







-
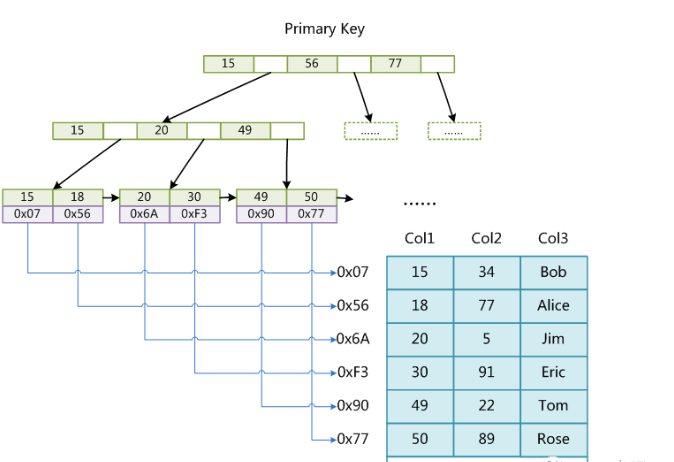
b+ 树.三层

假设一行数据的大小是 1k,那么一个页可以存放 16 行这样的数据。
我们假设主键 ID 为 bigint 类型,长度为 8 字节,而指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即 16384/14=1170。
那么可以算出一棵高度为 2 的 B+ 树,能存放 1170*16=18720 条这样的数据记录。
根据同样的原理我们可以算出一个高度为 3 的 B+ 树可以存放: 1170*1170* 16=21902400 条这样的记录。
上图就是3层.2层索引,,一层叶子,放数据 , 其实就是一个1170叉树(比二叉树多叉叉)
region 表只有 5 行数据,当然他的 B+ 树高度为 1。 表的高度随数据量大小变动的
-
为什么垂直分表
第一是由于数据量本身大,需要更长的读取时间
第二是跨页,页是数据库存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页内存储行数少,因此IO效率较低
第三,数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能
3.如果表中一行的数据长度超过了16k
innodb的页块中,但如果表中一行的数据长度超过了16k,这时候就会出现行溢出,溢出的行是存放在另外的地方,存放该溢出数据的页叫uncompresse blob page。
innodb采用聚簇索引的方式把数据存放起来,即B+TREE结构,因此每个页块中至少有两行数据,否则就失去了B+TREE的意义(每一个页中只有一条数据,整个树就退化成为了一条双向链表),这样就得出了一行数据的最大长度就限制为了8k。
表字段定义过多,会导致一行记录变长,有下面三点弊端:
1. 记录太长,会导致一行跨多块的情况,存储效率较差。
2. 记录太长,容易导致表太大,全表扫描时,查询效率较差。
3. 如果经常只查询几个字段的话,数据读取量并不会减少,数据查询效率较差。
4.聚簇索引
非聚簇索引的叶子结点存储的是索引列的值,它的数据域是聚簇索引即ID,聚簇索引叶子结点存储的是对应的数据。聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一且非空的索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键(类似oracle中的RowId)来作为聚簇索引。如果已经设置了主键为聚簇索引又希望再单独设置聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。
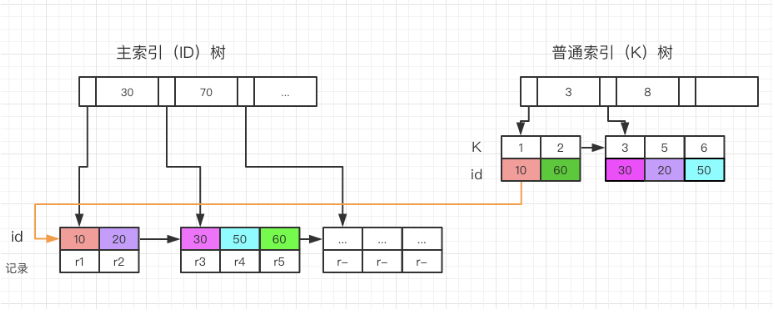
非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
<1>每个表都有且只有一个聚簇索引
<2> 聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一且非空的索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键(类似oracle中的RowId)来作为聚簇索引。如果已经设置了主键为聚簇索引又希望再单独设置聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。
<3> 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
5.对于MyISAM
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
6. mysql 配置
-
innodb_buffer_pool_size:
<0>InnoDB使用缓冲池来缓存索引和行数据。设置的值越大,访问表中数据所需的磁盘I/O就越少。在专用数据库服务器上,您可以将此参数设置为机器物理内存大小的80%。不过,不要将其设置得太大,因为物理内存的竞争可能会导致操作系统中的分页。请注意,在32位系统上,每个进程的用户级内存可能限制为2-3.5G,因此不要将其设置得太高。
<1>增加查询缓存的大小,以便加快查询速度。可以通过将query_cache_size设置为20M- 80M来提升MySQL的性能。
<2>可以调整innodb_log_file_size参数,此参数可以控制当系统重新启动时InnoDB日志文件的大小,以减少日志写入的I/O消耗,提高系统性能。
<3> 调整MySQL线程连接的最大值,以减小延时。可以通过设置max_connections参数,将MySQL的最大连接数设置为200或以下,以降低系统负荷,提升响应时间。
<4> max_allowed_packet 参数需要调大至64M ,否则会出现数据保存失败;
7.varchar 和text对比
-
varchar最大行宽限制,也就是 65535(64k) 字节, 使用 utf-8 字符编码集 varchar 最大长度是 (65535-2)/3 = 21844 个字符 (小于255 是占用1个字节的长度,,大于占用2个)
text最大限制也是64k,utf8也是21844个字符, 但是是溢出存储,但原则上不会全部overflow , 会有768字节和原始的行存储在一块,多于768的行会存在和行相同的Page或是其它Page上 (text 占用2个字节标记长度, tinytext 占用1个字节标记长度)
总结:
根据存储的实现: 可以考虑用varchar替代 text,因为 varchar 存储更弹性,存储数据少的话性能更高。
如果需要非空的默认值,就必须使用varchar
如果存储的数据大于64K,就必须使用到mediumtext , longtext
varchar(255+)和text在存储机制是一样的
需要特别注意varchar(255)不只是255byte ,实质上有可能占用的更多
特别注意,varchar大字段一样的会降低性能,所以在设计中还是一个原则大字段要拆出去,主表还是要尽量的瘦小















 2270
2270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









