







大家好,我是小F~
这两年AI可以说是非常火,尤其是AIGC领域。
而这其中很多都是基于Python实现的,比如ChatGPT、AI绘画、声音克隆等等。

对于普通人来说,想直接学习这些高难度的Python项目,还是比较困难的。
小F是非常建议大家学Python,可以从Python爬虫入门。
相对来说简单一点,可以通过学习爬虫案例来入门Python,为了以后学AI打下基础。
今天就给大家介绍一个百度指数数据爬取的实战案例。
其中为了保证数据采集的稳定与高效,小F使用了亮数据的IP代理。

在众多的IP代理提供商中,亮数据(Bright Data) 以其稳定、高效和专业的服务受到了广大用户的青睐,这也是小F选择它的原因。

不仅提供代理服务,还有一些数据集。

首次注册,提供5刀的免费额度,还是不错的。
大家要体验的,可以访问下方二维码,免费领取(联系客服开通免费试用),以备不时之需(比如运行爬虫代码IP被封)。

下面就来看一下爬虫实战案例吧~
发现百度指数的加密方式又变了,所以参考知乎一位大佬的代码。
完整代码如下。
import json
import requests
import urllib.request
from datetime import datetime
from datetime import timedelta
# 获取IP代理
def get\_proxy():
opener = urllib.request.build\_opener(
urllib.request.ProxyHandler(
{'http': 'http://brd-customer-hl\_5dede465-zone-try-country-cn:pdqt396jal8m@brd.superproxy.io:22225',
'https': 'http://brd-customer-hl\_5dede465-zone-try-country-cn:pdqt396jal8m@brd.superproxy.io:22225'}))
response = opener.open('http://lumtest.com/myip.json').read()
response\_str = response.decode('utf-8')
ip = json.loads(response\_str)\['ip'\]
proxies = {
"http": "http://{}".format(ip),
"https": "http://{}".format(ip),
}
return proxies
# 解码函数
def decrypt(ptbk, index\_data):
n = len(ptbk)//2
a = dict(zip(ptbk\[:n\], ptbk\[n:\]))
return "".join(\[a\[s\] for s in index\_data\])
def reCode(data, ptbk):
data = data\['data'\]
li = data\['userIndexes'\]\[0\]\['all'\]\['data'\]
startDate = data\['userIndexes'\]\[0\]\['all'\]\['startDate'\]
year\_str = startDate\[:4\] # 使用切片取前四个字符,即年份部分
try:
# 将年份字符串转换为整数
year = int(year\_str)
# 根据年份判断是否为闰年
if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0):
year = 366
else:
year = 365
except :
year =365
if li =='':
result = {}
name = data\['userIndexes'\]\[0\]\['word'\]\[0\]\['name'\]
tep\_all = \[\]
while len(tep\_all) < year:
tep\_all.insert(0, 0)
result\["name"\] = name
result\["data"\] = tep\_all
else:
ptbk = ptbk
result = {}
for userIndexe in data\['userIndexes'\]:
name = userIndexe\['word'\]\[0\]\['name'\]
index\_all = userIndexe\['all'\]\['data'\]
try:
index\_all\_data = \[int(e) for e in decrypt(ptbk, index\_all).split(",")\]
tmp\_all = index\_all\_data
except:
tmp\_all = \[\]
while len(tmp\_all) < year:
tmp\_all.insert(0, 0)
result\["name"\] = name
result\["data"\] = tmp\_all
return result
def get\_index\_data(word, year, proxies):
words = \[\[{"name": word, "wordType": 1}\]\]
words = str(words).replace(" ", "").replace("'", "\\"")
startDate = f"{year}\-01-01"
endDate = f"{year}\-12-31"
url = f'http://index.baidu.com/api/SearchApi/index?area=0&word={words}&startDate={startDate}&endDate={endDate}'
# 请求头配置
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/plain, \*/\*",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Cipher-Text": "1698156005330\_1698238860769\_ZPrC2QTaXriysBT+5sgXcnbTX3/lW65av4zgu9uR1usPy82bArEg4m9deebXm7/O5g6QWhRxEd9/r/hqHad2WnVFVVWybHPFg3YZUUCKMTIYFeSUIn23C6HdTT1SI8mxsG5mhO4X9nnD6NGI8hF8L5/G+a5cxq+b21PADOpt/XB5eu/pWxNdwfa12krVNuYI1E8uHQ7TFIYjCzLX9MoJzPU6prjkgJtbi3v0X7WGKDJw9hwnd5Op4muW0vWKMuo7pbxUNfEW8wPRmSQjIgW0z5p7GjNpsg98rc3FtHpuhG5JFU0kZ6tHgU8+j6ekZW7+JljdyHUMwEoBOh131bGl+oIHR8vw8Ijtg8UXr0xZqcZbMEagEBzWiiKkEAfibCui59hltAgW5LG8IOtBDqp8RJkbK+IL5GcFkNaXaZfNMpI=",
"Referer": "https://index.baidu.com/v2/main/index.html",
"Accept-Language": "zh-CN,zh;q=0.9",
'Cookie': '你的cookie'}
res = requests.get(url, headers=headers, proxies=proxies)
res\_json = res.json()
if res\_json\["message"\] == "bad request":
print("抓取关键词:"+word+" 失败,请检查cookie或者关键词是否存在")
else:
# 获取特征值
data = res\_json\['data'\]
uniqid = data\["uniqid"\]
url = f'http://index.baidu.com/Interface/ptbk?uniqid={uniqid}'
res = requests.get(url, headers=headers, proxies=proxies)
# 获取解码字
ptbk = res.json()\['data'\]
return res\_json, ptbk
def get\_date\_list(year):
"""
获取时间列表
"""
begin\_date = f"{year}\-01-01"
end\_date = f"{year}\-12-31"
dates = \[\]
dt = datetime.strptime(begin\_date, "%Y-%m-%d")
date = begin\_date\[:\]
while date <= end\_date:
dates.append(date)
dt += timedelta(days=1)
date = dt.strftime("%Y-%m-%d")
return dates
def get\_word():
proxies = get\_proxy()
startyear = 2023
endyear = 2023
words = \["Python", "C", "Java", "C#", "JavaScript", "SQL", "Go", "PHP", "MATLAB", "Swift", "Rust"\]
for word in words:
for year in range(startyear, endyear + 1):
try:
data, ptbk = get\_index\_data(word, year, proxies)
res = reCode(data, ptbk)
dates = get\_date\_list(year)
for num, date in zip(res\['data'\], dates):
print(word, num, date)
with open('word2.csv', 'a+', encoding='utf-8') as f:
f.write(word + ',' + str(num) + ',' + date + '\\n')
except:
pass
get\_word()
只需替换请求头里的cookie值即可,获取方式如下图。

对于IP代理,可以根据你需要的类型,如无限机房代理、动态住宅代理、机房代理、移动代理,创建代理通道。
进入通道后,可以看到使用指南,以及其它语言的调用案例。


具体代码如下。
import json
import urllib.request
opener = urllib.request.build\_opener(
urllib.request.ProxyHandler(
{'http': 'http://brd-customer-hl\_5dede465-zone-try-country-cn:pdqt396jal8m@brd.superproxy.io:22225',
'https': 'http://brd-customer-hl\_5dede465-zone-try-country-cn:pdqt396jal8m@brd.superproxy.io:22225'}))
response = opener.open('http://lumtest.com/myip.json').read()
# 将响应转换为字符串
response\_str = response.decode('utf-8')
# 使用json库解析字符串
data = json.loads(response\_str)\['ip'\]
# 打印IP地址,每一次打印结果是不一样的,输出例子:73.110.170.116
print(data)
这样就不用担心运行爬虫代码,网站把我自己的ip给封了。
如需体验使用,可以点击左下角【阅读原文】,快速访问,联系客服开通免费试用。
运行代码,成功获取到3000+的数据。

接下来使用pynimate进行可视化展示。
具体代码如下。
from matplotlib import pyplot as plt
import pandas as pd
import pynimate as nim
# 中文显示
plt.rcParams\['font.sans-serif'\] = \['SimHei'\] #Windows
plt.rcParams\['axes.unicode\_minus'\] = False
# 更新条形图
def post\_update(ax, i, datafier, bar\_attr):
ax.spines\["top"\].set\_visible(False)
ax.spines\["right"\].set\_visible(False)
ax.spines\["bottom"\].set\_visible(False)
ax.spines\["left"\].set\_visible(False)
ax.set\_facecolor("#001219")
# 读取数据
df\_data = pd.read\_csv('word2.csv', encoding='utf-8', header=None, names=\['name', 'number', 'day'\]).set\_index("day")
print(df\_data)
# 数据处理,数据透视表
df = pd.pivot\_table(df\_data, values='number', index=\['day'\], columns=\['name'\], fill\_value=0).head(30)
print(df)
# 保存
# df = pd.read\_csv("word.csv").set\_index("day")
# 新建画布
cnv = nim.Canvas(figsize=(12.8, 7.2), facecolor="#001219")
bar = nim.Barplot(
df, "%Y-%m-%d", "2h", post\_update=post\_update, rounded\_edges=True, grid=False, n\_bars=10
)
# 标题设置
bar.set\_title("主流编程语言热度排行(百度指数)", color="w", weight=600, x=0.15, size=30)
# 时间设置
bar.set\_time(
callback=lambda i, datafier: datafier.data.index\[i\].strftime("%Y-%m-%d"), color="w", y=0.2, size=20
)
# 文字颜色设置
bar.set\_bar\_annots(color="w", size=13)
bar.set\_xticks(colors="w", length=0, labelsize=13)
bar.set\_yticks(colors="w", labelsize=13)
# 条形图边框设置
bar.set\_bar\_border\_props(
edge\_color="black", pad=0.1, mutation\_aspect=1, radius=0.2, mutation\_scale=0.6
)
cnv.add\_plot(bar)
cnv.animate()
# 显示
# plt.show()
# 保存gif
cnv.save("code", 24, "gif")
结果如下所示。
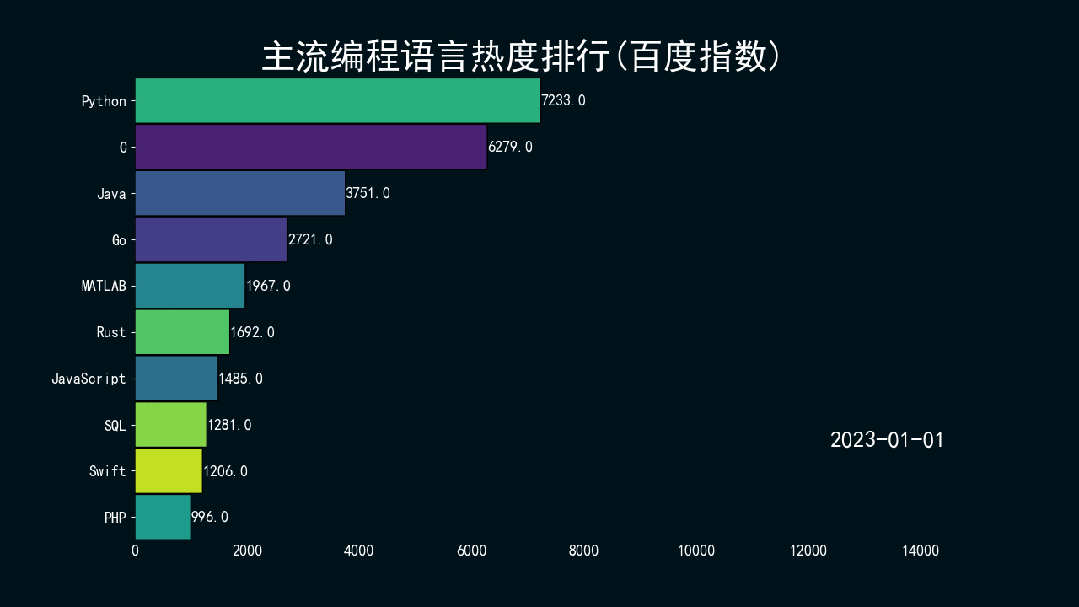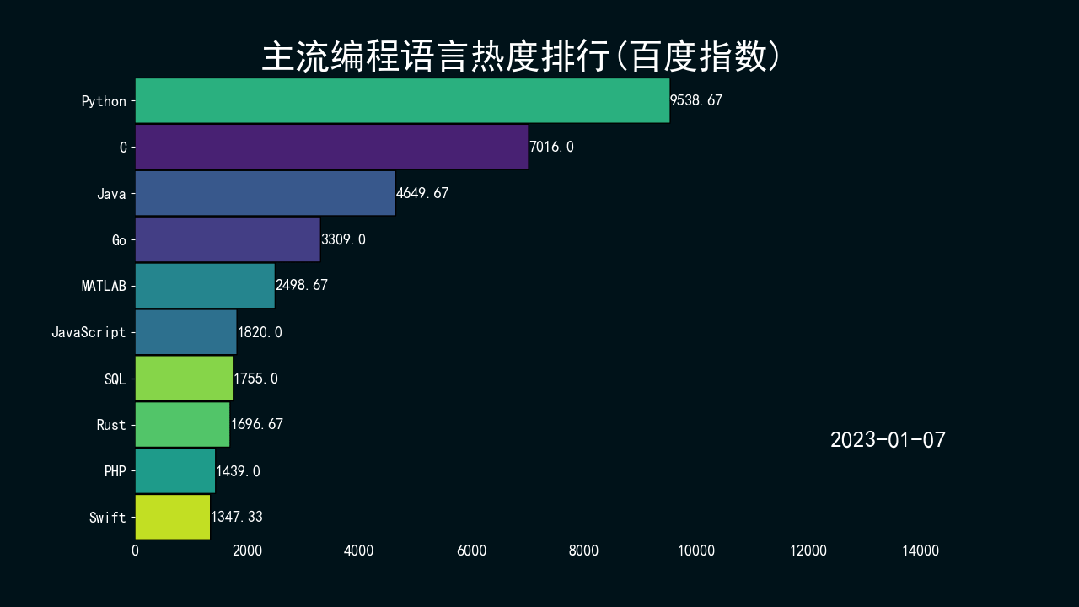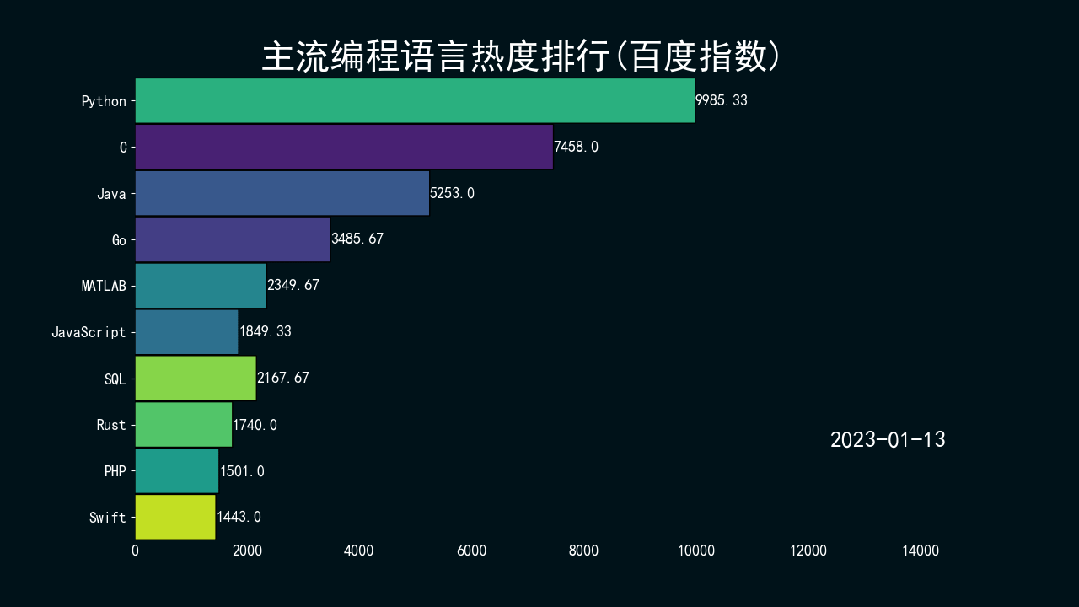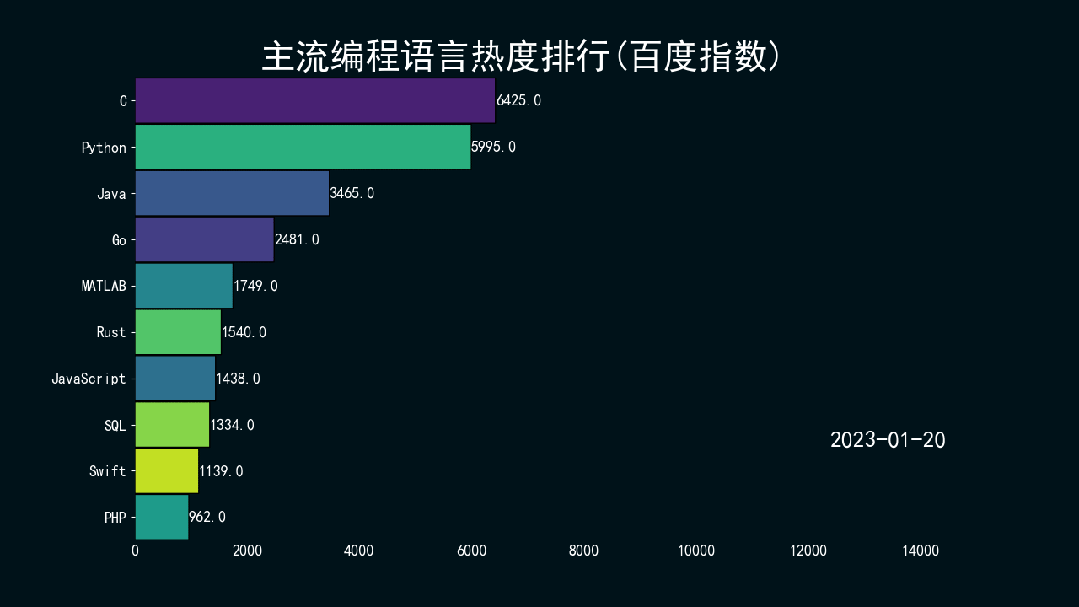
万水千山总是情,点个 👍 行不行。
点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python书籍和视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉Python副业创收路线👈

这些资料都是非常不错的,朋友们如果有需要《Python学习路线&学习资料》,点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
本文转自 网络,如有侵权,请联系删除。














 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









