







在此前的“实践二:将PG数据库数据同步至BQ数据库(一)”中分享了表结构同步的实践,这里分享表数据的同步。表数据同步可以有多种方式进行同步,这里采用将数据导出到文件中,再将文件导入至BQ数据库中的方式进行。
一、数据同步说明
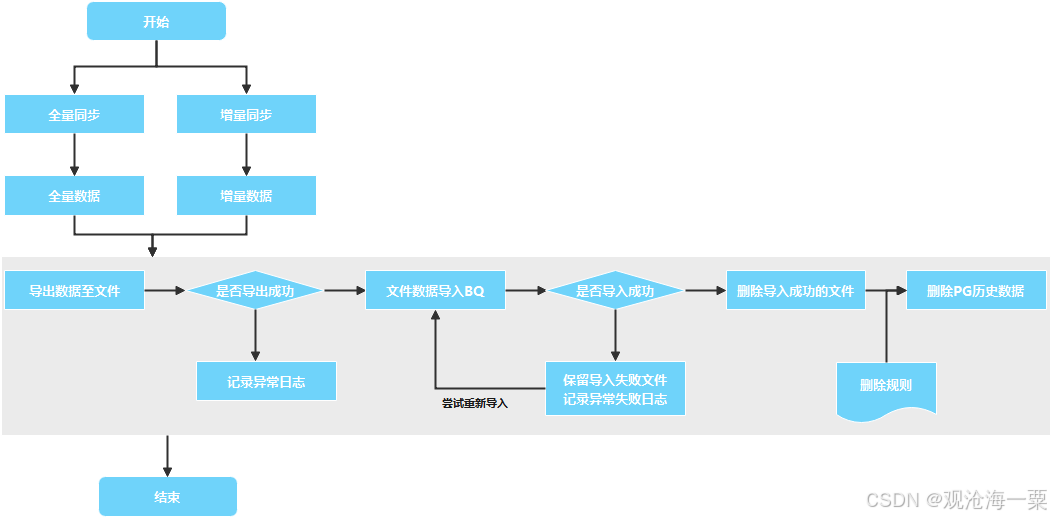
数据同步分为初始化全量同步和上线后增量同步两个阶段。同步处理流程逻辑如下:
1、根据同步类型,将PG数据库数据导出至文件,导出失败的记录日志;
2、将文件数据导入BQ数据库。如果导入成功,则删除对应数据文件及PG数据库中对应历史数据;如果导入失败,则保留数据文件,等待下次任务时重新导入。
说明:为什么要保留导入失败的数据文件,一是方便问题定;二是有时是由于网络等原因导致失败,下一调度任务可以重新完成导入工作。
二、数据同步具体实现
2.1、PG数据库数据导出至文件
将pg数据库数据导出至文件可分为两大步:
-
一是从PG数据库中查询数据
查询数据使用psycopg2包提供的方法进行查询,查询时可以使用fetchmany进行分页查询,也可以使用fetchall进行全量查询。
当数据量小的时候,两种方法都可以,主要看业务场景需要;
当数据量大的使用,就需要使用fetchmany进行查询,并查询时需要使用服务器游标的方式进行查询。
-
二是将查询出数据写入文件中;
写入文件可以写入很多种格式的文件,比如txt、excel、csv,但写入时需要注意控制文件的大小,文件过大则会导致内存溢出,过小会生成很多小文件导致处理效率降低。
将pg数据库数据导出至文件的PgService.py具体实现及说明如下:
(1)由于每次需要处理上亿的数据,我这里使用服务器游标的方式查询数据,否则会导致服务器内存溢出;
(2)由于数据量过大,为避免内存溢出,查询时数据库每次从磁盘预加载一定数据量的数据;
(3)将同一张表的数据按一定大小分为多个文件进行存储,可以避免文件过大,同时在后续可以使用多线程进行同步处理。
import csv
from datetime import datetime
import psycopg2
# 使用服务器游标的方式导出数据至csv文件
def pg_fetchmany_sc( table, table_sql):
connection = ''
iter_size = 2000000 # 每次从数据库预加载的行数
fetch_num = 500000 # 每次获取的行数
csv_file_path_string = 'csv存储路径'
connection_pool = create_pgdb_conn_pool('username', 'password', 'hostname', 'port', 'path')
try:
connection = connection_pool.getconn()
d = datetime.now().date()
cursor = connection.cursor(name=table + '_')
cursor.execute(table_sql)
cursor.itersize = iter_size
create_file = True
write_rows = 0
file_num = 1 # 创建的文件编号
while True:
records = cursor.fetchmany(fetch_num)
if not records:
break
if write_rows > 1900000:
write_rows = 0
file_num += 1
create_file = True
if create_file:
col_names = [desc[0] for desc in cursor.description]
create_csv(str(file_num) + '-' + table, csv_file_path_string, d)
with open(f'{csv_file_path_string}{str(d)}-{str(file_num)}-{table}.csv', mode='a', newline='',
encoding='utf-8') as file:
w = csv.writer(file)
w.writerow(col_names)
create_file = False
if records:
with open(f'{csv_file_path_string}{str(d)}-{str(file_num)}-{table}.csv', mode='a', newline='',
encoding='utf-8') as file:
w = csv.writer(file)
write_rows += fetch_num
w.writerows(records)
print(f"导出{table}表数据成功")
except Exception as e:
print(f"An error:{e}")
finally:
# 将连接返回到连接池
connection_pool.putconn(connection)
# 创建pg数据库连接池
def create_pgdb_conn_pool(username, password, hostname, port, path):
try:
db_params = {
'user': username,
'password': password,
'host': hostname,
'port': port,
'database': path
}
# 创建连接池
connection_pool = psycopg2.pool.SimpleConnectionPool(1, 20, **db_params)
return connection_pool
except Exception as e:
print(f"创建连接池失败: {e}")
return None
def create_csv(csv_file_name, csv_file_path, date=''):
try:
file_name_path = csv_file_path + csv_file_name + '.csv'
if date != '':
file_name_path = csv_file_path + str(date) + '-' + csv_file_name + '.csv'
with open(file_name_path, mode='w', newline='', encoding='utf-8') as file:
csv.writer(file)
except Exception as e:
print(f"An error:{e}")2.2、将文件数据导入至BQ
将文件数据导入BQ数据库主要使用google提供的bigquery的相关包实现。此处需要注意的是频繁调用接口会导致限流,BQ的数据操作会越来越慢,所以导入数据时要尽量减少调用频率。
比如你有100条数据,如果你调一次接口传一条数据,然后关闭,然后再调一次接口传一条数据,然后关闭,。。。这种使用方式将触发限流。BQ更希望用户的操作是调一次接口上传100条数据。
将文件数据导入BQ的BqService.py具体实现如下:
import glob
import os
from google.cloud import bigquery
from google.cloud.bigquery import SchemaField, LoadJobConfig
from google.oauth2 import service_account
def csv2bq( table_name, csv_file_path, bq_dataset_name, schemas):
csv_files = glob.glob(os.path.join(csv_file_path, '*.csv'))
isdelete = True
table_schema = get_table_schema(schemas[table_name])
for csv_file in csv_files:
if csv_file[-(len(table_name) + 4):-4] == table_name:
try:
load_csv(table_name, bq_dataset_name, csv_file,table_schema)
except Exception as e:
print(f"导入{csv_file}失败!!!")
isdelete = False
else:
print(f"{table_name}表的{csv_file}数据导入BQ完成")
delete_csv(csv_file, csv_file_path)
# 表对应的所有csv文件导入完成后,删除pg数据库历史数据
if isdelete:
#调用删除pg数据库历史数据的方法
print("删除pg数据库历史数据")
def load_csv( table_name, bq_dataset_name, csv_file,schema):
job_config = LoadJobConfig(
schema=schema,
source_format='CSV',
skip_leading_rows=1, # 如果CSV文件有标题行,则跳过第一行
autodetect=False # 跳过自动检测
)
with open(csv_file, 'rb') as source_file:
job = create_bq_conn().load_table_from_file(
source_file,
bq_dataset_name + table_name,
job_config=job_config,
location='US' # 指定数据的位置,根据你的需要更改
)
job.result()
# 检查作业状态
if job.state == 'DONE':
print(f"{table_name}表数据导入BQ完成")
else:
print(f"error: {job.error_result},{table_name}表数据导入BQ失败")
def read_schemas_from_file(file_name):
with open(file_name, 'r', encoding='utf-8') as file:
return json.load(file)
def get_table_schema(table_schema):
return [SchemaField(schema_filed['name'], schema_filed['type'], mode=schema_filed['mode'],
description=schema_filed['description']) for schema_filed in table_schema]
def delete_csv(is_all, csv_file_path):
csv_files = glob.glob(os.path.join(csv_file_path, '*.csv'))
try:
if is_all == '*':
for csv_file in csv_files:
os.remove(csv_file)
print(f"删除{csv_file}文件")
else:
os.remove(is_all)
print(f"删除{is_all}文件")
except:
print(f"在目录中没有找到CSV文件,无需进行删除")
# 创建BigQuery数据库连接端
def create_bq_conn():
try:
bq_file_string = '从bq中获取的json文件路径'
# 配置BigQuery客户端
credentials = service_account.Credentials.from_service_account_file(bq_file_string)
client = bigquery.Client(credentials=credentials, project=credentials.project_id)
return client
except Exception as e:
print(f"创建BigQuery客户端失败: {e}")
return None2.3、调用同步服务
调用同步服务可以使用多线程进行调用,具体如下:
xml_dict = {'A':'sql1','B','sql2',...}
tables = xml_dict.keys()
tables_sql = xml_dict.values()
bq_schema_file = 'schema的json文件路径'
csv_file_path = 'csv存储路径'
bq_dataset_name = 'A.test_op.'
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
executor.map(pg_fetchmany_sc, tables,tables_sql)
schemas = read_schemas_from_file(bq_schema_file)
a = lambda table_name:csv2bq(table_name,csv_file_path,bq_dataset_name,schemas)
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
executor.map(a, tables)三、一些注意事项
3.1、BQ数据集
bq_dataset_name是bq数据集名称。
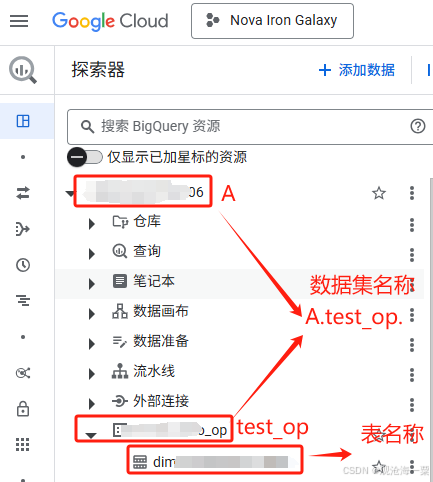
(1)bq中操作表时需使用完整的“数据集名称.表名称”进行操作,例如"A.test_op.dim",如下图所示。
3.2、关于schema
schema与schema的json文件在“实践二:将PG数据库数据同步至BQ数据库(一)”中有说明。
3.3、代码中的参数
示例代码中的各参数的值需要根据实际进行修改、调整。例如:
csv_file_path_string = 'csv存储路径'
bq_file_string = '从bq中获取的json文件路径'
bq_schema_file = 'schema的json文件路径'
四、一些补充说明
4.1、为什么使用数据库服务器端游标?
最主要还是在大数据量查询时避免将数据一次性传入客户端,导致客户端内存溢出。
| 维度 | 服务器端游标 | 普通游标(客户端游标) |
| 数据存储位置 | 数据保留在数据库服务器端,游标由服务器管理。 | 数据一次性从服务器加载到客户端内存,游标由客户端(应用程序)管理。 |
| 网络交互 | 每次获取数据时,客户端向服务器发送请求,服务器返回当前行数据(逐行传输)。 | 首次打开游标时,服务器将整个结果集一次性传输到客户端,后续操作在客户端内存中进行。 |
| 服务器资源占用 | 游标打开期间,服务器会为其维护状态(如当前行位置、结果集快照),占用服务器内存和连接资源。 | 数据加载完成后,服务器仅保留连接,不维护游标状态,资源占用较低。 |
4.2、为什么不使用时间分割查询数据大小
主要是为了增加数据同步处理的一些通用性,当然也可以在当前基础上增加按时间分割数据,我这里属于偷懒了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









