







概述
在此版本中,Ragflow-Plus进一步完善了MinerU解析器,并支持图文关联输出功能。
同时,对系统架构进行一些小调整,前台系统构建了单独的docker镜像。
Ragflow-Plus 开源地址:https://github.com/zstar1003/ragflow-plus
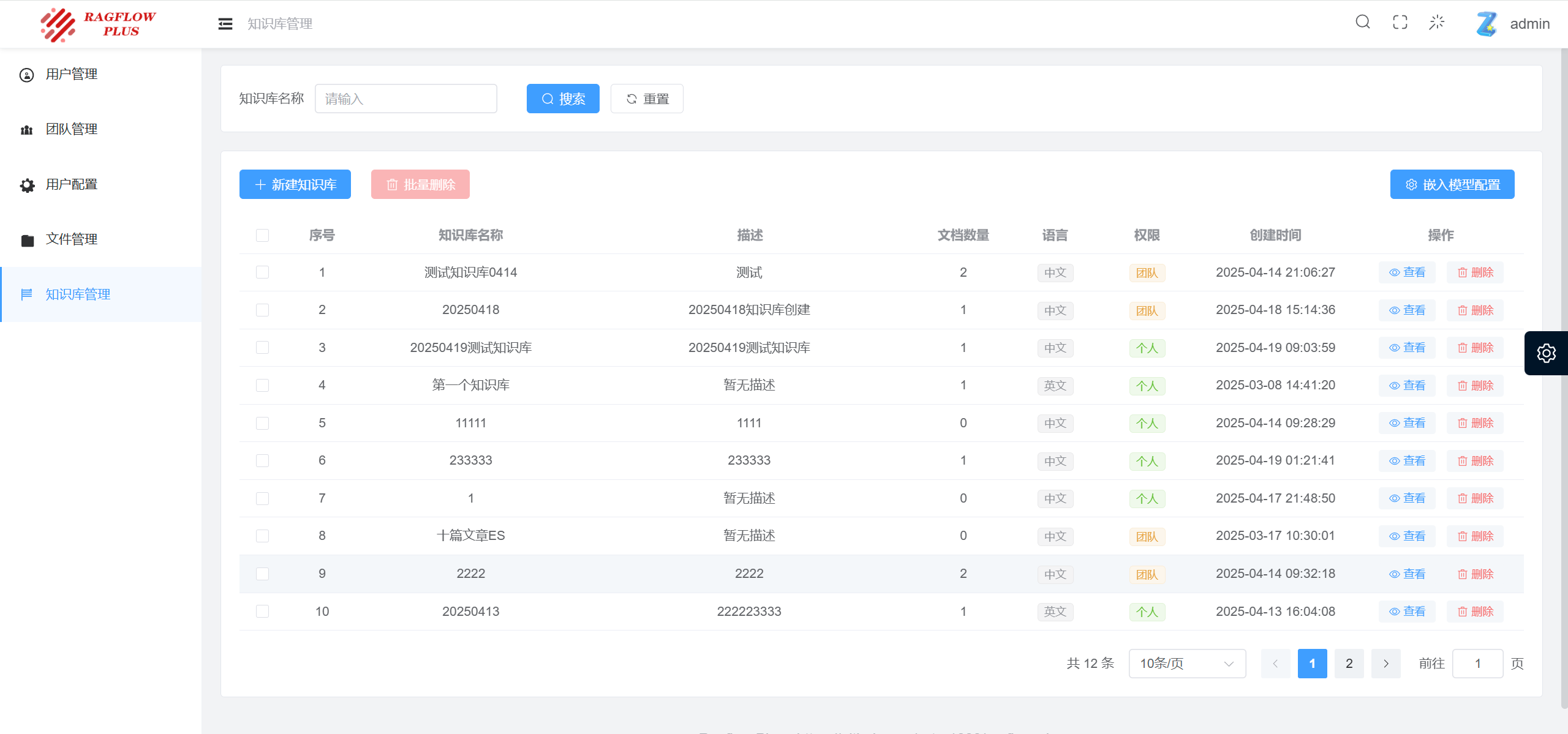
容器结构分析
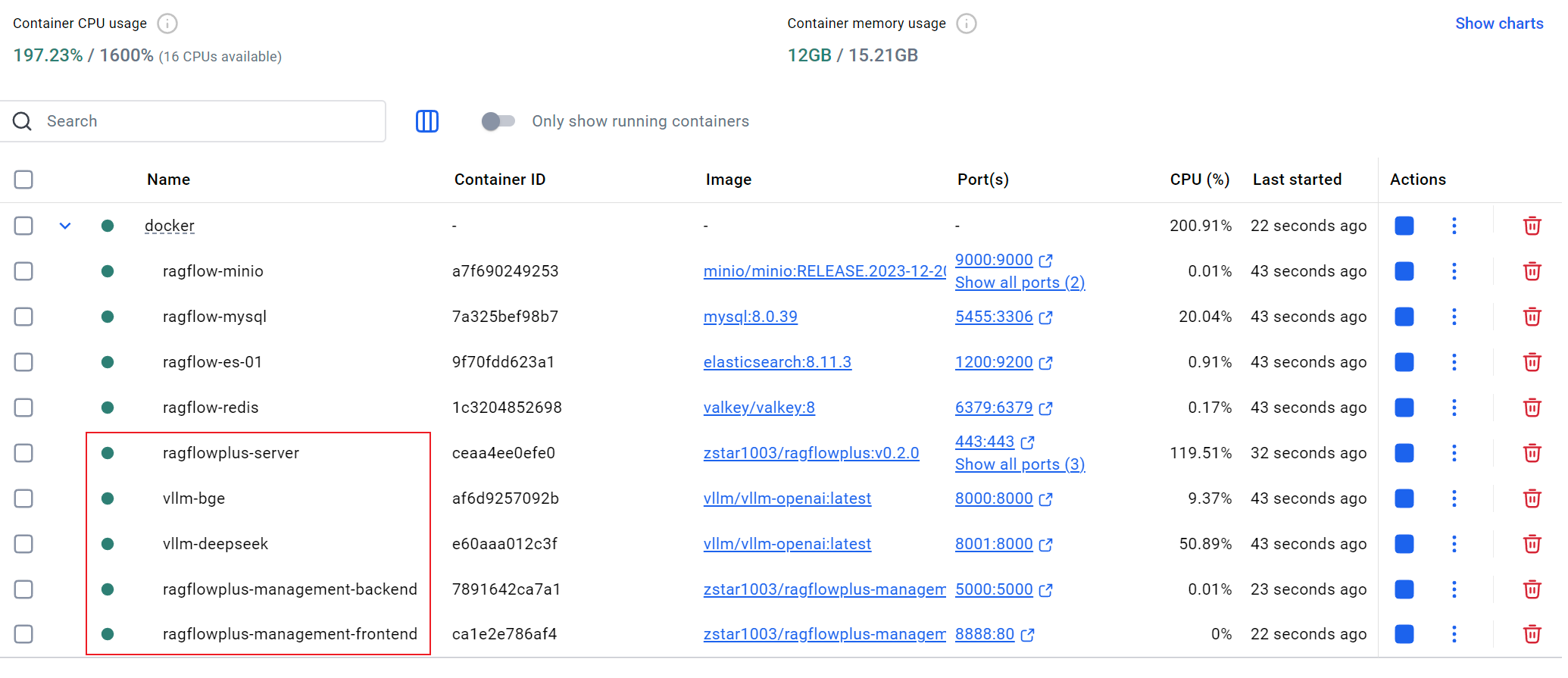
目前,整个共9个容器,minio、mysql、es、redis为基础容器。
ragflowplus-server为前台系统,vllm-xxx为vllm框架下的编码/语言模型推理容器,ragflowplus-management-xxx为后台管理系统的前后端。
所有容器运行起来需占用至少12GB内存。
对于后台管理系统后端镜像,由于集成了MinerU的各种模型,并内置了安装了LibreOffice用于将office文件数据转换成Pdf,整体体积会较大,约6.14 GB。

Docker运行方式
对于docker部署的用户,可以参照以下方式进行部署:
1.克隆仓库源码
https://github.com/zstar1003/ragflow-plus.git
2.准备embedding和chat模型
参考上一篇文章内容,下载需要部署的模型,放在docker/models路径下:
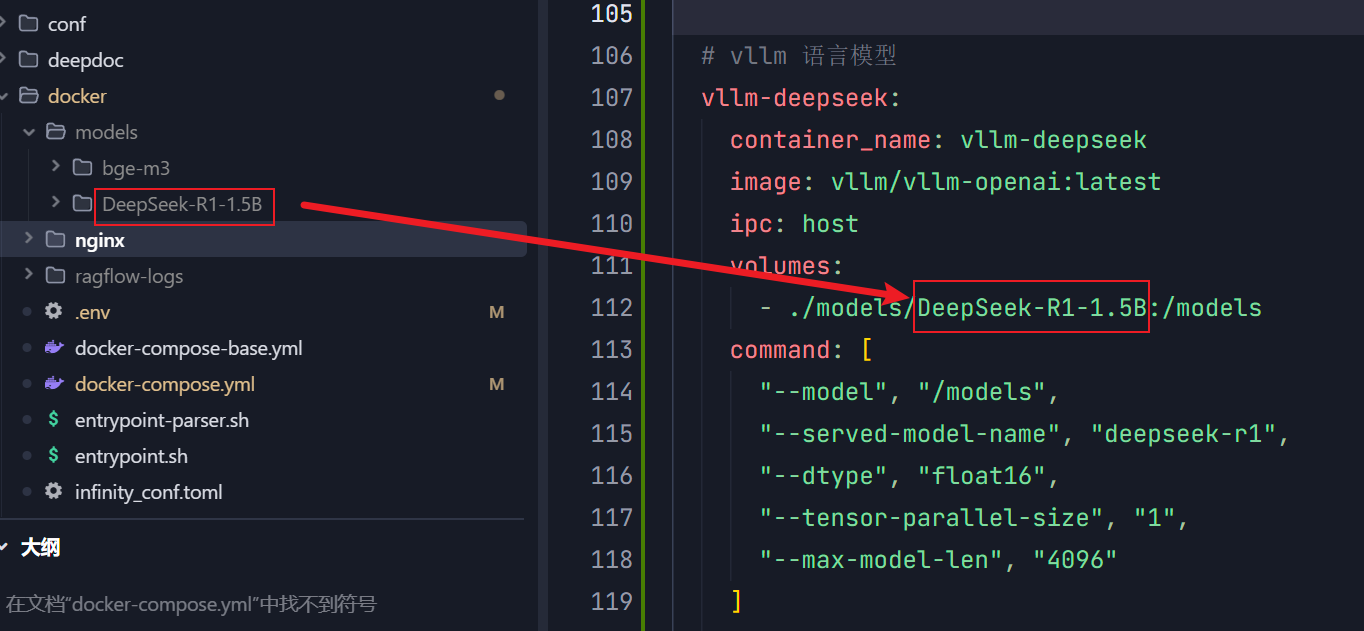
同时对应修改docker-compose.yml文件,模型的volumes参数和文件夹名称对应,served-model-name和后面在前台系统配置时的名称进行对应。
command对应了一系列vllm框架的参数,比如模型精度、多卡配置等参数,可根据vllm文档描述进行修改填充。
3.启动容器
在项目根路径下,执行:
docker compose -f docker/docker-compose.yml up -d
所有容器正常运行后,
- 访问"服务器ip:80",进入前台系统
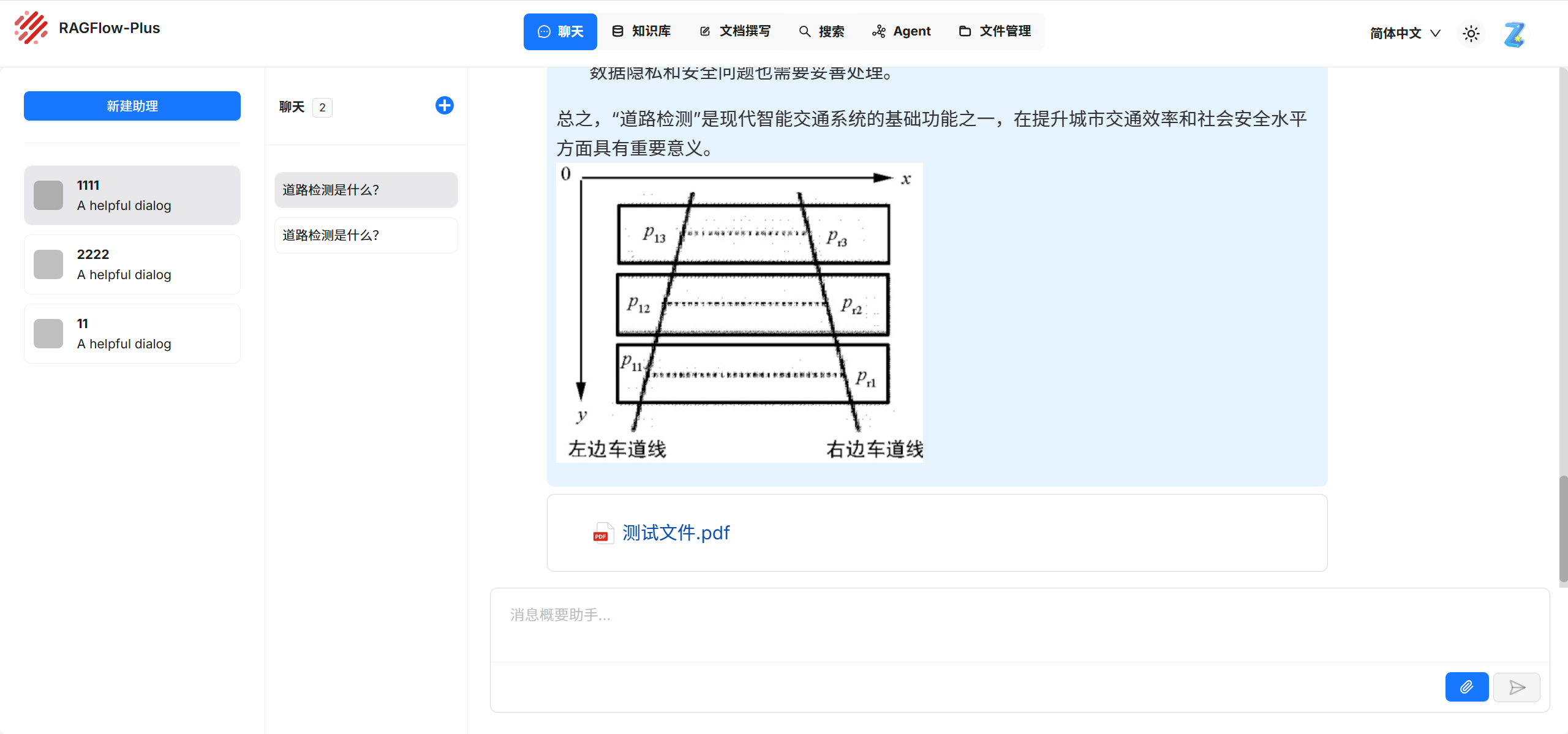
- 访问"服务器ip:8888",进入后台管理系统
新增功能简介
下面介绍本次发布版本的两个特色功能:完全体的MinerU解析和图像生成功能。
完全体的MinerU解析
1.概念界定
为什么叫完全体的MinerU解析?
之前的文章中写过用对接API的方式将MinerU解析的结果插入知识库,但这样并不是一个完整的解析策略。
因为并没有对文本块进行编码,这会导致模型在检索时,只用到关键词的匹配策略,而没有用到向量匹配,造成检索性能下降。
在此次更新中,进一步对文本块的内容进行编码,具体使用方式如下所述。
2.使用方式
1.配置管理员用户的模型参数
在后台管理系统中,默认第一个创建的用户为管理员用户。
也就是说,包含“上传文件”、“新建知识库”、“解析模型参数”都是以创建时间最早的用户作为主体的。
要解析文件,首先要在前台用管理员用户进行登录。
在模型提供商菜单中,选择vLLM模型:

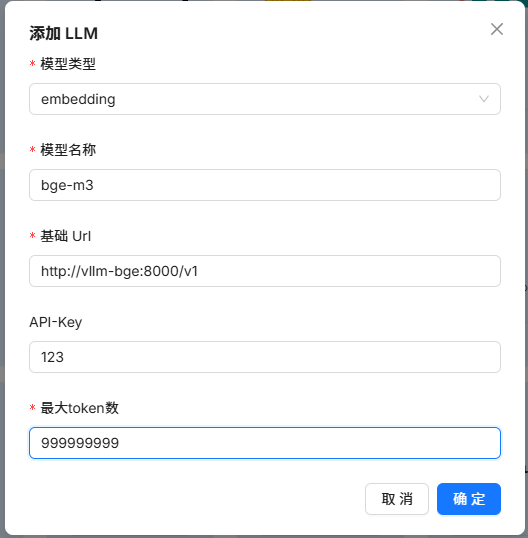
配置embedding模型:
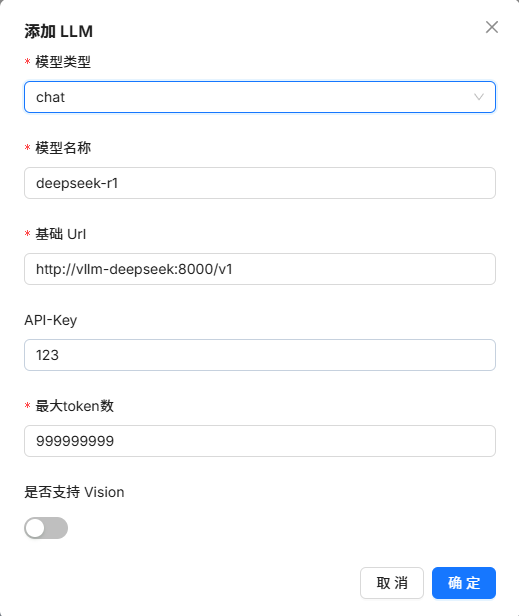
这里顺带可以把chat模型一块进行配置,尽管解析并不需要chat模型:
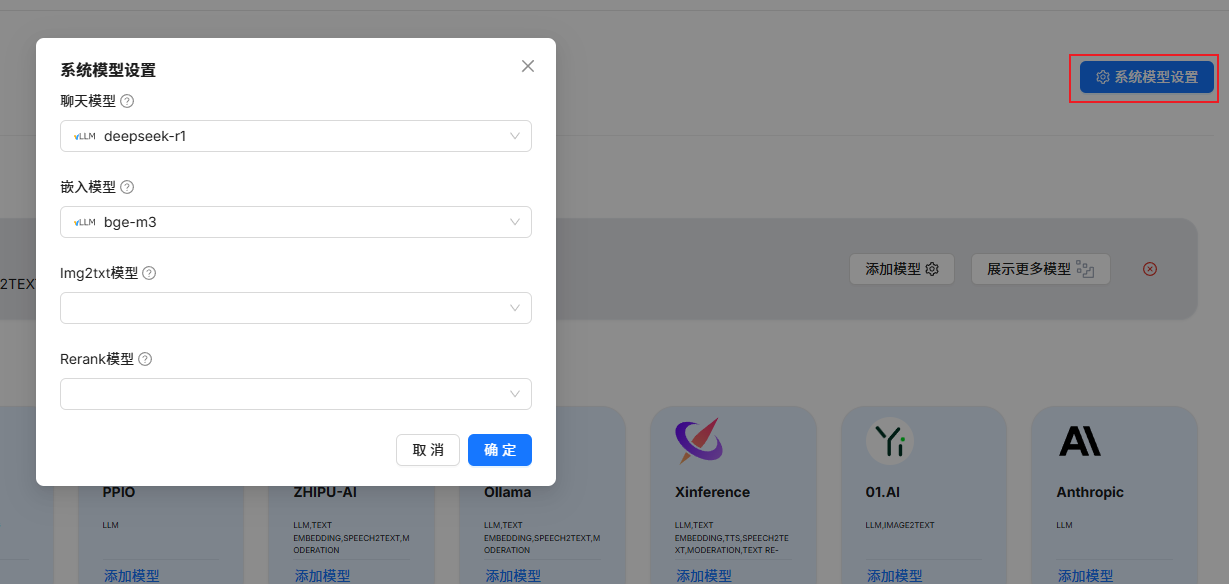
配置完成后,在系统模型设置中,设置添加的两个模型:
2.嵌入模型连接测试
前台配置完之后,进入到后台。
在知识库管理菜单中,点击嵌入模型配置,弹窗会自动补全在上一步中的填充信息,点击测试连接,可在解析前,测试嵌入模型是否能正常工作。
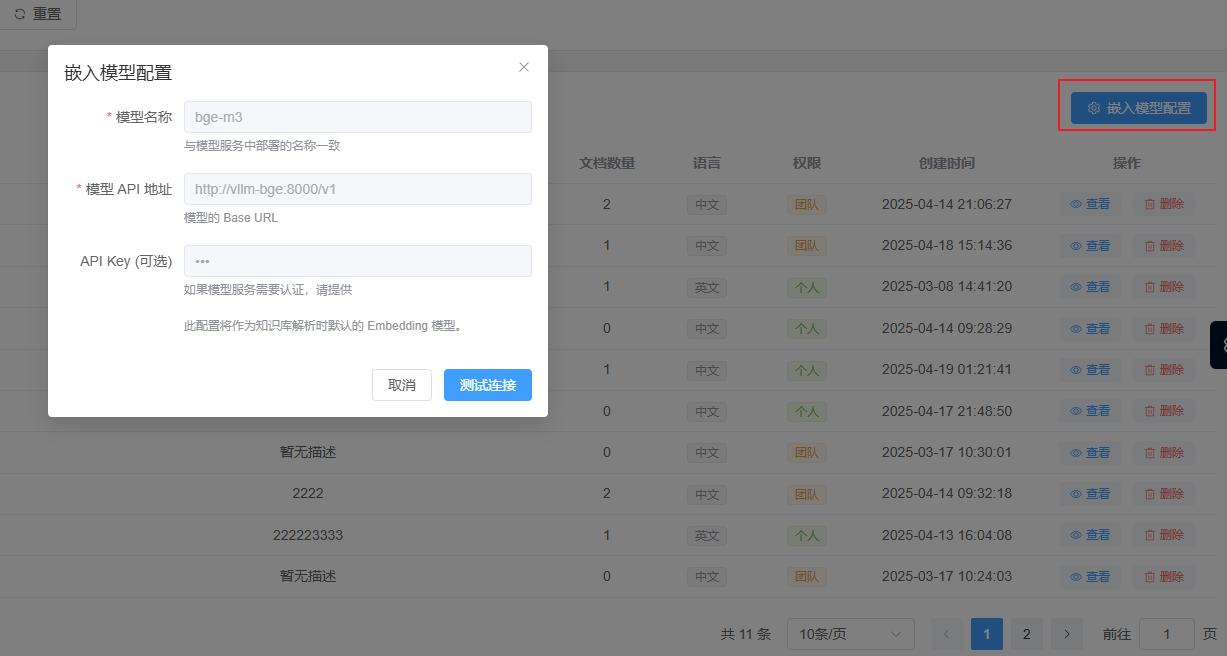
如果嵌入模型连接无误,可进入到下一步的文件解析。
3.文件解析过程
点击知识库的查看按钮,可在此界面将文件添加进单独的知识库。
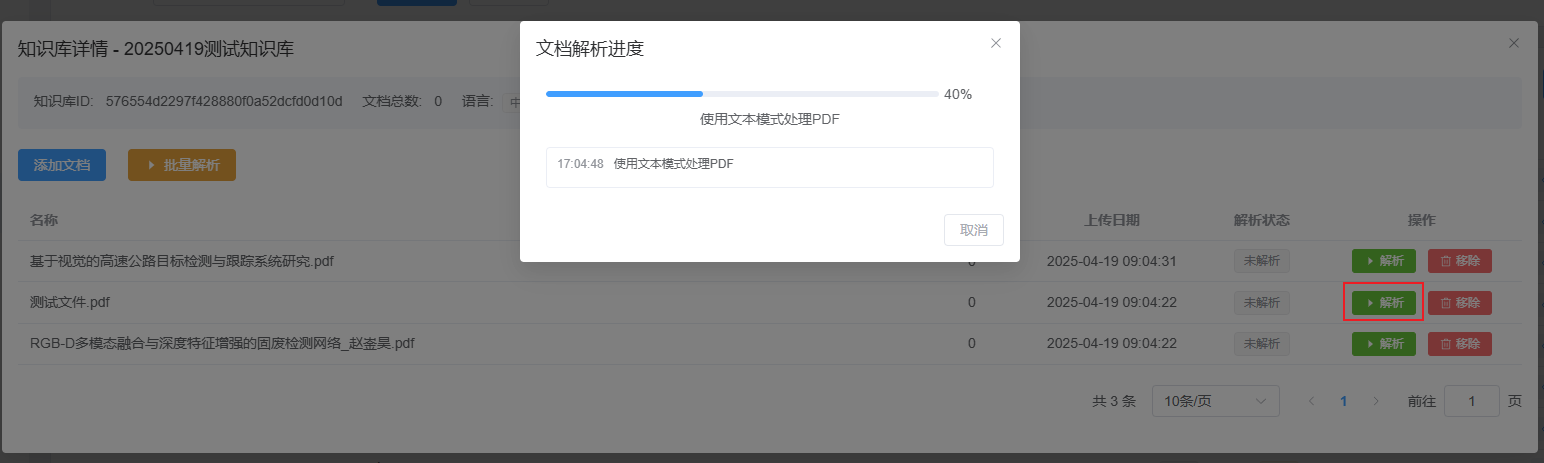
对于每个添加进知识库的文件,可以进行单独的解析和移除。
点击解析,会出现单个文件的解析进度和运行情况。
当然,文件多时,一个个点太麻烦了。
因此,提供了一种懒人解手的批量解析方式。
点击批量解析按钮,系统会在当前知识库内,自动查找所有未解析的文件,执行批量解析。
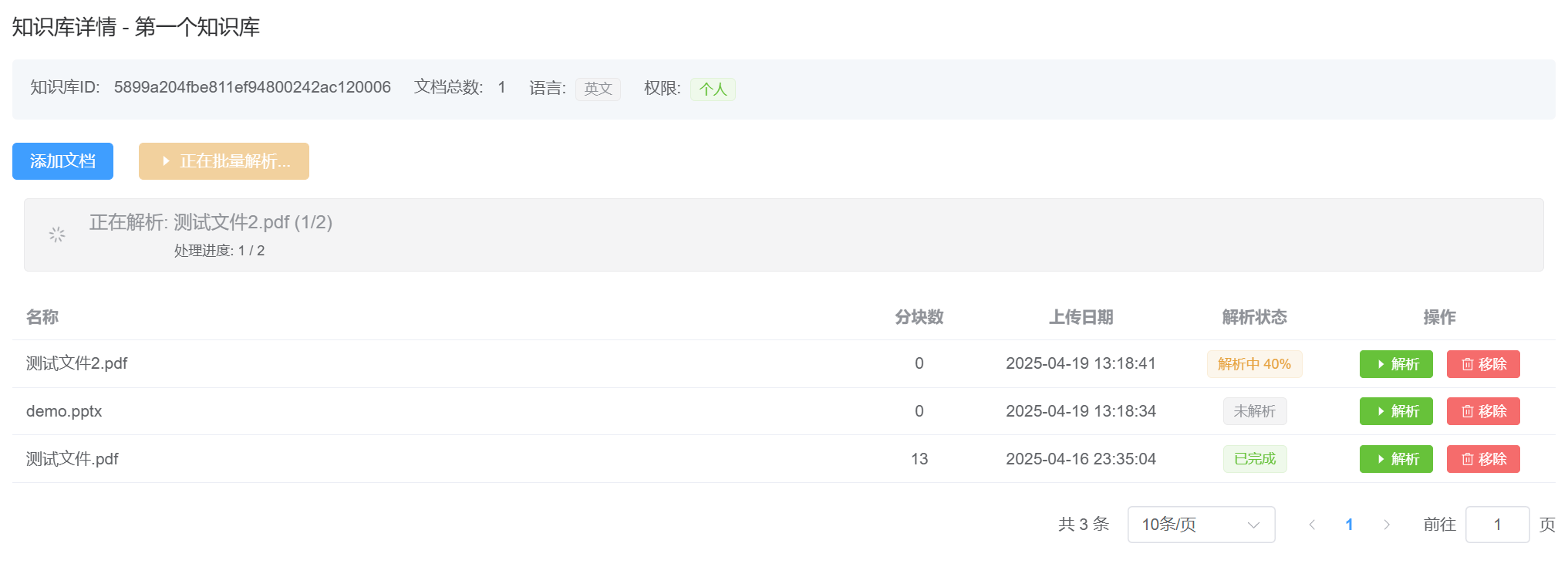
不同于ragflow原生的多线程并发解析方式,这种批量解析会依次对每个文件进行处理,一个文件解析完成后,才轮到下一个文件。
因此,这种方式不会造成解析一半,卡住的情况。
不怕慢,只怕停。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1560
1560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











