






Kafka是什么?
Kafka是一个高吞吐量的、分布式的消息发布-订阅系统,官网解释为一个分布式的、可分区的、可复制的的提交日志服务。具有如下特性:
1、通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
2、高吞吐量:即使是非常普通的硬件,Kafka也可以支持每秒数百万 的消息。
3、支持通过Kafka服务器和消费机集群来分区消息。
4、支持Hadoop并行数据加载。
问题:
(1)是什么原因能够让Kafka能够在处理海量数据时保持O(1)的复杂度
(2)高吞吐量?
(3)“可复制”怎么理解?
(4)“提交日志”怎么理解?
Kafka相关概念
- Broker
Kafka集群中运行着的一个或多个Server就称为Broker。 - Topic
每一个发送到Kafka集群的消息都有一个类别,Kafka通过维护消息源的类别,将消息路由到指定的路径,这个类别称为Topic。(物理上,不同Topic的消息是分开存储的,逻辑上,虽然Topic的消息保存在一个或多个Broker上,但客户端只需指定特定的Topic即可生产或消费消息,无需关系消息存在何处)。 - Partition
对于每一个Topic,Kafka都维护着一个或多个分区,每一个分区都是一个有序的、不可变的消息序列,并且是不断追加的(一个提交日志)。
- Producer
消息生产者,负责发送消息到Broker - Consumer
消息消费者,从Broker读取消息的客户端。
Topic和Log
一个Topic是消息发布的类别或来源的名称,它包含一个或多个分区,如下图:
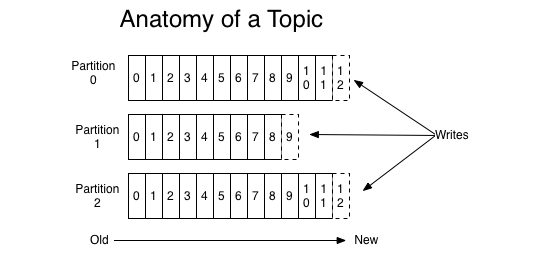
每个分区都是一个有序的、不可变的消息序列,消息序列是可以连续追加消息的(如提交一个日志),添加到序列中的消息都会被分配一个sequential ID号,称为“offset”(偏移量),用来唯一标识分区中的每一个消息。
对于已发布的消息,无论这些消息是否被“消费”,都会被保留一段时间,直到达到配置指定的保留时间期限,当超过这个期限就会被清理掉,释放占用的空间。
对于消息序列的“offset”,是由consumer控制的,它保存着consumer在分区日志中的位置,通常一个consumer从序列中读取消息,那么就会增加它在分区日志中偏移量。当然,consumer可以从任意位置读取,比如它可以重置它的offset。
对Topic log 分区有几个目的:首先,扩展性,当日志的大小超过单个server大小时能够方便扩展。一个Topic有多个分区,所以它可以处理任意数量的数据。其次是提高并行性。
分布式
日志的分区被分布在Kafka集群中的不同server上,这些server保存数据并处理请求。为实现容错性,每个分区会被复制到多个不同的server上(server数量可配置)。
每个分区只有一个server为“leader”,其它的零个或多个server为“follower”,leader server负责处理所有的读写请求,follower server被动的复制leader server。如果leader server发生故障,那么就从follower server中选择一个作为leader。每一个server既是某些分区的leader,也是其它的follower,这样集群就会有比较好的负载均衡。
Producer
Producer负责发送数据到Topic,它负责将消息路由到Topic的某个分区。
Consumer
传统的消息系统有两种模式:队列模式(queue model)和发布-订阅模式(publish-subscribe model)。基于队列的消息,多个consumer从一个server上读取数据,并且每个消息只能进入这些consumer之中的一个。而基于发布-订阅的消息,则会将消息广播到所有订阅的consumer。而Kafka则在这两种模式之上提出了Consumer Group(消费者组)抽象概念,每个Consumer Group 由多个Consumer实例组成,可以方便的扩展和具有较好的容错性。
每个Consumer都其所属组的组名,如果未指定则属于默认的组。 每个发送到Topic的消息只能被推送到Consumer Group中的其中一个Consumer。如果所有的Consumer都有相同的组名,那么其工作方式就和传统的队列模式相似。如果所有的Consumer有不同的组名,那么其工作方式就和传统的发布-订阅模式相似。
和传统的消息系统相比,Kafka具有较强的顺序保证
传统的队列消息系统,按顺序保存消息,如果多个Consumer从队列中的读取消息,Server会按消息的保存顺序传递给Consumer,但这种传递是异步的,并不能保证到达Consumer的顺序。这意味着在并行”消费“时,消息的顺序是混乱的。当然消息系统也可以仅允许一个进程从queue中读取消息,但这就不是并行处理了。
而Kafka为保证消息的顺序,提出了“partition”分区的概念,即对Topic分区,这样既保证了消息的顺序,也可以达到负载均衡的作用。它是通过保证每个Topic的每个分区只能被Consumer Group中的一个Consumer来“消费”,但是需要注意的是Consumer的数量不能超过分区的数量。
保证
Kafka给出了一下几点保证:
- 消息的顺序:Producer发送到特定的topic partition的消息是按它们发送的顺序附加的,就是说,如果M1、M2是由同一个producer发送的,M1先发送,然后M1将比M2的offset小,并且在log中较早出现。
- Consumer读取消息的顺序是按消息在log中保存的顺序读取的。
- 对于一个有N个副本的Topic来说,即使有N-1个server发生故障,也不会造成提交到log中的消息丢失。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









