







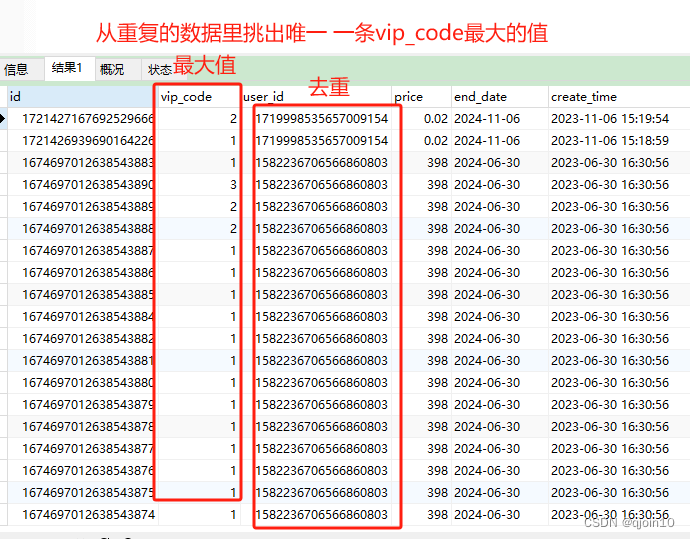
要求:这里要求从重复的user_id里筛选出vip_code最大的唯一 一条数据 , 如下图
SQL代码:
SELECT
b.id,b.vip_code,b.user_id,b.price,b.end_date,b.create_time,
(SELECT reimburse_award FROM t_vip_card WHERE id = b.vip_card_id) AS reimburseAward
FROM t_vip_card_buy_records AS b
JOIN (
SELECT max(vip_code) AS vip_code, user_id
FROM t_vip_card_buy_records GROUP BY user_id
) AS a ON b.vip_code = a.vip_code AND b.user_id = a.user_id
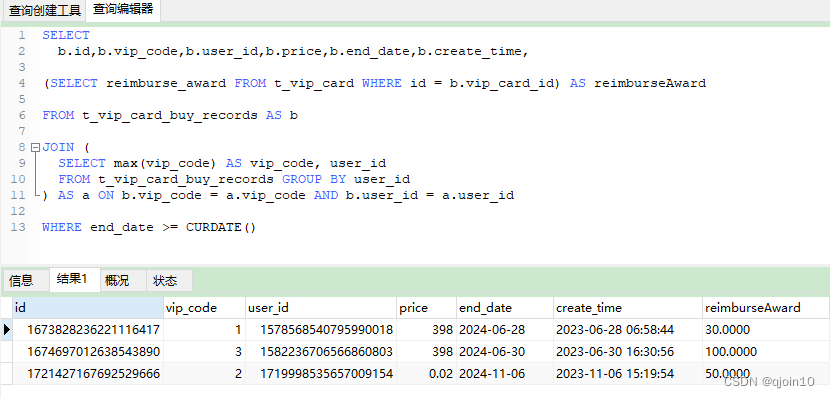
WHERE end_date >= CURDATE()运行效果:
总结:
这里一定要注意 max( ) 的结果一定是唯一的,比如上面的 end_date 和 create_time 就不是唯一的, 同一个user_id 有多条end_date和create_time相同数据 , 就只能用另外的方法来实现了
所以,这里用 max(vip_code) 配合 group by user_id 取出每个用户最大的 vip_code 那条数据,而这里每个 user_id 只会有一条 有效的 vip_code 最大的数据, 所以符合上面的写法














 3096
3096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









