






本文译者为 360 奇舞团前端开发工程师
原文标题:The rise of the AI crawler原文作者:Giacomo Zecchini, Alice Alexandra Moore, Malte Ubl, Ryan Siddle
原文地址:https://vercel.com/blog/the-rise-of-the-ai-crawler#geographic-distribution
MERJ和Vercel提供的真实数据显示,顶级AI爬虫展现出独特的行为模式。
AI爬虫已成为互联网生态中不可忽视的存在。过去一个月,OpenAI的GPTBot在Vercel网络上生成了5.69亿次请求,Anthropic的Claude紧随其后达到3.7亿次。作为对比,这一总量约占同期Googlebot 45亿请求量的20%。
在通过MERJ完成Googlebot处理JavaScript渲染机制的分析后,我们将研究焦点转向这些AI助手。新数据显示了OpenAI的ChatGPT、Anthropic的Claude等工具如何抓取和处理网页内容。
我们发现了这些爬虫处理JavaScript的方式、内容类型优先级和网络导航的清晰规律,这些发现直接影响AI工具对现代Web应用的理解与交互方式。
数据收集过程
核心数据来自对nextjs.org和Vercel网络数月的监测。为验证不同技术栈下的发现,我们还分析了两个招聘网站:Resume Library(基于Next.js构建)和CV Library(使用自定义单体框架)。这种多样性数据有助于确保我们对爬虫行为的观察在不同网络架构下的一致性。
有关数据收集的更多细节,请参阅首篇文章。
注:Microsoft Copilot因缺乏可追踪的独特用户代理未被纳入研究。
规模与分布
Vercel网络中的AI爬虫流量规模惊人。过去一个月:
Googlebot:通过Gemini和搜索产生45亿次抓取
GPTBot(ChatGPT):5.69亿次抓取
Claude:3.7亿次抓取
AppleBot:3.14亿次抓取
PerplexityBot:2440万次抓取
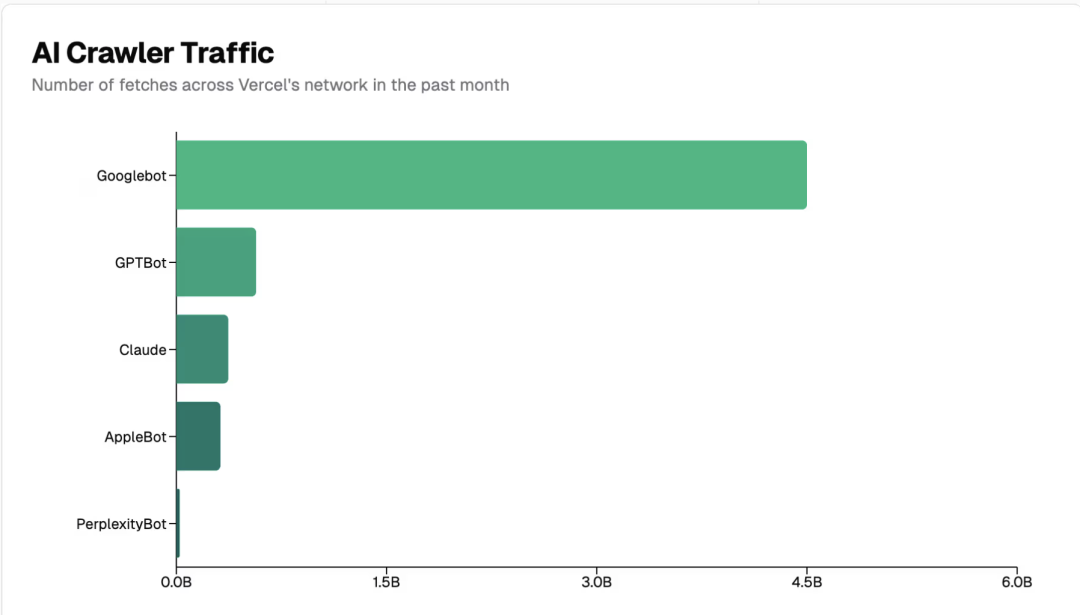
虽然AI爬虫尚未达到Googlebot的规模,但已占据网络爬虫流量的重要部分。GPTBot、Claude、AppleBot和PerplexityBot的总抓取量近13亿次,相当于Googlebot流量的28%。
地理分布
所有被测AI爬虫均从美国数据中心运行:
ChatGPT:得梅因(爱荷华州)、凤凰城(亚利桑那州)
Claude:哥伦布(俄亥俄州)
相比之下,传统搜索引擎通常跨多区域分布爬取。例如Googlebot在美国七地运营,包括达尔斯(俄勒冈州)、康瑟尔布拉夫斯(爱荷华州)和蒙克斯科纳(南卡罗来纳州)。
JavaScript渲染能力
分析显示AI爬虫在JavaScript渲染能力上存在明显差异。通过对Next.js应用和传统技术栈网站的双重验证,我们得出统一结论:主要AI爬虫均未实现JavaScript渲染,包括:
OpenAI(OAI-SearchBot、ChatGPT-User、GPTBot)
Anthropic(ClaudeBot)
Meta(Meta-ExternalAgent)
ByteDance(Bytespider)
Perplexity(PerplexityBot)
其他发现:
谷歌Gemini沿用Googlebot基础设施,具备完整JavaScript渲染能力
AppleBot通过基于浏览器的爬虫实现类似Googlebot的JavaScript渲染,可处理CSS、Ajax请求等完整页面渲染所需资源
常用于大语言模型训练的Common Crawl(CCBot)不渲染页面
数据表明,虽然ChatGPT和Claude爬虫会获取JavaScript文件(ChatGPT:11.50%,Claude:23.84%请求量),但不会执行。这意味着它们无法读取客户端渲染内容。
需注意的是,初始HTML响应中包含的JSON数据或延迟的React服务器组件仍可能被索引,因为AI模型可以解析非HTML内容。相比之下,Gemini凭借谷歌基础设施具备完整处理现代Web应用的能力,正如我们在Googlebot分析中所述。
内容类型优先级
AI爬虫在nextjs.org上展现出明显的内容偏好:
ChatGPT侧重HTML内容(57.70%抓取量)
Claude重点关注图像(占总抓取量35.17%)
虽然在JavaScript文件上花了大量时间(ChatGPT:11.50%,Claude:23.84%),但却不执行
相较之下,Googlebot(Gemini和搜索)抓取分布更均衡:
31.00% HTML内容
29.34% JSON数据
20.77% 纯文本
15.25% JavaScript
这些模式表明AI爬虫收集多样化内容类型(HTML、图像甚至作为文本的JavaScript文件),可能是为了用不同形式的网络内容训练模型。传统搜索引擎(如谷歌)已针对搜索索引优化爬取模式,而新兴AI公司仍在完善其内容优先级策略。
爬取效率
数据显示AI爬虫存在显著低效行为:
ChatGPT 34.82%抓取量消耗在404页面
Claude 34.16%抓取量遭遇404错误
ChatGPT另有14.36%抓取量用于重定向
404错误分析显示(排除robots.txt),这些爬虫频繁尝试获取/static/文件夹中的过时资源,表明需要改进URL选择和处理策略。这种高错误率与Googlebot形成鲜明对比(仅8.22%抓取量用于404,1.49%用于重定向),说明谷歌在优化爬虫定位真实资源方面投入更多。
流量相关性分析
流量模式分析揭示爬虫行为与网站流量的有趣关联(基于nextjs.org数据):
自然流量高的页面获得更频繁爬虫访问
AI爬虫URL选择模式可预测性较低
高404率暗示AI爬虫需改进URL选择和验证流程
传统搜索引擎已开发复杂优先级算法,而AI爬虫的网页内容发现策略似乎仍在演进。
我们与Vercel的研究表明,AI爬虫虽快速扩张,但在处理JavaScript和高效爬取内容方面仍面临重大挑战。随着AI驱动网络体验的加速普及,品牌必须确保关键信息采用服务器端渲染,并持续优化网站以在日益多元的搜索生态中保持可见性。
Ryan Siddle, MERJ董事总经理
建议
针对希望被爬取的网站所有者
关键内容优先采用服务器端渲染:因ChatGPT和Claude不执行JavaScript,重要内容(文章、产品信息、文档)、元信息(标题、描述、分类)和导航结构需服务器渲染。SSR、ISR和SSG可确保所有爬虫访问内容
客户端渲染仍适用于增强功能:视图计数器、交互式UI增强、实时聊天组件等非核心动态元素可自由使用客户端渲染
高效URL管理至关重要:AI爬虫的高404率突显了维护合理重定向、更新站点地图和保持URL模式一致的重要性
针对不希望被爬取的网站所有者
使用
robots.txt控制访问:该文件对所有被测爬虫有效。通过指定用户代理或产品令牌限制AI爬虫访问敏感内容(需查阅各公司文档,如Applebot和OpenAI爬虫)通过Vercel WAF阻止AI爬虫:阻止AI爬虫防火墙规则可一键配置防火墙拒绝访问
针对AI用户
JavaScript渲染内容可能缺失:因ChatGPT和Claude不执行JavaScript,其对动态Web应用的响应可能不完整或过时
注意信息来源:高404率(>34%)意味着AI工具提供的网页链接有较大几率失效。关键信息请直接验证原始来源
预期信息时效性差异:Gemini依托谷歌基础设施,其他AI助手的数据更新模式较难预测,可能引用旧缓存数据
有趣的是,即使要求Claude或ChatGPT获取最新Next.js文档数据,我们在nextjs.org服务器日志中也鲜见即时抓取。这表明AI模型可能依赖缓存或训练数据,即便声称已获取最新信息。
最终结论
AI爬虫以每月近10亿次的请求量迅速成为网络重要参与者。但其在渲染能力、内容优先级和效率方面与传统搜索引擎差异显著。遵循既定的Web开发最佳实践(特别是内容可访问性)仍至关重要。
- END -
如果您关注前端+AI 相关领域可以扫码进群交流

添加小编微信进群😊
关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









