







概述
本文继续上文的工作,进一步升级了 Ragflow-Plus 的管理系统,新增了知识库管理单元,同时初步支持 MinerU 解析算法,并探索了图片生成的技术路线。
目前,仓库已更新本文所述功能,docker镜像尚未更新。
对于大多数用户,使用docker部署较为方便,但本次更新涉及大量文件底层操作,后续仍会对部分接口进行调整。
因此,docker镜像需等待功能较稳定后再放出来,否则用户每一轮更新都需要重新解析文档,较为麻烦。
Ragflow-Plus 仓库:https://github.com/zstar1003/ragflow-plus
新功能简介
文件管理和知识库管理两个菜单具有先后关系。
用户首先需要上传文件到文件管理菜单中,此步骤会增加数据库中file表的记录,一条记录对应一个文件。
之后,在知识库管理界面,用户可以查看管理所有用户的知识库,对应的是数据库中knowledgebase表,私人构建的知识库也难逃法眼。
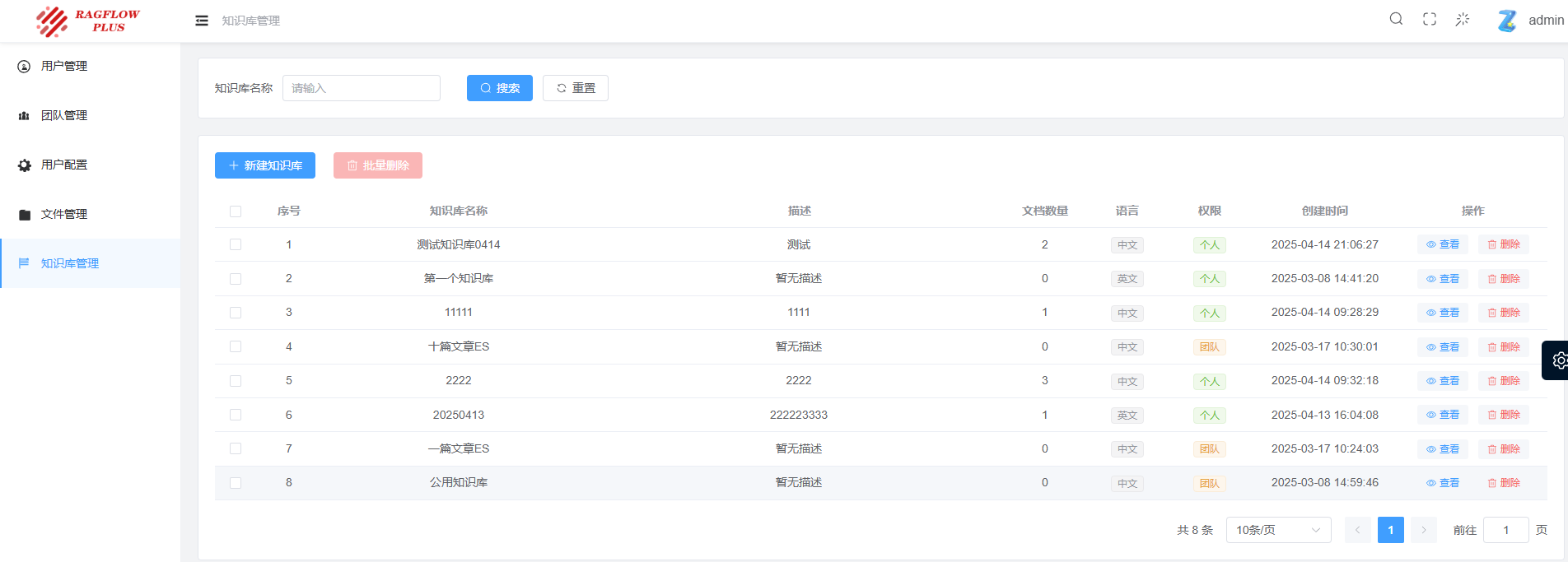
新建数据库,默认会以第一个注册用户的名义构建,可以选择语言、权限。
语言标记对实际功能不产生影响,只是作为标签进行提示。
权限会对共享情况产生影响,如需团队成员共同查看到该知识库,可设置为团队。
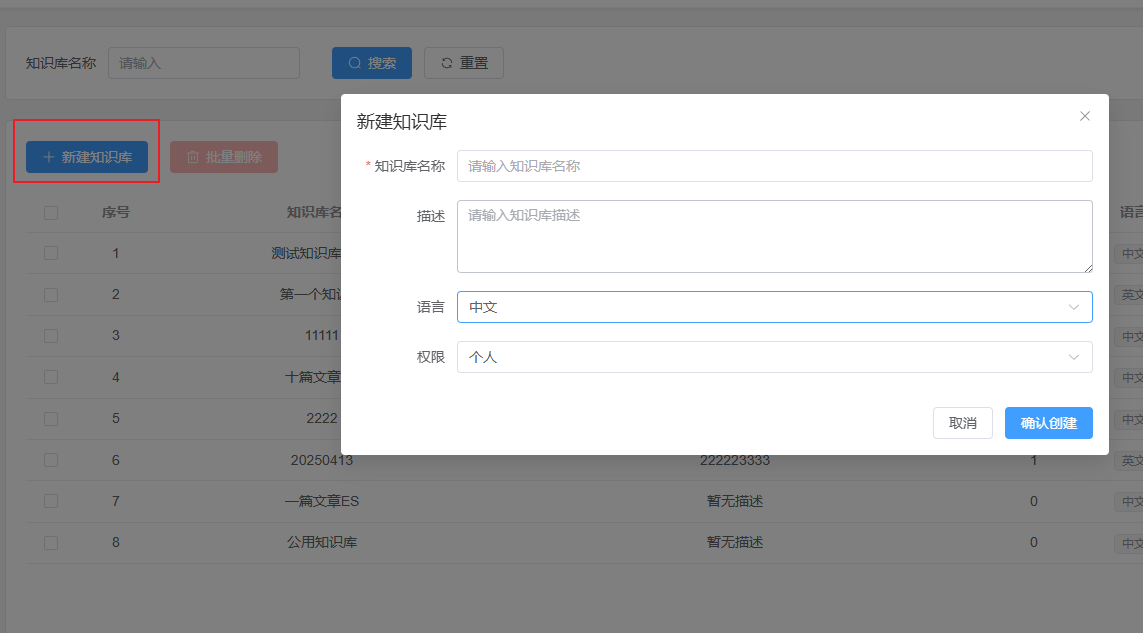
查看知识库,可以进一步看到知识库中包含的文档信息,可以执行添加文档、解析文档、移除文档操作。
添加文档,会从文件管理中的文件中进行选择,选择后,会在数据库中document和file2document两张表添加记录。
文件(file)只有添加进知识库中,才会形成文档(document),一个文件可以添加进多个知识库,形成多个独立文档。通过file2document表维护两者之间的关联。
在知识库中,移除文档,并不会彻底删除文件,文件仍然可以添加进其它知识库。
这样设计,虽然操作上会比ragflow原版略繁琐,但能够有效解决原版本中,上传文件/链接文件共存,导致文件管理杂乱的问题。
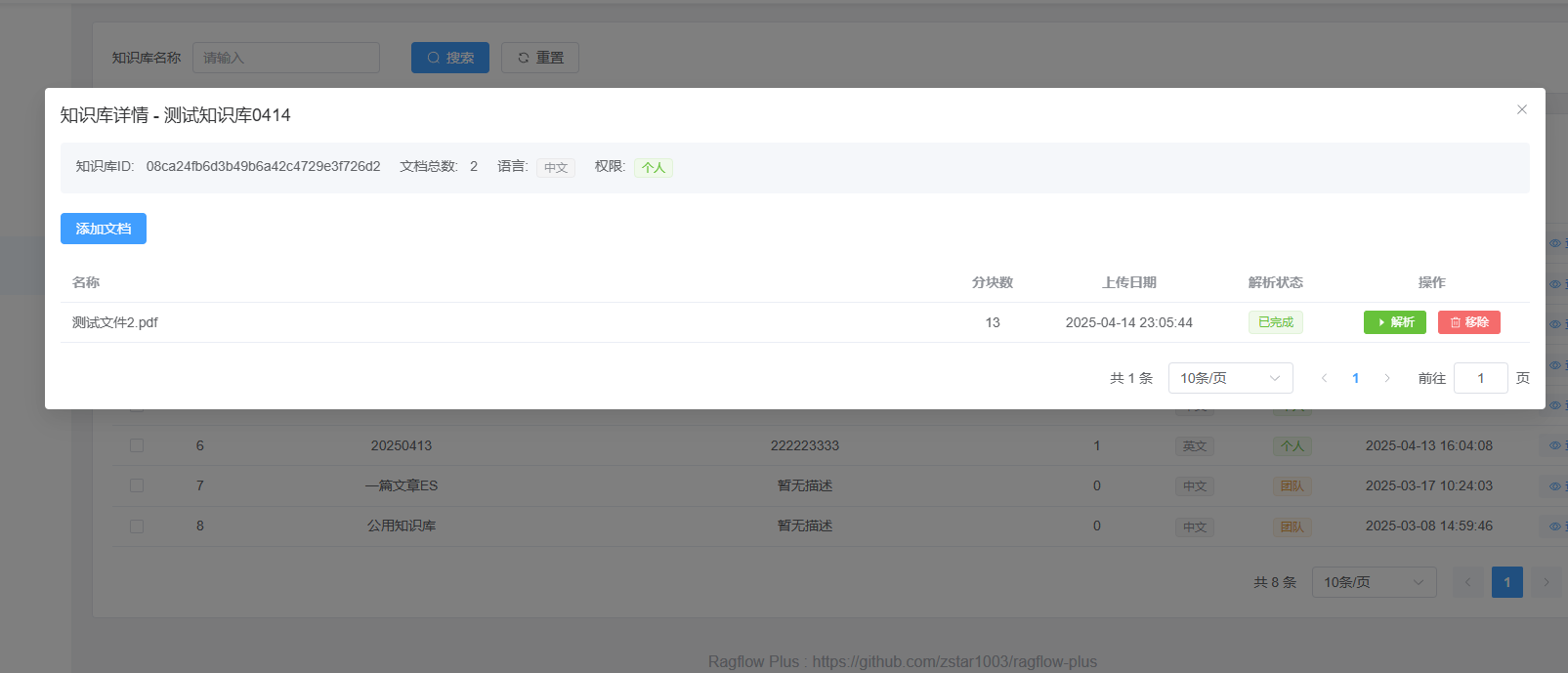
点击解析,默认采用 MinerU 对文件进行解析,如果是源码部署,需要参考往期文章,提前下载好解析模型。
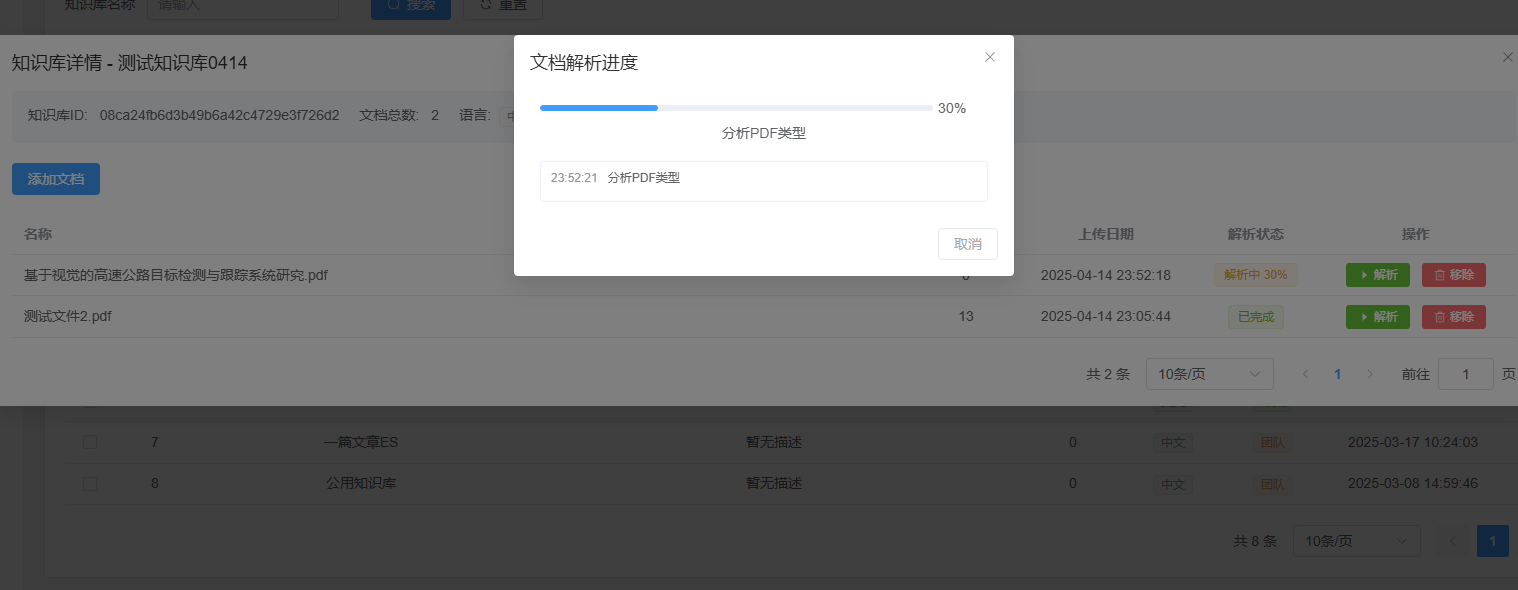
MinerU 解析的结果会形成文本块,直接可在系统主页的知识库里查看。
当前方案对解析结果进行了一定简化,并不会记录每一块内容在原始文档的位置。
因此,无法像原始的DeepDoc算法那样,对比原始文档位置查看。
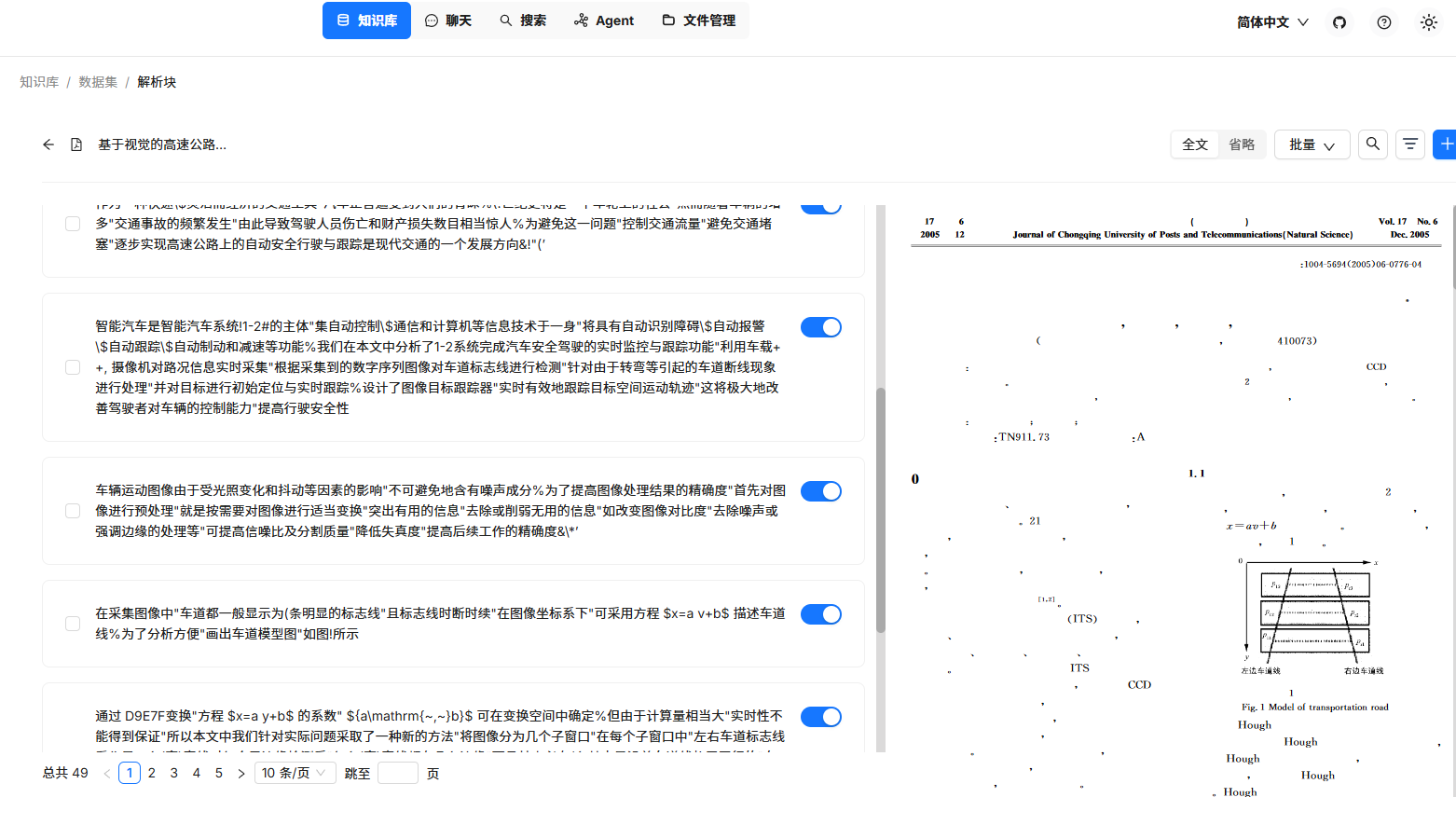
此外,当前版本并未对解析块进行embedding操作,因此解析块并不包含向量信息,做检索时,只能通过关键词匹配检索,此点后续会进行优化。
解析细节分析
解析是最复杂的内容之一,主要对应management/server/services/knowledgebases/service.py的parse_document函数,具体流程如下:
1.初始化阶段
- 建立数据库连接
- 查询文档基本信息
- 更新文档状态为"处理中"(status=‘2’, run=‘1’)
2.文件获取阶段
- 查询文件到文档的映射关系,获取文件ID
- 查询文件记录,获取存储桶信息
- 创建MinIO客户端并检查存储桶是否存在
- 从MinIO获取文件内容
3.文档解析阶段
- 解析配置处理
- 根据文件类型选择解析器
- 对PDF文件进行处理:
- 创建临时文件
- 分析PDF类型(OCR或文本模式)
- 处理PDF内容并提取文本和图像
4.内容处理与存储阶段
- 创建或确认MinIO存储桶
- 获取Elasticsearch客户端
- 确保Elasticsearch索引存在
- 处理文本块:
- 生成唯一ID
- 上传到MinIO
- 分词处理
- 索引到Elasticsearch
- 处理图像块:
- 读取图像内容
- 上传到MinIO
- 设置访问权限
5.更新数据库记录
- 更新
document表:- 状态更新为"已完成"(status=‘1’, run=‘3’)
- 更新进度为100%
- 更新块数量
- 更新
knowledgebase表:- 增加块数量
- 更新时间
- 创建
task表记录:- 记录处理信息
- 存储块ID列表
6.清理与完成
- 清理临时文件和目录
- 返回处理结果
解析过程中,有一些小细节需要注意:
在MinIO中,每个桶的名称对应的是知识库的id:
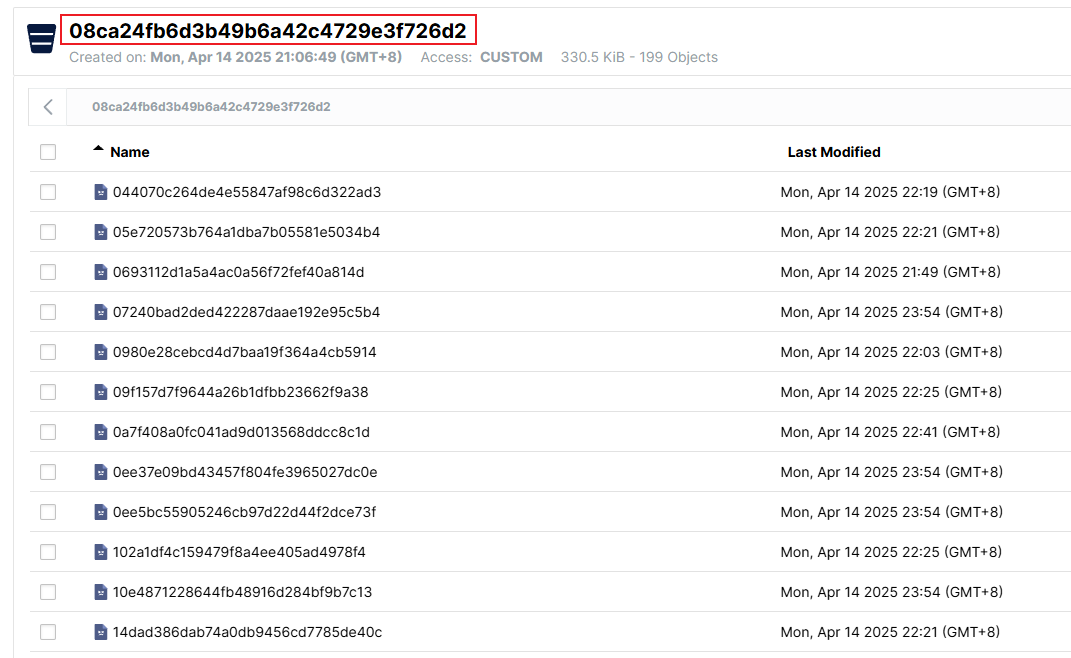
而在Elasticsearch中,每个索引后面的id对应是租户(tentant,即知识库所有者)的id。
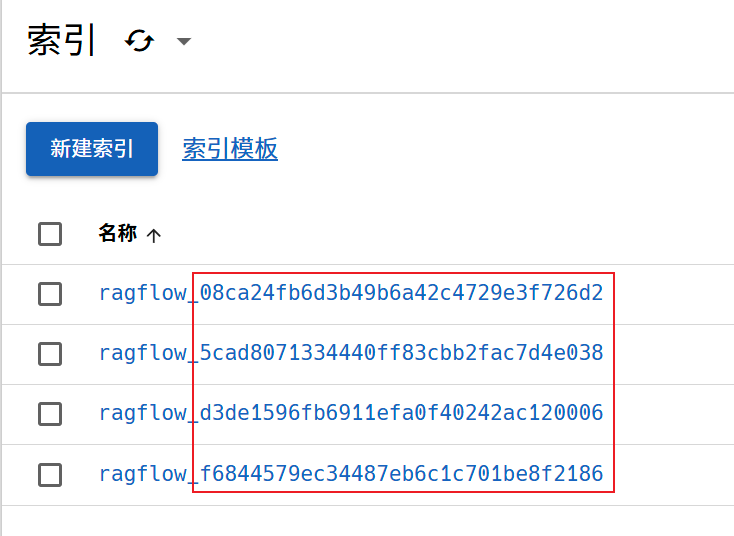
在知识库解析块可视化界面,通过v1/chunk/list接口获取响应信息,每一个解析块,索引文本(关键词,摘要,embedding_1024维度数值)存放在 es 中,内容文本存放在 minIO 中。
解析对比效果
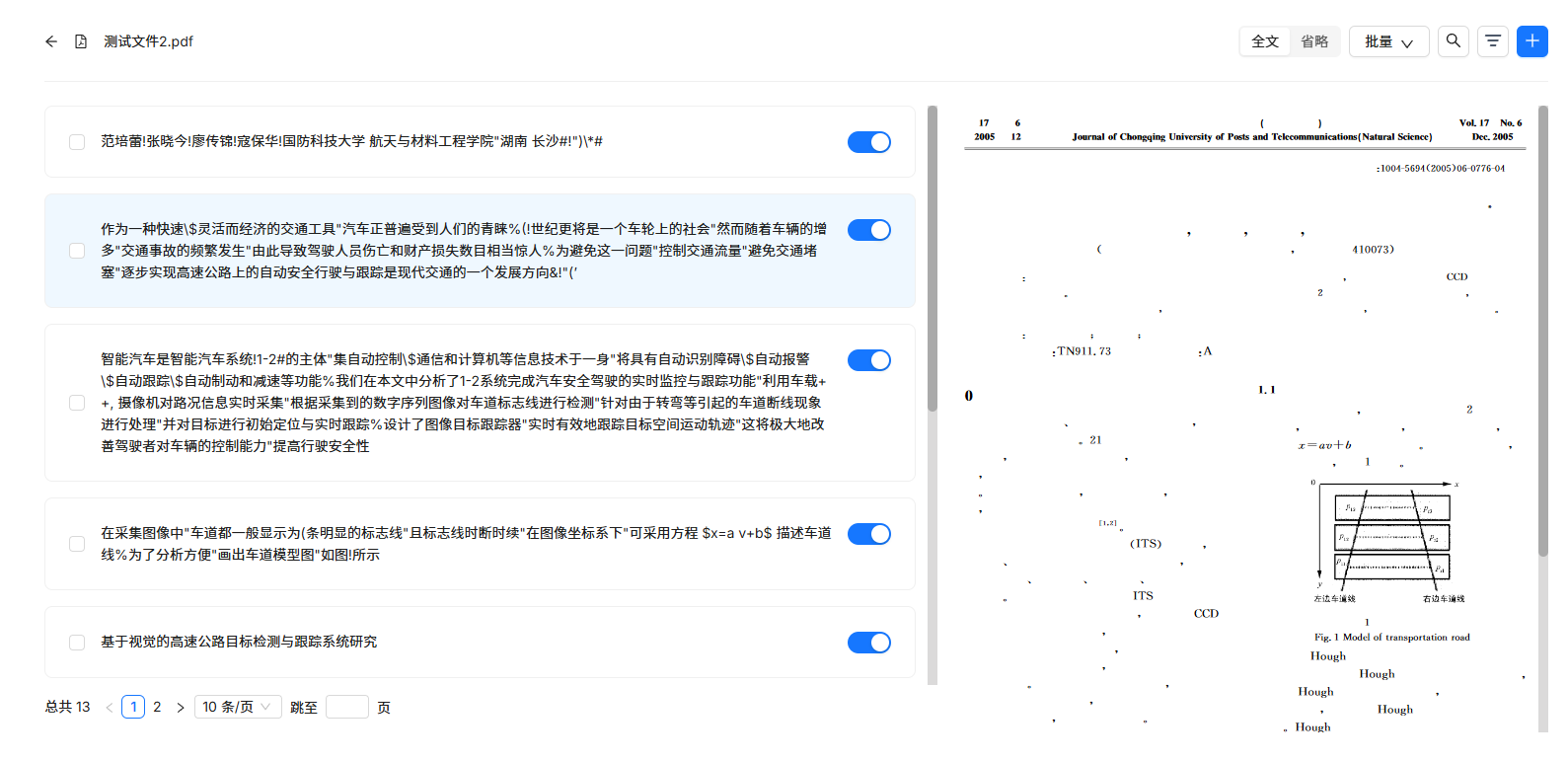
测试时,用了一份知网上下载的论文,有趣的是,这篇论文正常打开没问题。

而通过DeepDoc解析时,出现了如下图所示的情况,右侧预览图大块区域显示不清,导致解析面目全非。
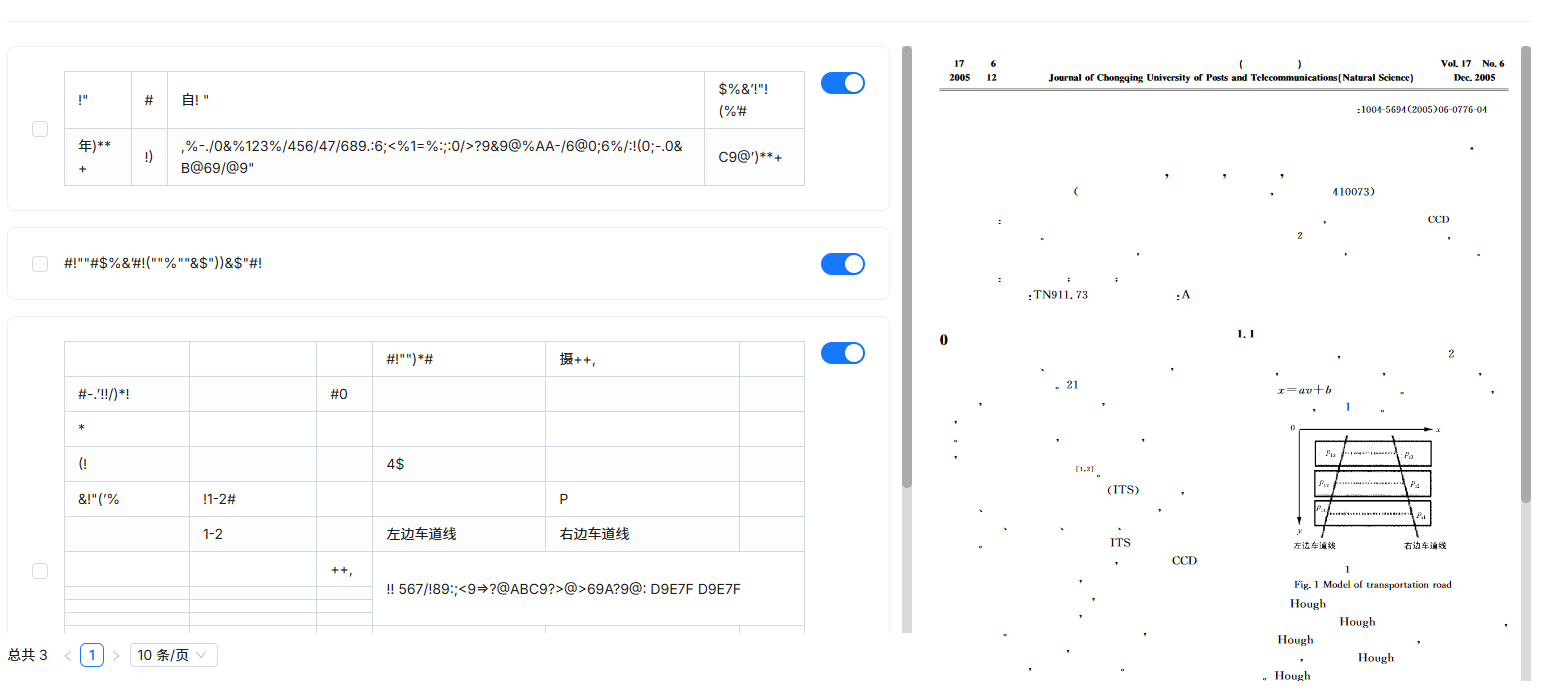
而 MinerU 采用了自己的文件读取接口,并未受到文件质量的影响,解析出大致正确的文本。
图片访问探索
下面进一步探索很多读者关切的问题:“如何让大模型回答能够输出知识库的图片?”
这个问题其实可以分解成以下三个子问题:
-
1.图片存在哪里?
-
2.如何输出图片?
-
3.如何把解析块和图片关联在一起?
前两个问题,已经大致解决。
1.图片存在哪里?
由于 MinIO 本身高性能的对象存储系统,除了存储文本和解析块之外,当然也可以存储图片。
因此,可以直接借助其接口,实现图片文件的上传,而无需另外单独构建一套图床系统。
由于 MinerU 可以把解析的图片保存下来,因此,在前面的解析过程中,已经包含了图片上传的过程。
2.如何输出图片?
上传完图片后,可以通过以下脚本查询图片的外链信息。
脚本:对应仓库中的management\server\get_minio_image_url.py
import os
import sys
import argparse
from minio import Minio
from dotenv import load_dotenv
# 加载环境变量
load_dotenv("../../docker/.env")
def is_running_in_docker():
# 检查是否存在/.dockerenv文件
docker_env = os.path.exists('/.dockerenv')
# 或者检查cgroup中是否包含docker字符串
try 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











