







es是什么
搜索能力
Elasticsearch REST API 支持的结查询方式
- 构化查询:结构化查询类似于可以在 SQL 中构造的查询类型。例如,您可以搜索
employee索引中的genderandage字段,并按hire_date字段对匹配项进行排序。 - 全文查询:全文查询查找与查询字符串匹配的所有文档,并按相关性(它们与搜索词的匹配程度)排序返回这些文档。
- 结合两者的复杂查询。
高可用
Elasticsearch 索引实际上只是一个或多个物理分片的逻辑分组,其中每个分片实际上都是一个自包含索引。通过将索引中的文档分布在多个分片上,并将这些分片分布在多个节点上,Elasticsearch 可以确保冗余,既可以防止硬件故障,又可以在将节点添加到集群时增加查询容量。随着集群的增长(或收缩),Elasticsearch 会自动迁移分片以重新平衡集群。
有两种类型的分片:主分片和副本分片。索引中的每个文档都属于一个主分片。副本分片是主分片的副本。副本提供数据的冗余副本,以防止硬件故障,并增加处理读取请求(如搜索或检索文档)的能力。
可拓展性
es整体结构
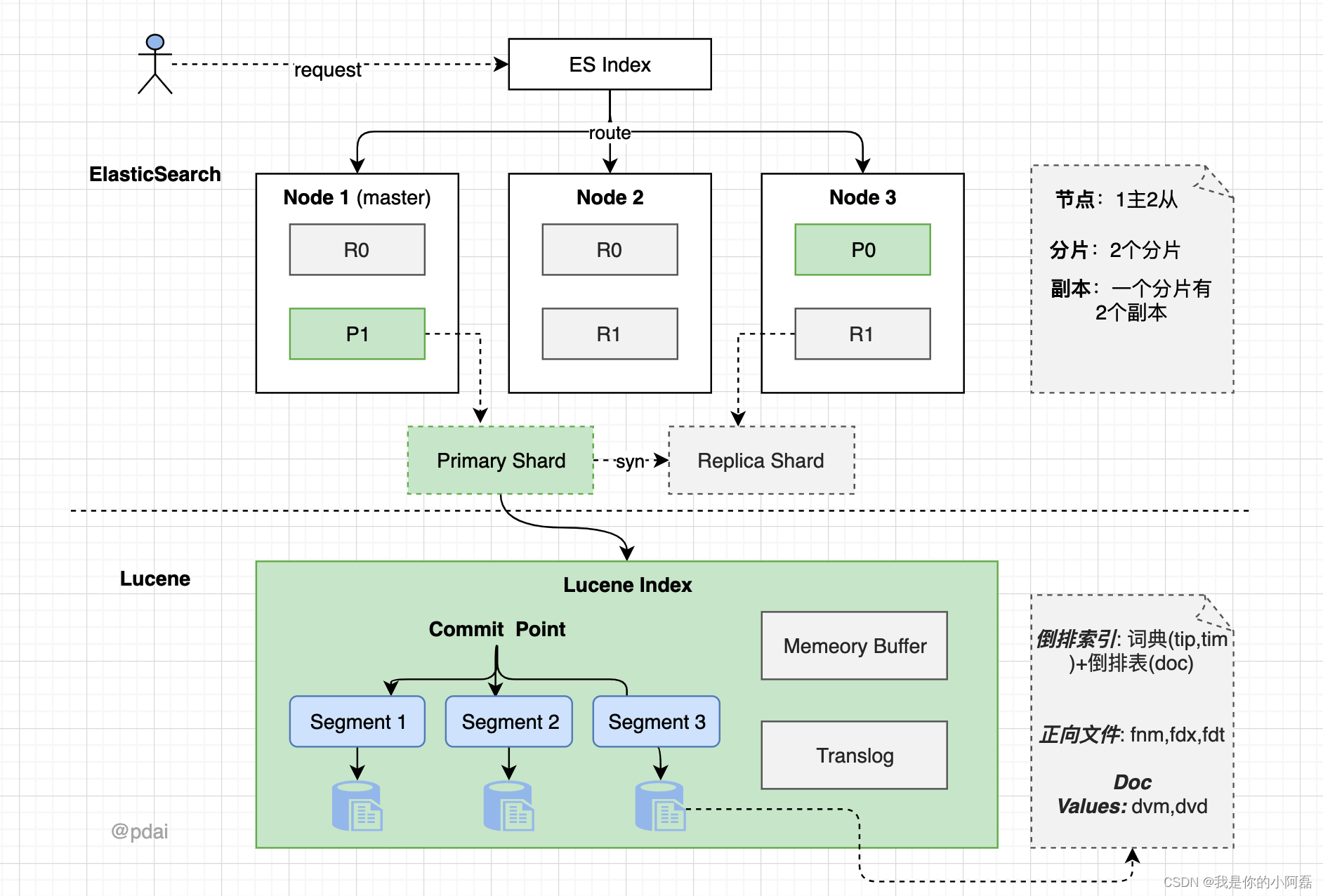
- 一个es集群由N个节点(node)组成
- 每个节点有M个分片(share),每个分片在其他节点会有他的副本分片(replica shard)
- 每个分片对应着
Lucene Index底层索引文件 - Lucene Index 是一个统称
- 由多个 Segment (段文件,就是倒排索引)组成。每个段文件存储着就是 Doc 文档。
- commit point记录了所有 segments 的信
index 模块
es可以分2种索引级别:
- static (静态类别):再创建索引前,需要确定好字段
- dynamic(动态类别):客户端通过api添加索引文档时,es动态的设置
merge
Elasticsearch中的分片是Lucene索引,Lucene索引被分解为多个段。段是存储索引数据的索引中的内部存储元素,并且是不可变的。较小的段会定期合并到较大的段中,以保持索引大小不变并清除删除的内容。
slow log慢日志
分片级慢速搜索日志允许将慢速搜索(查询和获取阶段)记录到专用日志文件中。
搜索慢速日志文件在 log4j2.properties 文件中配置。
PUT /my-index-000001/_settings
{
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms"
}
store存储
存储模块允许您控制如何在磁盘上存储和访问索引数据。
这是一个低级设置。某些存储实现的并发性较差,或者禁用了堆内存使用情况的优化。我们建议坚持使用默认值。
还可以通过在 config/elasticsearch.yml 文件中配置存储类型来为所有索引显式设置存储类型:
index.store.type: hybridfs
也可以再设置index时,设置对应的存储方式
PUT /my-index-000001
{
"settings": {
"index.store.type": "hybridfs"
}
}
列出所有存储类型:
- fs
- simplefs
- niofs
- mmapfs
- hybridfs
translog
对 Lucene 的更改仅在 Lucene 提交期间持久保存到磁盘,这是一项相对昂贵的操作,因此无法在每次索引或删除操作后执行。
Lucene 提交成本太高,无法对每个单独的更改执行,因此每个分片副本还将操作写入其事务日志中,称为 translog。所有索引和删除操作在由内部 Lucene 索引处理后但在确认之前写入 translog。如果发生崩溃,当分片恢复时,最近已确认但尚未包含在上次 Lucene 提交中的操作将从 translog 中恢复。
这个就像mysql的redo log,为了不实时将数据刷盘,临时将数据储存到日志文件,有crash safe的作用,避免宕机导致的数据丢失
mapping映射
Dynamic mapping动态映射
Elasticsearch最重要的功能之一是它试图摆脱你的束缚,让你尽快开始探索你的数据。要为文档编制索引,您不必先创建索引、定义映射类型和定义字段 — 您只需为文档编制索引,索引、类型和字段将自动显示。
您可以通过将 dynamic 参数设置为 true 或 runtime 来显式指示 Elasticsearch 基于传入文档动态创建字段。启用动态字段映射后,Elasticsearch 使用下表中的规则来确定如何映射每个字段的数据类型:
| JSON 数据类型** | "dynamic":"true" | "dynamic":"runtime" |
|---|---|---|
null | No field added 未添加字段 | No field added 未添加字段 |
true or false true 或 false | boolean | boolean |
double | float | double |
long | long | long |
object | object | No field added 未添加字段 |
array | 取决于数组中的第一个非 null 值 | 取决于数组中的第一个非 null 值 |
string 通过日期检测 | date | date |
string 通过数字检测 | float 或 long | double 或 long |
string 未通过 date 检测或 numeric 检测 | text 带有 .keyword 子字段 | keyword |
Explicit mapping 显示映射
您对数据的了解比 Elasticsearch 能猜到的要多,因此虽然动态映射对于入门很有用,但在某些时候,您需要指定自己的显式映射。
创建显示映射
可以使用创建索引 API 创建具有显式映射的新索引。
PUT /my-index-000001
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
# 查看映射
GET /my-index-000001/_mapping
向现有映射添加字段
PUT /my-index-000001/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
# 查看映射
GET /my-index-000001/_mapping
runtime fields 运行时字段
运行时字段是在查询时计算的字段。运行时字段使您能够:
- 向现有文档添加字段,而无需重新索引数据
- 在查询时重写从索引字段返回的值
- 定义特定用途的字段,而无需修改基础架构
运行时字段不存再索引中,是api后的返回结果。
映射运行时字段
以下请求中的脚本根据 @timestamp 定义为 date 类型的字段计算星期几。该脚本根据 的值 timestamp 计算星期几,并用于 emit 返回计算值。
PUT my-index-000001/
{
"mappings": {
"runtime": {
"day_of_week": {
"type": "keyword",
"script": {
"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"
}
}
},
"properties": {
"@timestamp": {"type": "date"}
}
}
}
如果在 dynamic 参数设置为 runtime 的地方启用了动态字段映射,则新字段将自动作为运行时字段添加到索引映射中:
PUT my-index-000001
{
"mappings": {
"dynamic": "runtime",
"properties": {
"@timestamp": {
"type": "date"
}
}
}
}
数据类型
aggregate metric field type 聚合指标类型
用途:聚合返回所有子字段的 min/max/sum/value_count/avg
用例:
定义mapping
PUT stats-index
{
"mappings": {
"properties": {
"agg_metric": {
"type": "aggregate_metric_double",
"metrics": [ "min", "max", "sum", "value_count" ],
"default_metric": "max"
}
}
}
}
insert data
PUT stats-index/_doc/1
{
"agg_metric": {
"min": -302.50,
"max": 702.30,
"sum": 200.0,
"value_count": 25
}
}
PUT stats-index/_doc/2
{
"agg_metric": {
"min": -93.00,
"max": 1702.30,
"sum": 300.00,
"value_count": 25
}
}
查询使用
POST stats-index/_search?size=0
{
"aggs": {
"metric_min": { "min": { "field": "agg_metric" } }, // 返回metric_min字段, 效果是索引中 agg_metric 字段的min最小值,
"metric_max": { "max": { "field": "agg_metric" } },
"metric_value_count": { "value_count": { "field": "agg_metric" } },
"metric_sum": { "sum": { "field": "agg_metric" } },
"metric_avg": { "avg": { "field": "agg_metric" } }
}
}
别名Alias
alias 映射定义索引中字段的备用名称。别名可用于代替搜索请求中的目标字段,
PUT trips
{
"mappings": {
"properties": {
"distance": {
"type": "long"
},
"route_length_miles": {
"type": "alias",
"path": "distance"
},
"transit_mode": {
"type": "keyword"
}
}
}
}
GET _search
{
"query": {
"range" : {
"route_length_miles" : {
"gte" : 39
}
}
}
}
上面的列子中的route_length_miles,alias表明route_length_miles是trips这个index的distance字段的别名,如果是object里的子类型,就需要写完成的路径object.fields_name
(常用)数组Array
在 Elasticsearch 中,没有专用 array 的数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的所有值都必须具有相同的数据类型,例如:
- 字符串数组:[
"one","two"] - 整数数组: [
1,2] - 对象数组: [
{ "name": "Mary", "age": 12 },{ "name": "John", "age": 10 }]
text ,keyword类型的字段,都可以赋值成一个数组,只要里面的值类型相同
文本类型组 Text Famliy
文本类型组包括以下字段类型:
- text:这是全文内容(如电子邮件正文或产品描述)的传统字段类型。
- match_only_text:这是一种空间优化的变体,可禁用评分 ,并查询上执行较慢。它最适合为日志消息编制索引。
text
用于索引全文值(如电子邮件正文或产品说明)的字段。这些字段是 analyzed ,也就是说,它们通过分析器传递,以在编制索引之前将字符串转换为单个术语的列表。分析过程允许 Elasticsearch 在每个全文字段中搜索单个单词**。文本字段不用于排序,也很少用于聚合**(尽管重要的文本聚合是一个值得注意的例外)。
(常用)关键字组 keyword family
keyword包括一下3中type类型
- keyword:
keyword常量关键字是针对索引中所有文档都具有相同值的情况的字段的特殊化。 - Constants_keyword:
constant_keyword支持与字段相同的查询和聚合keyword,但利用所有文档每个索引具有相同值的事实来更有效地执行查询。 - Wildcard:模糊查询
keyword
一些number类型的数据,也可以定义成keyword,因为keyword更适合term和其他术语级查询
再下面
PUT idx
{
"mappings": {
"_source": { "mode": "synthetic" },
"properties": {
"kwd": { "type": "keyword" }
}
}
}
PUT idx/_doc/1
{
"kwd": ["foo", "foo", "bar", "baz"]
}
constant_keyword
常量关键字,是所有document具有相同值的特殊keyword类型。(看名字能看出来,常量!)
constant_keyword 支持与字段相同的 keyword 查询和聚合,但利用所有文档每个索引具有相同值这一事实来更有效地执行查询。
它可以定义一个默认值value:xx。允许提交没有字段值的文档,也允许提交其值等于映射中配置的值的文档。如果mapping中未设置 value ,则该字段将根据第一个索引文档中包含的值自动配置默认值。虽然此行为可能很方便,但请注意,这意味着如果不赋值就有可能导致成一个错误数据。
POST logs-debug/_doc
{
"date": "2019-12-12",
"message": "Starting up Elasticsearch",
"level": "debug"
}
POST logs-debug/_doc
{
"date": "2019-12-12",
"message": "Starting up Elasticsearch"
}
wildcard
wildcard类似于 grep 和 regexp 查询搜索的非结构化机器生成内容。
如何选择使用wildcard还是text:
text字段类型选择:- 内容是人类可读的,例如电子邮件正文或产品说明。
- 您计划使用全文查询在字段中搜索单个单词或短语,
wildcard字段类型选择:- 内容是机器生成的,例如日志消息或 HTTP 请求信息。
- 计划使用术语级查询在字段中搜索精确的完整值 或者 字符串部分匹配
PUT my-index-000001
{
"mappings": {
"properties": {
"my_wildcard": {
"type": "wildcard"
}
}
}
}
PUT my-index-000001/_doc/1
{
"my_wildcard" : "This string can be quite lengthy"
}
GET my-index-000001/_search
{
"query": {
"wildcard": {
"my_wildcard": {
"value": "*quite*lengthy"
}
}
}
}
数字类型 num
long | 一个带符号的 64 位整数,最小值为,最大值为。 -263``263-1 |
|---|---|
integer | 一个带符号的 32 位整数,最小值为,最大值为。 -231``231-1 |
short | 一个带符号的 16 位整数,最小值为-32,768,最大值为32,767。 |
byte | 一个带符号的 8 位整数,最小值为-128,最大值为127。 |
double | 双精度 64 位 IEEE 754 浮点数,仅限于有限值。 |
float | 单精度 32 位 IEEE 754 浮点数,仅限于有限值。 |
half_float | 半精度 16 位 IEEE 754 浮点数,仅限于有限值。 |
scaled_float | 由 支持的浮点数long,按固定double比例因子缩放。 |
unsigned_long | 一个无符号 64 位整数,最小值为 0,最大值为. 264-1 |
对象object
您不需要将字段 type object 显式设置为,因为这是默认值。
PUT my-index-000001
{
"mappings": {
"properties": {
"region": {
"type": "keyword"
},
"manager": {
"properties": {
"age": { "type": "integer" },
"name": {
"properties": {
"first": { "type": "text" },
"last": { "type": "text" }
}
}
}
}
}
}
}
复合结构 nested
该nested类型是数据类型的特殊版本object,它允许以一种可以彼此独立查询的方式对对象数组进行索引。
PUT my-index-000001
{
"mappings": {
"properties": {
"user": {
"type": "nested"
}
}
}
}
PUT my-index-000001/_doc/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
GET my-index-000001/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "Smith" }}
]
}
}
}
}
}
GET my-index-000001/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "White" }}
]
}
},
"inner_hits": {
"highlight": {
"fields": {
"user.first": {}
}
}
}
}
}
}
DSL复合查询
bool query
bool查询包含四种操作符,分别是must,should,must_not,filter。他们均是一种数组,数组里面是对应的判断条件。
must: 必须匹配。贡献算分 ,类似mysql的andmust_not:过滤子句,必须不能匹配,但不贡献算分 ,类似mysql的and x!=1,and x<>1should: 选择性匹配,至少满足一条。贡献算分,类似mysql的orfilter: 过滤子句,必须匹配,类似must,但不贡献算分
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
翻译成sql
where (user.i ="kimchy") and (tags="production") and (age not between 10 and 20) and (tags="env1" or tags="deployed")
must和 filter 的区别?
(1)must:查询操作不仅仅会进行查询,还会计算分值,用于确定相关度;
(2)filter:查询操作仅判断是否满足查询条件,不会计算任何分值,也不会关心返回的排序问题,同时,filter 查询的结果可以被缓存,提高性能。
boosting query(提高查询)
不同于bool查询,bool查询中只要一个子查询条件不匹配那么搜索的数据就不会出现。而boosting query则是降低显示的权重/优先级(即score)。
例如:搜索逻辑是 name = ‘apple’ and type =‘fruit’,对于只满足部分条件的数据,不是不显示,而是降低显示的优先级(即score)
POST /test-dsl-boosting/_bulk
{ "index": { "_id": 1 }}
{ "content":"Apple Mac" }
{ "index": { "_id": 2 }}
{ "content":"Apple Fruit" }
{ "index": { "_id": 3 }}
{ "content":"Apple employee like Apple Pie and Apple Juice" }
GET /test-dsl-boosting/_search
{
"query": {
"boosting": {
"positive": {
"term": {
"content": "apple"
}
},
"negative": {
"term": {
"content": "pie"
}
},
"negative_boost": 0.5
}
}
}
# 3行数据都会命中,但是只命中一个条件的数据,score会被降低
constant_score query(固定分数查询)
查询某个条件时,固定的返回指定的score;显然当不需要计算score时,只需要filter条件即可,因为filter context忽略score。
POST /test-dsl-constant/_bulk
{ "index": { "_id": 1 }}
{ "content":"Apple Mac" }
{ "index": { "_id": 2 }}
{ "content":"Apple Fruit" }
GET /test-dsl-constant/_search
{
"query": {
"constant_score": {
"filter": {
"term": { "content": "apple" }
},
"boost": 1.2
}
}
}
# 查询到的文档,分数都时boost设置的值
dis_max(最佳匹配查询)
分离最大化查询(Disjunction Max Query)指的是: 将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回 。
POST /test-dsl-dis-max/_bulk
{ "index": { "_id": 1 }}
{"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}
{ "index": { "_id": 2 }}
{"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}
GET /test-dsl-dis-max/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
function_score(函数查询)
用自定义function的方式来计算_score。
es预定义函数:
script_score使用自定义的脚本来完全控制分值计算逻辑。如果你需要以上预定义函数之外的功能,可以根据需要通过脚本进行实现。weight对每份文档适用一个简单的提升,且该提升不会被归约:当weight为2时,结果为2 * _score。random_score使用一致性随机分值计算来对每个用户采用不同的结果排序方式,对相同用户仍然使用相同的排序方式。field_value_factor使用文档中某个字段的值来改变_score,比如将受欢迎程度或者投票数量考虑在内。衰减函数(Decay Function)-linear,exp,gauss
DSL全文搜索
match
将type=text类型的字段,可以用分词器拆分查询
PUT /test-dsl-match
{ "settings": { "number_of_shards": 1 }}
POST /test-dsl-match/_bulk
{ "index": { "_id": 1 }}
{ "title": "The quick brown fox" }
{ "index": { "_id": 2 }}
{ "title": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 3 }}
{ "title": "The quick brown fox jumps over the quick dog" }
{ "index": { "_id": 4 }}
{ "title": "Brown fox brown dog" }
match步骤:
- 查询搜索字段类型,是
text类型,分词器拆分,拆成多个词 - 转换成bool should多个term查询
- 匹配文档,为每个文档打分
GET /test-dsl-match/_search
{
"query": {
"match": {
"title": "BROWN DOG"
}
}
}
#类似于
GET /test-dsl-match/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": "brown"
}
},
{
"term": {
"title": "dog"
}
}
]
}
}
}
match_parse
match 语句解析,将query当成一个句子去搜索
GET /test-dsl-match/_search
{
"query": {
"match_phrase": {
"title": {
"query": "quick brown f"
}
}
}
}
# 必须是 quick brown f这个句子才行,不能是 quick brown fuck,这个是查不出来的
match_parse_prefix
match 语句解析,将query当成一个句子的前缀去搜索,上面的例子是可以查出来的
{
"query": {
"match_phrase": {
"title": {
"query": "quick brown f"
}
}
}
}
# quick brown fuck,这个是查不出来的
match_bool_prefix
这个其实就是 bool+prefix,跟parse无关
GET /test-dsl-match/_search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "quick brown f"
}
}
}
}
# 相当于
GET /test-dsl-match/_search
{
"query": {
"bool" : {
"should": [
{ "term": { "title": "quick" }},
{ "term": { "title": "brown" }},
{ "prefix": { "title": "f"}}
]
}
}
}
query_string
此查询使用语法根据运算符(例如AND OR)来解析和拆分提供的查询字符串NOT。然后查询在返回匹配的文档之前独立分析每个拆分的文本。
GET /test-dsl-match/_search
{
"query": {
"query_string": {
"query": "(lazy dog) OR (brown dog)",
"default_field": "title"
}
}
}
这里查询结果,你需要理解本质上查询这四个分词(term)or的结果而已
DSL 的 term详解
PUT /test-dsl-term-level
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"programming_languages": {
"type": "keyword"
},
"required_matches": {
"type": "long"
}
}
}
}
POST /test-dsl-term-level/_bulk
{ "index": { "_id": 1 }}
{"name": "Jane Smith", "programming_languages": [ "c++", "java" ], "required_matches": 2}
{ "index": { "_id": 2 }}
{"name": "Jason Response", "programming_languages": [ "java", "php" ], "required_matches": 2}
{ "index": { "_id": 3 }}
{"name": "Dave Pdai", "programming_languages": [ "java", "c++", "php" ], "required_matches": 3, "remarks": "hello world"}
字段是否存在 exist
由于多种原因,文档字段的索引值可能不存在:
- 源JSON中的字段是null或[]
- 该字段已"index" : false在映射中设置
- 字段值的长度超出ignore_above了映射中的设置
- 字段值格式错误,并且ignore_malformed已在映射中定义
GET /test-dsl-term-level/_search
{
"query": {
"exist": {
"field": "remark"
}
}
}
id查询:ids
ids 即对id查找
GET /test-dsl-term-level/_search
{
"query": {
"ids": {
"values": [3, 1]
}
}
}
前缀 prefix
通过前缀查找某个字段
GET /test-dsl-term-level/_search
{
"query": {
"prefix": {
"name": {
"value": "Jan"
}
}
}
}
分词匹配 term
前文最常见的根据分词查询
GET /test-dsl-term-level/_search
{
"query": {
"term": {
"programming_languages": "php"
}
}
}
多词匹配 terms
按照读个分词term匹配,它们是or的关系
GET /test-dsl-term-level/_search
{
"query": {
"terms": {
"programming_languages": ["php","c++"]
}
}
}
通配符:wildcard
通配符匹配,比如*
GET /test-dsl-term-level/_search
{
"query": {
"wildcard": {
"name": {
"value": "D*ai",
"boost": 1.0,
"rewrite": "constant_score"
}
}
}
}
# 匹配 Dsdfsdfai 串
范围range
常常被用在数字或者日期范围的查询
GET /test-dsl-term-level/_search
{
"query": {
"range": {
"required_matches": {
"gte": 3,
"lte": 4
}
}
}
}
模糊匹配fuzzy
GET /test-dsl-term-level/_search
{
"query": {
"fuzzy": {
"remarks": {
"value": "hell"
}
}
}
}
聚合查询
ElasticSearch中桶在概念上类似于 SQL 的分组(GROUP BY),而指标则类似于 COUNT() 、 SUM() 、 MAX() 等统计方法。
- 桶(Buckets) 满足特定条件的文档的集合
- 指标(Metrics) 对桶内的文档进行统计计算
聚合就是分组统计,es有3中聚合方式:
- 桶聚合 bucket
- 指标聚合(Metric Aggregration
- 管道聚合
准备数据
POST /test-agg-cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
聚合查询bucket
标准聚合
GET /test-agg-cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color.keyword" #只能是keyword才可以
}
}
}
}
- 聚合操作被置于顶层参数 aggs 之下(如果你愿意,完整形式 aggregations 同样有效)。
- 然后,可以为聚合指定一个我们想要名称,本例中是: popular_colors 。
- 最后,定义单个桶的类型 terms 。
返回值
{
"took" : 332,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"popular_colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "red",
"doc_count" : 4
},
{
"key" : "blue",
"doc_count" : 2
},
{
"key" : "green",
"doc_count" : 2
}
]
}
}
}
buckets就是每个桶的统计数据
多个聚合
同时计算两种桶的结果:对color和对make。会返回两个buckets信息
GET /test-agg-cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color.keyword"
}
},
"make_by" : {
"terms" : {
"field" : "make.keyword"
}
}
}
}
嵌套聚合
这个新的聚合层让我们可以将 avg 度量嵌套置于 terms 桶内。实际上,这就为每个颜色生成了平均价格。
GET /test-agg-cars/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color.keyword"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
筛选后聚合
通过过滤器(Filter)匹配的所有文档的单个存储桶。通常,这将用于将当前聚合上下文缩小到一组特定的文档。
GET /test-agg-cars/_search
{
"size": 0,
"aggs": {
"make_by": {
"filter": { "term": { "make": "honda" } },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}
对filter进行分组聚合:filters
设计一个新的例子, 日志系统中,每条日志都是在文本中,包含warning/info等信息。
PUT /test-agg-logs/_bulk?refresh
{ "index" : { "_id" : 1 } }
{ "body" : "warning: page could not be rendered" }
{ "index" : { "_id" : 2 } }
{ "body" : "authentication error" }
{ "index" : { "_id" : 3 } }
{ "body" : "warning: connection timed out" }
{ "index" : { "_id" : 4 } }
{ "body" : "info: hello pdai" }
我们需要对包含不同日志类型的日志进行分组,这就需要filters:
GET /test-agg-logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"other_bucket_key": "other_messages",
"filters" : {
"infos" : { "match" : { "body" : "info" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
es索引(写)文档搜索引过程

-
写请求发到
协调节点 -
协调节点生成
_id,通过hash计算得到主分片id,分配到主分片写入shard = hash(document_id) % (num_of_primary_shards) -
传到
lucence底层,将请求写到Memory Buffer缓存中。同时将请求持久化到Transaction Log,这个步骤叫做write -
es配置中默认每秒将
Memory buffer里的数据刷到Filesystem Cache内,这个过程就叫做refresh。 -
Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush。内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。 flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时。
es索引文档的步骤如下
write -> refresh -> flush -> merge
write
将请求写到memory buffer,此时数据并没有分词操作,只是把请求写到了内存中
为了避免宕机丢失数据,把请求记录到transcation log(可以看成mysql的redolog)
refresh
refresh操作,es默认配置是1秒
- 将数据进行处理(分词,创建倒排,创建正排),生成一个segment。保存在内存中,避免大量磁盘IO。
- 清空
memory buffer中的请求。
segment段,里面记录了 term倒排表,aggs统计倒排表 等等结构
flush
segment写入磁盘持久化
- 所有在内存缓冲区的文档都被写入一个新的segment。
- 缓冲区被清空。
- 一个Commit Point被写入硬盘。
- 文件系统缓存通过 fsync 被刷新(flush)。
- 老的 translog 被删除。
merge
即使flush已经把缓冲区内的segment合并成了1个segment,单磁盘内还是会有很多小segment。每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
luence是会去luence index的每一个segment去查找数据的,所以度segment越多,需要从磁盘读取的文件就会越多
es就通过后台异步线程,将这些小段合并成大段,避免大量磁盘IO
更新和删除文档的流程
删除和更新都是写操作,但是由于 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更;所以 ES 利用 .del 文件 标记文档是否被删除,磁盘上的每个段都有一个相应的.del 文件
- 如果是删除操作,文档其实并没有真的被删除,而是在 .del 文件中被标记为 deleted 状态。该文档依然能匹配查询,但是会在结果中被过滤掉。
- 如果是更新操作,就是将旧的 doc 标识为 deleted 状态,然后创建一个新的 doc。memory buffer 每 refresh 一次,就会产生一个 segment 文件 ,所以默认情况下是 1s 生成一个 segment 文件,这样下来 segment 文件会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个 segment 文件合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,不写入到新的 segment 中,然后将新的 segment 文件写入磁盘,这里会写一个 commit point ,标识所有新的 segment 文件,然后打开 segment 文件供搜索使用,同时删除旧的 segment 文件。
es查询数据的流程
搜索被执行成一个两阶段过程,即 Query Then Fetch:
1、Query阶段:
客户端发送请求到 coordinate node,协调节点将搜索请求广播到所有的 primary shard 或 replica,每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。接着每个分片返回各自优先队列中 所有 docId 和 打分值 给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
2、Fetch阶段:
协调节点根据 Query阶段产生的结果,去各个节点上查询 docId 实际的 document 内容,最后由协调节点返回结果给客户端。
coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
接收请求的 node 返回 document 给 coordinate node 。
coordinate node 返回 document 给客户端。
ACID保证
- 原子性:
- 一致性:
- 隔离性:通过乐观锁,在读数据时被数据打上版本号,更改时对比版本后,提交或回滚
- 持久性:segment最后会落入磁盘,如果在内存中的数据会被写到
transcation log内,来做到crash-safe















 3249
3249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









