







一、插入排序(直接插入排序,折半插入排序,希尔排序)
1、直接插入排序

public static void sort(int[] array) {
for(int i=1;i<array.length;i++) { //这里叫它第一行吧
int temp=array[i]; //将要插入的数先保存起来,那么数组的这个位置就可以拿来用了
int j=i-1;
for(;j>=0&&array[j]>temp;j--) { //将保存的数与前面的数一一比较
array[j+1]=array[j]; //一旦满足条件就将前面的数往后挪一格
}
array[j+1]=temp; //最后把保存的数插入,然后回到第一行进行下一个数的插入
}
System.out.println(Arrays.toString(array) + " InsertSort");
}2、折半插入排序
折半插入排序是对直接插入排序的一种改进,直接插入排序中0到i-1有序的,折半插入排序就是用折半查找迅速找到需要插入的地方,而不用从i-1开始逐一向前比较。

使用折半查找查找3应该插入的位置,
1. low=0 hight=6 mid=(low+hight)/2=3
因为data[3]<=data[7],说明应该插入的位置在4-6之间 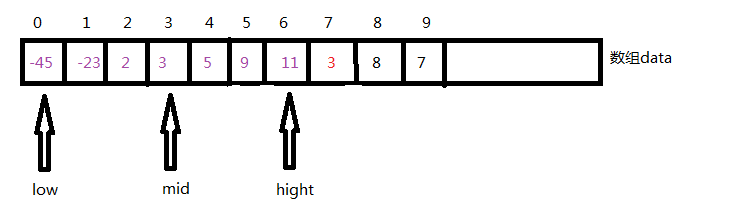
2. low=mid+1=3+1=4 hight=6 mid=(low+hight)/2=5 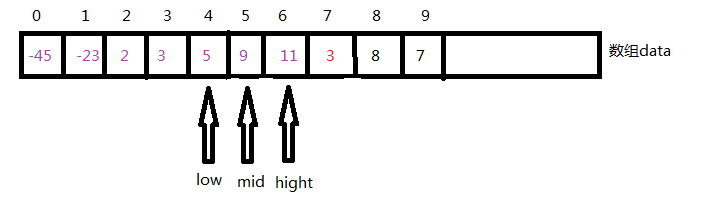
因为data[5]>data[7]说明应该插入的位置在4到5间
3 low=4 hight=mid-1=5 mid=(4+5)/2=4
因为data[4]>data[7]所以插入的位置是4,但是此时折半查找并没有结束
4 low=4 hight=mid-1=3 因为此时low>hight所以折半折半查找结束 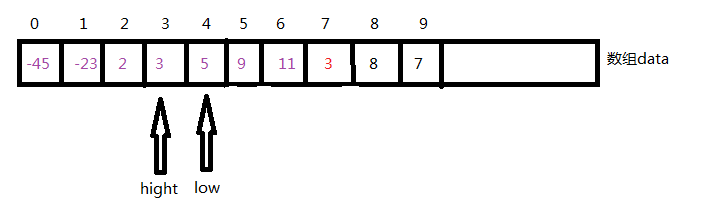
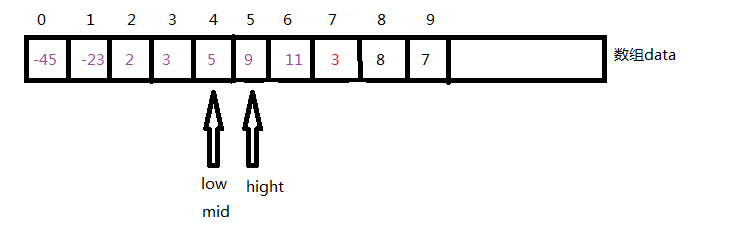
low的位置便是应该插入的位置(该位置满足data[low]>待插入的值,data[hight]<=待插入的值,或者hight为-1,也就是插入的位置为0)
5 将low到i-1的数字都往后移动腾出low的位置将插入值插入,注意备份i位置的值避免被覆盖后找不回待插入值。

public static void binaryInsertSort(int[] array){
for(int i = 1; i < array.length; i++){
int temp = array[i];
int low = 0;
int high = i - 1;
while(low <= high){ //当low>high时就会跳出循环
int mid = (low + high) / 2;
if(temp < array[mid]){ //用temp保存要插入的值
high = mid - 1;
}
else {
low = mid + 1;
}
}
for(int j = i; j >= low + 1; j--){
array[j] = array[j - 1];
}
array[low] = temp; //要插入的位置一定是low的位置
}
}3、希尔排序(最小增量排序)
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
先取一个正整数d1 < n, 把所有相隔d1的记录放一组,每个组内进行直接插入排序;然后d2 < d1,重复上述分组和排序操作;直至di = 1,即所有记录放进一个组中排序为止。

public static void shellsort(int[] array) {
int i,j,temp;
int gap=1; //表示间隔
int len=array.length;
while(gap<len/3) {gap=gap*3+1;} //通过计算得到一个间隔数,如果不加1,那么间隔数会取到0,这是不允许的
for(;gap>0;gap/=3) { //通过上一步的计算,如果总长度为20,那么间隔为13,4,1
/****下面的计算其实就是直接插入排序了****/
for (i = gap; i < len; i++) {
temp = array[i];
for (j = i - gap; j >= 0 && array[j] > temp; j -= gap) {
array[j + gap] = array[j];
}
array[j + gap] = temp;
}
}
System.out.println(Arrays.toString(array) + " shellsort");
}三种插入排序的时间复杂度和空间复杂度
| 插入排序 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 直接插入排序 | O(n^2) | O(1) |
| 折半插入排序 | O(n^2) | O(1) |
| 希尔排序 | O(n^3/2)~O(n^7/6) | O(1) |
二、选择排序
1、简单选择排序
基本思想:在要排序的一组数中,选出最小的一个数与第一个位置的数交换;
然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。
下面两种方法的思路是一样的,只不过上面那种方法是先用两个变量缓存最小的值和他的位置,最后才交换。
public static void selectSort(int[] array) {
int position = 0;
for (int i = 0; i < array.length; i++) {
int j = i + 1;
position = i;
int temp = array[i];
for (; j < array.length; j++) {
if (array[j] < temp) {
temp = array[j];
position = j;
}
}
array[position] = array[i];
array[i] = temp;
}
System.out.println(Arrays.toString(array) + " selectSort");
}
public static void ansort3(int[] array){
for(int i=0;i<array.length;i++){
for(int j=i+1;j<array.length;j++){
if(array[j]<array[i]){
int temp=array[i];
array[i]=array[j];
array[j]=temp;
}
}
}
}2、堆排序
基本思想:堆排序是一种树形选择排序,是对直接选择排序的有效改进。
堆的定义如下:具有n个元素的序列(h1,h2,...,hn),当且仅当满足(hi>=h2i,hi>=h(2i+1))或(hi<=h2i,hi<=h(2i+1))(i=1,2,...,n/2)时称之为堆。在这里只讨论满足前者条件的堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项(大顶堆)。完全二叉树可以很直观地表示堆的结构。也就是说父节点会比它的左节点和有节点大(小)。堆顶为根,其它为左子树、右子树。初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的存储序,使之成为一个堆,这时堆的根节点的数最大。然后将根节点与堆的最后一个节点交换。然后对前面(n-1)个数重新调整使之成为堆。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
建堆:

交换,从堆中踢出最大数
为什么要和最后一个节点交换?
因为最后一个节点对应数组的最后一个位置,排序完成后数组就是从小到大的排列了,空间复杂度是(1)。

剩余结点再建堆,再交换踢出最大数

依次类推:最后堆中剩余的最后两个结点交换,踢出一个,排序完成。
public class HeapSort {
private int[] arr;
public HeapSort(int[] arr) {
this.arr = arr;
}
/**
* 堆排序的主要入口方法,共两步。
*/
public void sort() {
/*
* 第一步:将数组堆化
* beginIndex = 第一个非叶子节点。
* 从第一个非叶子节点开始即可。无需从最后一个叶子节点开始。
* 从第一个非叶子节点开始的原因(因为它是最后一个叶子节点的parent,就是说他是最后一个节点的
* 父节点)
* 叶子节点可以看作已符合堆要求的节点,根节点就是它自己且自己以下值为最大。
*/
int len = arr.length - 1;
int beginIndex = (len - 1) / 2;
for (int i = beginIndex; i >= 0; i--) {
maxHeapify(i, len);
}
/*
* 第二步:对堆化数据排序
* 每次都是移出最顶层的根节点A[0],与最尾部节点位置调换,同时遍历长度 - 1。
* 然后从新整理被换到根节点的末尾元素,使其符合堆的特性。
* 直至未排序的堆长度为 0。
*/
for (int i = len; i > 0; i--) {
swap(0, i);
maxHeapify(0, i - 1);
}
}
private void swap(int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
* 调整索引为 index 处的数据,使其符合堆的特性。
*
* @param index 需要堆化处理的数据的索引
* @param len 未排序的堆(数组)的长度
*/
private void maxHeapify(int index, int len) {
int li = 2 * index + 1; // 左子节点索引
int ri = li + 1; // 右子节点索引
int cMax = li; // 子节点值最大索引,默认左子节点。
if (li > len) return; // 左子节点索引超出计算范围,直接返回。
if (ri <= len && arr[ri] > arr[li]) // 先判断左右子节点,哪个较大。
cMax = ri;
if (arr[cMax] > arr[index]) {
swap(cMax, index); // 如果父节点被子节点调换,
maxHeapify(cMax, len); // 则需要继续判断换下后的父节点是否符合堆的特性。
}
}
分析(和快排分析比较):
最后我们简要分析下堆排序的时间复杂度。我们在每次重新调整堆时,都要将父节点与孩子节点比较,这样,每次重新调整堆的时间复杂度变为O(logn),而堆排序时有n-1次重新调整堆的操作,建堆时有((len-1)/2+1)次重新调整堆的操作,因此堆排序的平均时间复杂度为O(n*logn)。由于我们这里没有借用辅助存储空间,因此空间复杂度为O(1)。
堆排序在排序元素较少时有点大才小用,待排序列元素较多时,堆排序还是很有效的。另外,堆排序在最坏情况下,时间复杂度也为O(n*logn)。相对于快速排序(平均时间复杂度为O(n*logn),最坏情况下为O(n*n)),这是堆排序的最大优点。
详细的分析可以参考http://www.360doc.com/content/14/0306/11/3705007_358165809.shtml
3、树形选择排序
可以去这里了解一下
https://www.cnblogs.com/kubixuesheng/p/4359406.html(不讲了,好像他比较落后)
三、冒泡排序
基本思想:在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
public static void bubbleSort(int[] array) {
int temp = 0;
for (int i = 0; i < array.length - 1; i++) {
for (int j = 0; j < array.length - 1 - i; j++) {
if (array[j] > array[j + 1]) {
temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
System.out.println(Arrays.toString(array) + " bubbleSort");
} 四、快速排序(对冒泡排序的一种优化)
基本思想:选择一个基准元素,通常选择第一个元素或者最后一个元素,通过一趟扫描,将待排序列分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后再用同样的方法递归地排序划分的两部分。

public class QuickSort {
/**
* 将数组的某一段元素进行划分,小的在左边,大的在右边
*/
public static int divide(int[] a, int start, int end){
//每次都以最右边的元素作为基准值
int base = a[end];
//start一旦等于end,就说明左右两个指针合并到了同一位置,可以结束此轮循环。
while(start < end){
while(start < end && a[start] <= base)
//从左边开始遍历,如果比基准值小,就继续向右走
start++;
//上面的while循环结束时,就说明当前的a[start]的值比基准值大,应与基准值进行交换
if(start < end){
//交换
int temp = a[start];
a[start] = a[end];
a[end] = temp;
//交换后,此时的那个被调换的值也同时调到了正确的位置(基准值右边),因此右边也要同时向前移动一位
end--;
}
while(start < end && a[end] >= base)
//从右边开始遍历,如果比基准值大,就继续向左走
end--;
//上面的while循环结束时,就说明当前的a[end]的值比基准值小,应与基准值进行交换
if(start < end){
//交换
int temp = a[start];
a[start] = a[end];
a[end] = temp;
//交换后,此时的那个被调换的值也同时调到了正确的位置(基准值左边),因此左边也要同时向后移动一位
start++;
}
}
//这里返回start或者end皆可,此时的start和end都为基准值所在的位置
return end;
}
/**
* 排序
*/
public static void sort(int[] a, int start, int end){
if(start > end){
//如果只有一个元素,就不用再排下去了
return;
}
else{
//如果不止一个元素,继续划分两边递归排序下去
int partition = divide(a, start, end);
sort(a, start, partition-1);
sort(a, partition+1, end);
}
}
} 五、归并排序
基本排序:归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。

public static void mergingSort(int[] array) {
sort(array, 0, array.length - 1);
System.out.println(Arrays.toString(array) + " mergingSort");
}
private static void sort(int[] data, int left, int right) {
if (left < right) {
//找出中间索引
int center = (left + right) / 2;
//对左边数组进行递归
sort(data, left, center);
//对右边数组进行递归
sort(data, center + 1, right);
//合并
merge(data, left, center, right);
}
}
/**
* 这是完成两个有序数组的合并操作,可以看出时间复杂的是O(1)
* 2018年2月13日
* 这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。
* 然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
*/
private static void merge(int[] data, int left, int center, int right) {
int[] tmpArr = new int[data.length]; //准备一个暂存数组
int mid = center + 1;
//third记录中间数组的索引
int third = left;
int tmp = left;
while (left <= center && mid <= right) {
//从两个数组中取出最小的放入中间数组
if (data[left] <= data[mid]) {
tmpArr[third++] = data[left++];
} else {
tmpArr[third++] = data[mid++];
}
}
//剩余部分依次放入中间数组
while (mid <= right) {
tmpArr[third++] = data[mid++];
}
while (left <= center) {
tmpArr[third++] = data[left++];
}
//将中间数组中的内容复制回原数组
while (tmp <= right) {
data[tmp] = tmpArr[tmp++];
}
}
归并排序的效率是比较高的,设数列长为N,将数列分开成小数列一共要logN步,每步都是一个合并有序数列的过程,时间复杂度可以记为O(N),故一共为O(N*logN)。因为归并排序每次都是在相邻的数据中进行操作,所以归并排序在O(N*logN)的几种排序方法(快速排序,归并排序,希尔排序,堆排序)也是效率比较高的,但是空间复杂度为O(N),所以内部排序一般用快速排序,外部排序才考虑用归并排序。
六、基数排序
基本思想:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
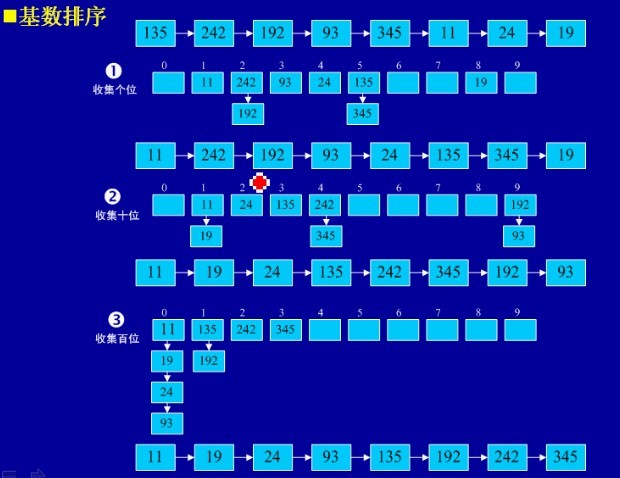
public static void radixSort(int[] array) {
//首先确定排序的趟数;
int max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i] > max) {
max = array[i];
}
}
int time = 0;
//判断位数;
while (max > 0) {
max /= 10;
time++;
}
//建立10个队列;
ArrayList<ArrayList<Integer>> queue = new ArrayList<>();
for (int i = 0; i < 10; i++) {
ArrayList<Integer> queue1 = new ArrayList<>();
queue.add(queue1);
}
//进行time次分配和收集;
for (int i = 0; i < time; i++) {
//分配数组元素;
for (int anArray : array) {
//得到数字的第time+1位数;
int x = anArray % (int)Math.pow(10, i + 1) / (int)Math.pow(10, i);
ArrayList<Integer> queue2 = queue.get(x);
queue2.add(anArray);
queue.set(x, queue2);
}
int count = 0;//元素计数器;
//收集队列元素;
for (int k = 0; k < 10; k++) {
while (queue.get(k).size() > 0) {
ArrayList<Integer> queue3 = queue.get(k);
array[count] = queue3.get(0);
queue3.remove(0);
count++;
}
}
}
System.out.println(Arrays.toString(array) + " radixSort");
}















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









