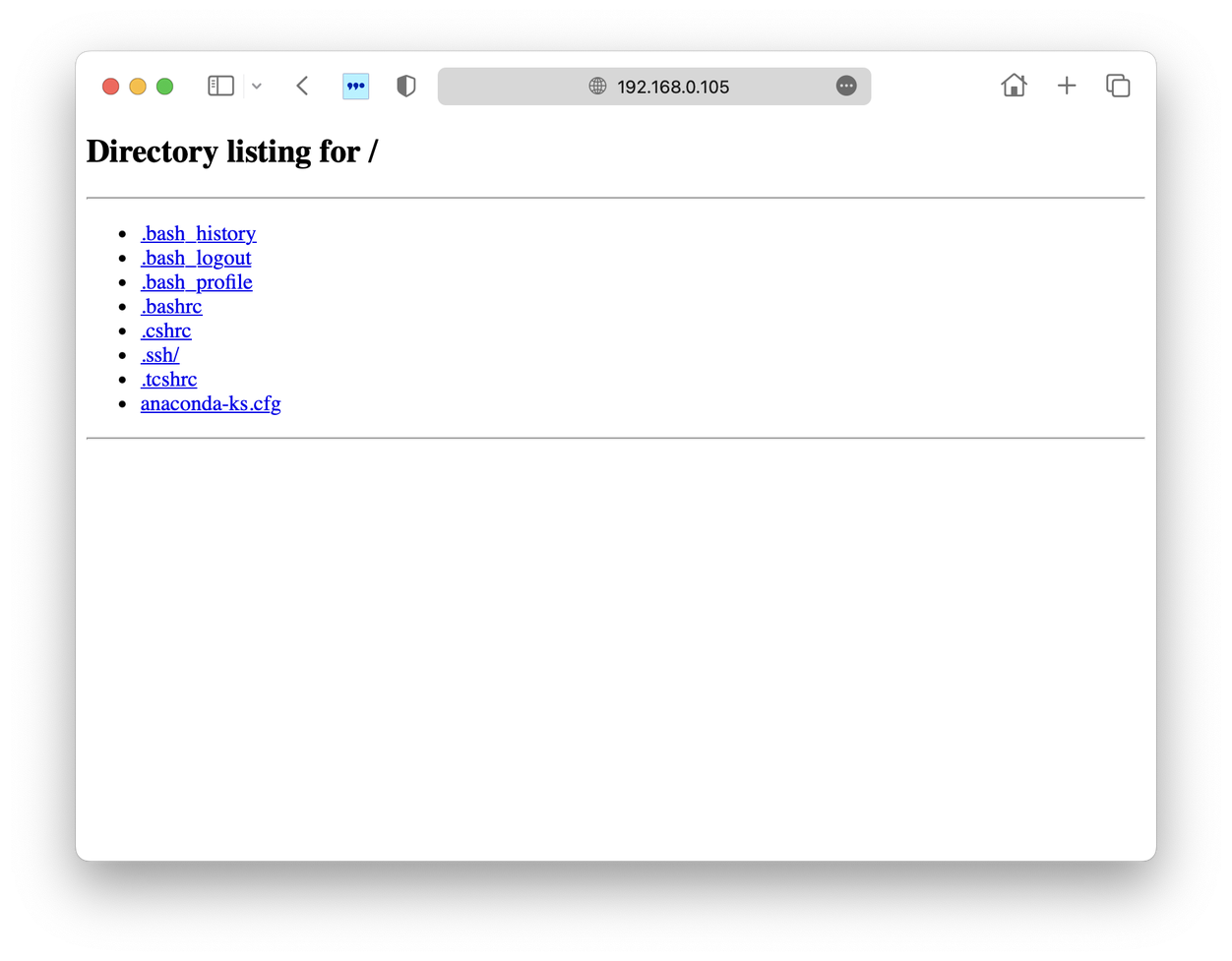
ok,服务可用,且这是我们期待的内容。现在我们访问刚才创建的虚拟服务器地址:192.168.0.123:80。
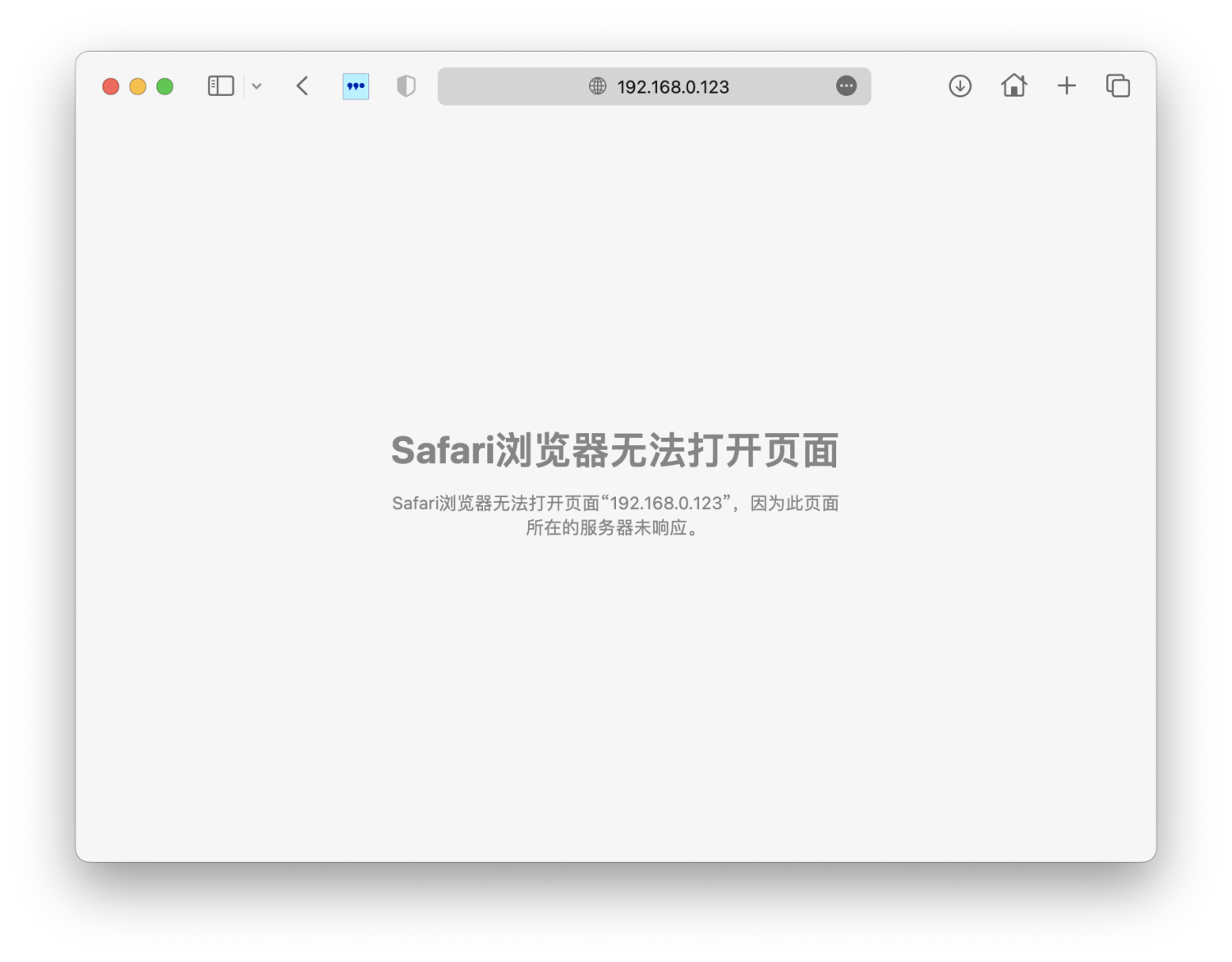
哎!为什么不好使呢?其实这和我们搭建的环境以及使用的包转发模式有关系。在Direct Routing模式下,后端服务器需要添加一个IP地址为VIP地址的网卡才行,在realserver机器上执行下面的命令:
[root@realserver ~]# ip link add dummyvip type dummy
[root@realserver ~]# ip addr add dev dummyvip 192.168.0.123/32
再次访问:
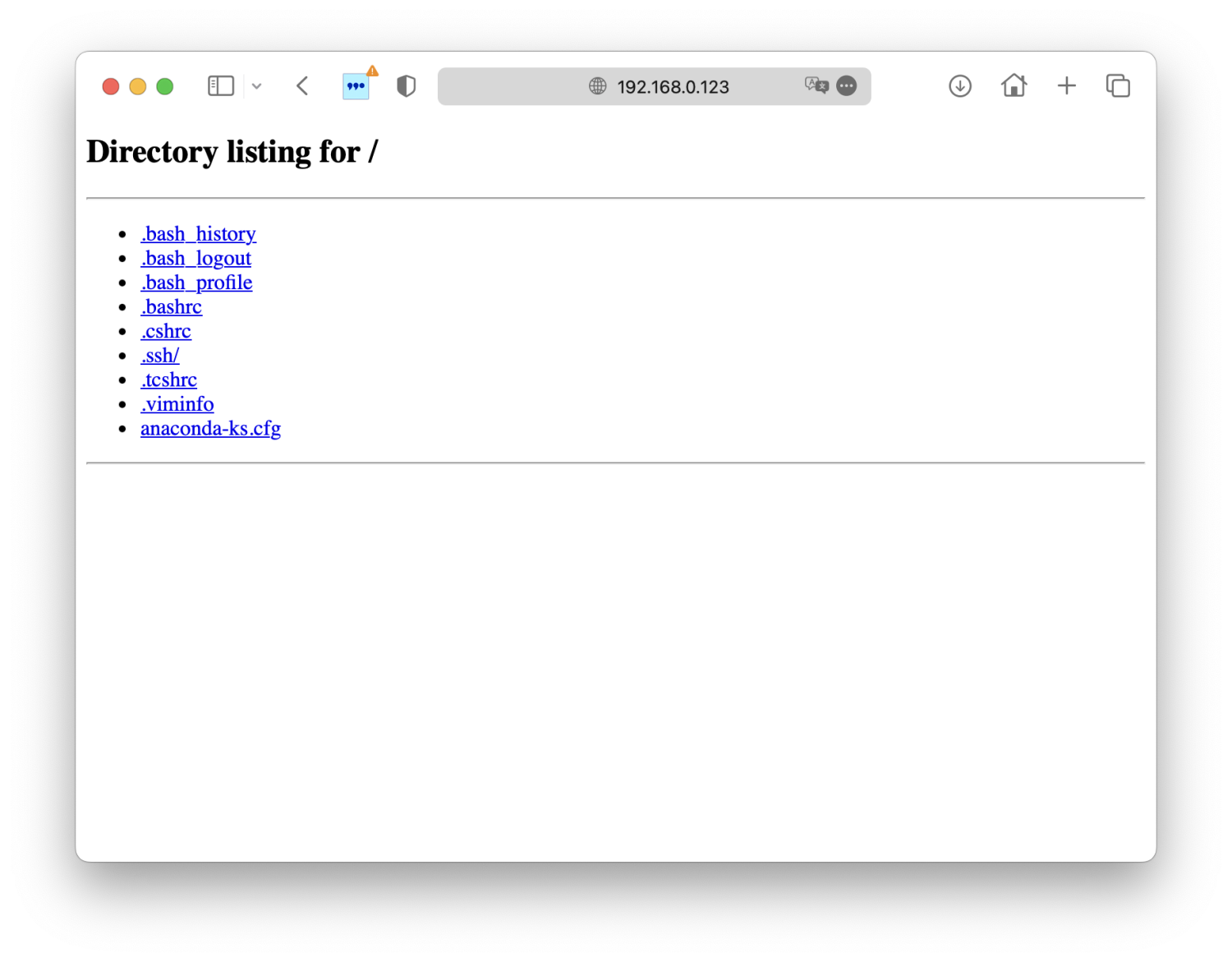
ok,可以正常访问了。至于为什么会这样,这里先留个悬念,等我们了解完IPVS工作模式之后,你自然会明白这个配置的意义在哪。
3.3.5 专有名词
有关专业名词这个部分,我思来想去还是放在这里比较好。因为我们刚才已经实际进行过一次ipvs的配置了,有这一部分经验后理解专业名词会轻松很多。有关ipvs,甚至LVS项目中的其他软件,有如下的一些专有名词。请熟记,后续文章将用专有名字表示相关概念:
- DS:Director Server:即负载均衡器(主导服务器)。
- RS:Real Server:后端真实的工作服务器。
- VIP:Virtual IP Address:即虚拟服务IP地址,这个其实就是
iptables -A后面紧跟的地址。这个IP也是DS对外的IP地址。 - DIP:Director Server IP,为负载均衡器的IP地址,这是DS对内的地址。
- RIP:Real Server IP,后端服务器的IP地址。
- CIP:Client IP,访问客户端的IP地址。
四、IPVS包转发模式
在上面小试牛刀的部分我们在DS(Director Server,负载均衡器)上配置了VIP(虚拟IP)对应的RS(Real Server,后端服务器),其中我们使用到了-m的参数,这个参数表示这个后端服务器的转发模式为NAT模式,此外,IPVS还提供另外两种转发模式的参数。IPVS提供的所有包转发模式一共有三种:
-m:NAT,也称作伪装模式(masquerading)。-g:Direct Routing,默认模式,也成网关模式(gatewaying);-i:IP Tunneling,也称作 ipip 封包模式(ipip encapsulation);
4.1 NAT模式
NAT,全称Network Address Translation,常用于局域网与外部网络通信的场景中。当外部网络访问局域网内服务时,通常会访问一个NAT网关,然后由NAT网关对数据包做DNAT的操作,将目的地址指向局域网内的服务;而当局域网内的机器想访问外部网络服务时,NAT网关则会对数据包做SNAT的操作,将其源地址指向NAT网关的对外地址。
4.1.1 工作原理
以NAT模式进行包转发的场景下,一个由外部网络发出的,访问局域网内服务的数据包会经历下面的流程:
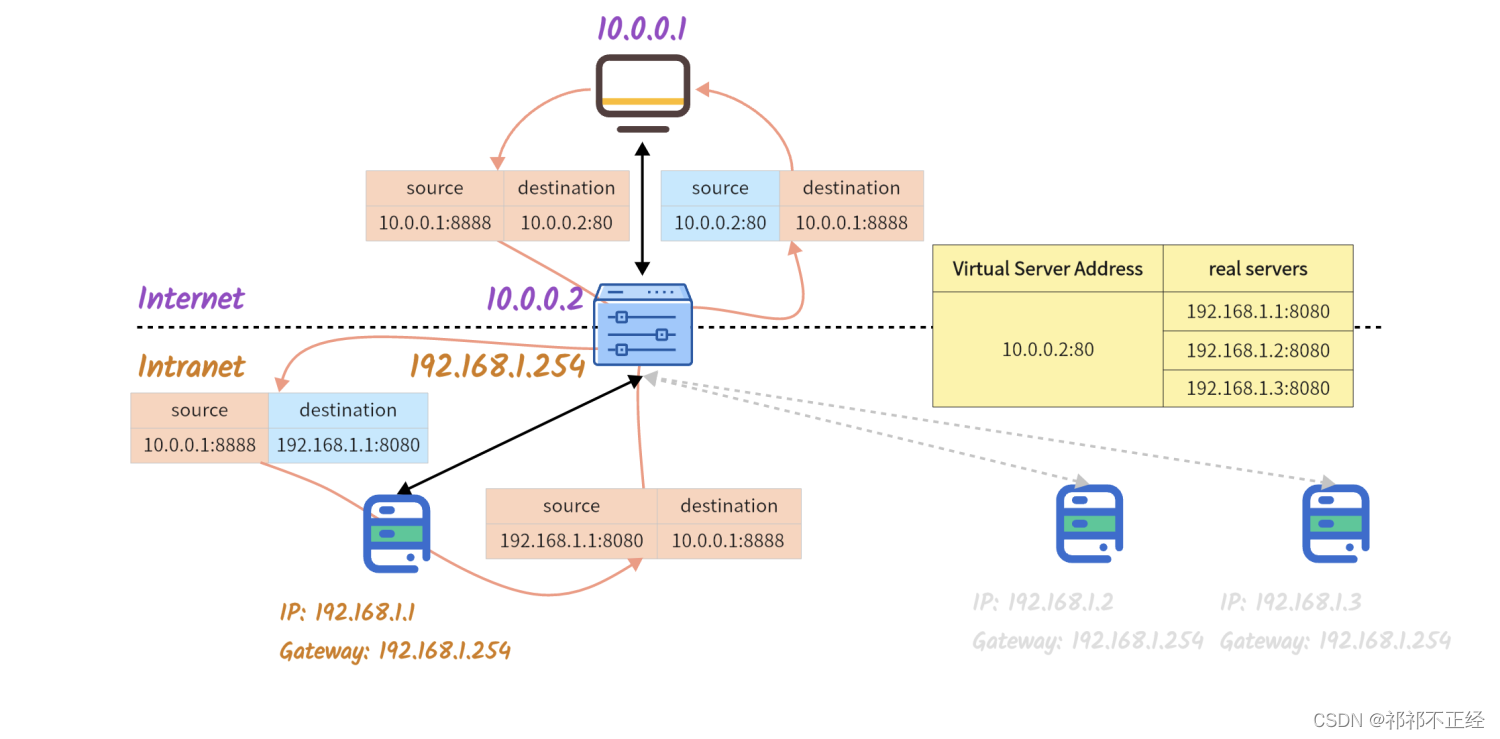
- 外部网络CIP
10.0.0.1:8888访问DS的VIP10.0.0.2:80,发出数据包; - DS通过IPVS规则,找到该数据包实际要转发的RS
192.168.1.1:8080; - 找到RS信息后,DS将数据包的目的地址和端口换成IPVS规则中配置的RS记录,并将这条连接添加到记录
ESTABLISHED类型连接的哈希表中,如果后续有相同源地址端口的数据包到来,负载均衡将根据哈希表记录统一转发给同一个RS; - DS
192.168.1.254发出修改后的数据包; - 数据包到达RS
192.168.1.1,RS处理完成后,通过默认网关192.168.1.254将数据包发回DS192.168.1.254; - DS收到RS返回的数据包后,对该数据包的源地址和端口做转换,更换成对应VIP和端口;
- DS通过其与外部网络相连的网卡
10.0.0.2将数据包发出去; - 外部网络CIP
10.0.0.1收到数据包; - 连接结束,DS删除位于
ESTABLISHED哈希表中的相关数据。
4.1.2 适用场景
刚才提到了,NAT通常用于局域网与外部网络通信的场景,因此,NAT模式适用于通信发生在局域网与外部网络之间的场景。因此有如下的要求:
- DS提供至少两个IP,一个连接外部网络(VIP),一个连接局域网(DIP);
- 处于局域网内的RS必须以DS为默认网关;
4.2 Direct Routing模式
Direct Routing,从字面意义上的直接路由来理解获取还有些不解,但如果从官方给的另一种描述理解获取就能明白其真正含义——Gatewaying,即网关模式。这种模式可以将DS看作是外部网络CIP访问RS的网关(而不是RS访问外部网络的网关),客户端CIP访问VIP后,由DS将数据包转发到RS上,RS处理完成后直接由RS通过RIP返回给客户端CIP,无需经过DS。
4.2.1 工作原理
以Direct Routing模式进行包转发的场景下,一个由外部网络发出的,访问局域网内服务的数据包会经历下面的流程:
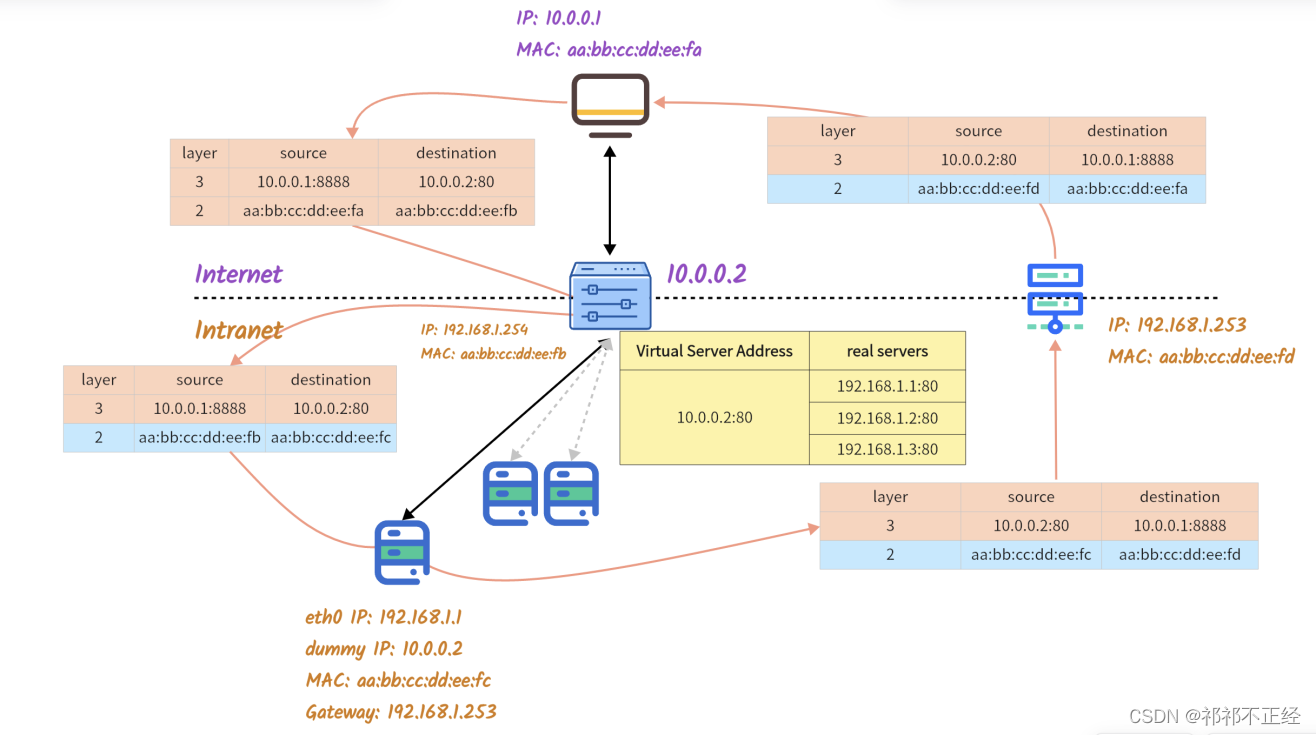
- 外部网络CIP
10.0.0.1:8888访问DS的VIP10.0.0.2:80,发出数据包; - DS通过IPVS规则,找到该数据包实际要转发的RS
192.168.1.1:80; - 找到服务器信息后,DS根据其自身的MAC地址映射表将数据包的源MAC地址和目的MAC地址换成IPVS规则中配置的RS所对应的MAC地址,并将这条连接添加到记录
ESTABLISHED类型连接的哈希表中,如果后续有相同的数据包到来,DS将根据哈希表记录统一转发给同一个RS; - DS发出修改后的数据包;
- 数据包到达RS,由于RS也配置了VIP,即dummy网卡上配置的
10.0.0.2地址,因此RS会将该数据包发送至本机处理; - RS处理完成后,通过默认网关
192.168.1.253将数据包发出; - 外部网络CIP
10.0.0.1收到数据包; - 连接结束,DS删除位于
ESTABLISHED哈希表中的相关数据。
4.2.2 适用场景
Direct Routing模式的适用场景要跟NAT模式对比可能更好理解一些。NAT模式下,所有的数据包NAT操作都经过DS,同时,不管是请求报文还是应答报文,都是通过DS来转发的。因此,当RS的数量很多时,NAT模式瓶颈就显而易见了。
而Direct Routing模式下,DS只需要处理请求报文而不关心应答报文。因此大大降低了DS的性能损耗。因此,当RS数量比较多的情况下,采用Direct Routing要更好一些。且由于Direct Routing模式下RS直接向客户端CIP返回数据,因此当客户端CIP和RIP处于统一局域网下时,Direct Routing的转发效率会更高一些,因为可以直达。
然而,Direct Routing转发模式并不是万金油,它对网络环境有如下的要求:
- DS和RS在
同一子网下,目的是DS知道RS的MAC地址是多少; - RS必须生成一个拥有
VIP的网卡,目的是让目的地址是VIP的数据包能够被本机获取并处理。
4.2.3 注意事项
- 与NAT模式不同,Direct Routing模式,包括接下来要介绍的IP Tunneling模式,都不会对传输层的数据做修改,即不会对端口做修改。因此,在这两种模式下,IPVS虚拟服务器配置的端口
10.0.0.2:80必须和RS提供服务的端口192.168.1.1:80一致。 - 由于RS也配置了VIP
10.0.0.2,因此当子网内有与VIP相关的ARP Request包产生时,有可能会被RS应答而非DS。因此,为了保证VIP在整个集群内只被DS绑定,所有的RS都应该将其配置了VIP的网卡“隐藏”起来。所谓“隐藏”,其实就是指:只有我自己知道,别人都不知道。因此,你可以通过创建一个dummy网卡的方式来解决这个问题,因为dummy网卡是不会响应ARP请求报文的。
有关网卡的隐藏(不对ARP请求做应答),可以看下面的这些说明:
4.2.4 回过头看看
不知道你对之前我们一起做的那部分小试牛刀还有没有印象,当时在配置完ipvs之后我们尝试通过VIP192.168.0.102:80去访问运行在RS192.168.0.105:80的服务,但是失败了。
随后我们通过在192.168.0.105机器上给dummy0网卡配置VIP的方式解决了这个问题。集群环境相关配置如下:
| 主机名 | 配置 | IP地址 |
|---|---|---|
| my-laptop | 笔记本电脑(MacBook) | 192.168.0.101 |
| loadbalance | 虚拟机(CentOS 7.9) | 192.168.0.102 |
| 虚拟服务器IP:192.168.0.222 | ||
| realserver | 虚拟机(CentOS 7.9) | 192.168.0.105 |
为什么一定要配置呢?
其实这是一个很基础的网络问题,当DS将数据包转发到RS时,RS接收到的报文格式大致如下图所示:
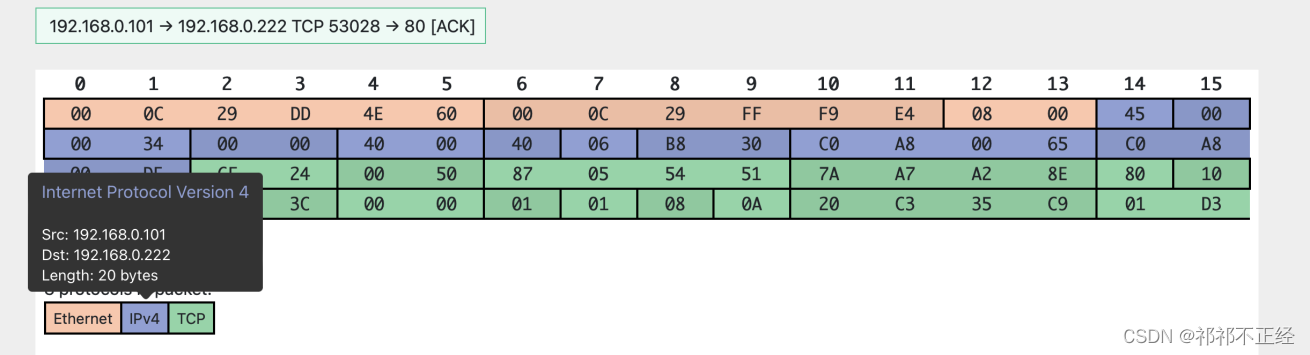
可以看到,目标IP地址是没有更改的,依旧是VIP192.168.0.222,可是这个包确实是需要RS处理的,有什么办法能让目的地址为192.168.0.222的数据包被IP地址为192.168.0.105的机器处理吗?答案就是虚拟一个网卡并给这个网卡配置VIP。
[root@realserver ~]# ip addr add dev dummy0 192.168.0.222/32
当我们执行上面的命令后,RS上就会将192.168.0.222认为是自己的IP地址,这样一来,当它收到目的地址为192.168.0.222的数据包,就会自己捕获这个包并处理这个包,然后再通过192.168.0.222这个地址作为源地址发给客户端192.168.0.101。这样也保证了客户端CIP发出的包和返回的包信息是匹配的,从而保证了正常的通信。
💡 祁祁有话讲:下划线这里的内容也是一个比较基础的网络知识,加入客户端发出一个包,源地址是A,目的地址是B。那么有且仅有源地址是B,目的地址是A的数据包才会被客户端识别为正确的返回包。如果某个数据包源地址是C,而目的地址是A,那么客户端将会丢弃这个包。简单来说就是:我给你写的信,必须是你回的我才看,别人回的我都不看。
可能你会问:“有没有不添加额外的网卡的解决办法?”。其实还可以通过iptables来配置一个重定向的规则,不过这里我就不多作说明了,感兴趣的可以戳这里自己研究。
此外,这部分介绍的有关新增网卡并配置VIP的内容在下面的IP Tunneling模式也涉及到了。
4.3 IP Tunneling模式
IP Tunneling模式,又称ipip模式。通过采用Linux提供的ipip内核模块实现,ipip协议为在ip协议报文的基础上继续封装ip报文,基于tun设备实现,是一种点对点的通讯技术。通过搭建隧道,可以在不修改原数据包相关头字段的情况下将数据包在不同子网下的主机之间进行传输。
其实IP Tunneling模式整体工作原理和Direct Routing很类似,只是前者提供了后者不具备的跨子网传递数据包的能力。
4.3.1 工作原理
以IP Tunneling模式进行包转发的场景下,一个由外部网络发出的,访问局域网内服务的数据包会经历下面的流程:
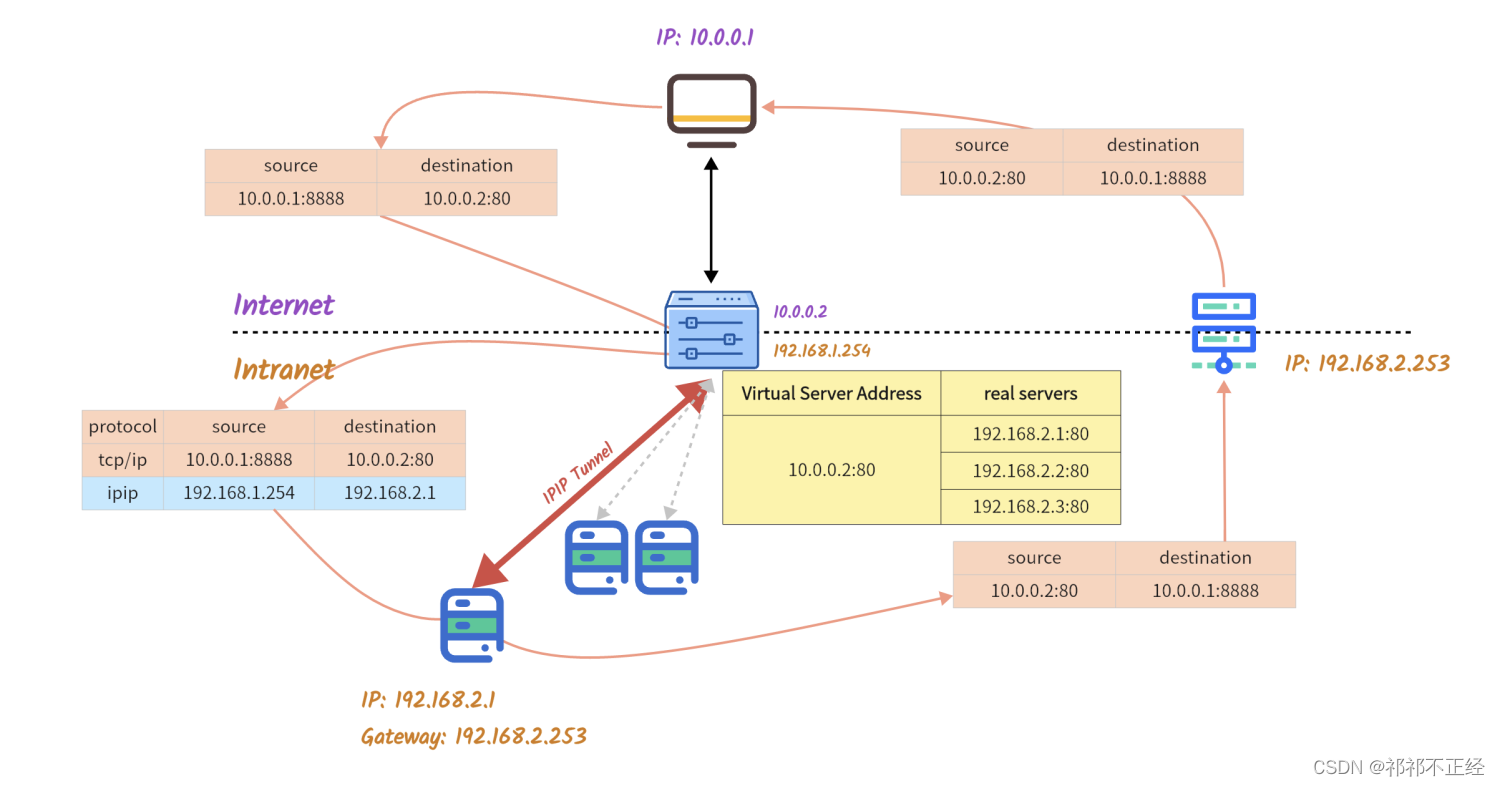
- 外部网络CIP
10.0.0.1:8888访问DS的VIP10.0.0.2:80,发出数据包; - DS通过IPVS规则,找到该数据包实际要转发的RS
192.168.2.1:80; - 找到RS后,DS中的ipvs根据RIP将原本的数据包封装进ipip协议中,且ipip协议中源地址为本机地址,目的地址为RIP,并将这条连接添加到记录
ESTABLISHED类型连接的哈希表中,如果后续有相同的数据包到来,DS将根据哈希表记录统一转发给同一个RS; - DS发出修改后的数据包;
- 数据包到达RS,由于RS同样配置了基于ipip协议的tunnel设备,因此会对ipip协议进行解包,解包后服务器发现ip协议的目的地址为
10.0.0.2。而由于RS也配置了VIP,即dummy网卡上配置的10.0.0.2地址,因此RS会将该数据包发送至本机处理; - RS处理完成后,通过默认网关
192.168.1.253将数据包发出; - 外部网络CIP
10.0.0.1收到数据包; - 连接结束,DS删除位于
ESTABLISHED哈希表中的相关数据。
4.3.2 适用场景
由于IP Tunneling模式的工作原理和Direct Routing模式非常类似,因此其也有相对于NAT而言能够减少DS压力的优点。且相对于Direct Routing模式而言,IP Tunneling模式能够在不同子网间发送数据包,因此如果DS和RS并不在一个子网下,IP Tunneling模式是优选项。但如果两者在同一个子网下,还是优先选择Direct Routing模式。
然而,IP Tunneling转发模式也不是万金油,它对集群服务器有如下的要求:
- DS和RS必须支持ipip协议,必须加载ipip模块;
- 集群服务器如果是虚拟机,那么其物理机器上不能有ipip隧道设备。
4.3.3 思考
通过刚才的了解,不难发现IP Tunneling模式相对于Direct Routing模式只是解决了跨子网间数据包转发的问题。那么,为什么跨子网不能直接按照像Direct Routing那样的的转发流程去进行呢。这里做一个说明。
还是刚才那个例子,这里我将DS到RS之间的链路单独绘制成图:
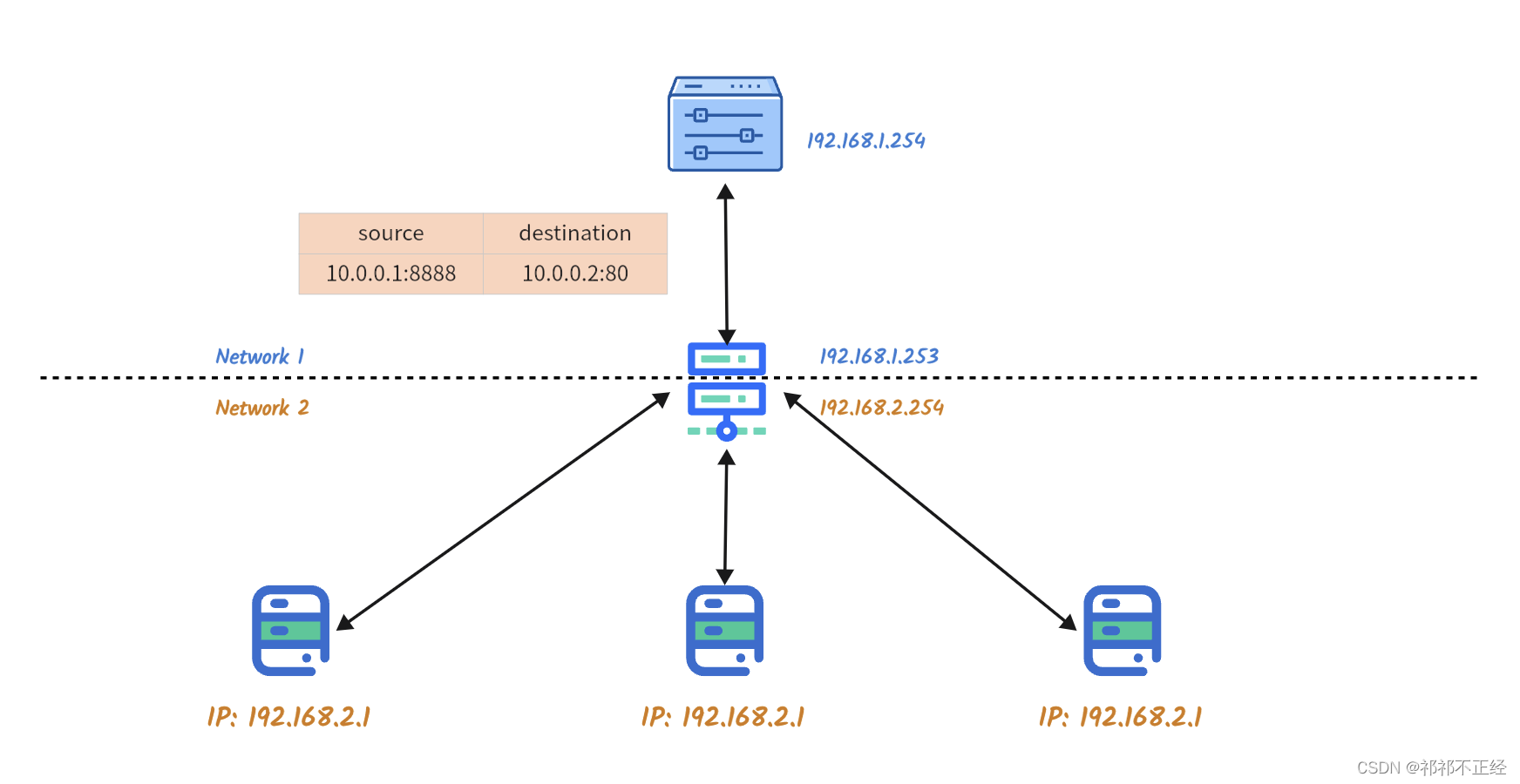
- 假如现在包到达DS,按照Direct Routing模式的流程,ipvs会对这个包的MAC地址作处理,在这个跨子网的环境下,处理后的目的MAC地址一定是图中间这个网关的MAC地址。
- 假设现在包已经处理完毕,发给了网关,这时就有一个问题:网关怎么知道
10.0.0.2这个地址是哪个IP?可能你会说,那还不简单,我给网关加路由就是了,把这个IP的后端服务器都加进去。 - 那么好,假设现在路由加上了,网关怎么选择这个数据包的流向呢?假如像图中那样,有三个后端服务器,每台服务器都对应
10.0.0.2这个地址,网关可以负载,但没办法做到均衡。
所以说,在原IP报文的基础上再做IP报文的封装,让IPIP协议来解决底层连接的问题,而IPVS还是专注于其负载均衡的工作就可以了。
4.4 小结
至此,我们对IPVS的工作原理算是彻彻底底摸清楚了,在继续后面的学习之前,先做一个小结:
- IPVS是LVS项目中为Linux系统提供四层负载均衡的一个软件;
- IPVS工作在Netfilter框架上,在
LOCAL_IN、FORWARD以及LOCAL_OUT三个Hook上都注册了处理函数,顺从Netfilter框架处理数据包的流程; - IPVS在用户空间的管理工具为
ipvsadm; - IPVS对包转发有三个模式:
NAT模式、Direct Routing模式以及IP Tunneling模式。
如果你对于这些知识点都熟悉了的话,那么恭喜你,你对于IPVS的了解已经超过了全球80%的人👍。接下来的两个部分都是比较轻松的部分了。坚持下去,给IPVS的学习做一个完美的收尾!
五、IPVS均衡算法
对IPVS的学习终于要接近尾声了。其实类似IPVS这类有关网络的工具,只要解决了网络方面的疑惑点,基本上就已经掌握了这类工具。IPVS做负载的部分就是网络的部分,而均衡的部分则是算法的部分。在这一小节里,我将粗略介绍一下IPVS的10种均衡算法,具体的算法细节不多做说明,感兴趣的小伙伴可以自行研究。
等等😱!之前不是介绍是8种吗?对这种现象唯一合理的解释就是ipvsadm的帮助手册没同步更新。不过无伤大雅,我们还是以官网的种类为准就好了,戳这里可以直通官方原文
💡 P.S:如果你是一次性看到这里来的,我建议可以先略过
IPVS均衡算法的部分。因为这部分内容大部分内容都是直接翻译过来的。你可以在实际要使用的时候再来翻看。
5.1 Round Robin
5.1.1 命令参数
-s rr
5.1.2 算法说明
Round Robin又称轮询调度。这种算法会将新的请求调度到后端服务器列表中的下一个服务器上。假如集群内有三个后端服务器:A、B、C,这时依次来了4个不同的请求,那么它们的调度结果将是这样:
- 请求1调度到A;
- 请求2调度到B;
- 请求3调度到C;
- 请求4调度到A。
由此可见,Round Robin算法将后端服务器的调度顺序形成了一个循环。这种调度算法不考虑新的连接数和每台后端服务器的处理时长,只按照循环次序去调度。
5.2 Weighted Round-Robin
5.2.1 命令参数
-s wrr
5.2.2 算法说明
Weight Round Robin又称加权轮询调度。这种算法会根据每台后端服务器配置的权重生成轮询的序列。假如集群内有三个后端服务器(括号内为权重):A(4)、B(3)、C(2),那么,在配置生效的那一刻,IPVS就会为这三个后端服务器生成用来执行Round Robin的轮询序列,比如AABABCABC就是一个优秀的序列。成功生成序列后,再按照Round Robin的方式去执行调度就可以了。
Round Robin是一种特殊的Weighted Round Robin,Round Robin使所有后端服务器的权重相等。
5.3 Least-Connection
5.3.1 命令参数
-s lc
5.3.2 算法说明
Least-Connection又称最小连接数调度,它是一个动态的调度算法。为什么是动态?因为它会根据当前后端服务器的连接数来动态选择一个连接数最小的后端服务器进行数据包调度,而这也意味着,它需要动态记录每一台后端服务器的连接情况。
当后端服务器工作性能差不多的时候,Least-Connection算法能够更好地解决高并发请求的分发问题。
值得注意的是,Least-Connection算法并不适合后端服务器性能差别比较大的场景,这是因为TCP报文有TIME_WAIT状态存在,TIME_WAIT会在断开连接后保持2MSL(Maximum Segment Lifetime,报文最大生存时间)的时间,也就是说,服务器处理完请求并返回后并不会立即释放连接,会等待。
打个比方:现在有两台后端服务器A和B,A处理1000个请求需要10秒,而B处理1000个请求需要1分钟。现在有2000个请求需要调度,1000给调度给A后,A处理完了,但是要等待,所以剩下的1000个请求没法直接发给A,因为A现在的连接数还是1000,并没有释放。因此只能将剩下的1000个请求调度给B,而B处理就很慢。所以这种情况就会导致客户端有些请求快有些请求慢的故障发生。
5.4 Weighted Least-Connection
5.4.1 命令参数
-s wlc(这也是默认的参数)
5.4.2 算法说明
Weighted Least-Connection又称加权最小连接数调度,它和Least-Connection一样,也是一个动态的调度算法。相较于Least-Connection,它能够弥补其在后端服务器性能有较大差异的情况下的缺陷。
该算法要求给性能较好的后端服务器配置较高的权重,以此来接收更多的数据包。当新的数据包到来时,Weighted Least-Connection算法会根据下面的公式选择出调度的目标后端服务器:
C
j
W
j
=
min
C
i
W
i
(
i
=
1...
n
)
\frac{C_j}{W_j} = \min{\frac{C_i}{W_i}}(i=1...n)
WjCj=minWiCi(i=1...n)
其中,n代表后端服务器的个数,i代表某个后端服务器,Wi代表i这个后端服务器的权重,Ci代表i这个后端服务器当前的连接数,j代表调度的后端服务器。简单来说就是:计算所有的后端服务器节点的连接数和权重的比值,取最小的那个数对应的服务器来调度。
5.5 Locality-Based Least-Connection
5.5.1 命令参数
-s lblc
5.5.2 算法说明
Locality-Based Least-Connection又称基于本地的最少连接数调度,它通常被用在缓存集群里面(cache cluster)。当某个数据包到达LB且需要被调度时,该算法会获取数据包中的目的IP地址,并根据本地的一个目的IP地址:RS映射表进行如下操作:
- 如果映射表中不存在RS,则通过Weighted Least-Connection算法算出一个RS,将这个数据包调度过去并且将这个RS添加进映射表里面。
- 如果映射表存在RS,则判断该RS是否过载,如果没有,则转发;如果过载,则再次通过Weighted Least-Connection算法算出一个RS,并用这个新的RS替换掉原来的RS。
其算法伪代码如下:
Supposing there is a server set S = {S0, S1, ..., Sn-1},
W(Si) is the weight of server Si;
C(Si) is the current connection number of server Si;
ServerNode[dest_ip] is a map from destination IP address to server;
WLC(S) is the server of weighted least connection in the server set S;
Now is the current system time.
if (ServerNode[dest_ip] is NULL) then {
n = WLC(S);
if (n is NULL) then return NULL;
ServerNode[dest_ip].server = n;
} else {
n = ServerNode[dest_ip].server;
if ((n is dead) OR
(C(n) > W(n) AND
there is a node m with C(m) < W(m)/2))) then {
n = WLC(S);
if (n is NULL) then return NULL;
ServerNode[dest_ip].server = n;
}
}
ServerNode[dest_ip].lastuse = Now;
return n;
5.6 Locality-Based Least-Connection with Replication
5.6.1 命令参数
-s lblcr
5.6.2 算法说明
Locality-Based Least-Connection with Replication又称具有多副本的LBLC。它和LBLC的适用场景一样。区别于LBLC保存目的IP的映射表,LBLCR算法保存的是某个IP对应的RS Set,即后端服务器集合。当某个数据包到达LB且需要被调度时,该算法会获取数据包中的目的IP地址,并根据本地的目的IP地址:RS Set映射表来获取后端服务器组并进行下面的操作:
- 如果映射表不存在RS Set,则通过Weighted Least-Connection算法算出一个RS,将这个数据包调度过去并且将这个RS添加进映射表的RS Set;
- 如果映射表存在RS Set,则通过Weighted Least-Connection算法对这个RS Set里面的后端服务器做加权计算,选择出一个RS,随后进行判断:
- 如果RS负载正常,那就直接转发;
- 如果RS过载,则从所有的RS中采用Weighted Least-Connection算法算出一个RS,将这个数据包调度过去并且将这个RS添加进映射表的RS Set;
- 移除RS Set中长时间没使用过的RS(Garbage Collection:GC)。
其算法伪代码如下:
Supposing there is a server set S = {S0, S1, ..., Sn-1},
W(Si) is the weight of server Si;
C(Si) is the current connection number of server Si;
ServerSet[dest_ip] is a map from destination IP address to server set;
WLC(S) is the server of weighted least connection in the server set S;
WGC(S) is the server of weighted greatest connections in the server set S;
Now is the current system time;
ServerSet[dest_ip].lastmod is the last modified time of server set for destination IP;
T is the specified time for adjust server set.
if (ServerSet[dest_ip] is NULL) then {
n = WLC(S);
if (n is NULL) then return NULL;
add n into ServerSet[dest_ip];
} else {
n = WLC(ServerSet[dest_ip]);
if ((n is NULL) OR
(n is dead) OR
(C(n) > W(n) AND
there is a node m with C(m) < W(m)/2))) then {
n = WLC(S);
if (n is NULL) then return NULL;
add n into ServerSet[dest_ip];
} else
if (|ServerSet[dest_ip]| > 1 AND
Now - ServerSet[dest_ip].lastmod > T) then {
m = WGC(ServerSet[dest_ip]);
remove m from ServerSet[dest_ip];
}
}
ServerSet[dest_ip].lastuse = Now;
if (ServerSet[dest_ip] changed) then
ServerSet[dest_ip].lastmod = Now;
return n;
5.7 Destination Hashing
5.7.1 命令参数
-s sh
5.7.2 算法说明
Destination Hashing又称目的地址匹配。该算法通过对静态哈希表查询,找到数据包源地址对应的后端服务器并进行转发。
5.8 Source Hashing
5.8.1 命令参数
-s sh
5.8.2 算法说明
Source Hashing又称源地址匹配。该算法通过对静态哈希表查询,找到数据包源地址对应的后端服务器并进行转发。
5.9 Shortest Expected Delay
5.9.1 命令参数
-s sed
5.9.2 算法说明
Shortest Expected Delay又称最短期望延迟。该算法会计算数据包发给所有后端服务器后的期望延迟(expected delay),然后选择一个最短延迟的服务器,将数据包调度过去。后端服务器的期望延迟计算公式为:
C
i
+
1
W
i
\frac{C_i + 1}{W_i}
WiCi+1
其中,Ci代表i号服务器的连接数,Wi代表i号服务器的权重。
5.10 Never Queue
5.10.1 命令参数
-s nq
5.10.2 算法说明
Never Queue又称永不排队。该算法采用双速模型(two-speed model),其选择后端服务器的判断逻辑如下:
- 如果有空闲的后端服务器,那么数据包将被调度到这台服务器上,不论其性能好坏;
- 如果没有空闲的后端服务器,那么会采用Shortest Expected Delay算法来调度数据包。
六、实战篇
终于!!来到了IPVS学习的最后一个小节 🎉。在这个小节里,我会带你一步步地通过ipvsadm命令来搭建不同工作模式下的四层负载均衡。通过这一小节的跟练,你将掌握一套负载均衡从创建到卸载的全部过程。快搭建起你的环境,跟我一起动起来吧!
战前准备:
- 关闭所有测试机器的防火墙:
systemctl stop firewalld && systemctl disable firewalld- 关闭SELinux安全策略:
sed -i 's/SELINUX=enforcing/SELINUX=disable/g' /etc/sysconfig/selinux
6.1 Direct Routing
Direct Routing的模式在前面介绍ipvsadm命令的时候就已经实战过了,这里我将具体的操作步骤提炼了出来,你也可以跟着再操作一次~
6.1.1 环境配置
| 主机名 | 配置 | IP地址 |
|---|---|---|
| my-laptop | 笔记本电脑(MacBook) | 192.168.0.101 |
| loadbalance | 虚拟机(CentOS 7.9) | 192.168.0.102 |
| 虚拟服务器IP:192.168.0.123 | ||
| realserver | 虚拟机(CentOS 7.9) | 192.168.0.105 |
6.1.2 LB配置
- 我们先创建一个虚拟IP地址(Virtual IP Address,即VIP):
192.168.0.123
[root@loadbalance ~]# ip addr add dev ens33 192.168.0.123/32
[root@loadbalance ~]# ipvsadm -A -t 192.168.0.123:80 -s rr
[root@loadbalance ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.123:80 rr
- 接下来我们为上面新增的虚拟服务器添加RS,使用
-g选项来指定该RS通过Direct Routing模式转发包。
[root@loadbalance ~]# ipvsadm -a -t 192.168.0.123:80 -r 192.168.0.105:80 -g -w 1
[root@loadbalance ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.123:80 rr
-> 192.168.0.105:80 Route 1 0 0
6.1.3 RS配置
- 为RS新增一个dummy网卡,并绑定虚拟IP地址(VIP):
[root@realserver ~]# ip link add dummyvip type dummy
[root@realserver ~]# ip addr add dev dummyvip 192.168.0.123/32
- 启动一个80端口的HTTP服务:
[root@realserver ~]# python -m SimpleHTTPServer 80
Serving HTTP on 0.0.0.0 port 80 ...
6.1.4 验证
验证一下服务是否可用,在my-laptop机器上访问VIP:port,即192.168.0.123:80:
ok,可以正常访问了。Direct Routing模式实战结束。现在我们来还原配置
6.1.5 LB配置还原
- 首先我们删除刚才创建的虚拟服务器
192.168.0.222:80:
[root@loadbalance ~]# ipvsadm -D -t 192.168.0.222:80
- 其次,我们删除刚才在
ens33网卡上新增的虚拟IP地址(VIP):
[root@loadbalance ~]# ip addr del dev ens33 192.168.0.222/32
6.1.6 RS配置还原
- 删除刚才在
dummyvip网卡上新增的虚拟IP地址(VIP):
[root@realserver ~]# ip link del dev dummyvip
至此,我们已经还原到最开始的状态。现在我们进行IP Tunneling模式的实战。
6.2 IP Tunneling
6.2.1 环境配置
| 主机名 | 配置 | IP地址 |
|---|---|---|
| my-laptop | 笔记本电脑(MacBook) | 192.168.0.101 |
| loadbalance | 虚拟机(CentOS 7.9) | 192.168.0.104 |
| 虚拟服务器IP:192.168.0.223 | ||
| realserver | 虚拟机(CentOS 7.9) | 192.168.0.108 |
6.2.2 配置分析
由于IP Tunneling的方式涉及到Linux隧道的配置,因此会有些小麻烦。通过对此方式的包转发过程进行分析,明确要进行哪些配置以及为什么要进行这些配置。这对我们理解这项技术也有很大的帮助。
ok,我们假设现在有请求来到LB机器,目的地址的IP为192.168.0.223,很显然这需要通过ipvs做负载均衡。因此ipvs会找到与这个请求相关的虚拟服务器记录,并找到对应的RS地址,假设RS地址是192.168.0.106。
此时,ipvs的包转发模式是IP Tunneling模式,该模式会对IP包进行再一次封包。而ipvs会在其代码内部直接对数据包进行封包而不需要我们再单独为其创建tunnel设备。因此LB机器我们不做隧道的配置。
到RS机器这边,其收到带有IPIP协议的包后,一定需要提供一个IPIP隧道设备用来对IPIP协议进行解包。拿到解包后的原数据包后,这时我们就可以用Direct Routing的思维来解决这个问题了:提供一个跟VIP一样地址192.168.0.223的dummy网卡来提供路由即可。
6.2.3 LB配置
- 我们先创建一个虚拟IP地址(Virtual IP Address,即VIP):
192.168.0.223
[root@loadbalance ~]# ip addr add dev ens33 192.168.0.223/32
[root@loadbalance ~]# ipvsadm -A -t 192.168.0.223:80 -s rr
[root@loadbalance ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.223:80 rr
- 接下来我们为上面新增的虚拟服务器添加后端真实服务器,使用
-i选项来指定该RS通过IP Tunneling模式转发包。
[root@loadbalance ~]# ipvsadm -a -t 192.168.0.223:80 -r 192.168.0.108:80 -i -w 1
[root@loadbalance ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.223:80 rr
-> 192.168.0.108:80 Tunnel 1 0 0
6.2.4 RS配置
- 首先我们加载ipip模块,加载模块后会默认创建一个ipip隧道设备
tunl0:
[root@realserver ~]# modprobe ipip
[root@realserver ~]# ip link set dev tunl0 up
[root@realserver ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:55:8a:5d brd ff:ff:ff:ff:ff:ff
3: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
- 提供了一个tunnel设备后,解包的步骤我们就做完了。接下来我们按照Direct Routing的方式来创建dummy网卡并绑定IP地址:
[root@realserver ~]# ip link add dummyvip type dummy
[root@realserver ~]# ip addr add dev dummyvip 192.168.0.223/32
- 网络配置的最后一步,是要
关闭tunl0网卡的反向路径校验,因为ipip协议包被解包后是从tunl0网卡进入协议栈的,如果tunl0网卡这时进行方向路径校验,必定不通过,从而导致丢包。因此需要这一额外的配置。有关反向路径校验,可以自行搜索学习,只是一个内核参数,很简单的:
[root@realserver ~]# sysctl net.ipv4.conf.tunl0.rp_filter=0
- 启动服务
[root@realserver ~]# python -m SimpleHTTPServer 80
Serving HTTP on 0.0.0.0 port 80 ...
6.2.5 验证
验证一下服务是否可用,在my-laptop机器上访问VIP:port,即192.168.0.222:80:
ok,可以正常访问了。IP Tunneling模式实战结束。现在我们来还原配置。
6.2.6 LB配置还原
- 首先我们删除刚才创建的虚拟服务器
192.168.0.223:80:
[root@loadbalance ~]# ipvsadm -D -t 192.168.0.223:80
- 其次,我们删除刚才在
ens33网卡上新增的虚拟IP地址(VIP):
[root@loadbalance ~]# ip addr del dev ens33 192.168.0.223/32
6.2.7 RS配置还原
- 删除刚才在
dummyvip网卡上新增的虚拟IP地址(VIP):
[root@realserver ~]# ip link del dev dummyvip
- 删除刚才用来做IPIP协议解包的
tunl0设备:
[root@realserver ~]# ip link delete dev tunl0
至此,我们已经还原到最开始的状态。现在我们进行NAT模式的实战。
6.3 NAT
6.3.1 环境配置
| 主机名 | 配置 | IP地址 |
|---|---|---|
| my-laptop | 笔记本电脑(MacBook) | 192.168.0.101 |
| loadbalance | 虚拟机(CentOS 7.9) | 192.168.0.104 |
| 虚拟服务器IP:192.168.0.225 | ||
| realserver | 虚拟机(CentOS 7.9) | 192.168.0.108 |
6.3.2 配置分析
区别于前面两种模式,NAT模式要求所有的数据包都必须通过LB机器,因此相较于前两种模式,我们需要:
- 开启LB机器的转发功能;
- 修改RS机器的默认网关为LB机器。
6.3.3 LB配置
- 我们先创建一个虚拟IP地址(Virtual IP Address,即VIP):
192.168.0.225
[root@loadbalance ~]# ip addr add dev ens33 192.168.0.225/32
[root@loadbalance ~]# ipvsadm -A -t 192.168.0.225:80 -s rr
[root@loadbalance ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.123:80 rr
- 接下来我们为上面新增的虚拟服务器添加后端真实服务器,使用
-m选项来指定该RS通过NAT模式转发包。
[root@loadbalance ~]# ipvsadm -a -t 192.168.0.225:80 -r 192.168.0.108:80 -m -w 1
[root@loadbalance ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.123:80 rr
-> 192.168.0.105:80 Masq 1 0 0
- 接下来打开LB机器的转发功能:
[root@loadbalance ~]# sysctl net.ipv4.ip_forward=1
6.3.4 RS配置
- 在NAT模式下,我们不需要创建额外的网卡,因为当数据包被RS接收到的时候就已经是其物理网卡的IP地址
192.168.0.108,为了让所有的数据包都通过LB机器,我们需要对RS机器做默认路由的配置。建议先通过ip route将默认的一些路由备份一下,后续还原用得到:
[root@realserver ~]# ip route add default via 192.168.0.104 dev ens33 metric 50
[root@realserver ~]# ip route del 192.168.0.0/24 dev ens33
[root@realserver ~]# ip route
default via 192.168.0.104 dev ens33 metric 50
default via 192.168.0.1 dev ens33 proto dhcp metric 100
[root@realserver ~]# tracepath 192.168.0.101
1?: [LOCALHOST] pmtu 1500
1: gateway 1.349ms
2: 192.168.0.101 2.276ms reached
Resume: pmtu 1500 hops 2 back 1
6.3.5 验证
验证一下服务是否可用,在my-laptop机器上访问VIP:port,即192.168.0.225:80:
ok,可以正常访问了。NAT模式实战结束。现在我们来还原配置。
6.3.6 LB配置还原
- 首先我们删除刚才创建的虚拟服务器
192.168.0.225:80:
[root@loadbalance ~]# ipvsadm -D -t 192.168.0.225:80
- 其次,我们删除刚才在
ens33网卡上新增的虚拟IP地址(VIP):
[root@loadbalance ~]# ip addr del dev ens33 192.168.0.225/32
6.3.7 RS配置还原
- 删除添加的路由规则即可:
[root@realserver ~]# ip route del default via 192.168.0.104
[root@realserver ~]# ip route add 192.168.0.0/24 dev ens33 proto kernel scope link src 192.168.0.108 metric 100
恭喜你🎉,完成了这篇有关IPVS的博客的阅读。不知道这篇文章对你来说是不是还是有许多难点无法理解呢?对于新手来说这篇文章是不是太“硬核”了呢?欢迎在评论区写下你的任何想法。如果觉得文章给你带来了比较大的帮助,希望能获得你的点赞、转发和关注😊。
下一篇出什么内容好呢🤔~

















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









