





Hadoop 提供了一组原始的数据IO,这些都是比Hadoop更为通用的技术,比如数据一致性、压缩等。但是值得考虑的是处理TB级的数据。
数据一致性(Data Integrity)
在数据存储和处理期间,用户不希望发生数据的丢失或中断的情况,然而在磁盘或网络上读写数据难免发生错误,并且发生的几率较高。
检测数据是否损坏的常用方式是当数据第一次进入系统时计算数据的校验和(checksum),在传输完成后再次计算校验和,如果两次计算的校验和不相等,则认为数据是损坏的。但是这项技术并不能修复数据,仅只能用来数据错误检测。此外也有可能是校验和本身损坏了,而不是数据,但这是很不可能的,因为校验和的大小比数据的大小要小很多。
常用的错误检测码是CRC-32(32位循环冗余检测),它对任意大小的数据计算,结果为一个32位整数的校验和。它被用于Hadoop文件系统的校验,HDFS做了些高效的改进称之为CRC-32C。
HDFS的数据一致性
HDFS默认对所有数据的写入和读取做校验和。datanode节点负责在数据存入前对接收到的数据进行校验,并保存校验和。一个客户端写数据发送到datanode节点的管道,管道中的最后一个节点负责做计算数据的校验和,如果检测到错误,客户端将接收到一个IOException,通常客户端将采取特定的方式做处理(比如,重新发送数据)。
当客户端从datanode节点中读取数据,同样需要验证校验和,和存储在datanode节点中的校验和做对比。每个datanode节点都保存着检验和的验证日志,所以知道每个数据块的最后验证时间。当客户端校验成功,它会告诉datanode更新日志。在检测坏的数据块方面统计这些日志是值得的。
除了在客户端读取时验证块之外,每个datanode还运行了一个DataBlockScanner后台进程来定期检测存储的所有数据块,这主要是防止在物理存储介质中的“循环”。
因为HDFS保存着块的副本,它可以通过复制没有损坏的副本,产生一个新的完整的数据块来恢复损坏的块。这种方式的工作机制是如果客户端在读取一个数据块时检测到错误,它将报告给datanode 节点,然后datanode节点在抛出CheckSumException异常之前会告诉namenode节点,namenode节点将改块标记为已损坏,不再允许其它任何客户端或者试图要复制此块的datanode节点访问它,然后它将复制块的副本到其它节点,这样复制因子就回到了的原来的水平。一旦操作完成,损坏的数据块将被删除。
在FileSystem上调用open方法读取文件之前可以通过传递false给setVerifyChecksum()方法来禁用校验和的验证,另外还可以通过使用-ignoreCrc选项或使用-copyToLocal命令来禁用。
Compression
文件压缩有两个好处:一是它降低了文件的存储空间,而是它加快了文件在网络或磁盘上传输。当处理海量数据时,这些节省将会很有意义。所以,需要仔细考虑在Hadoop中怎样使用压缩。
Hadoop中有多种不同的压缩格式、工具和算法,每一个都有其特征。如下图一些常用的压缩方式:
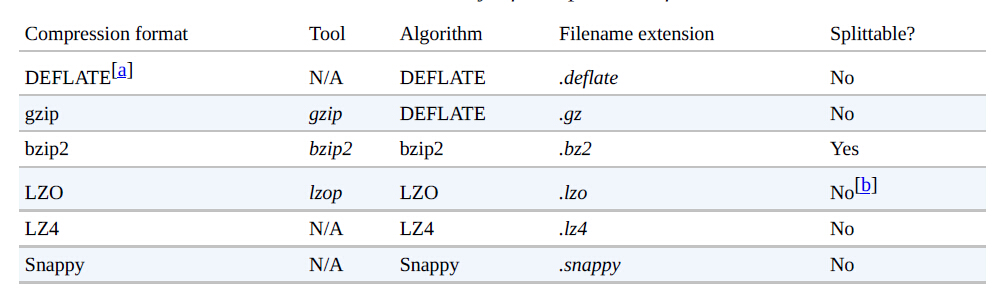
所有的压缩算法都要权衡空间和时间:更快的压缩或解压缩通常占用的空间较大。上图中不同的压缩方式有很大不同的特性。gzip是一个比较常用的压缩方式,它在空间和时间权衡中出于中间位置。bzip2比gzip更有效的压缩,但是压缩速度较慢,bzip2解压缩比其压缩速度要快,但是它仍慢于其它的压缩方式。LZO、LZ4和Snappy三者的压缩速度要比gzip快一个数量级,但是它们的压缩低效。Snappy和LZ4在解压缩方面要比LZO块很多。
上图表格中的“Splittable”列表示压缩格式是否支持分割(也就是说,你可以在流中查找任何点来开始读取)。可分割的压缩格式非常适合MapReduce。















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









