







Kafka简介
Kafka是由Linkedin公司开发的一个分布式、支持分区(partition)、多副本(replica),基于Zookeeper协调的分布式消息系统。它的最大的特点就是可以实时的处理大量数据以满足各种需求场景。如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等。
Kafka的使用场景
日志收集:用Kafka收集各种服务的日志,通过Kafka以统一服务接口的方式开放给各种consumer,如:Hadoop、Hbase、Solr等。
消息系统:解耦生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
Kafka的基本概念
Kafka是一个分布式、分区的消息(commit log)服务。Kafka借鉴了JMS规范的思想,但是确没有完全遵循JMS规范。
名称 | 解释 |
Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
Producer | 消息生产者,向Broker发送消息的客户端 |
Consumer | 消息消费者,从Broker消费消息的客户端 |
ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息 |
Partition | 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
producer通过网络发送消息到kafka集群,然后consumer对消息进行消费处理,如下图:
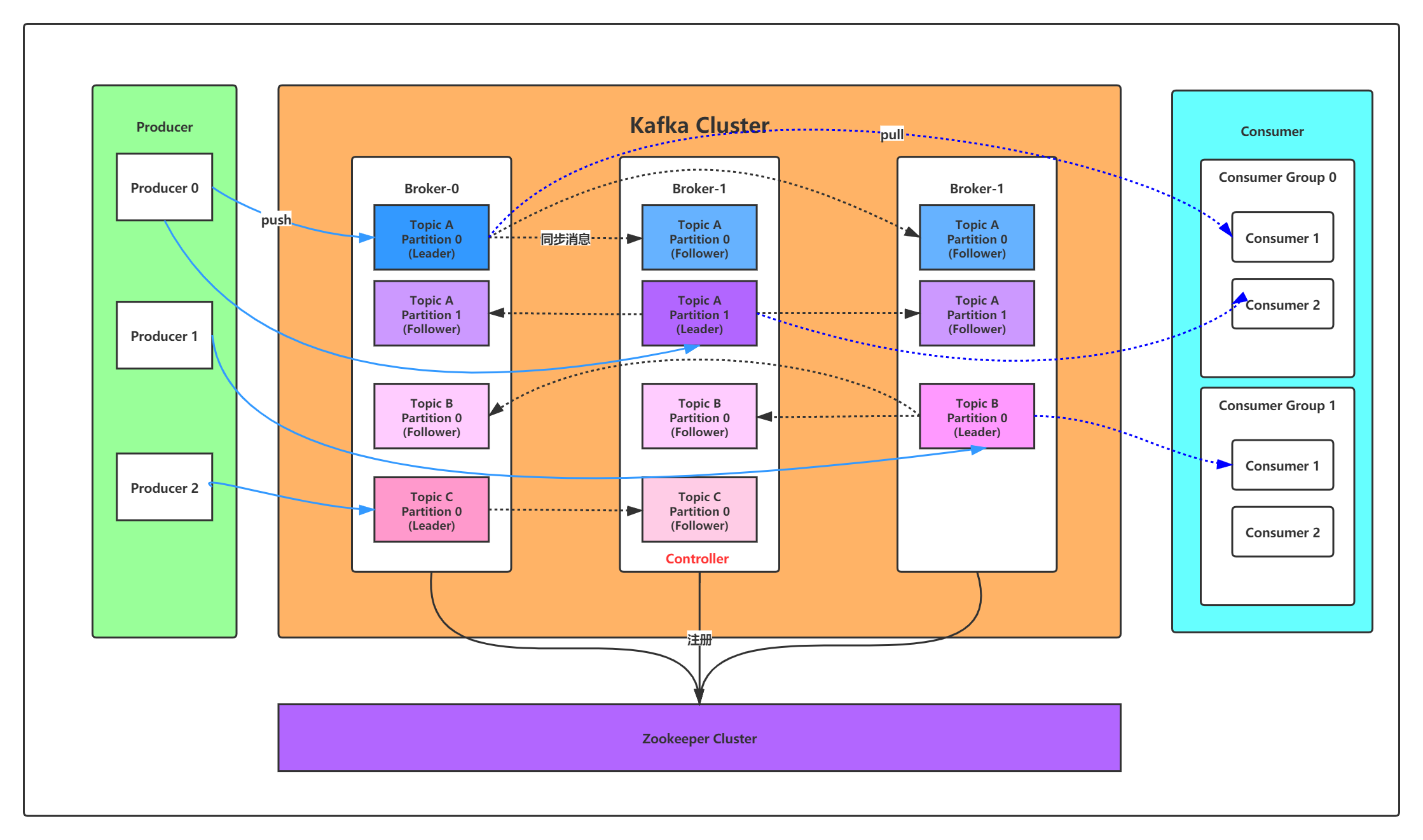
服务端(brokers)和客户端(producer、consumer)之间通信通过 TCP协议来完成。
Kafka的主题Topic和消息日志Log
Topic是一个类别名称,同类消息发送到同一个Topic下面,对于每一个Topic下面可以有多个分区(Partition)日志文件,如下图:
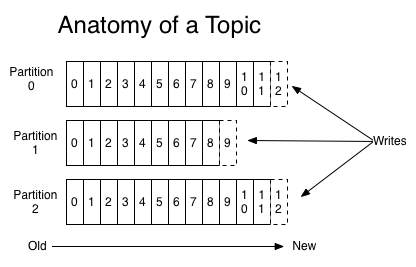
Partition是一个有序的message序列,这些message按顺序添加到一个叫commit log的文件中。每个partition中的消息都有一个唯一的编号offset,用来唯一标识某个分区中的message。
kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多久被删除,默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,因此保存大量的数据消息日志信息不会有什么影响。
Consumer:每个consumer是基于自己在commit log中的消息记录(offset)来工作的,消费offset由consumer自己来维护。一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。
为什么要对Topic下数据进行分区存储?
commit log文件会受到所在机器的文件系统大小的限制,分区之后可以将不同的分区放在不同的机器上,相当于对数据做了分布式存储,理论上一个topic可以处理任意数量的数据。
为了提高并行度。















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









