






背景
在流式的数据处理中,因为一些原因,导致数据没有输出到下游系统,造成源数据与目标数据不一致,发现不一致后,怎么修复数据?我们是不能够简单直接在目标端修改数据。eg:源端事件流是:
t_s_0: field_a = a
t_s_1: updaet filed_a from a to a1
t_s_2: update filed_a from a1 to a2
在t_s_1与t_s_2间发现数据不一致,我们修复数据,查询到当前数据是 field_a:a1,我们准备sql: update field_a=a1,还未执行sql前,收到t_s_2 事件,目标端数据 变成 a2,这时候我们再执行准备的sql,目标端数据变化顺序(a -> a2 -> a1),这件造成了目标端数据不一致,这主要原因是我们存在两处对目标端数据的并发更新:
a)正常的事件流更新,
b)外部数据修复,read 源数据,再write。
这样并发更新就会很有机会造成数据不一致。既然并发更新会导致数据不一致,那是否可以将并发改成串行?下面我们讨论的 debezium increment snapshot 就可以帮助我们解决这问题。
Debezium increment snapshot原理
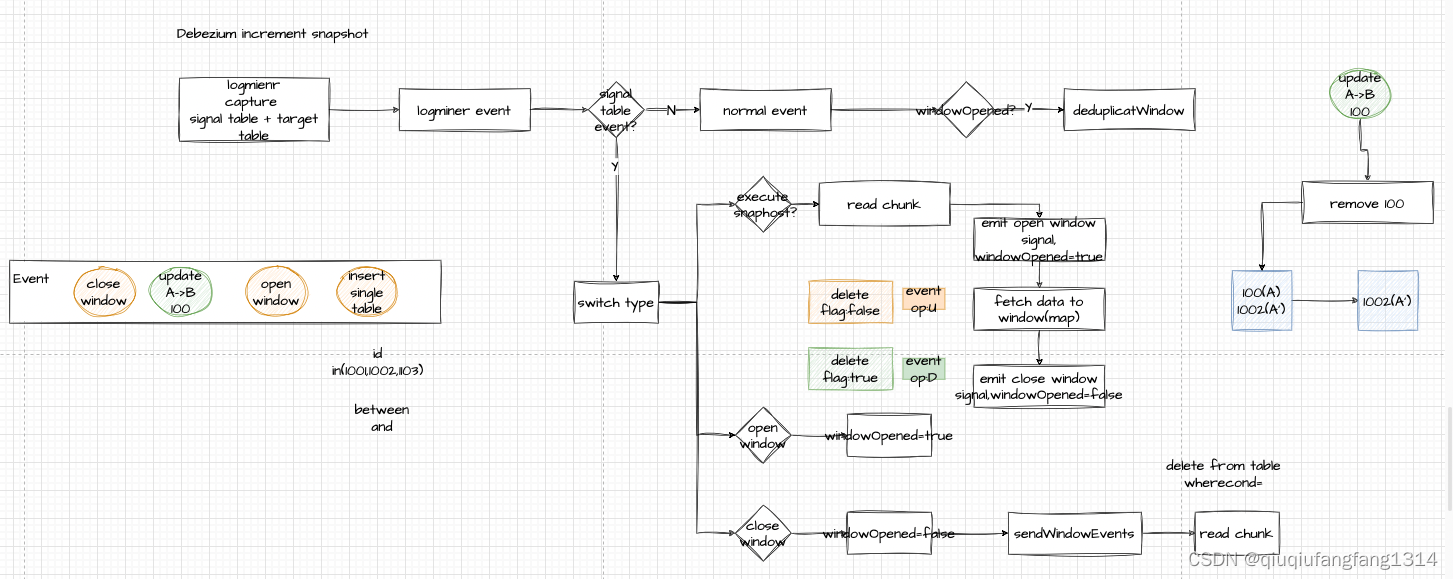
- 在目标源添加一个single table,我们的log监听也会监听这个表的数据变化;
- 在这个表新增一条记录,告诉debezium 我们需要修复的数据
- log capture 接收到single table 事件,事件类型是 执行快照,就会先open window(同样会往single table insert 一条数据,事件类型是 open window);读取需要修复的数据,缓存在窗口中(内存中);close window(single table insert 一条数据,事件类型是 close window)
- 在读取修复数据同时debezium还是会收到变更的数据,有可能会修改上一步读取的数据,删除窗口中的脏数据,下发新的数据
- 收到close window事件,下发窗口剩下的数据。
//TODO















 1051
1051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









