







 本文介绍了如何使用Python爬虫从前程无忧(51job)网站上抓取数据挖掘类岗位的招聘信息。首先解析了网络爬虫的基本概念,然后分析了51job搜索页面的URL结构,通过编码转换获取正确的搜索链接。接着,探讨了自动翻页和获取详细页面的方法,并利用页面查看器定位到所需信息。最后,展示了初步的爬取结果,并指出需要进一步处理数据。
本文介绍了如何使用Python爬虫从前程无忧(51job)网站上抓取数据挖掘类岗位的招聘信息。首先解析了网络爬虫的基本概念,然后分析了51job搜索页面的URL结构,通过编码转换获取正确的搜索链接。接着,探讨了自动翻页和获取详细页面的方法,并利用页面查看器定位到所需信息。最后,展示了初步的爬取结果,并指出需要进一步处理数据。
开始之前先了解一下什么是网络爬虫,百度百科对于网络爬虫的解释是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。也就是相当于我做一个机器人,我让它上网帮我找大量的资料。我要告诉他我想要什么数据,怎么找,是从一个网站找,还是好多网站一起找,数据中要包含什么属性,以上就是我们所讲的爬取策略。这其中要学习一些网络结构的内容,请读者自行参阅HTML的相关文献,非常简单。大部分网站的爬取流程如下:
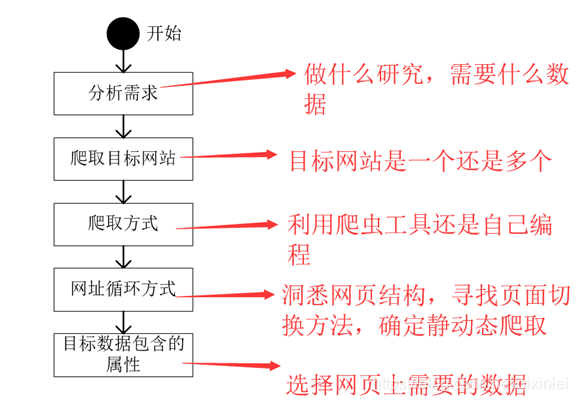
好!明确了爬取流程,我们下边以数据挖掘类就业岗位为例,爬取51job上的相关招聘信息。
首先分析需求:希望获得数据挖掘就业岗位的就业信息;
其次确定目标网站:前程无忧;
爬取方式:用Python自己编;
对于网址循环方式,我们要根据网站的结构来确定。
打开前程无忧搜索网站,如下图所示输入数据挖掘的检索内容,点击搜索。
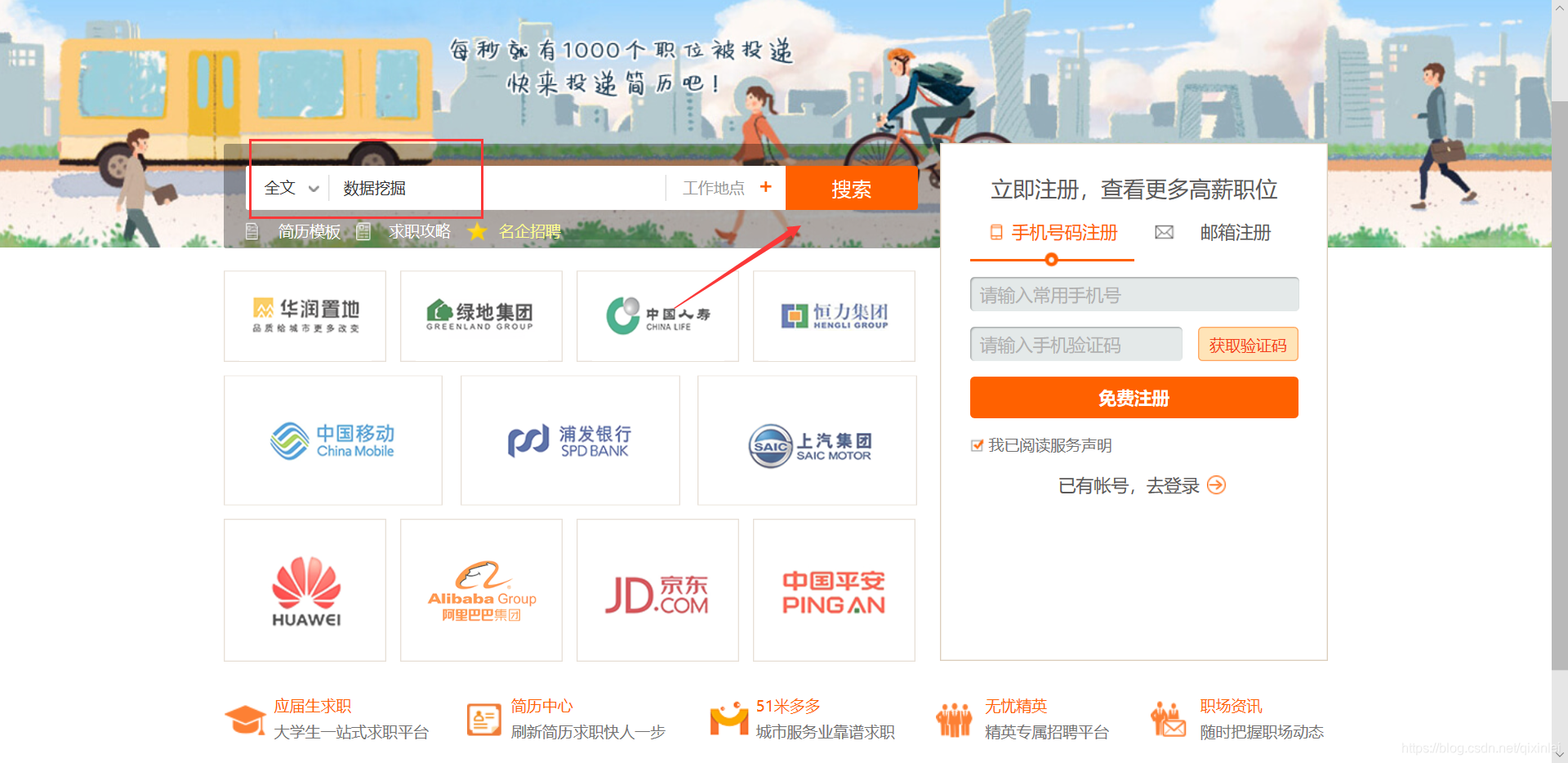
搜索结果页面如下,图中红圈处是我们输入的检索词,红框是页面的网址,让我们看看页面的网址是什么吧。
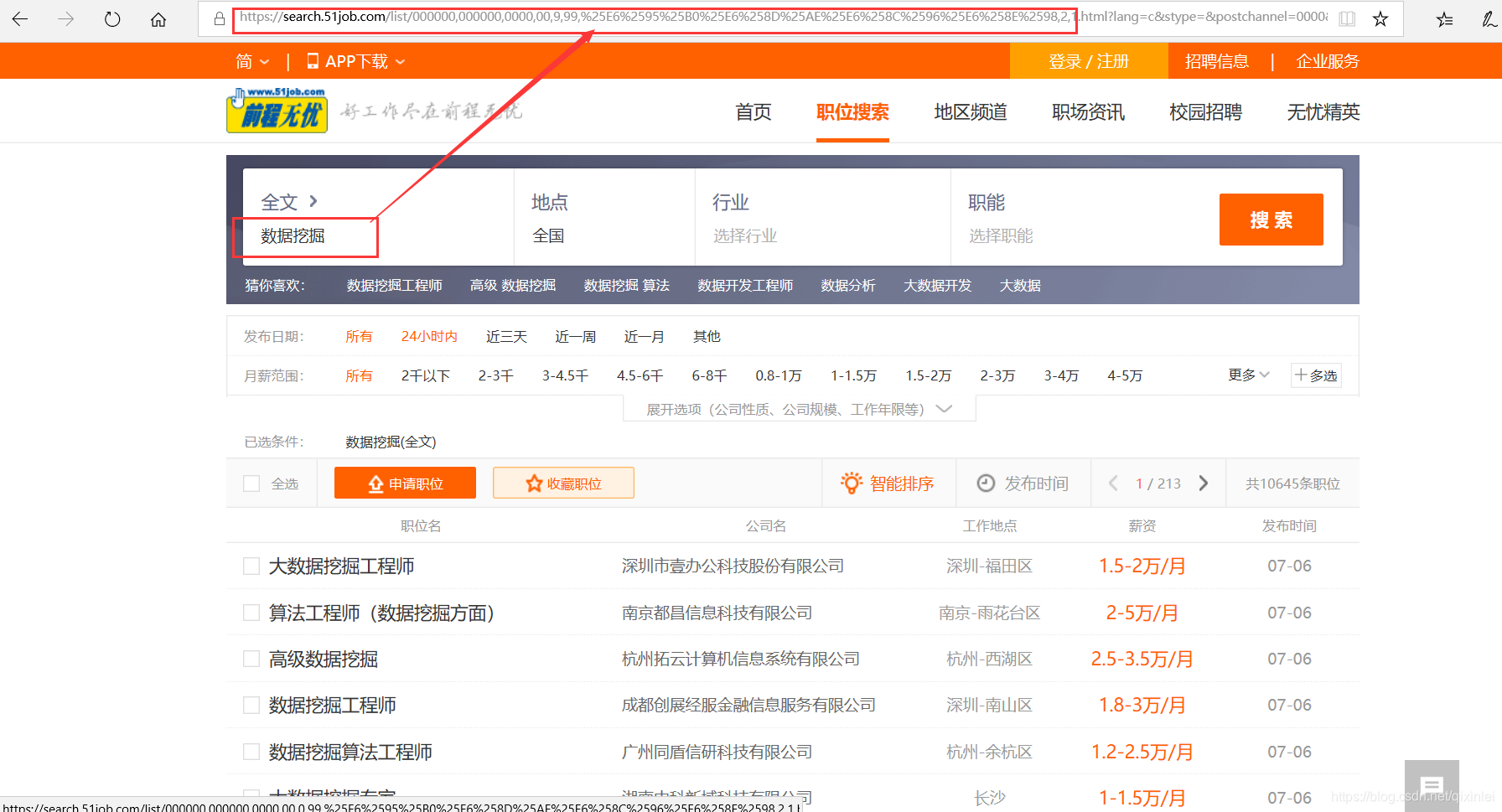
网站界面网址
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3010
3010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









