







第1章 第一行代码
从零开始学习一种编程语言,特别是学习 Python 编程语言,并不难,更何况从现在开始,每个学习者还多了一个强有力的学习工具——大语言模型(Large Language Model,LLM)。
本章重点介绍 Python 语言编程环境的配置,而后要写下具有划时代意义的第一行代码。
1.1 编程语言
可以将语言分为两类,一类是自然地随文化演化的语言,称为自然语言(Natural Language),如汉语、英语、法语等;另一类是根据特定目的、用途,人为创造的语言,称为人造语言(或“人工语言”,Constructed Language)。编程语言(或“程序设计语言”,Programming Language)是用来定义计算机程序的形式语言,属于人造语言。
通常,编程语言可以划分为:
- 机器语言
- 汇编语言
- 高级语言
1.1.1 机器语言
机器语言(Machine Language)是用二进制代码( 0 、1 )表示的计算机能够直接识别和执行的机器指令集合。如图1-1-1所示,就是用机器语言编写的表示字符串 “Hello World” 的程序(关于字符串,参阅第3章3.2节)。阅读它是不是很有挑战性?
机器语言的最大优势是运行速度快,但它的劣势也很明显,比如图1-1-2所示的代码,如果不仔细地分辨,难以发现与图1-1-1所示内容是否有差异。
又由于机器语言是计算机的设计生产者通过硬件结构赋予计算机的操作功能,所以,不同型号计算机的机器语言会有所差别。这就导致机器语言的通用性差。
1.1.2 汇编语言
汇编语言(Assembly Language)是二进制代码的文本形式,使用便于记忆的书写格式表达机器语言指令。如图1-1-3所示,是一段在 X86 计算机、64 位 Linux 操作系统运行的汇编语言程序。即使不理解这段程序,也能看出来,相对于机器语言,对人的友好度已经有了很大提高。
但是,汇编语言非常靠近机器语言,仍然是一条指令对应着一条机器指令,并且某种汇编语言只专用于某类计算机系统,不能在不同系统之间移植。
现在,汇编语言依然有用武之地,因为它有一些独特之处,比如目标程序占用内存少、运行效率高等。当然,与之相伴的代价是开发上的低效。
1.1.3 高级语言
高级编程语言(或“高级语言”,High-level Programming Language)是面向人的编程语言—— It is for Humans ——这不是某一种语言,而是一类语言。一般我们把“机器语言”和“汇编语言”归类为“低级语言”,除此之外的都称为高级语言(如图1-1-4所示)
高级语言之“高级”的原因是使用了大量的英语单词,对开发者而言,更容易理解。最重要的,高级语言摆脱了“硬件的拖累”,不需要与机器语言的指令对应,借助操作系统实现了对硬件的抽象。
1.1.4 Python 编程语言
Python 编程语言是一种的高级编程语言。为什么要学习这种编程语言,其解释是仁者见仁智者见智。先看看由 TIOBE 提供的2024年3月的编程语言排行榜(如图1-1-5所示,来源:https://www.tiobe.com/tiobe-index/ )。
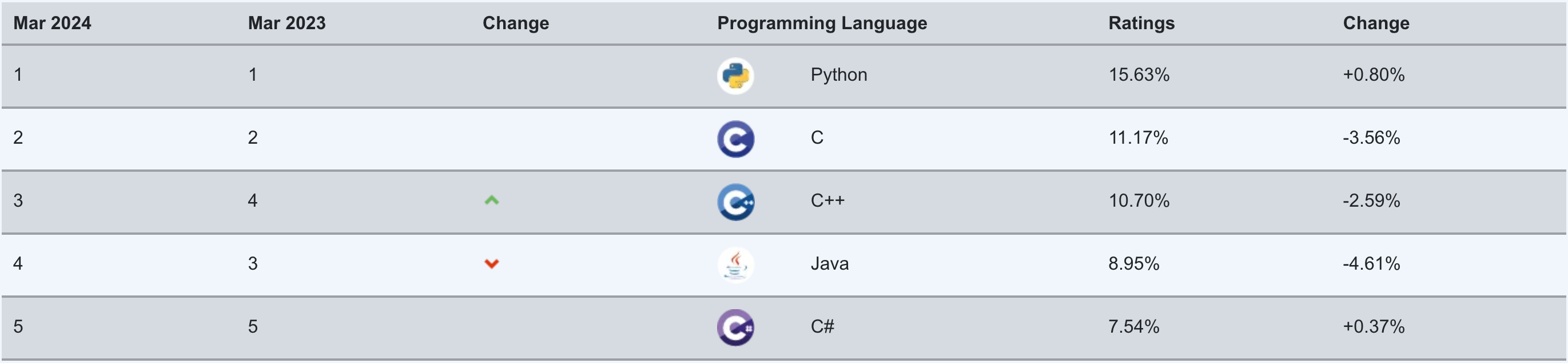
从榜单可见,Python 语言位列第一名。读者查看此排行榜的时候,结果可能会与图1-1-5所示不同,但无论如何,Python 语言在工程、教学等领域,都是颇受欢迎的编程语言。
一种“已过而立之年”的编程语言,缘何有如此魅力? 还要从“初心”开始谈起。

Python 语言的发明人是吉多·范罗苏姆(Guido van Rossum),他发明这种语言的初心都被总结到《Zen of Python》(中文翻译为《 Python 之禅》)。下面列出英文和中文两个版本(中文翻译来自“维基百科”的“ Python 之禅”词条),读者可以对照阅读,从中初步了解 Python 语言的特点。在后续的学习过程中,还可以将所学 Python 语言知识与此处的诗句对照,感悟这些凝练的词语中所蕴含的深刻含义。
| 英文版 | 中文版 |
| Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren’t special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one– and preferably only one –obvious way to do it. Although that way may not be obvious at first unless you’re Dutch. Now is better than never. Although never is often better than right now. If the implementation is hard to explain, it’s a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea – let’s do more of those! | 优美优于丑陋, 明瞭优于隐晦; 简单优于复杂, 复杂优于凌乱, 扁平优于嵌套, 稀疏优于稠密, 可读性很重要! 即使实用比纯粹更优, 特例亦不可违背原则。 错误绝不能悄悄忽略, 除非它明确需要如此。 面对不确定性,拒绝妄加猜测。 任何问题应有一种,且最好只有一种, 显而易见的解决方法。 尽管这方法一开始并非如此直观,除非你是荷兰人。 做优于不做, 然而不假思索还不如不做。 很难解释的,必然是坏方法。 很好解释的,可能是好方法。 命名空间是个绝妙的主意, 我们应好好利用它。 |
现在的 Python 编程语言,由于遵循着“开源、开放”的原则,已经发展成为一个覆盖诸多领域的开放生态系统,例如数据分析、机器学习、网站开发等。
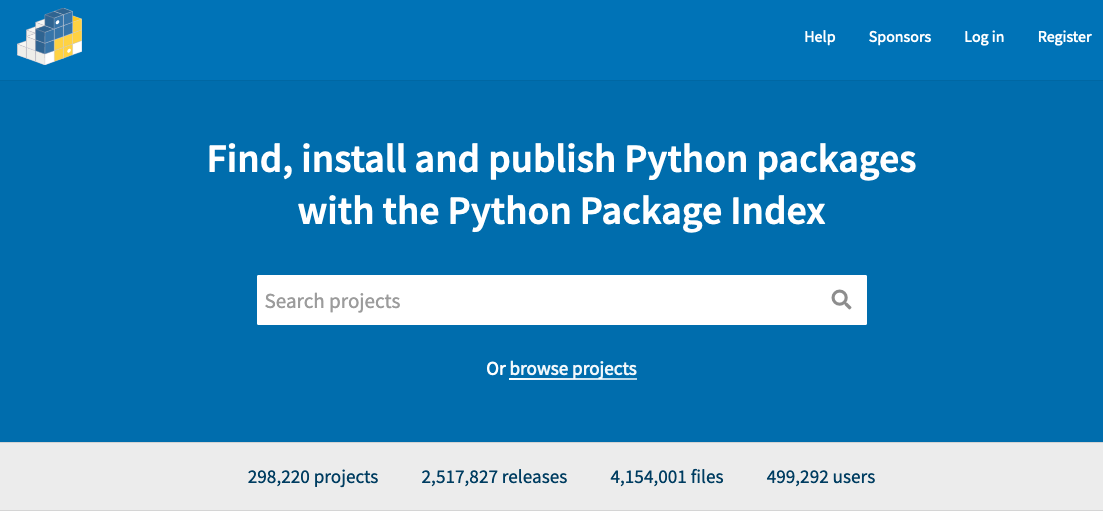
下图是 PyPI 网站的首页( pypi.org ),这个网站专门发布开发者编写的 Python 第三方库(参阅第10章10.4节),至撰写这段内容为止,此网站上已经有 298,220 个项目(如图1-1-7所示)。毫不夸张地说,PyPI 的第三方库几乎涵盖了常规开发的各个领域——需要开发什么,先来这里搜一下,看看有没有“轮子”。正是有如此庞大的生态系统,才让所有使用 Python 语言编程的人感受到了“节省开发者时间”的人本主义精神。
1.2 大语言模型
所谓大语言模型(Large Language Models,LLM),是一种能够理解、预测并生成人类语言的人工智能模型,也俗称为“大模型”(这是一种不严谨的称谓)。比如 ChatGPT、文心一言、通义千问、KIMI、Deepseek、豆包等等,都是 LLM 的产品。目前这类产品均提供面向用户直接使用的界面。
这里我们不探究大语言模型的原理,重点关注的是在学习编程语言和编程工作中如何正确地使用 LLM。
本课程不向读者推荐任何 LLM,或者说读者可以选用任何一家市面上已经发布的 LLM 辅助学习。在后面的内容中,如果因为演示需要,不得不提及某个 LLM 产品,但是这并不意味着本书向读者推荐该产品。
从初级的角度来讲,使用 LLM 辅助学习的方法比较简单。或者说,作为初学者,读者向 LLM 提问有关编程问题时,一般情况下能得到比较令人满意的回复。读者可以在所选定的 LLM 的提问框中输入问题:“如何在 macos 操作系统中配置 Python 编程环境。”看看会得到什么回复信息,并且将回复信息仔细阅读一遍。
诚然,由于当前的 LLM 底层原理和训练模型时所用数据集的限制,LLM 的回答可能会存在如下不足:
- 针对同一个问题,所回答的内容并不唯一。比如图1-2-1所示的提问,如果读者也在文心一言中提问相同的内容,所得到的回复与图1-2-1所示的结果,在大概率上是不同的。
- LLM 并不保证所回复的内容都是正确的。对其正确性的判断,目前还得需要通过人的主观判断或者人利用相关工具辅助实现。因此,在一段时间内,随着 LLM 的应用广度的扩张,对人的要求也不会降低,至少人必须具备判断 LLM 输出信息是否正确的能力。
- 会存在偏见和不公正,这是由训练模型所用的数据集决定的。所以,对于 LLM 的输出信息,人必须秉持“正确的思想观念”来阅读、分析。
- 有时会出现“机器幻觉”,即针对人类的提问,LLM 会生成不准确的、杜撰的信息或数据,回答的内容逻辑混乱、错误或与事实不符。这是由当前 LLM 的底层原理所致。
除了以上各项,LLM 的其他不足不再一一列出。
尽管如此,也不能泯灭 LLM 的光辉,它从现在开始将改变人类社会的方方面面,包括学习和工作。本书将在后续内容中向读者展示如何在学习编程语言中使用 LLM;并以实例的方式,向读者展示如何在编程实践中使用 LLM 的方法。
注意: 在本书的后续内容中,会经常使用【LLM问答】辅助学习,希望学习者在学习过程中,也要频繁地使用它,用它为自己答疑解惑。
1.3 配置开发环境
学习任何一门编程语言,一般都要在本地的计算机上配置该编程语言的开发环境,即安装相应的软件。当然,对于多数编程语言而言,目前也都有在线开发环境可以使用。但从未来实际工作和使用的便捷性角度来看,配置本地的开发环境是必不可少的。
### 1.3.1 了解 Python
Python 语言最权威的资料,一定是来自其官方网站:python.org(如图1-3-1所示)。
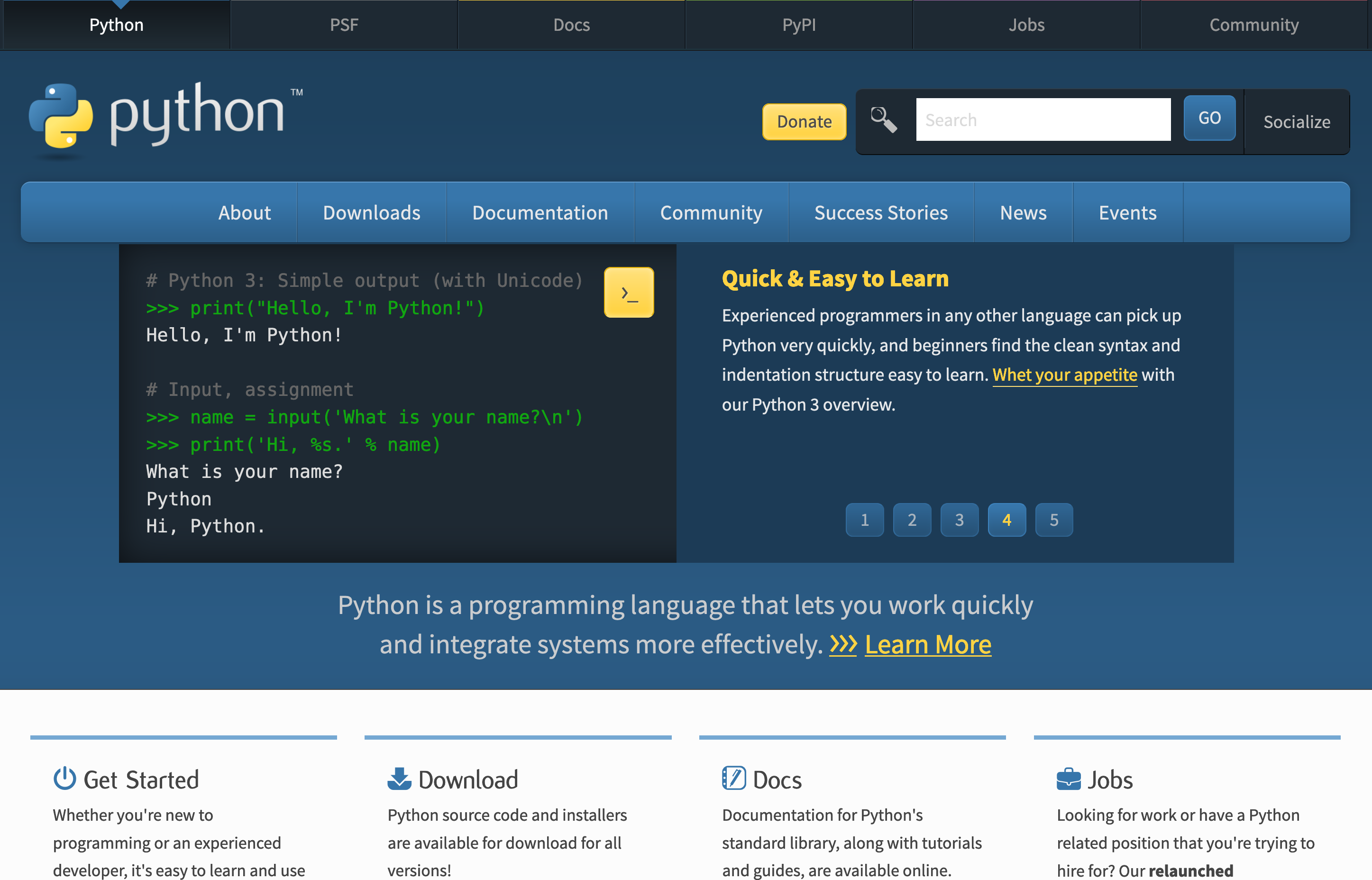
从网站上可知,Python 语言目前支持两大类版本:Python 2 和 Python 3 。这两个大版本有比较明显的差别,并且互不兼容——用 Python 2 编写的程序,无法用 Python 3 直接运行,反之亦然。当前 Python 官方支持的是 Python 3。
但是 Python 3 还有那么多小版本呢,那就选择最新正式发布的。将鼠标滑动到图1-3-1所示页面的“Downloads”菜单时,该网站会根据用户所用操作系统,推出当前最新的可下载使用的版本,如图1-3-2所示。
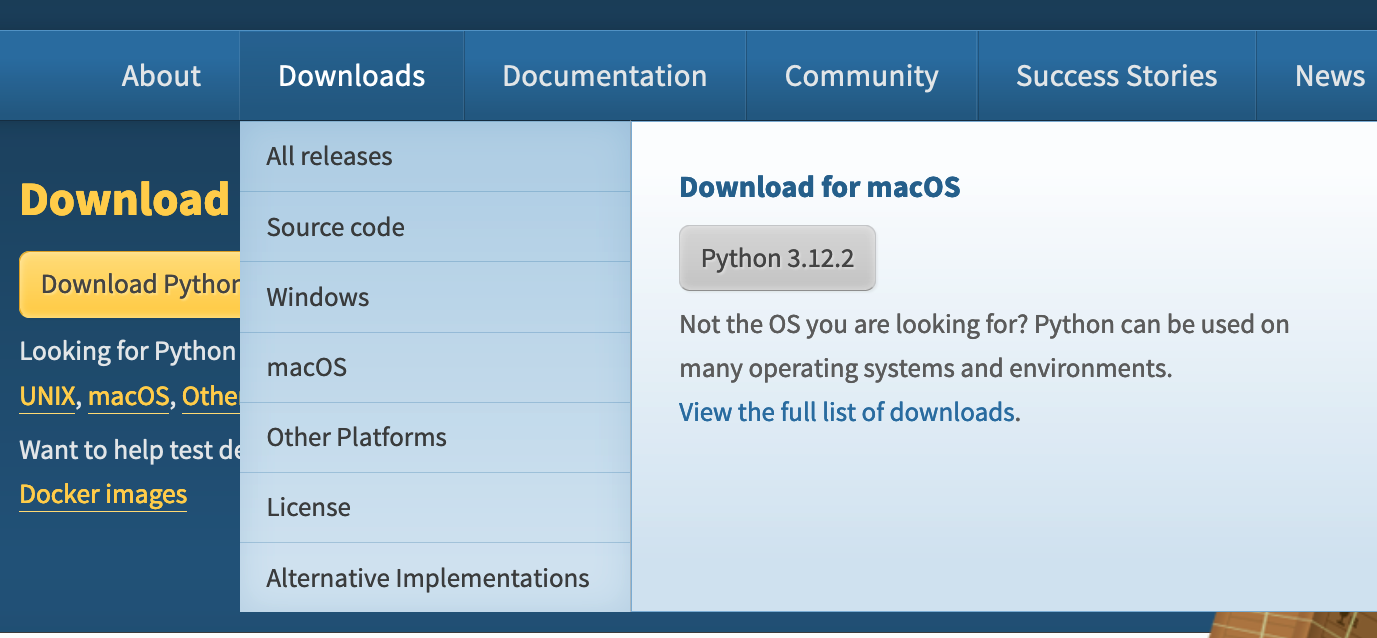
如果读者在 【LLM问答】 中提问“当前 Python 编程语言最新版本是什么”,大概率得到的结果不是图1-3-2所推荐的当前最新版本,这是由于大语言模型通常是在某一时刻之前的数据上训练的,它缺乏对最新事件或信息的了解。
本书演示所用的是 Python 3.12.2 ,如果读者使用的是其他小版本——统称为 Python 3.x.y ,也均适用于本书的学习要求。也就是说,只要在 Python 3 这个大版本范畴内,各个小版本之间的差异不很大,对于初学者而言,甚至可以忽略——不可忽略的部分,会在书中提醒。
在了解了 Python 语言的版本之后,如果读者还想了解其他与 Python 语言相关的概况信息,一方面可以在图1-3-1所示的网站上翻阅,另外也可以向【知舟问答】提问,借以快速浏览。
👉🏻👉🏻 LLM练习 👈🏻👈🏻
在【LLM问答】中提问:
请总结出 Python 编程语言在实际工作中的用途,包括但不限于软件或网站开发,也要包括其他行业。
1.3.2 安装 Python
从图1-3-2所示页面下载适用于各种操作系统的 Python 安装程序,然后按照本地计算机一般软件的安装方法,即可完成 Python 开发环境的配置。
不同的操作系统,具体的安装流程会有差异,如果在安装过程中,遇到了一些问题,建议读者利用 LLM 解决。例如,在 Windows 操作系统上,在安装好 Python 程序之后,需要配置环境变量。请读者参考一下提问,利用【LLM问答】完成不同操作系统的 Python 开发环境配置。
👉🏻👉🏻 LLM练习 👈🏻👈🏻
提问举例:
在 windows 操作系统中,已经安装完毕 Python 编程语言程序,如何为它配置环境变量?在回答中,也同时给出参考网页链接。
在安装 Python 或者配置有关环境参数的时候,可能会遇到各种问题,一方面可以通过搜索引擎解决,另外也可以向大模型提问。例如,本书作者在自己的计算机中,原本安装了 Python3.9,为了编写本书的代码示例,又安装了 Python3.12,但是如何将最新版本的 Python 作为默认版本(即执行 python 指令即可执行该版本)?就此问题向【LLM问答】提问:
👉🏻👉🏻 LLM练习 👈🏻👈🏻
macOS 系统中原来有 python3.9,现在安装了 python3.12,如何实现执行 python 指令,就运行 python3.12 ?
1.3.3 交互模式
在本地计算机上安装了 Python 之后,可以打开命令行界面(如图1-3-3所示),输入 python 并按回车键,显示图1-3-3所示效果,即说明本地的 Python 环境已经配置完成。

在图1-3-3中的符号 >>> 后面输入 Python 代码,如图1-3-4中所示输入 print(‘hello world’) 。输入一行代码之后,按回车键,即得到反馈(如图1-3-4所示)。像这样的操作模式称为 Python 的交互模式。
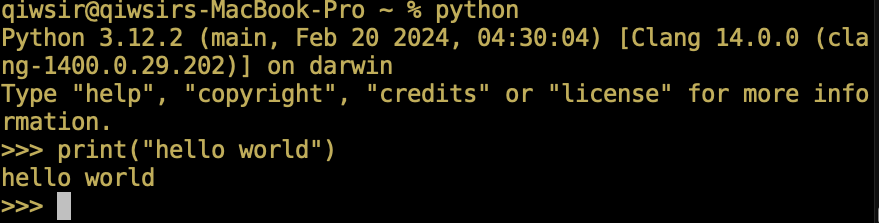
若从交互模式退回到命令行状态,可以输入 exit() 函数,如图1-3-5所示——请注意区分两种状态:命令行和交互模式。
1.4 IDE 和 AI 插件
所谓 IDE ,全称是 Integrated Development Environment ,或者 Integration Design Environment、Integration Debugging Environment ,中文翻译为“集成开发环境”。一般来讲,它跟编程语言无关。
一款适合的 IDE 能够提升开发者的生产力,将开发工作的各个环节密切地整合起来,例如编辑代码同时检查语法错误、代码自动补全;将源码管理工具(比如 Git )融入到 IDE 等。
不同的开发者有不同的偏好,不同的项目有不同的需要,因此,一般而言没有哪一个 IDE 能够“一统江湖”,尽管有的 IDE 号称“普遍适用于”各种场景,也只能是在某个领域或者文化范围中的应用比例相对较高罢了。
1.4.1 安装 VS Code
在本书中,使用一款名为 Visual Studio Code(简称:VS Code )的 IDE,它是微软出品的免费代码编辑器,默认支持 JavaScript、TypeScript、CSS 和 HTML,通过下载扩展插件支持 Python、C/C++、Java 等多种编程语言,还具有语法高亮、代码自动补全、代码折叠等常用功能。
VS Code 的官方网站是:https://code.visualstudio.com/ ,可以根据自己的操作系统下载相应安装程序,图1-4-1所示的是其编辑界面。
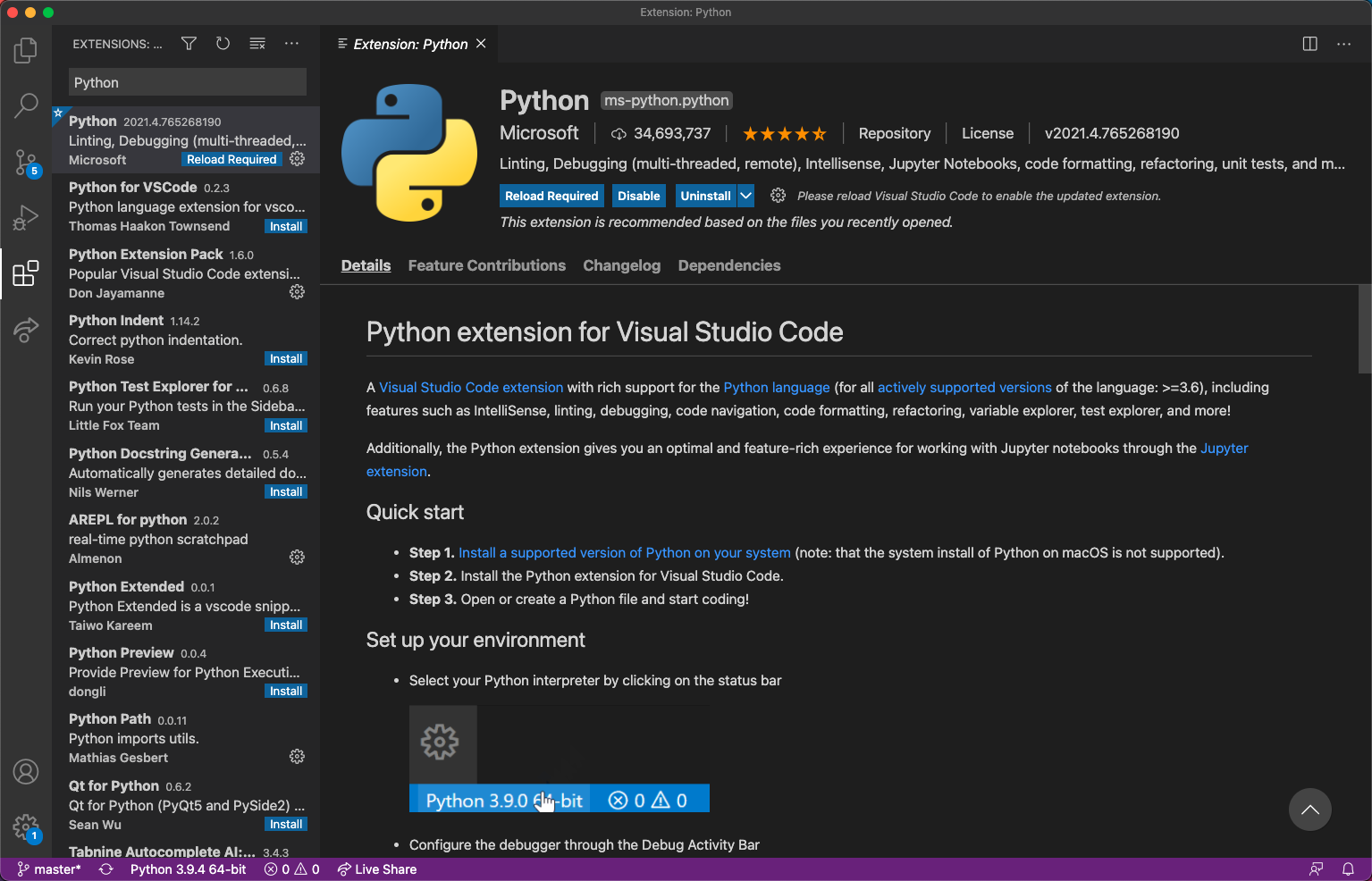
VS Code 的诱人之处在于任何人都可以开发扩展,并且背靠微软的大树,颇受开发者欢迎(2019年 Stack Overflow 调查显示,在87317的受访者中有50.7%的声称正在使用 VS Code ),安装了 VS Code 之后,可以在 https://marketplace.visualstudio.com/VSCode 查看所需扩展,或者在 VS Code 内部进行搜索,如图1-4-2所示,确认本地计算机已经连接到国际互联网,根据需要,点击“ Install ”按钮即可安装该项。
1.4.2 编写程序文件
在 VS Code 中创建一个文件,将其命名为 hello.py ,这是一个 Python 程序文件。特别提醒:文件名用数字,如1.py,不是好习惯。如图1-4-3所示,用 VS Code 创建了此文件。
然后在文件中输入如下内容:
print("Hello World")
其效果如图1-4-4所示,并保存此文件。
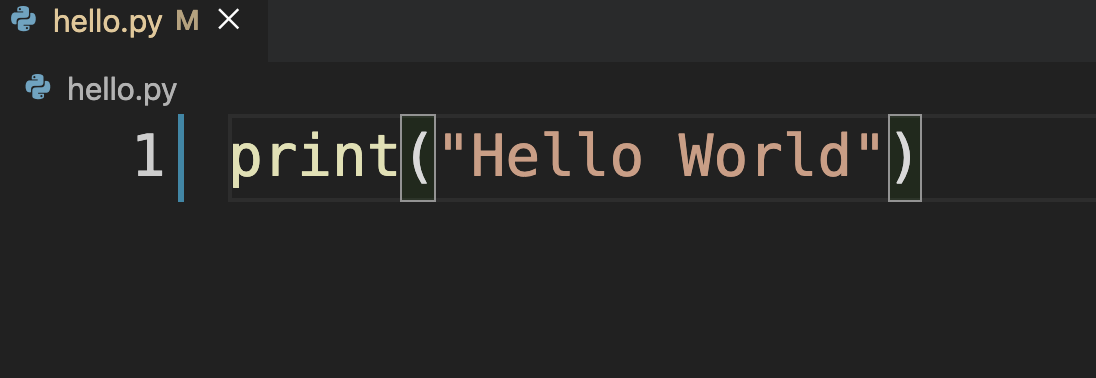
如此即编写好了一个 Python 程序的文件,下面就要让此程序运行起来。以下两种运行或调试程序的方法,读者可任选。
方法 1:利用 IDE 调试
如图1-4-4所示,点击 VS Code 的菜单项中的“ Run (运行)”,在下拉菜单选项中点击“ Start Debugging(启动调试) ”。
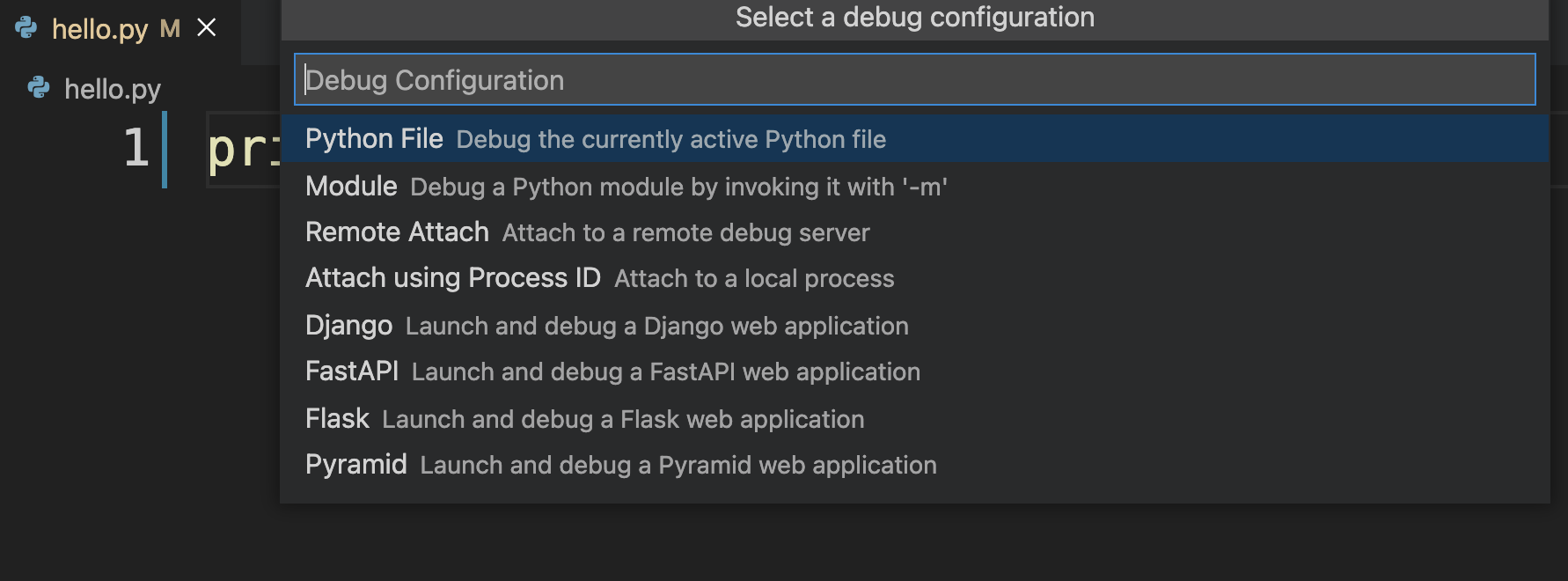
随即可以看到图1-4-6所示窗口,此处应该选择“ Python File ”项。
之后就会自动运行 hello.py 文件,其效果如图1-4-7所示,并在 VS Code 的 TERMINAL(终端)显示运行结果——打印出了“ Hello World ”字样。
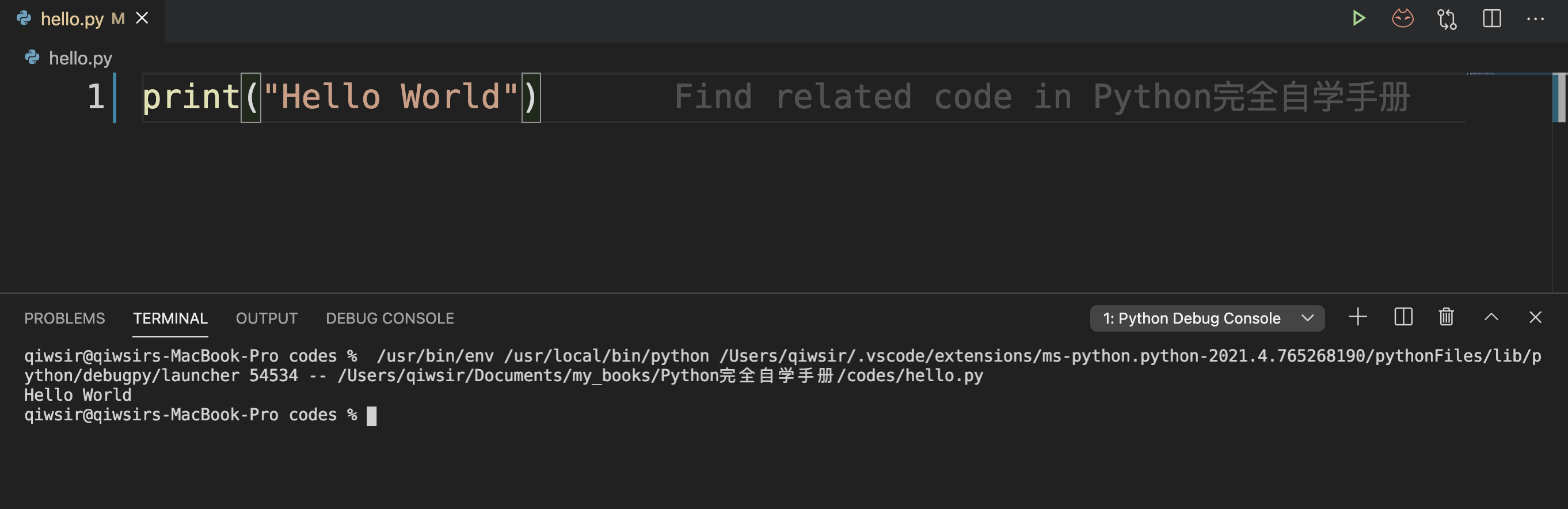
如果读者使用的是其他 IDE,也有类似的操作,甚至于执行调试命令的快捷键(F5)都是一样的。
方法 2:利用命令行运行
进入到命令行状态——注意不是交互模式,然后进入到保存 hello.py 文件的目录(如果不进入该目录,应在文件名之前写明路径),如图1-4-8所示(提示:图示中的命令ls不是 Windows 的指令,请知悉)。
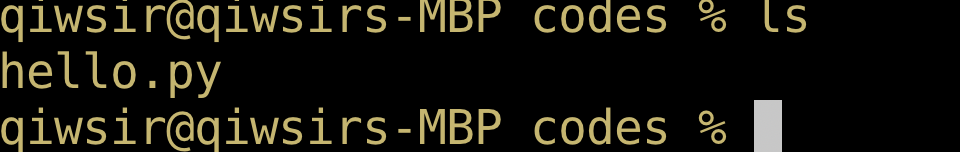
在图1-4-8所示状态,输入如下指令:
python hello.py
即可运行 hello.py 文件,其效果如图1-4-9所示,显示了运行效果——打印出“Hello World”字样。
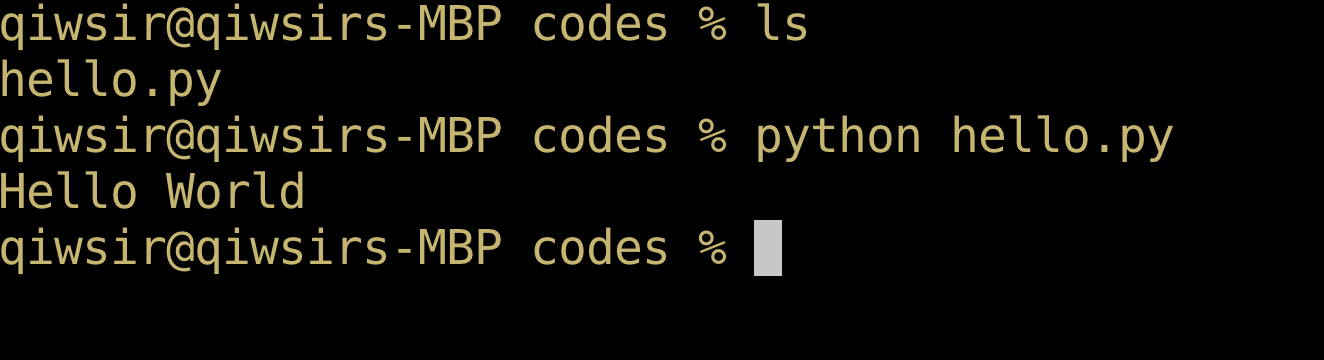
1.4.5 解释器
上面所编写的 hello.py 和 hello_llm.py 程序,是用 Python 编程语言编写的,这是一种高级语言,计算机不能直接“认识”,它能直接“认识”的是机器语言,为此要将高级编程语言“翻译”为机器语言。对于 Python 程序而言,用于“翻译”的叫做 Python 解释器( Interpreter )。目前常见的 Python 解释器包括:CPython、JPython、IPython、PyPy、IronPython 五个版本。当读者按照 1.3.2 节所述,在本地计算机配置好了 Python 开发环境之后,就已经将最常用的一个解释器 CPython 安装好了。CPython 是使用 C 语言开发的 Python 解释器,也是标准的 Python 解释器,是使用最广泛的 Python 解释器。
解释器执行程序的方法有三种:
- 直接执行程序;
- 将高级语言编写的程序转化为字节码( Bytecode ),并执行字节码;
- 用解释器包含的编译器对程序进行编译,并执行编译后的程序。
Python 语言的解释器采用的是第 2 种方法,如 1.4.3 节所编写的 hello.py 文件,当执行 python hello.py 后,Python 解释器都会将源代码(用高级编程语言所编写的程序)转化为字节码,生成扩展名为.pyc的文件,此即为字节码文件,然后解释器执行字节码。
但是,如果按照图 1-4-9 的方式执行了该 Python 程序之后,并没有在当前目录中看到 .pyc 类型的字节码文件。这是因为用 python hello.py 的方式运行此程序,.pyc 文件运行之后并没有保存在硬盘中。为了能直观感受到字节码文件的存在,下面换一种执行程序的方式。
qiwsir@qiwsirs-MBP codes % python -m py_compile hello.py
此指令的作用就是要生成 hello.py 对应的 .pyc 文件,并保存到硬盘中。
qiwsir@qiwsirs-MBP codes % ls
__pycache__ hello.py hello_llm.py
比之前多了一个目录__pycache__,进入到此目录中。
qiwsir@qiwsirs-MBP codes % cd __pycache__
qiwsir@qiwsirs-MBP __pycache__ % ls
hello.cpython-312.pyc
这里有一个 hello.cpython-312.pyc 文件,就是前面所说的由 Python 解释器生成的字节码文件。
qiwsir@qiwsirs-MBP __pycache__ % python hello.cpython-312.pyc
Hello World
执行这个字节码文件,打印出了“ Hello World ”字样,与图 1-4-12 的运行效果相同。
下面做一个有意思的探索。如果在 hello.py 文件中增加一行,其完整代码是:
print("Hello World")
print("Life is short. You need Python.")
保存文件后执行python hello.py,会打印出什么?
qiwsir@qiwsirs-MacBook-Pro codes % python hello.py
Hello World
Life is short. You need Python.
此结果当然不会出乎意料。
再执行那个.pyc文件,会是什么结果?
qiwsir@qiwsirs-MBP __pycache__ % python hello.cpython-312.pyc
Hello World
还是老样子。为什么?
虽然刚才修改了 hello.py 文件,执行 python hello.py 的时候,肯定会生成新的 .pyc 文件,但是该文件并没有保存在硬盘中,现在所看到的 hello.cpython-312.pyc 还是原来的 hello.py 所对应的字节码文件,故执行结果仍同以往。
再走一遍前面的流程,生成新的 .pyc 文件并保存,就会看到期望的结果了。
qiwsir@qiwsirs-MBP codes % python -m py_compile hello.py
qiwsir@qiwsirs-MBP codes % cd __pycache__
qiwsir@qiwsirs-MBP __pycache__ % ls
hello.cpython-312.pyc
qiwsir@qiwsirs-MBP __pycache__ % python hello.cpython-312.pyc
Hello World
Life is short. You need Python.
Python 解释器执行字节码文件的速度要快于执行源代码文件,因此有的时候会发布 .pyc 文件——当然,如果源代码修改了,还需要重新发布。例如将 hello.cpython-312.pyc 文件移动到上一级目录,并更名为fasthello.pyc (下面在命令行中使用的 mv 命令,不能用于 Windows 系统中)。
qiwsir@qiwsirs-MBP __pycache__ % mv ./hello.cpython-312.pyc ../fasthello.pyc
qiwsir@qiwsirs-MBP __pycache__ % cd ..
qiwsir@qiwsirs-MBP codes % ls
__pycache__ fasthello.pyc hello.py hello_llm.py
然后执行它:
qiwsir@qiwsirs-MBP codes % python fasthello.pyc
Hello World
Life is short. You need Python.
觉察到 python fasthello.pyc 的运行速度快于执行 python hello.py 了吗?如果能觉察到,不用阅读本书了——你就是超人。
1.5 注释
注释是程序的重要组成部分,良好的注释有助于增强程序的可读性、可维护性。注释是“给人看的”,所以,一定要用自然语言编写(至于用哪种自然语言,要根据项目的统一规定和人员的组成状况而定)。
以 1.4.3 节所创建的 hello.py 文件为例,在其中增加如下所示的内容:
print("Hello World") # print a string.
print("Life is short. You need Python.") # 打印一行英文字符。
所增加的内容就是注释,其中:
- # 是英文状态下输入的注释开始符号,表示此符号之后的内容都是注释,直到本行结束。
“print a tring”和“打印一行英文字符。”是注释的具体内容,此内容与 # 符号之间的空格不是强制的,有此空格更便于阅读。
如此形式的注释,也称为“行注释”——从注释符号开始到本行结束,都是注释。
在上面的示例中,一行注释使用的是英文,另一行是中文。然后调试上述代码,正常地显示了打印的结果(如图1-5-1所示),这说明 Python 解释器在执行此程序的时候,并没有受到所增加的注释影响——注释是给人看的,“机器不看”。

可能有的读者在调试上述代码的时候报错,比如类似下面的错误提示:
SyntaxError: Non-UTF-8 code starting with '\xb4' in file /Users/qiwsir/codes/hello.py on line 2, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
这是字符编码所致,如果删除了程序中的中文注释,就会消除此错误——这是方法之一。由报错信息可知,此问题是所用 IDE 编码类型导致的。不论读者使用哪一款 IDE 软件,通常都应当将其编码设置为 UTF-8 (参见第3章3.1节)。图1-5-2所示是 VS Code 中显示的编码配置。所以,将 IDE 编码设置为 UTF-8 也是一种解决方法。
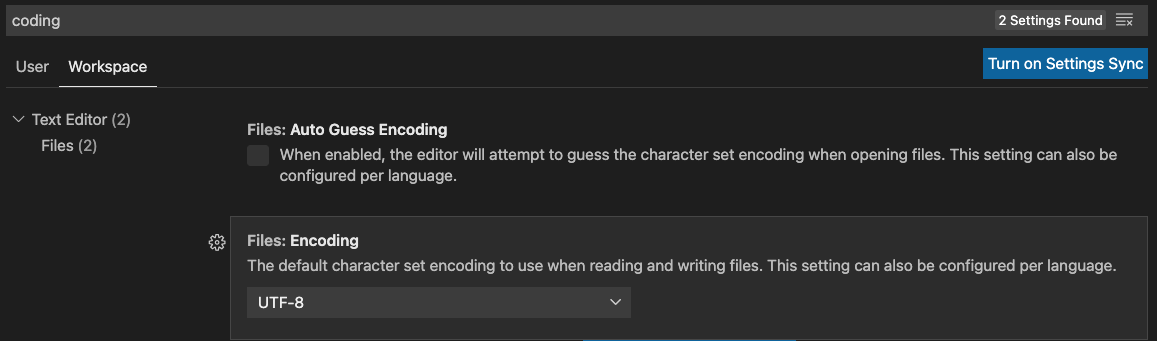
还有一个方法,就是在文件的顶部声明使用 UTF-8 编码。
#coding:utf-8
print("Hello World") # print a string.
print("Life is short. You need Python.") # 打印一行英文字符。
新增 #coding:utf-8 之后,调试此程序,就不再报错了。除了如上所示的写法之外,读者在其他资料中还会看到 # -*- coding:utf-8 -*- 和 #coding=utf-8 ,都是声明本文件使用 UTF-8 编码,如此即可在文件中使用中文等非英文字符。
符号 # 发起的注释,可以如前面那样,在某行代码之后,用于注释该行;也可以单独占据一行,多用于说明下面若干行代码的含义,如:
# This is my first Python program.
print("Hello World")
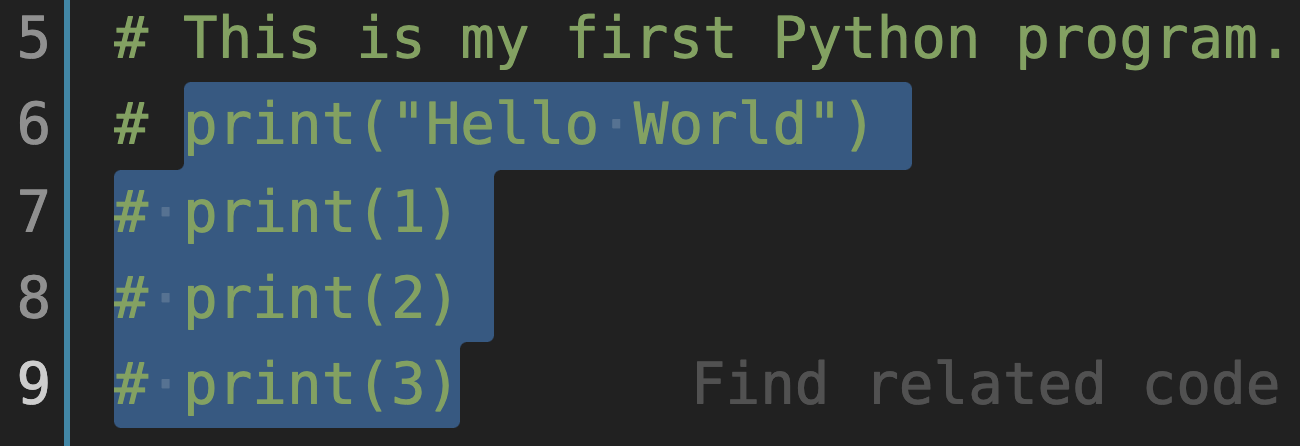
另外,在调试程序的时候,有可能要暂时不让计算机“看到”某些代码,也可以在该行代码前面加上 # ,将其暂时转换为注释,等需要的时候再转换回来。例如将 hello.py 文件中的代码修改为:
#coding:utf-8
print("Hello World") # print a string.
# print("Life is short. You need Python.")
此时调试该程序,则会只打印“ Hello World ”字样。
常用的 IDE 提供了实现多行“注释”以及取消的快捷操作。以 VS Code 为例,如图1-5-3所示,将第6、7、8、9三行代码选中之后,使用快捷键组合“ COMMAND + / ”(或“ CTRL + / ”),即可将选中的多行“注释”了(此处的“注释”是动词,或者说是“名词用作动词”,意思是“将多行代码变成了注释”。如图1-5-4所示)。这个组合键可以实现“注释”和“取消注释”的切换,即选中多个已注释的行之后,通过此组合键可以取消注释。
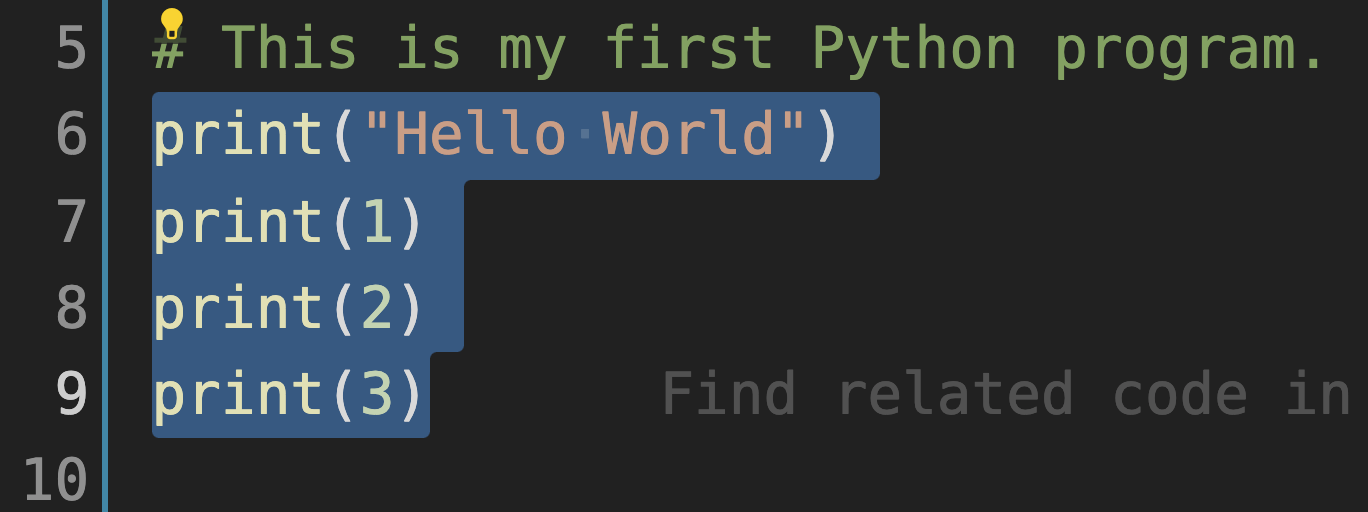
除了 # 发起的是单行注释之外,还有多行注释。如下代码所示,使用三对英文的双引号或者单引号,能够实现多行注释,下面的代码依然是在 hello.py 中编辑,在三对双引号内输入了多行注释内容。
#coding:utf-8
"""
This is my first Python program.
I like it.
I am learning it myself.
"""
print("Hello World") # print a string.
# print("Life is short. You need Python.")
这种注释是针对文件的,常称为“模块注释”(一个 .py文件,可以看做一个模块,关于模块的内容,参阅第10章10.1节)。
虽然代码的注释能够增强可读性,而且操作上简单易行,但是,对注释的争论向来没有消停,比如有的人说“好代码”不需要写注释(其本意是通过代码中变量、函数、类等命名以及恰当的代码组织实现高可读性),更多的争论则围绕着什么时候写注释、注释的内容是什么等展开。尽管很多所争论的话题没有标准答案,但是在开发实践中,也逐渐达成了一些经验性共识,比如:
- 注释内容不要重复代码。下面的注释就不提倡。
print('Hello World') # print hello world
- 不要用注释替代丑陋的变量命名。例如打算创建一个表示笔者已经出版的图书的列表(列表,是 Python 的一类内置对象,参阅第4章4.3节),如果用下面的方式:
# a list of books
a = ["机器学习数学基础", "数据准备和特征工程"]
虽然用注释的方式说明变量 a 的含义(关于变量,请参阅1.6节),但此注释实则是丑陋代码的遮羞布,丝毫无法改变所命名变量致使程序的可读性降低的本质。如果改为:
books = ["机器学习数学基础", "数据准备和特征工程"]
即使不用注释,代码的含义也一目了然。故首要的是写“好代码”,注释是对代码的辅助,而不要用注释替代晦涩的代码。
- 注释的用语简单明了,表达准确,且讲究文明礼貌。这是对开发者表达能力的基本要求。
“注释除了给人看”之外,还能够让 CodeGeeX 根据注释中的描述自动生成代码,例如在 1.4.4 节的 hello_llm.py 中所自动生成的代码,就是根据该文件第一行的注释生成的。
1.6 变量
如果本书是读者所阅读的第一本编程语言的书籍,则倍感荣幸。下面就以此类读者为对象,介绍 Python 中的变量( Variable )。
1.6.1 Python 语言中的变量
进入到本地计算机的 Python 交互模式中,按照如下方式输入:
>>> x = 3.14 # (1)
>>> x # (2)
3.14 # (3)
注释(1)和(2)是输入的内容(其中 # (1) 和 # (2) 不必输入,本书中用这种方式标记相应的行,即“注释(1)”是指注释(1)所标记的一个代码逻辑行 x = 3.14 )。
输入注释(1)之后,敲回车键,进入下一个命令行,再输入注释(2),敲回车键,返回了注释(3)所示的值(称为“返回值”)。同样方法,还可以令 x “等于”其他数,也均可以用注释(2)得到该数字。
这里的 x 就是 Python 中的变量。注意区分此变量与数学中的变量之间的区别。
在数学中,变量用来表示一个数( x = 3 x=3 x=3 的含义是当前变量 x x x 是整数 3 3 3 ), x + 1 x+1 x+1 的意思是 x x x 所表示那个数与另外一个整数 1 1 1 求和(即为 4 4 4 ),如果比较 x x x 和 x + 1 x + 1 x+1 ,显然不相等(即 3 ≠ 4 3\ne 4 3=4 )。
而在 Python 中,变量 x 引用了一个数字,注意这个词语:“引用”。此处需要发挥个人的想象力,形象地理解“引用”的含义。以上述代码中的注释(1)为例,如果将 3.14 看做为一个东西(严格术语是“对象”,请参阅第 7 章7.1节。“东西”是一种通俗的说法,但不严谨,只适用于此处的初步理解),而变量就是一枚标签,注释(1)的作用效果就是将这枚标签贴到 3.14 这个东西上。注释(2)的作用就是通过这枚标签,找到它对应的东西,即得到了返回值。
接续上述代码,继续执行如下操作:
>>> x + 2.1
5.24
如前所述,变量 x 引用了 3.14 ,那么 x + 2.1 就实现了 3.14 和 2.1 的求和,返回值是 5.24——注意,在上述操作中,如果用其他数字与 x 相加,得到了莫名其妙的结果,暂时不用理会,后面会详解(参阅第2章2.4.1节)。
那么,这时候变量 x 是否还在引用 3.14 呢?从逻辑上看,没有对它做任何操作——将标签贴在了那个东西上,并没有对它执行“摘下来”的动作——应该维持原样。
>>> x
3.14
果真如此。
继续下述操作,并尝试用“ Python 中的变量与对象之间是引用关系”这一认识解释操作结果。
>>> x = 3 # (4)
>>> x + 1 # (5)
4
>>> x # (6)
3
注释(4)表示变量 x 引用了 3 ;注释(5)完成的实则是 3 + 1 ;执行注释(6),返回的是 3 ,而不是前面的 3.14 。
如果在交互模式中输入 x = x + 1 会是什么结果?从数学角度看,这个式子是不成立的,然而在 Python 中,会看到别样风景。
>>> x = x + 1 # (7)
>>> x # (8)
4
注释(7)是接续前面的注释(6)进行的操作,先看注释(8)返回的结果,变量 x 引用的东西不再是注释(6)中的 3 ,而是 4 ,这个变化是怎么发生的?应用“ Python 中的变量与对象之间是引用关系”的认识,结合图1-6-1来理解注释(7)的奥妙之处:
- 计算
x + 1,它的返回值是4,如图1-6-1中的①所示; - 变量
x引用上面计算结果,如图1-6-1中的②所示,相当于执行x = 4; - 所以,注释(8)的执行结果是
4。
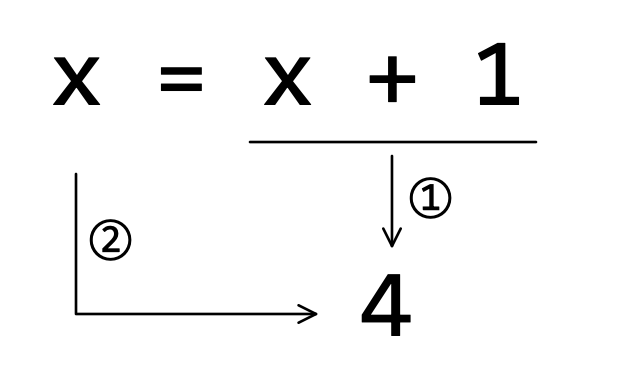
Python 的变量除了可以引用数字之外,还可以引用其他任何 Python 对象,读者会随着本书的学习不断深入理解这句话的含义。
特别注意,Python 中的变量不能脱离所引用的对象(即前面所说的“东西”)而单独存在,比如创建一个变量 y ,试图以备后用,就会爆出 NameError 异常(关于异常,参阅第9章)。
>>> y
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'y' is not defined
这是 Python 中变量的一个特点。
本节中特别强调的一个认识是“ Python 中的变量与对象之间是引用关系”,在牢固地树立了此观念之后,行文表述中可能会用一些比较简略的说法,比如注释(8)中,变量 x 引用了整数 4 ,简化为“ x 变量的值是 4 ”,或者用 x 指代所引用的对象等。
1.6.2 变量命名
如果在 Python 语言中套用数学中变量的命名规则,就会出现诸如 a = ["机器学习数学基础", "用大模型学Python", "数据准备和特征工程"] 这样可读性很差的“丑陋的变量名称”。在 Python 语言中——所有高级编程语言都如此,习惯于用意义明确的英文单词或者单词组合来命名变量,这样做的好处是可读性强——通过名称可知道其含义,胜过任何注释;坏处是拼写的字母多一些,但与可读性相比,多敲击几次键盘是值得的。
如果使用多个单词,这些单词如何连接也是一个问题,比如:
mywebsite = "https://lqlab.readthedocs.io/"
这里的变量 mywebsite 虽然符合上述的命名建议,但可读性并没有增强,或者说不太“增强”。从自然语言的角度来说,“my website”的可读性才强呢,但是 Python 不允许在变量中有空格:
>>> my website = "https://lqlab.readthedocs.io/"
File "<stdin>", line 1
my website = "https://lqlab.readthedocs.io/"
^
SyntaxError: invalid syntax
为了既要使用多个单词,又要有可读性,还不引入歧义,在编程语言中(包括 Python)通常有如下推荐命名形式(注意,是推荐,而非强制):
- 驼峰式( Camel Case ):第一个单词首字母小写,第二个及其后的每个单词的首字母大写,其余字母均为小写,例如:
myWebsite、firstUniveristyName。 - 帕斯卡式( Pascal Case ):每个单词首字母大写,其余字母小写,例如:
MyWebsite、FirstUniversityName。这种命名形式又称为“大驼峰式”,对应着上面的“驼峰式”则称为“小驼峰式”。 - 蛇形式( Snake Case ):每个单词的字母均为小写,单词之间用一个下划线
_连接(注意,是英文输入法下的下划线,在英文状态下,按住“ shift ”键,再按“ - ”键),例如:my_website、first_unviersity_name。 - 烤串式( Kebab Case ):每个单词的字母均为小写,单词之间用一个减号
-连接(注意,是英文输入法下的减号),例如:my-website、first-university-name。
以上常见的四种变量命名形式,不同的开发团队会根据自己的喜好选择,开发者应该服从团队的规定——内部统一。在本书中,选择使用“蛇形式”,这也是 Python 中比较流行的命名普通变量的形式( Python,即“蟒蛇”,图1-6-2为其图标)。

了解了变量的命名形式之后,其名称必须符合如下要求:
- 变量名称不以数字开头;
- 变量名称中可以包含英文字母(大写和小写)、数字以及下划线
_。不允许有其他英文状态下的字符,如“+、-、#、!、@”等,也不能有空格。 - 一般不使用单个的
l(字母L的小写)、O(字母o的大写)、I(字母i的大写)作为变量名称,这也是为了提高可读性,避免误解。 - 一般不用内置的 Python 函数来命名,这样会导致以后调用该函数的时候无法使用(关于内置函数,参阅第2章2.2.1节)。
- 变量名称的长度可以任意,但不宜太长。
- 不使用 Python 关键词命名。在交互模式,执行下述操作,查看关键词(或称“保留字”)。
>>> import keyword
>>> print(keyword.kwlist)
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
下表列出若干个变量名称,读者可以自行在交互模式里测试,如此命名会出现什么结果。
| 变量名称 | 正确与否 | 说明 |
|---|---|---|
1abc | 错误 | 不能用数字开头 |
__book__ | 正确 | 允许以下划线开头 |
__book&code__ | 错误 | 不能含有&符号 |
int | 错误 | 不能用 Python 内置对象类型命名 |
class | 错误 | 不能用 Python 关键词 |
按照以上的要求和建议,是不是就能命名出非常“好”的变量了呢?非也。以上仅仅是形式上和对个别字符、词语的规定,具体到一个变量怎么“取名字”,还要靠个人或者团队的其他规定,比如颇受一部分开发者推崇的“匈牙利命名法”,就规定了一些命名规则(开发者对“匈牙利命名法”并没有完全达成共识,仁者见仁智者见智,此处不单独对此进行介绍)。
前面所讨论的是 Python 中的普通变量,后续还会遇到其他变量,比如全局变量,其命名形式会有所差别,主要是为了突出它不是普通变量。命名的问题不仅仅局限于变量,还有函数、类、模块等,这些内容在本书后续章节中会逐步介绍。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











