









大家好,我是RecordLiu。
初学SQL,有哪些合适的练习网站推荐呢?
如果你有编程基础,那么我推荐你到Leetcode这样的专业算法刷题网站,如果没有,也不要紧,你也可以到像牛客网一样的编程网站去练习。
牛客网有很多面向非技术人员的练习题目,很适合入门。
今天给大家分享的是牛客网在线编程SQL篇非技术快速入门题解第二弹。
题目直达链接:
切换到SQL篇就能看到了。
我这里先列一下题目分类:

接下来,我们来详细看一看。
多表查询-子查询
1.现在运营想要查看所有来自浙江大学的用户题目回答明细情况,请你取出相应数据。用户信息保存在user_profile中,用户答题信息保存在question_practice_detail中。
示例:user_profile

示例:question_practice_detail

返回结果

题解
题目要求查出的是浙江大学的用户答题明细,因此需要同时用到用户信息表和答题信息表两张表。
第一种方式是使用内连接方式来解这道题。通过设备号(device_id)将两张表关联起来,再把学校为浙江大学的用户答题信息过滤出来。
SQL中的连接操作可以把多张表的字段水平连接起来,相当于组成一张大的宽表返回。
内连接使用inner join实现。
连接可以理解成是表的横向拓展,这样就可以使用另一张表(或更多表)里面的字段了。
那怎样在不使用表连接的方式下,用到其他表里面的字段呢?SQL中可以用子查询来实现。
子查询又称为嵌套查询。子查询允许我们将一张表的查询结果作为另一张表的过滤条件的数据输入。
怎么理解呢,我举个例子可能会明白些:
# 子查询例子,作为in的过滤条件
SELECT f1,f2
FROM t1
WHERE f1 IN(
SELECT f1 FROM t2 WHERE f3=xxx
);
这道题中,我们可以先从用户表中过滤出是浙江大学的记录,记为一个子查询,这个查询结果只保留是浙江大学的设备ID列表,假设把这个临时结果记为u_p。
然后再查询答题信息表,再根据子查询结果u_p的保存设备列表去过滤出符合条件的设备号和答题信息,也可以解此道题。
代码参考
方法1:内连接实现
SELECT qpd.device_id,
qpd.question_id,qpd.result
FROM question_practice_detail AS qpd
INNER JOIN user_profile AS up
ON qpd.device_id =up.device_id
AND up.university = '浙江大学';
方法2:子查询实现
SELECT device_id,question_id,result
FROM question_practice_detail
WHERE device_id IN(
SELECT device_id FROM user_profile WHERE university='浙江大学'
)
多表查询-链接查询
2.运营想要了解每个学校答过题的用户平均答题数量情况,请你取出数据。其中,用户信息保存在表user_profile中,用户的答题信息保存在question_practice_detail中。设备号可以唯一标识一个用户。
说明
某学校用户平均答题数量计算方式为该学校用户答题总次数除以答过题的不同用户个数,需要对结果保留4位小数,结果按照university升序排序:
示例:user_profile
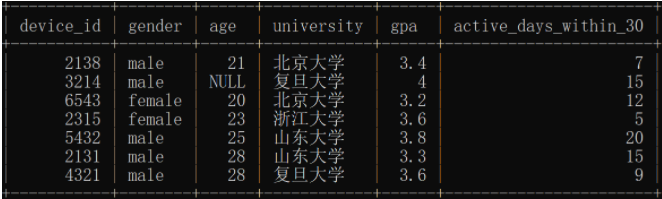
示例:question_practice_detail

返回结果

题解
题目要求计算的是用户的平均答题次数,计算公式为答题次数/答题用户数。
答题次数可以从用户的答题信息表统计出来,使用count函数,对列question_id计算总和即可。
答题的用户数也是从用户的答题信息表统计出来,也是使用count函数,对列device_id进行计算总和。但题目要求是不同的用户数,所以需要结合去重函数distinct对设备号进行去重。
由于需要按不同学校进行统计,所以需要内联表用户信息,通过设备号把两张表里面的数据关联起来,再按university字段进行分组。
还有一点,题目要求对结果保留4位小数,我们可以使用round函数对结果进行四舍五入并且保留4位小数。
最后,需要使用order by对university字段进行升序排列。
代码参考
SELECT up.university,ROUND(COUNT(qpd.question_id) / COUNT(DISTINCT qpd.device_id),4)
FROM question_practice_detail AS qpd
INNER JOIN user_profile AS up
ON qpd.device_id = up.device_id
GROUP BY up.university
ORDER BY up.university ASC;
多表查询-组合查询
3.现在运营想要分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重。
示例:user_profile

返回结果

题解
题目要求是查出山东大学或者性别为男性的用户信息,并且结果不去重。
那过滤条件可不可以直接写成where university=‘山东大学’ or gender='male’呢?
我们注意看示例中这条记录:

这条记录同时满足学校为山东大学以及性别为男性,如果使用上述的过滤条件,查询出来的结果将会只有一条,但题目要求返回的是两条,我们看示例返回的结果就清楚了。
这道题本质是考察union的用法。
join可以理解成是表之间的水平连接操作,而union则是表之间的垂直连接操作。
union允许我们将多个select查询结果组合在一起。
但使用前提是每个select查询需要满足查询的结构一致,即查询的列名相同、查询的列顺序保持一致。
其中,union默认会将查询出的结果进行去重,union all不对结果进行去重,将会返回所有组合在一起的结果。
回到这道题中,可以将查询出学校为山东大学和查询出性别为男性的结果使用union all操作组合在一起。
这样就可以把同时满足学校为山东大学且性别为男性的记录查询出两条了。
代码参考
SELECT device_id,gender,age,gpa FROM user_profile
WHERE university='山东大学'
UNION ALL
SELECT device_id,gender,age,gpa FROM user_profile
WHERE gender='male'
必会的常用函数-条件函数
4.现在运营想要将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量。其中,age为null 也记为25岁以下
示例:user_profile

返回结果

题解
这道题很多解法,我这里主要给大家讲一下用case函数来实现。
返回结果中age_cut这列在用户信息表是没有的,所以我们需要利用条件函数来生成age_cut这个辅助列。
那具体如何生成辅助列呢?看完case函数的用法你就知道了。
接下来,我给你详细说说。
case函数是一种多分支的条件表达式,它是用来匹配多种情况的。
case函数基本语法如下
简单case函数
基本语法:
CASE 测试表达式
WHEN 简单表达式1 THEN 结果表达式1
WHEN 简单表达式2 THEN 结果表达式2 ...
WHEN 简单表达式n THEN 结果表达式n
[ELSE 结果表达式n+1 ]
END
简单case的执行顺序,先计算测试表达式的值,然后将计算出的结果从上到下依次和when后面的简单表达式进行对比,其中有一个匹配就终止case语句。
如果都没有匹配上,在书写了else语句情况下,会使用默认的结果表达式,否则会返回NULL。
举例
比如有个发货订单表(order),表里面有个订单状态字段(status),取值分别为0、1、2,对应未发货、已发货、已收到三种状态。
现在要求你对查出的订单状态字段用中文进行命名。
使用简单case函数实现如下:
SELECT
CASE status
WHEN 0 THEN '未发货'
WHEN 1 THEN '已发货'
WHEN 2 THEN '已收到'
END AS 订单状态
FROM order
搜索case函数
基本语法:
CASE
WHEN 布尔表达式1 THEN 结果表达式1
WHEN 布尔表达式2 THEN 结果表达式2 ...
WHEN 布尔表达式n THEN 结果表达式n
[ELSE 结果表达式n+1 ]
END
与简单case函数不同的是,搜索case函数不需要带测试表达式,而是从上到下,依次比较when后面的布尔表达式,如果其中一个为真,就执行then后面的结果表达式,并停止往下匹配。
如果没有一个布尔表达式满足,在书写了else语句情况下,会使用默认的结果表达式,否则会返回NULL。
举例
假设用户信息表user中有一个年龄字段age,记录的是用户的周岁,比如20、25、30等。
现在需要你对用户年龄进行分段,划分为0-17岁、18-25岁、26-35岁、36-45岁、46-55岁、56岁及以上。
使用搜索case实现如下:
SELECT
CASE
WHEN age >=0 AND age <= 17 THEN "0-17岁"
WHEN age >= 18 AND age <= 25 THEN "18-25岁"
WHEN age >= 26 AND age <= 35 THEN "26-35岁"
WHEN age >= 36 AND age <=45 THEN "36-45岁"
WHEN age >= 46 AND age <= 55 THEN "46-55岁"
ELSE "56岁及以上"
END
FROM user
代码参考
使用case实现这道题
SELECT CASE
WHEN age < 25 OR age is NULL THEN '25岁以下'
WHEN age >=25 THEN '25岁及以上'
END AS age_cut,COUNT(*) AS number
FROM user_profile
GROUP BY age_cut
这道题中,我们通过case函数给每条记录生成了一个辅助列age_cut,这个辅助列只有两个取值,分别为25岁以下和25岁及以上,再对列进行分组后,就可以统计出两个类型的用户数量了。
作为拓宽思路,我给你列举了一些其他的解题思路,大家可以看看。
使用if实现
SELECT IF(age<25 OR age IS NULL,'25岁以下','25岁及以上') age_cut,COUNT(device_id) Number
FROM user_profile
GROUP BY age_cut
使用union实现
SELECT '25岁以下' AS age_cut,COUNT(device_id) number
FROM user_profile
WHERE age<25 OR age IS NULL
UNION
SELECT '25岁及以上' AS age_cut,COUNT(device_id) number
FROM user_profile
WHERE age>=25
GROUP BY age_cut
使用子查询实现
SELECT age_cut,COUNT(device_id) AS number FROM
(SELECT IF(age>=25,'25岁及以上','25岁以下') age_cut,device_id
FROM user_profile) u2
GROUP BY age_cut;
必会的常用函数-时间函数
5.现在运营想要计算出2021年8月每天用户练习题目的数量,请取出相应数据。
示例

返回结果
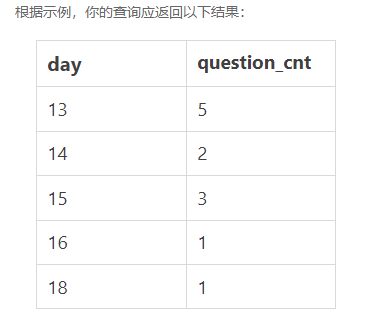
题解
这道题中,我们需要对date字段进行分组后,再统计每个日期的答题数量。
题目的限定条件为2021年8月份的数据,有多种过滤方式,你可以直接用date >= '2021-08-01' AND date <= '2021-08-31'进行判断,或者使用date_format函数,写成DATE_FORMAT(date,'%Y%m') = 202108。
在结果中,我们只需要返回日期中天数,因此需要使用day函数取date字段中的天数,再进行别名处理。
代码参考
SELECT day(date) as day,COUNT(question_id) question_cnt
FROM question_practice_detail
WHERE DATE_FORMAT(date,'%Y%m') = 202108
GROUP BY date;
在这里,我给你总结了常用的日期函数的用法:
返回日期中的年份
year('2021-08-01')
返回结果:2021
返回日期中的月份
month('2021-08-01')
返回结果:8
返回日期中的天数
day('2021-08-01')
返回结果:1
日期格式化
DATE_FORMAT('2021-08-01 12:30:00','%Y%m%d')
返回结果:20210801
日期增加1天
date_add('2021-08-01 12:30:00',interval 1 day), 返回结果:2021-08-02 12:30:00
返回两个日期之间的天数
datediff('2021-08-31','2021-08-30')
返回结果:1
必会的常用函数-文本函数
6.现在运营想要计算出2021年8月每天用户练习题目的数量,请取出相应数据。
示例:

返回结果

题解
这道题中,我们需要统计每种性别对应人数,但从示例中可以看出,没有单独的性别字段,无法直接统计。
用户的性别信息保存在profile字段中,因此我们需要从profile字段中截取出性别信息为每条记录生成一个辅助列gender,再按gender分组后,统计出总数量。
sql中的字符串截取可以使用substring_index函数来实现,具体用法:substring_index(字符串,分割符,取多少位)。
比如有一个字符串为‘a,b,c,d’
截取字符a
substring_index(‘a,b,c,d’,',',1)
截取字符a,b
substring_index(‘a,b,c,d’,',',2)
截取字符串b
substring_index(substring_index(‘a,b,c,d’,',',2),',',-1)
截取字符d
substring_index(‘a,b,c,d’,',',-1)
截取字符c,d
substring_index(‘a,b,c,d’,',',-1)
截取字符c
substring_index(substring_index(‘a,b,c,d’,',',-2),',',1)
从以上例子可以看出,当substring_index第三个参数为正数时,表示从左到右取n个子串;为负数时,则刚好相反,表示从右到左取n个子串。
代码参考
SELECT SUBSTRING_INDEX(profile,',',-1) as gender,
COUNT(device_id) AS number
FROM user_submit
GROUP BY gender
必会的常用函数-窗口函数
7.现在运营想要找到每个学校gpa最低的同学来做调研,请你取出每个学校的最低gpa。
示例:

返回结果
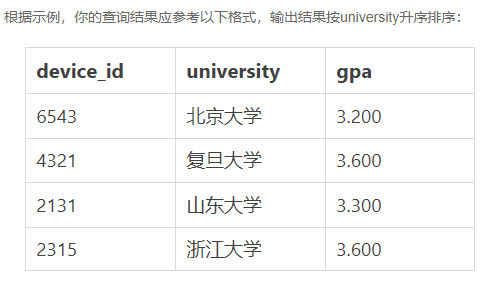
题解
这道题中,我们能不能直接按学校分组后,取出最低的gpa呢,sql实现如下:
SELECT device_id,university,min(gpa) FROM user_profile GROUP BY university ORDER BY university ASC;
提交之后,你会发现结果并不正确,为什么呢?大家可以思考下原因。
这道题我们可以利用SQL中的窗口函数来实现,在窗口函数里,按university字段进行分区后,再对gpa字段进行升序排列,再通过row_number()函数为每条记录生成一个辅助的排名字段,每个分区里面的第一名就是我们所要求的值。
代码参考
SELECT device_id,university,gpa FROM (
SELECT *,
row_number() OVER (PARTITION BY university ORDER BY gpa ASC) AS u_rank
FROM user_profile) AS u_p
WHERE u_p.u_rank = 1
ORDER BY university ASC;
好了,今天的文章就分享到这里了,如果觉得我的文章对你有帮助,欢迎多分享给你身边的朋友。














 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









