







python机器学习复习
1. python基础
python内置数据类型
数字(Number)
字符串(String)
列表(List)
元组(Tuple)
集合(Set)
字典(Dictionary)
区别:
整数和浮点数是数值类型,用于存储数值;
字符串是文本类型,用于存储文本数据;
列表、元组和字典是复合类型,用于存储多个值;
集合是无序的,唯一的,用于存储唯一的元素集合;
布尔值是特殊的整数类型,只有两个值 True 和 False,用于条件判断。
不可变类型 内存中的数据不允许被修改(一旦被定义,内存中分配了小格子,就不能再修改内容了):
数字类型int,bool,float,complex,long(2,x)
字符串str
元组tuple
可变类型 内存中的数据可以被修改(可以通过变量名调用方法来修改列表和字典内部的内容,而内存地址不发生变化):
列表list
字典dict(注:字典中的key只能使用不可变类型的数据)
注:给变量赋新值的时候,只是改变了变量的引用地址,不是修改之前的内容
1.可变类型的数据变化,是通过方法来实现的
2.如果给一个可变类型的变量,复制了一个新的数据,引用会修改(变量从之前的数据上撕下来,贴到新赋值的数据上)
元组的操作
取值
tup = (1, 2, 3, 4, 5 )
tup[0](取出的具体数值)
tup[2:5](取出的为元组)
修改
元组是不可变序列,元组中的元素不能被修改,所以我们只能创建一个新的元组去替代旧的元组。
删除
当创建的元组不再使用时,可以通过 del 关键字将其删除,但是不能删除元组的单个项
索引、切片、矩阵

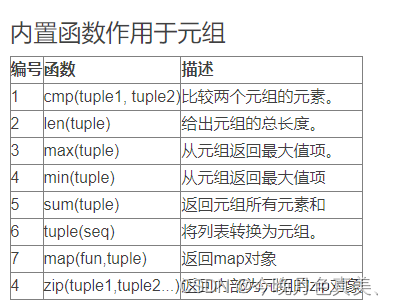
元组方法:index count
index()查找并返回指定元素的索引位置,若指定的元素不存在则会抛出异常,可以指定范围查找
count()统计指定元素出现的次数并返回这个数,若指定元素不存在则返回:0
列表的操作(增删改查)
列表生成式的语法基本结构为:
new_list = [expression for item in iterable if condition]
expression:是一个表达式,用于对item进行操作,生成新的元素,这是列表生成式必须要有的部分。
item:是在iterable中的元素,可以是列表、元组、字符串、集合、字典等可迭代对象。
iterable:是一个可迭代对象,可以是列表、元组、字符串、集合、字典等。
condition:是一个可选的条件,用于筛选item,只有满足条件的item才会被加入到新列表中。
numbers = [1, 2, 3, 4, 5]
squares = [num ** 2 for num in numbers]
print(squares) # 输出 [1, 4, 9, 16, 25]
带有条件的列表生成式:列表生成式还可以包含条件表达式,用于筛选原列表中的元素。
numbers = [1, 2, 3, 4, 5]
even_numbers = [num for num in numbers if num % 2 == 0]
print(even_numbers) # 输出 [2, 4]
嵌套列表生成式
嵌套列表生成式指的是在一个列表生成式中使用多个循环语句,来生成嵌套的列表。
语法:[[expression] for item in iterable1 [for item2 in iterable2] …]
matrix = [[i+j for j in range(3)] for i in range(4)]
print(matrix)
输出:[[0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5]]
使用函数
列表生成式不仅可以使用简单的表达式,还可以使用函数来对元素进行操作。通过在列表生成式中调用函数,可以对元素进行自定义的操作和处理。
def reverse_string(string):
return ''.join(reversed(string))
words = ['hello', 'world', 'python']
reverse_words = [reverse_string(word) for word in words]
print(reverse_words)
# 生成随机列表,查找缺失值
import random
nums = [x for x in range(100)]
print(nums)
num = []
while len(num) < 90:
i = random.randint(0, 100)
if i in num:
pass
else:
num.append(i)
print(num)
queshi = []
for i in nums:
if i in num:
pass
else:
queshi.append(i)
print(queshi)
查找
- 下标
- 切片
- 函数
index():返回指定数据所在位置的下标
count():统计指定数据在当前列表中出现的次数
len(): 访问列表⻓度,即列表中数据的个数
判断是否存在:
in :判断指定数据在某个列表序列,如果在返回 True ,否则返回 False
not in: 判断指定数据不在某个列表序列,如果不在返回 True ,否则返回 False
增加
append():列表结尾追加数据。
extend():列表结尾追加数据,如果数据是⼀个序列,则将这个序列的数据逐⼀添加到列表。
insert():指定位置新增数据。
序列类型添加操作
a = [1, 2]
c = a + [3, 4] # 保证多个序列的类型一致,否则报错
# c = a + (3, 4) # TypeError: can only concatenate list (not "tuple") to list
print(c) # [1, 2, 3, 4]
print(a) # [1, 2]
# 在变量a的基础上添加元素
a += (3, 4) # 本质上是调用了序列类中的__iadd__方法
print(a) # [1, 2, 3, 4]
删除
del ⽬标
del name_list #删除列表
del name_list[0] #删除元素
pop():删除指定下标的数据(默认为最后⼀个),并返回该数据。【列表序列.pop(下标)】
remove():移除列表中某个数据的第⼀个匹配项。【列表序列.remove(数据)】
clear():清空列表 【只是清空,列表还是存在的】
修改
修改指定下标数据:下标
name_list = ['Tom', 'Lily', 'Rose']
name_list[0] = 'aaa'
# 结果:['aaa', 'Lily', 'Rose']
print(name_list)
逆置:list.reverse()
列表序列
sort( key=None, reverse=False)【改变原列表】
sorted(list):sorted对一切可迭代对象进行排序【不该变原列表】
(注意:reverse表示排序规则,reverse = True 降序, reverse = False 升序(默认))
【同一数据类型可直接进行排序,多种不同数据结构排序,需要先转换成字符串型】
可变数据类型
books = [
{
"id": 1, "name": '三国演义'},
{
"id": 2, "name": '水浒传'},
{
"id": 3, "name": '西游记'}
]
print(books)
for book in books:
book['id_name'] = str(book['id']) + "_" + str('name')
print(books)


复制
函数: list.copy()
列表的循环遍历
while
name_list = ['Tom', 'Lily', 'Rose']
i = 0
while i < len(name_list):
print(name_list[i])
i += 1
for
name_list = ['Tom', 'Lily', 'Rose']
for i in name_list:
print(i)
列表嵌套
列表嵌套指的就是⼀个列表⾥⾯包含了其他的⼦列表。
name_list = [['⼩明', '⼩红', '⼩绿'], ['Tom', 'Lily', 'Rose'], ['张三', '李四', '王五']]
# 第⼀步:按下标查找到李四所在的列表
print(name_list[2])
# 第⼆步:从李四所在的列表⾥⾯,再按下标找到数据李四
print(name_list[2][1])
字典的操作【增删改查】
增加
字典的创建
创建字典的基本方法是使用花括号 {},在其中放置以逗号分隔的键值对。
my_dict = {
'name': '张三', 'age': 30, 'city': '北京'}
此外,也可以使用 dict() 函数来创建字典
my_dict = dict(name='张三', age=30, city='北京')
字典推导式
字典推导式(dictionary comprehension)是创建字典的快速方法。它类似于列表推导式,但用于生成键值对。例如,将一个数字列表转换为其平方的字典
squares = {
x: x*x for x in range(6)}
print(squares) # 输出:{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
update() :可以使用 update() 方法来合并两个字典。该方法会更新已存在的键值对,并添加不存在的键值对。
other_dict = {
'gender': '男', 'age': 32}
my_dict.update(other_dict)
字典的嵌套
字典可以嵌套其他字典,从而创建更复杂的数据结构。
nested_dict = {
'child1': {
'name': '小明', 'age': 5},
'child2': {
'name': '小红', 'age': 7}}
修改
可以直接通过键来修改字典中的值。如果该键存在,其值将被更新;如果不存在,将添加新的键值对。
> my_dict['age'] = 31 # 修改已存在的键
> my_dict['address'] = '上海' # 添加新的键值对
查找
访问字典中的值
要访问字典中的值,可以使用相应的键
name = my_dict['name']
print(name) # 输出:张三
如果尝试访问字典中不存在的键,将引发 KeyError。为了避免这种错误,可以使用 get() 方法,当键不存在时,它将返回 None 或者指定的默认值。
address = my_dict.get('address', '地址未知')
print(address) # 输出:地址未知
字典的遍历
遍历字典时,可以使用 items() 方法来获取键值对,keys() 方法来获取所有键,以及 values() 方法来获取所有值。
for key, value in my_dict.items():
print(f"{
key}: {
value}")
# 输出: # name: 张三 # city: 北京
字典的排序
虽然字典本身是无序的,但可以对其进行排序并生成一个新的有序结构,如列表。
sorted_dict = dict(sorted(my_dict.items()))
或者根据值排序
sorted_by_value = dict(sorted(my_dict.items(), key=lambda item: item[1]))
删除
可以使用 del 语句来删除字典中的特定元素。
del my_dict['address']
还可以使用 pop() 方法来删除并返回字典中的特定元素。
age = my_dict.pop('age') print(age)  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









