






在现代软件开发过程中,随着项目规模的不断增大,开发者面对的挑战也越来越多,我们需要借助开发工具帮助我们更好地理解整个项目,比如:
代码编辑器的代码高亮功能帮助开发者迅速区分语法元素,如变量、函数、关键字等,鼠标 hover 上去还可以快速查看变量属性和函数定义。
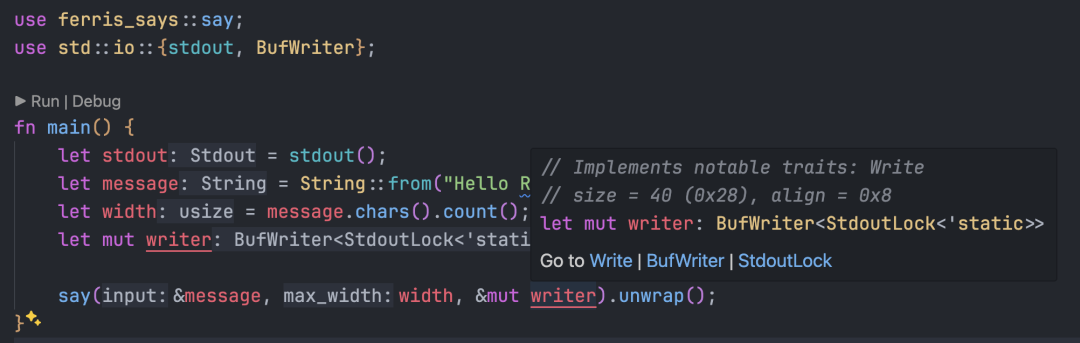
当我们在 Github 中查看源码时,Github 提供了 Navigating code 的能力,帮助我们快速在函数或变量的定义和引用之间跳转,甚至可以跨 Repo 进行。
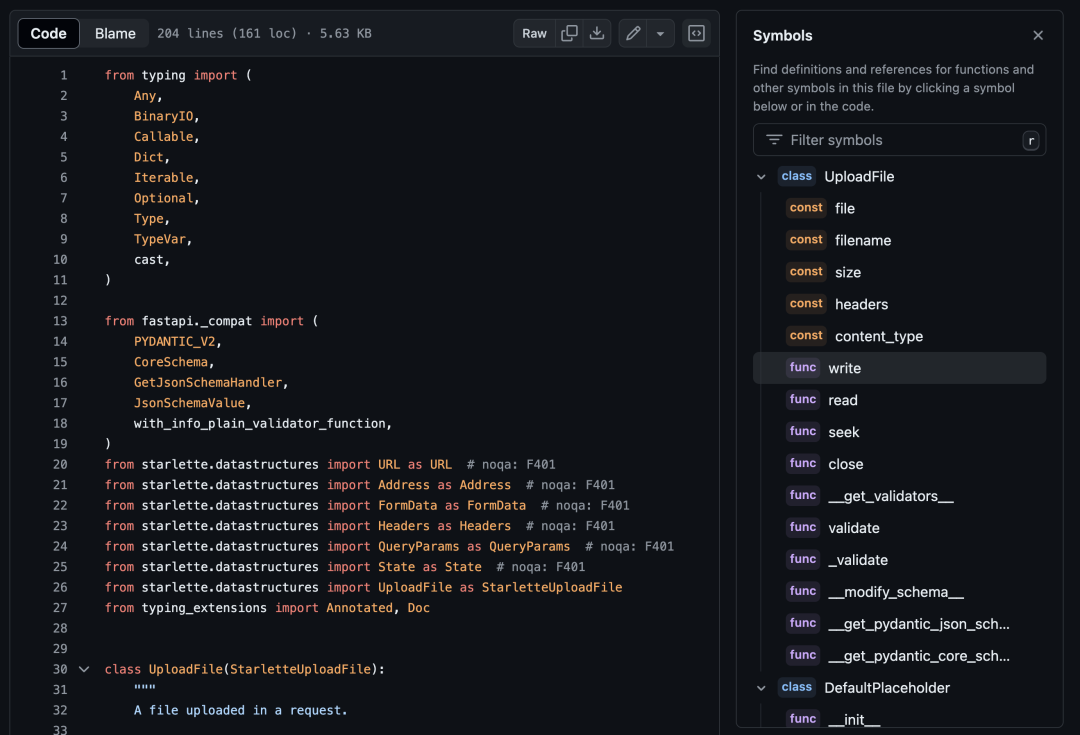
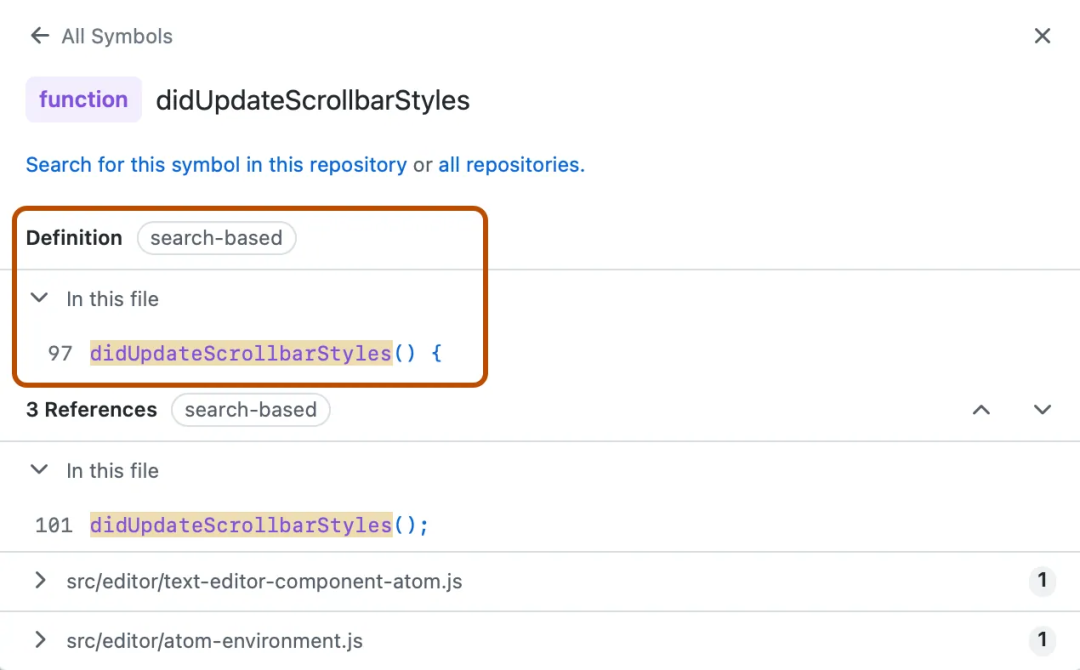
当我们开发前端项目时,常常会使用 Prettier 等工具自动格式化代码,以确保团队项目代码风格的一致性。
上述的三种场景在底层实现上都依赖了语法树技术,其不光在代码编译技术中至关重要,同时在代码分析、代码处理等应用场景下也起到了核心作用。
如果你是一名前端开发,你应该知道我们可以用 @babel/parser 库来解析生成JavaScript 的 抽象语法树(Abstract Syntax Tree,AST),用于 JavaScript 的语言转译,将现代 JavaScript 转换成兼容老版本浏览器的代码。
我们今天要聊的 Tree-sitter 是一个通用的 具体语法树(Concrete Syntax Tree,CST,也可以叫 Parse Tree,即 PT)解析生成工具,最初被用于 Atom 文本编辑器,后续被用于越来越多的地方,比如上文提到的 GitHub Navigating Code 功能,它具有以下特点:
通用:支持绝大部分编程语言
快速:具备增量构建能力
健壮:即使存在语法错误,也可以输出有效的结果
无依赖:使用纯 C 编写,并提供 wasm 包可以在浏览器环境高效运行
AST vs CST
很多 Paser 在工作时,会首先生成 CST,包含所有的代码细节,再经过一些操作,去除冗余的语法信息,只保留语义相关的部分,将 CST 转化为 AST。所以一般来说 AST 相比 CST 的抽象程度更高,CST 生成更快。
不过 CST 优点也在于它存储了更加完整的语法细节,这使得它在 代码补全、代码格式化、语法高亮 等领域相比 AST 更为合适。
上手 Tree-sitter
刚刚为大家简单介绍了下背景,相信大家对 Tree-sitter 已经有了一些大致的了解,接下来我们正式聊一聊 Tree-sitter 的使用。
虽说 Tree-sitter 解析功能都是通过 C API 暴露的,但官方提供了一些主流语言的 Binding Library,所以我们可以使用 JavaScript、Python 等语言快速使用 Tree-sitter。
后续为了方便,我会使用 Node.js 版的 Tree-sitter —— node-tree-sitter 来为大家做进一步讲解。(Tree-sitter 有对应的 wasm 版本,所以在浏览器环境也可以使用,但是演示起来相对比较复杂,大家感兴趣可以去官网了解下)
基础概念
首先,进行包的安装:
npm install tree-sitter
npm install tree-sitter-javascript接下来我们尝试解析一段简单的 JavaScript 代码片段:
const Parser = require('tree-sitter'); // Parser
const JavaScript = require('tree-sitter-javascript'); // Language
const parser = new Parser();
parser.setLanguage(JavaScript); // 为 Parser 设置 Language
const sourceCode = 'let x = 1; console.log(x);';
const tree = parser.parse(sourceCode); // Tree
const rootNode = tree.rootNode; // Node在这段代码涵盖了 Tree-sitter 中的四个最重要的概念:
Parser: 是一个具有状态的对象,可以被赋予一种Language来对特定编程语言进行解析生成TreeLanguage:一个不透明的对象,内部定义了如何对特定编程语言进行解析Tree:表示源码的语法树,容纳了Node实例,可以对Tree进行编辑并生成新的TreeNode:表示语法树的单个节点,存储着语法节点在源码中的开始结束位置,以及父子兄弟节点等关系信息。
解析生成语法树
我们继续,看看 Tree-sitter 生成的语法树结构是怎样的:
console.log(rootNode.toString());
// Input:
// 'let x = 1; console.log(x);'
// Output:
// (program
// (lexical_declaration
// (variable_declarator name: (identifier) value: (number)))
// (expression_statement
// (call_expression
// function: (member_expression object: (identifier) property: (property_identifier))
// arguments: (arguments (identifier)))))我们在代码中输出了语法树的字符串表示,是 S-expression 风格的。我们可以看到我们我们的整个程序的根节点为 program 节点,其中包含的两个语句在语法树被表示为 lexical_declaration (词法声明) 和 expression_statement (表达式语句)两个节点。其中更细的部分我们也可以看得很清楚。
什么是 S-expression?
S-expression(符号表达式)是一种简单的表示形式,最初用于 Lisp 编程语言,以表达程序和数据。它由括号包围的 List 组成,List 里的元素可以是 Atom(如数字或符号)或其他 List。这种语法具备简洁性和一致性,同时易于解释执行。S-expression 非常适合表示嵌套结构,使其在函数式编程和数据处理中广受欢迎。
例如,表达式
(+ 1 (* 2 3))描述了1 + (2 * 3)。
具名节点 和 匿名节点
细心的小伙伴可能已经发现了,我们上一节生成的语法树看上去和 AST 没有什么不同,没有体现出所谓的 CST。其实这是因为在上一节生成的语法树字符串表示中没有包含 Tree-sitter 中的「匿名节点」。
Tree-sitter 生成的是 CST,CST 会包含源码中所有的独立 Token,包括逗号、括号、分号之类的。这样详细的语法树对代码高亮等场景非常重要。但对于代码分析等场景更适合使用 AST,AST 删除了哪些不太重要的细节。Tree-sitter 将诸如关键字、逗号、分号等语法节点标记为「匿名节点」,在语法中被明确定义的部分标记为「具名节点」。
我们上代码:
console.log(rootNode.children[0]); // LexicalDeclarationNode
console.log(rootNode.children[0].children); // [SyntaxNode, VariableDeclaratorNode, SyntaxNode]
console.log(rootNode.children[0].children[2].text); // ';'
console.log(rootNode.children[0].children[2].isNamed); // false可以观察到 Tree-sitter 确实生成的是 CST,其中包含了我们在字符串表示中没有看到的 SyntaxNode 。找到我们的分号节点,并通过 isNamed 方法,可以看到其为「匿名节点」。
如此一来,通过是否排除「匿名节点」,Tree-sitter 就可以同时支持 CST 和 AST。
节点字段
为了使语法节点更容易分析,Tree-sitter 为特定的节点赋予了唯一的字段。还以我们之间例子中的 VariableDeclaratorNode 为例。
const variableDeclaratorNode = rootNode.children[0].children[1]; // VariableDeclaratorNode
console.log(variableDeclaratorNode.text); // 'x = 1'
console.log(variableDeclaratorNode.fields); // ['nameNode', 'valueNode']
console.log(variableDeclaratorNode.nameNode.text); // 'x'
console.log(variableDeclaratorNode.valueNode.text); // '1'可以看到,Tree-sitter 将特定的节点字段存储在了 fields 中,我们可以以此找到在 VariableDeclaratorNode 特定的字段,这些字段和我们之前的字符串表示之间是能够找到对应关系的。
如果存在错误 …
Tree-sitter 不仅对语法正确的代码片段生效,也能对存在语法错误的代码片段生效,提供精准信息,这是很多 AST Parser 无法做到的,请看如下代码:
const wrongCode = `var 42num = 42`
console.log(parser.parse(wrongCode).rootNode.toString());
// (program
// (variable_declaration
// (ERROR (number))
// (variable_declarator name: (identifier) value: (number))))在这个 case 中,Tree-sitter 找到了代码中的错误。
利用 Query 进行模式匹配
Tree-sitter 不光能构建语法树,也能方便的通过一种声明式的语言对语法树进行模式匹配,匹配语法树中的特定节点。这让我们在对代码片段进行分析的操作变得简单高效。
下面我为大家简单介绍一下这种 query 语言的语法,篇幅有限,我只为大家讲解最基础的部分,详细内容大家可以到 Tree-sitter 的官网文档查看(https://tree-sitter.github.io/tree-sitter/using-parsers#pattern-matching-with-queries)。
在前文中,我们提到 Tree-sitter 的语法树字符串表示格式风格为 S-expression,这让我们可以更加直观的对语法树进行查询,因为这种 query 语言同样符合 S-expression 风格,我们最终的查询语句就是一组 S-expression。
这一节我们可以使用 Tree-sitter 官网的 Syntax Tree Playground (https://tree-sitter.github.io/tree-sitter/playground),进行匹配时会更加直观。
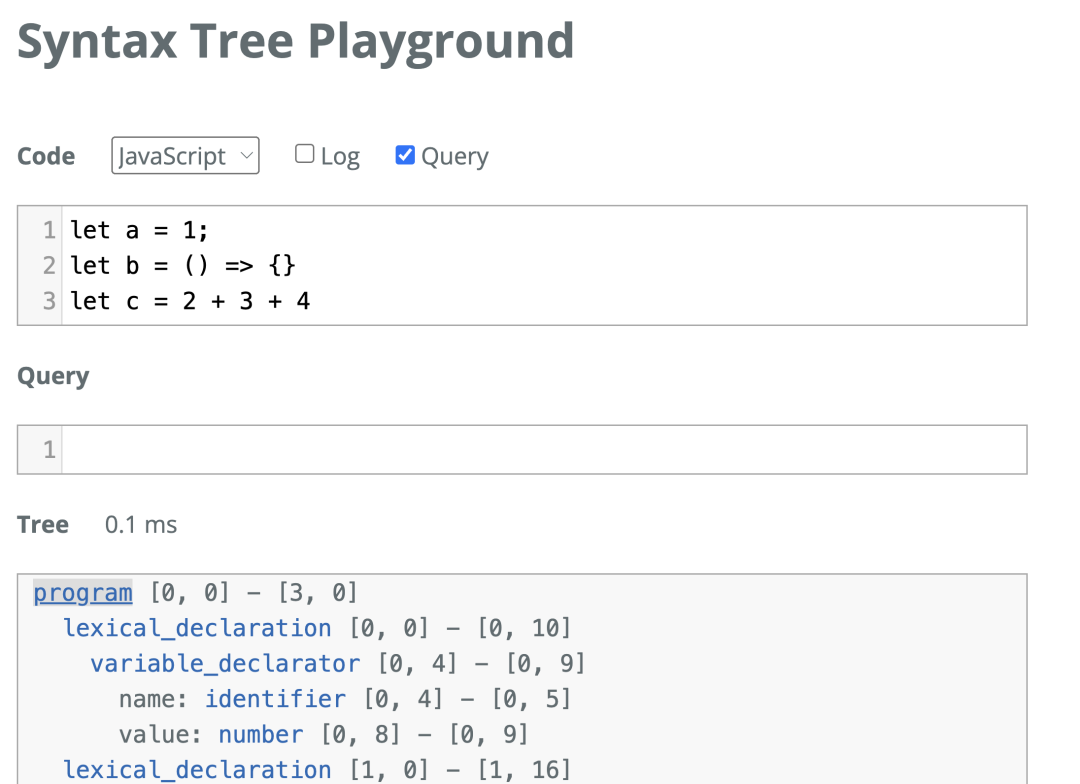
可以通过选中「Query」配置,来打开 Query 面板。
Tree-sitter 的 query 由一个或多个模式组成,每个模式都是 S-expression 风格的。
举个例子,我们使用以下模式,可以匹配所有子节点均为 number 的 binary_expression:
(binary_expression (number) (number))也可以省略其中的一个子节点,匹配有一个子节点为 number 的 binary_expression:
(binary_expression (number))我们可以对这些节点进行捕获,为我们的模式匹配到的节点进行命名:
(binary_expression (number) (number)) @num_binary_expression
(variable_declarator (identifier) @definition.variable)效果可以非常直观的在 Syntax Tree Playground 中看到,不同的捕获节点使用了不同的颜色表示: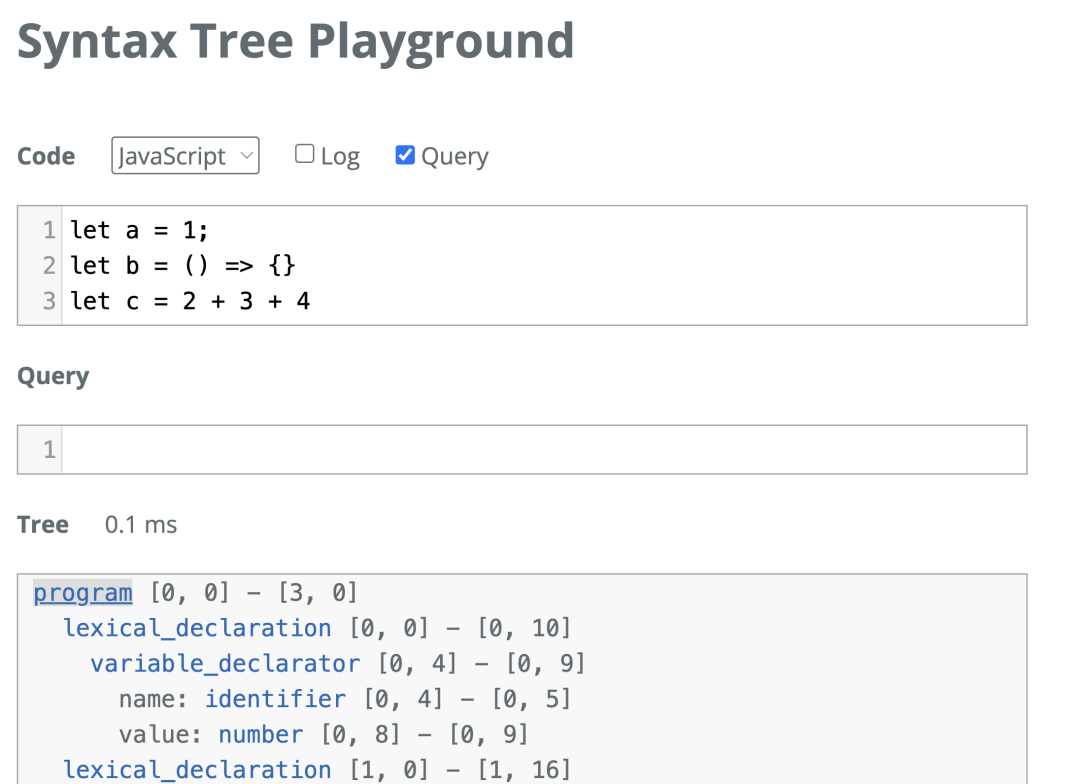
在第一行的模式匹配,我们对子节点均为 number 的 binary_expression 节点进行了捕获,第二行,我们对 variable_declarator 下的 identifier 节点进行捕获。
另外,我们也可以使用前文提到的部分节点具有的特殊字段来进行匹配:
(variable_declarator value: (arrow_function) @definition.arrow_function)
如此,我们匹配到了进行变量声明时,被赋值的箭头函数。
我们在代码中自己试一下:
const Parser = require('tree-sitter');
const JavaScript = require('tree-sitter-javascript');
const { Query } = require('tree-sitter');
const parser = new Parser();
parser.setLanguage(JavaScript);
const sourceCode = `
let a = 1;
let b = () => {}
let c = 2 + 3 + 4
let d = '1' + 2 + true
let e = a + b + c`;
const tree = parser.parse(sourceCode);
const patterns = `
(variable_declarator (arrow_function) @definition.arrow_function)
(variable_declarator (identifier) @definition.var)
`;
const query = new Query(JavaScript, patterns);
const matches = query.matches(tree.rootNode);
console.log(matches);
// Output:
// let a = [
// {
// pattern: 1,
// captures: [{
// name: 'definition.var',
// node: IdentifierNode { type: 'identifier', ... }
// }]
// },
// ...
// ];实战:构建一个简易的语法高亮系统
我们刚刚说了一堆比较枯燥的理论,但是用的上的理论才是好理论。我们这一节来尝试构建一个简易的语法高亮系统,虽说 Tree-sitter 其实提供了 tree-sitter-highlight 库来处理这种任务,也可以通过 CLI 工具 方便调用,但我觉得我们通过刚学到的知识自己实现一个也是很有价值的。
首先,我们新建项目并安装必要的依赖:
npm install tree-sitter tree-sitter-javascript然后准备一个待语法高亮的示例代码 example.js ,这里你也可以用自己的代码试试:
// 定义一个变量
let greeting = 'Hello, World!';
/**
* 打印问候语
* @param {string} message - 要打印的消息
*/
function printGreeting(message) {
console.log(message);
}
// 定义一个类
class Person {
/**
* 创建一个新的 Person 实例
* @param {string} name - 名字
* @param {number} age - 年龄
*/
constructor(name, age) {
this.name = name;
this.age = age;
}
/**
* 打印人的信息
*/
printInfo() {
console.log(`Name: ${this.name}, Age: ${this.age}`);
}
}
// 调用函数
printGreeting(greeting);
// 创建一个 Person 实例并调用方法
let person = new Person('Alice', 30);
person.printInfo();然后我们创建 main.js 写我们的主流程:
const fs = require('fs');
const Parser = require('tree-sitter');
const JavaScript = require('tree-sitter-javascript');
const { Query } = require('tree-sitter');
const parser = new Parser();
parser.setLanguage(JavaScript);
const sourceCode = fs.readFileSync('example.js', 'utf8');然后我们创建 queries.scm 来编写 query 语句,对代码中的一些关键语法结构做查询,针对匹配到的元素,我们后续就可以对其进行高亮处理了:
[
"function"
"const"
"let"
"var"
"if"
"else"
"for"
"while"
"return"
"class"
"import"
"export"
"from"
"new"
"try"
"catch"
"finally"
"throw"
"switch"
"case"
"default"
"break"
"continue"
"do"
"typeof"
"instanceof"
"void"
"delete"
"in"
"of"
"with"
"yield"
"await"
"async"
"{"
"${"
"}"
"("
")"
"`"
] @keyword
(function_declaration name: (identifier) @function)
(call_expression function: (identifier) @function)
(method_definition name: (property_identifier) @function)
(call_expression
function: (member_expression
object: (identifier) @variable
property: (property_identifier) @function)
arguments: (arguments))
(class_declaration name: (identifier) @class)
(new_expression constructor: (identifier) @class)
(variable_declarator name: (identifier) @variable)
(assignment_expression right: (identifier) @variable)
(call_expression arguments: (arguments (identifier) @variable))
(formal_parameters (identifier) @variable)
(member_expression property: (property_identifier) @variable)
(this) @variable
(string) @string
(template_string (string_fragment) @string)
(number) @number
(comment) @comment然后在我们的 main.js 中读取 queries.scm 并创建 Query 对象,后续会使用其对语法树进行查询,另外我还创建了对应每一个语法结构的一个样式表,后面可以附在 HTML 中:
const query = new Query(JavaScript, fs.readFileSync('queries.scm', 'utf8'));
// 定义样式
const styles = {
keyword: 'color: #d55fde;',
variable: 'color: #ef596f;',
function: 'color: #61afef;',
class: 'color: #e5c07b;',
string: 'color: #89ca78;',
number: 'color: #d19a66;',
comment: 'color: #7f848e; font-style: italic;',
};然后,我们在 main.js 中写一下高亮逻辑:
// 生成高亮HTML
function generateHighlightedHTML(source, query) {
const tree = parser.parse(source);
const matches = query.matches(tree.rootNode);
const parts = extractParts(matches, source);
const filteredParts = filterOverlappingParts(parts);
return buildHTML(source, filteredParts);
}
// 提取匹配部分
function extractParts(matches, source) {
const parts = [];
for (const match of matches) {
for (const capture of match.captures) {
const { startIndex, endIndex } = capture.node;
parts.push({
startIndex,
endIndex,
className: capture.name,
text: source.slice(startIndex, endIndex),
priority: match.pattern
});
}
}
return parts;
}
// 过滤重叠部分
function filterOverlappingParts(parts) {
parts.sort((a, b) => {
if (a.startIndex === b.startIndex) {
if (a.endIndex === b.endIndex) {
return a.priority - b.priority;
}
return a.endIndex - b.endIndex;
}
return a.startIndex - b.startIndex;
});
const filteredParts = [];
let lastPart = null;
parts.forEach((part) => {
if (lastPart && part.startIndex === lastPart.startIndex && part.endIndex === lastPart.endIndex) {
if (part.priority < lastPart.priority) {
lastPart = part;
}
} else {
if (lastPart) {
filteredParts.push(lastPart);
}
lastPart = part;
}
});
if (lastPart) {
filteredParts.push(lastPart);
}
return filteredParts;
}最终,我们在 main.js 中利用匹配到的模式输出为 HTML:
// 构建HTML
function buildHTML(source, parts) {
let lastIndex = 0;
let html = '';
parts.forEach((part) => {
const beforeText = source.slice(lastIndex, part.startIndex);
html += `${escapeHTML(beforeText)}<span class="${part.className}">${escapeHTML(part.text)}</span>`;
lastIndex = part.endIndex;
});
html += escapeHTML(source.slice(lastIndex));
return html;
}
// 转义HTML
function escapeHTML(str) {
return str.replace(/&/g, '&').replace(/</g, '<').replace(/>/g, '>');
}
// 写入HTML文件
function writeHTMLPage(highlightedHTML) {
const htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Highlighted Code</title>
<style>
pre {
background-color: #23272e;
color: white;
padding: 10px;
}
${Object.entries(styles)
.map(([className, style]) => `.${className} { ${style} }`)
.join('\n')}
</style>
</head>
<body>
<pre>${highlightedHTML}</pre>
</body>
</html>
`;
fs.writeFileSync('highlighted.html', htmlContent);
}
// 主流程
const highlightedHTML = generateHighlightedHTML(sourceCode, query);
writeHTMLPage(highlightedHTML);可以看到最终效果还可以: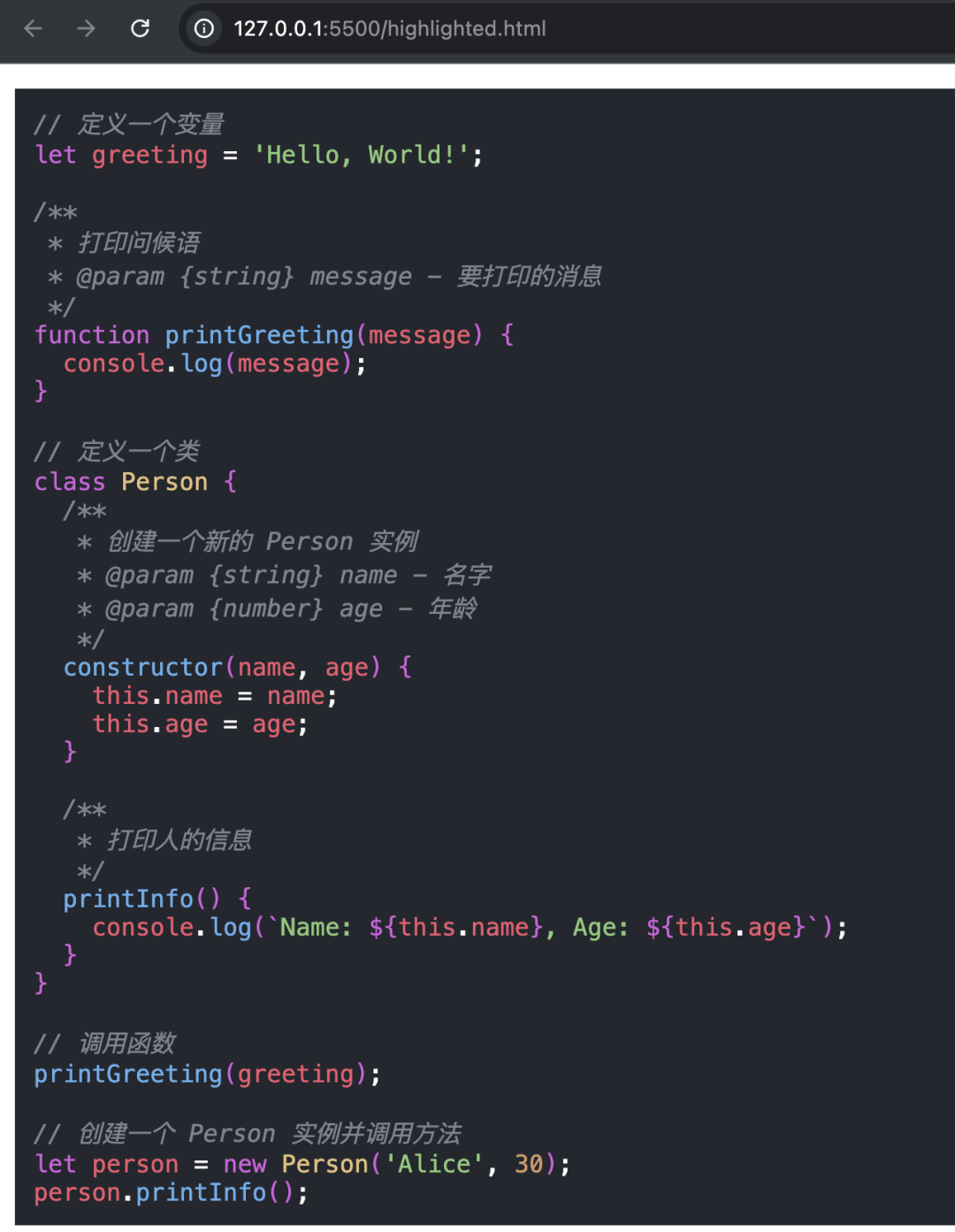
结语
谢谢你能看到这里,在本文中我们学习了 Tree-sitter 的一些基础概念和基本用法,也通过实战尝试触碰了下 Real World,但其实 Tree-sitter 的一些更加强大有趣的特性我们还没有使用,大家感兴趣可以继续深入,不仅可以享受到 Tree-sitter 强大能力带来的好处,也可以对编译原理、语法树等知识了解的更加透彻。
我也在不断学习相关知识,如果我有说错的地方欢迎大家指正补充~
参考文献
Tree-Sitter 官网: https://tree-sitter.github.io/tree-sitter/code-navigation-systems
Wikipedia - Abstract syntax tree: https://en.wikipedia.org/wiki/Abstract_syntax_tree
Wikipedia - Parse Tree: https://en.wikipedia.org/wiki/Parse_tree
Abstract Syntax Tree vs Parse Tree : https://www.geeksforgeeks.org/abstract-syntax-tree-vs-parse-tree/
Treesitter 入门: https://shellraining.xyz/docs/tools/treesitter/start.html
How to write a linter using tree-sitter in an hour: https://siraben.dev/2022/03/22/tree-sitter-linter.html
- END -
如果您关注前端+AI 相关领域可以扫码进群交流


扫码进群2或添加小编微信进群1😊
关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。


















 3518
3518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









