




今天凌晨,Google 正式发布 Gemini 3 Pro。
这款模型外界可谓期待已久,因为之前它在某些第三方平台有盲测版本,效果据说非常好。
本文来实际体验一下。

性能指标
它的技术报告[1]中没有披露具体的技术细节,但是公布了评测指标结果。
Coding能力是这款模型最大的亮点,数据表明,相比于2.5 Pro,3 Pro 有 20% 以上的提升,提升效果非常明显。
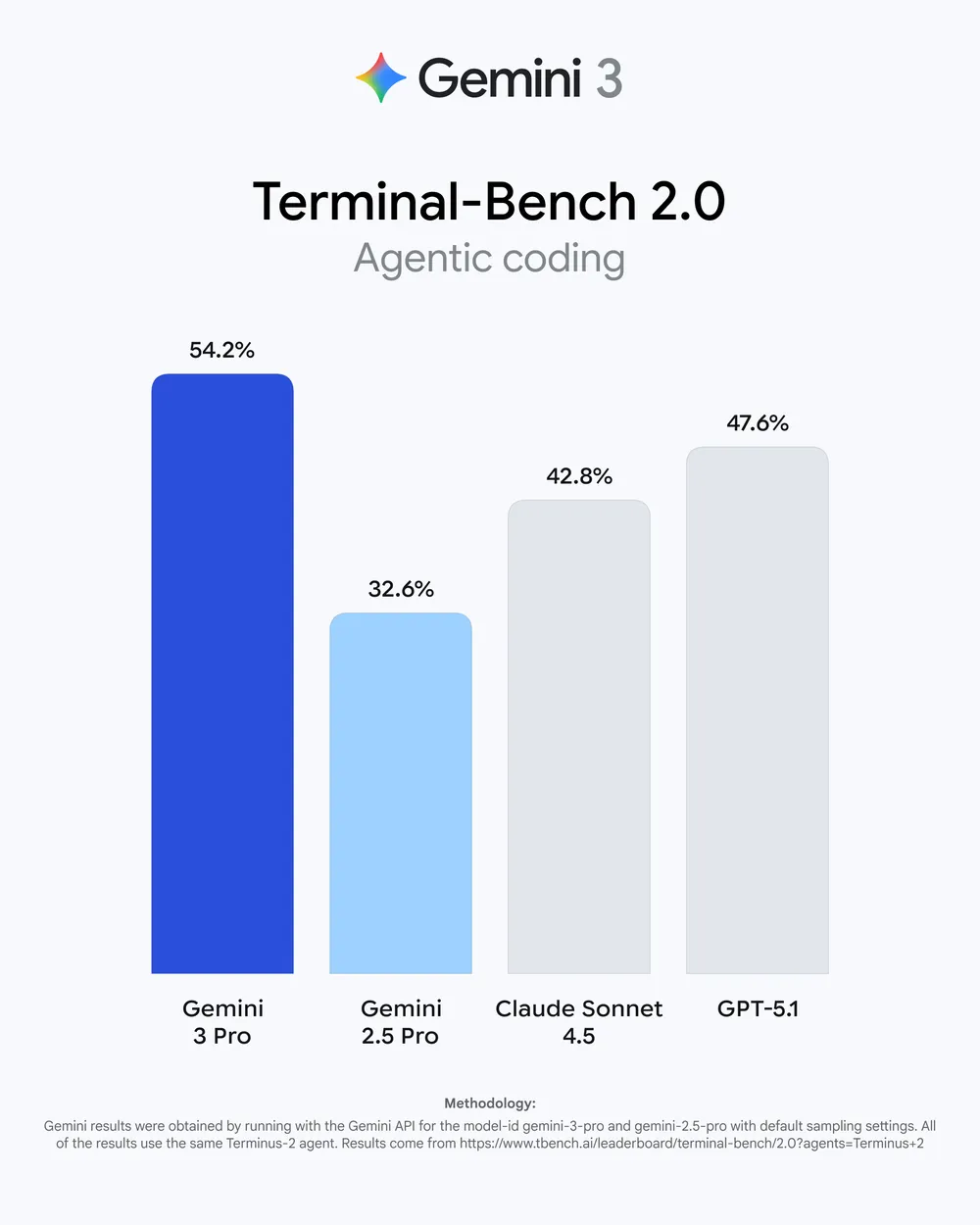
再看各领域的数据集,和其他模型相比,数值完全是“碾压”式的,所有领域都达到了SOTA。
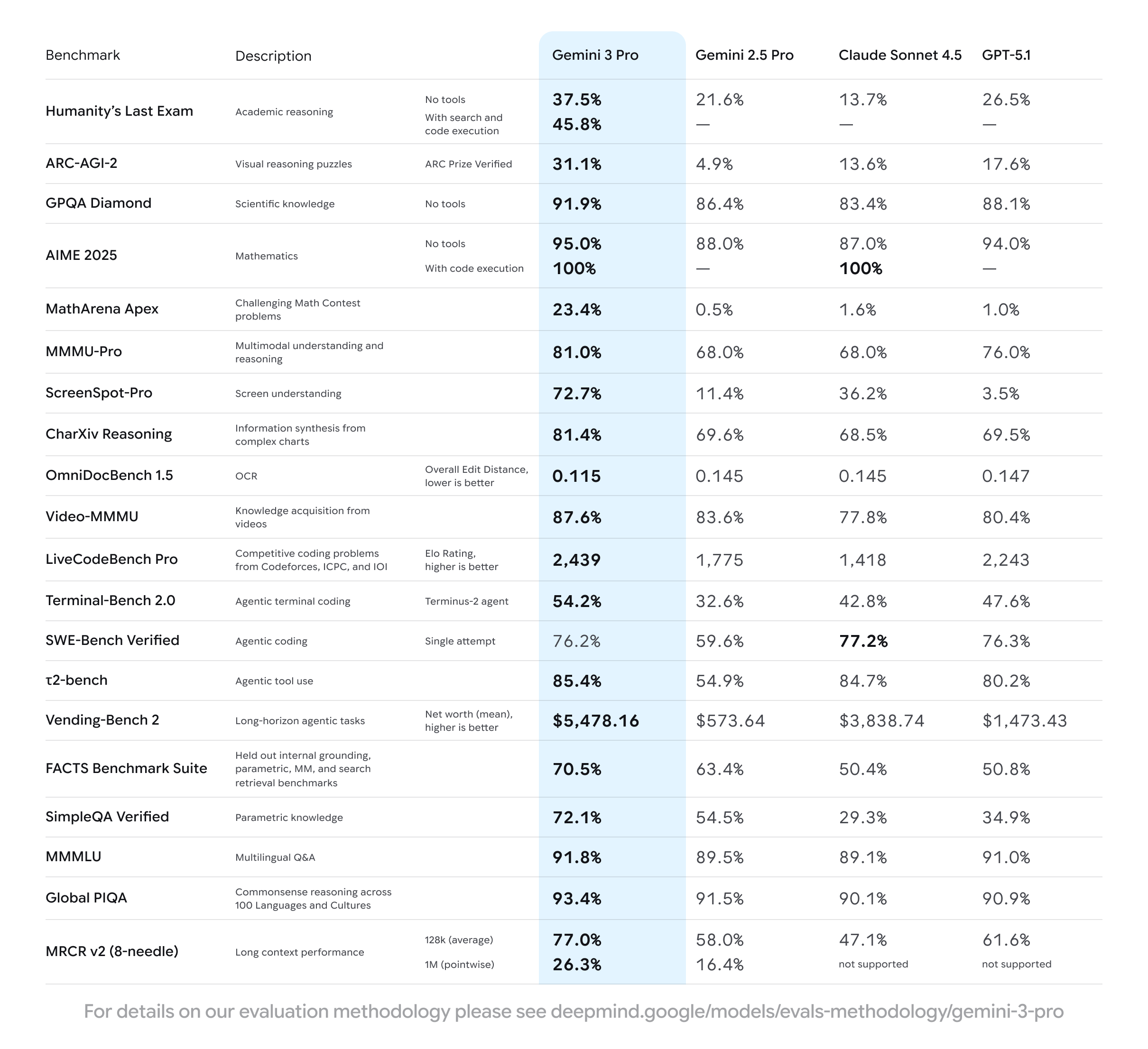
效果表现
下面来看一下 Gemini 3 Pro 具体的 Coding 表现。
在 Google AI Studio[2] 中,可以用 Build 模式,用该模型快速构建出一个 React 应用。
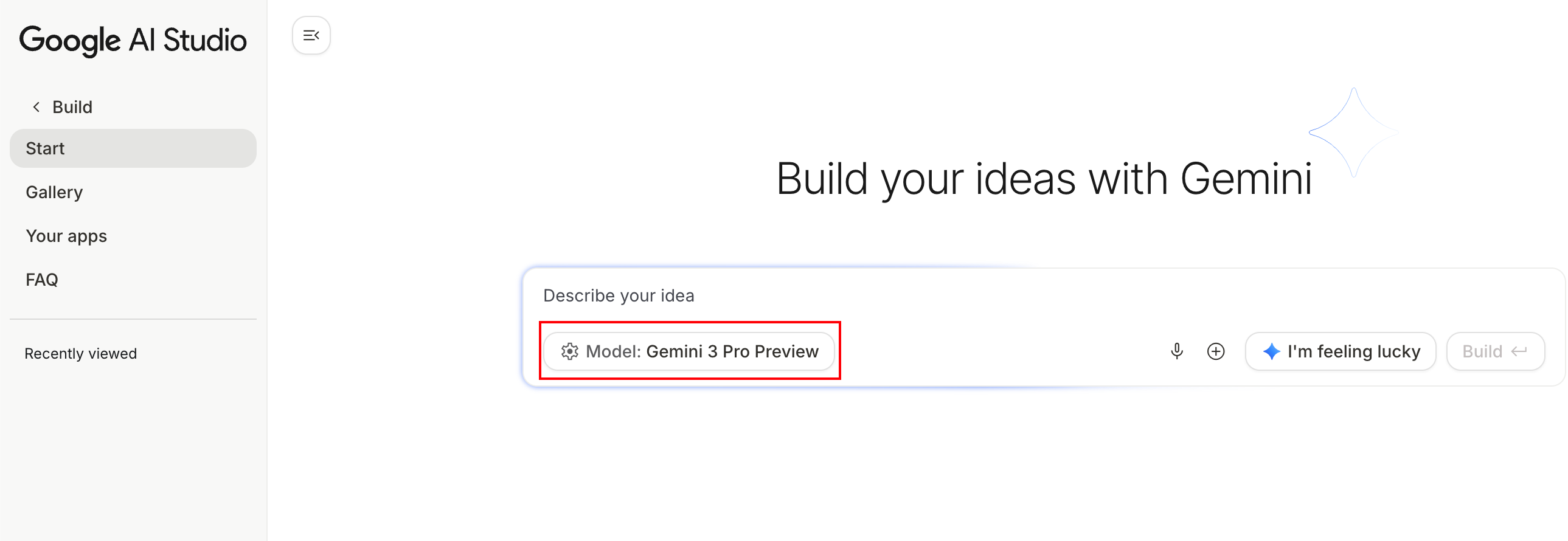
首先看一下画廊里的一些示例:
产品官网,它现在能够生成更加丰富美观的视觉效果。

物理碰撞模拟,没什么难度。
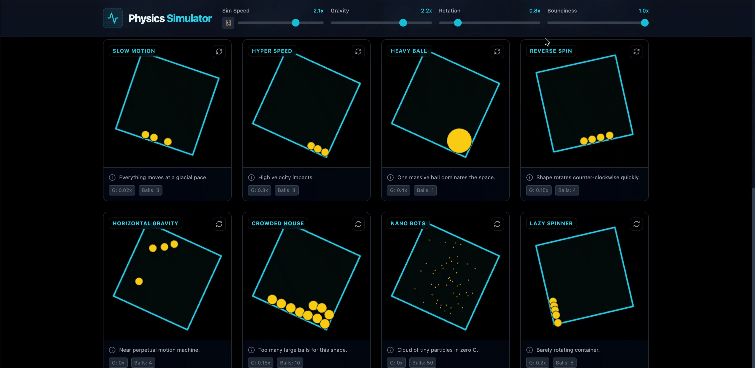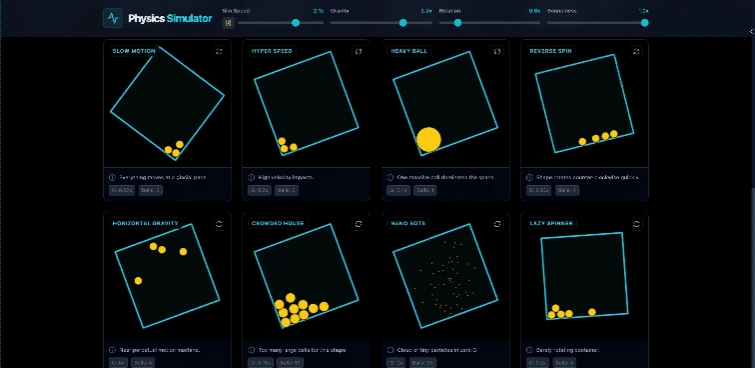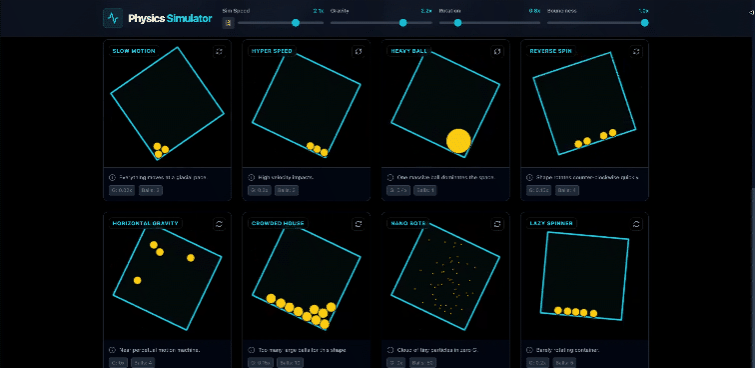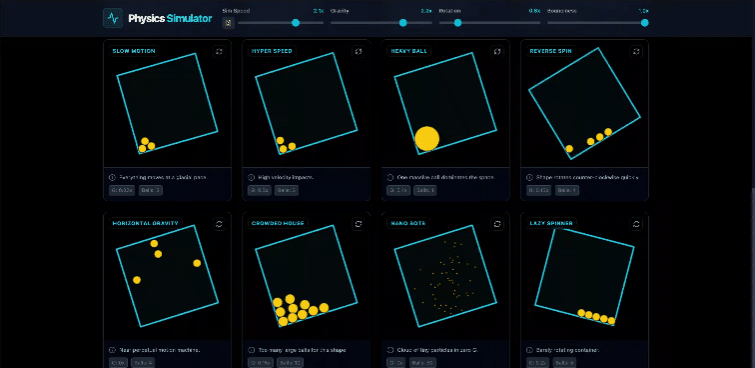
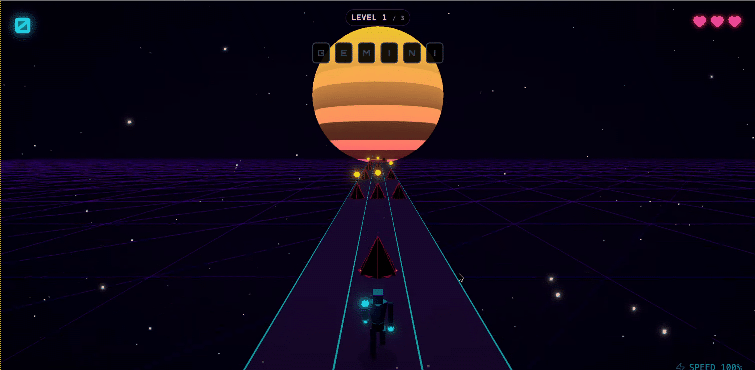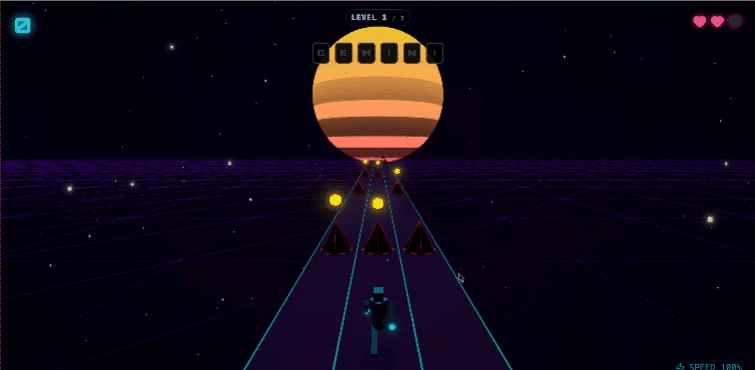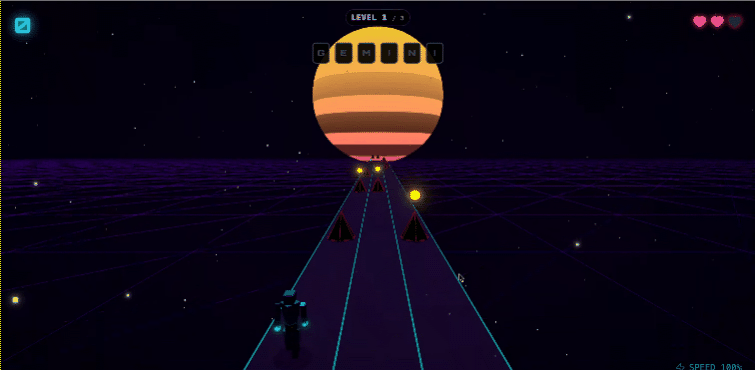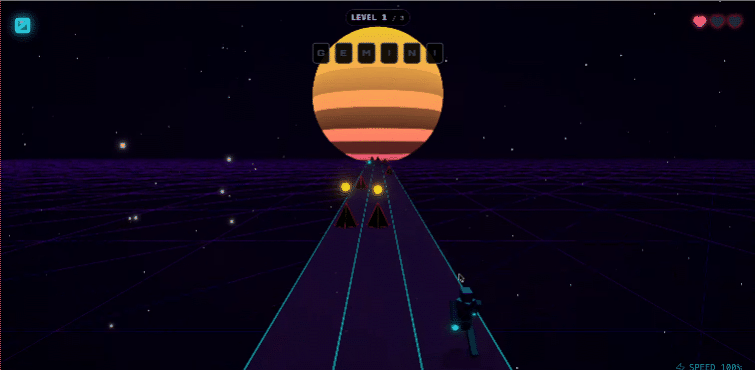
甚至可以直接搓一个网页跑酷游戏。
具体测试
看完演示,下面来具体测试一下。
首先让它写一个类chagpt的chatbot。
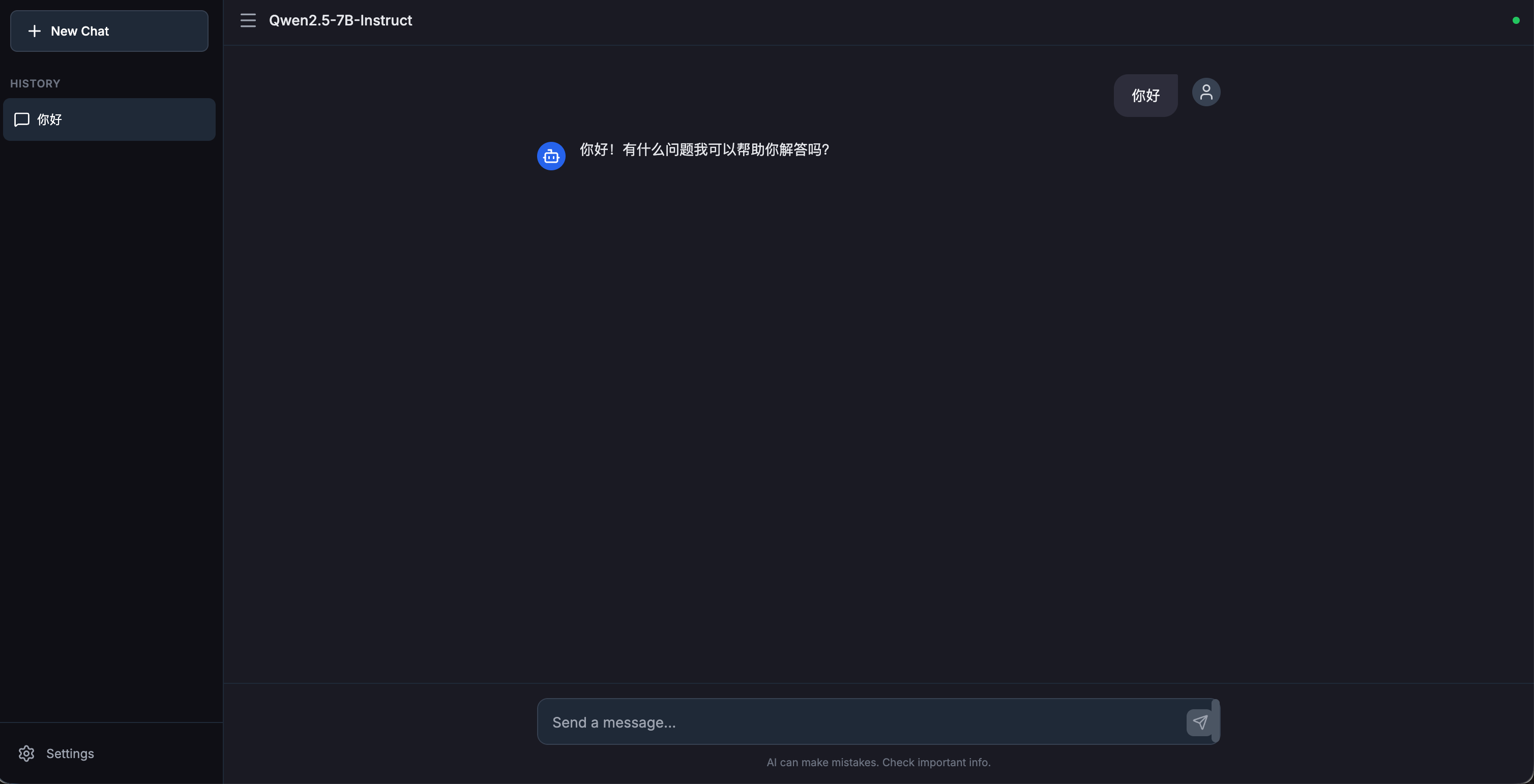
它很快就写完了,一遍过,功能也正常。这道题之前也测试过其它模型,它的美观度是目前看下来最好的。
下面再让它做一个枪战FPS小游戏,我提示词写得很简单,它做出来的版本有点像红白机上面的小游戏。
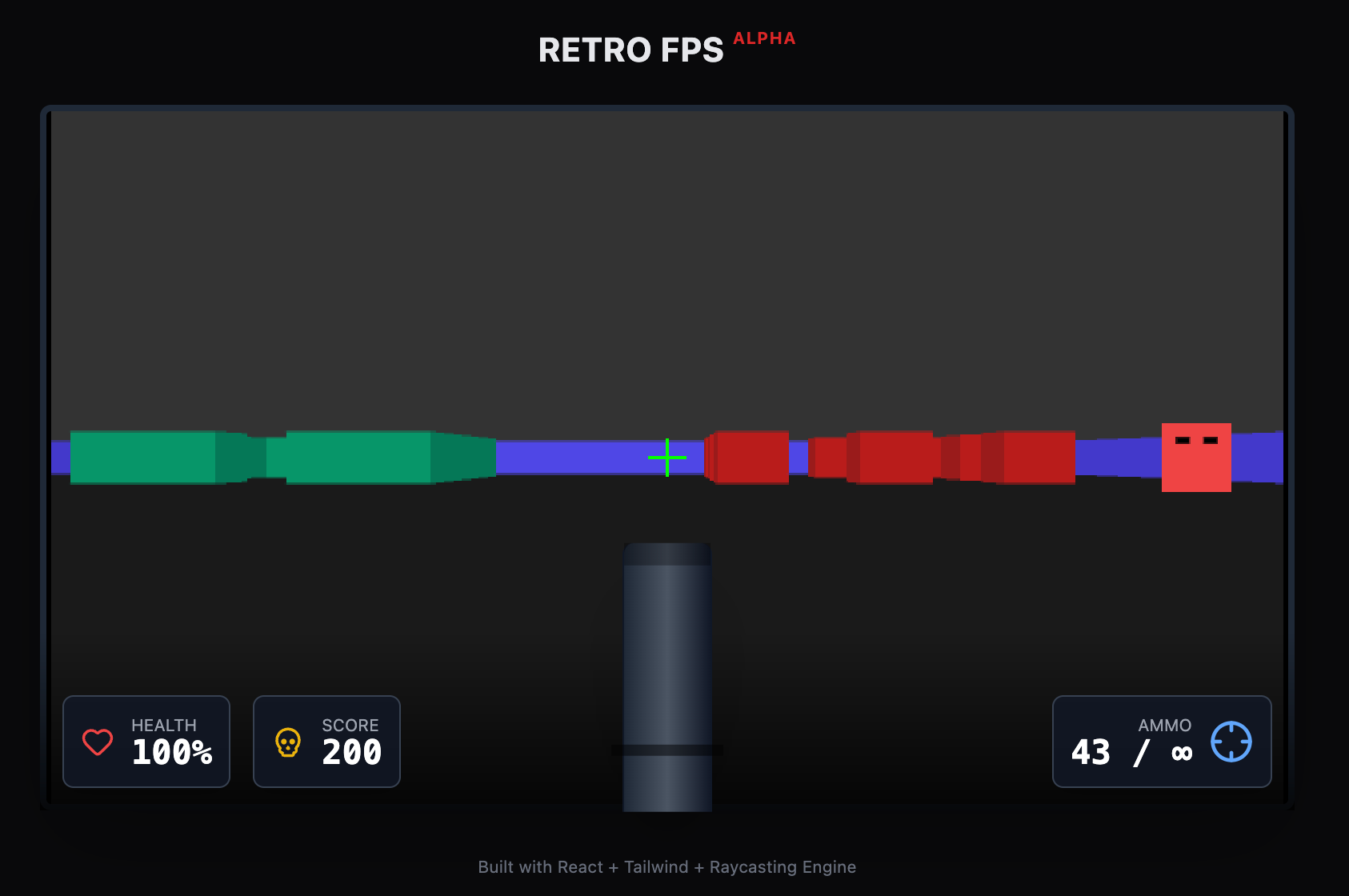
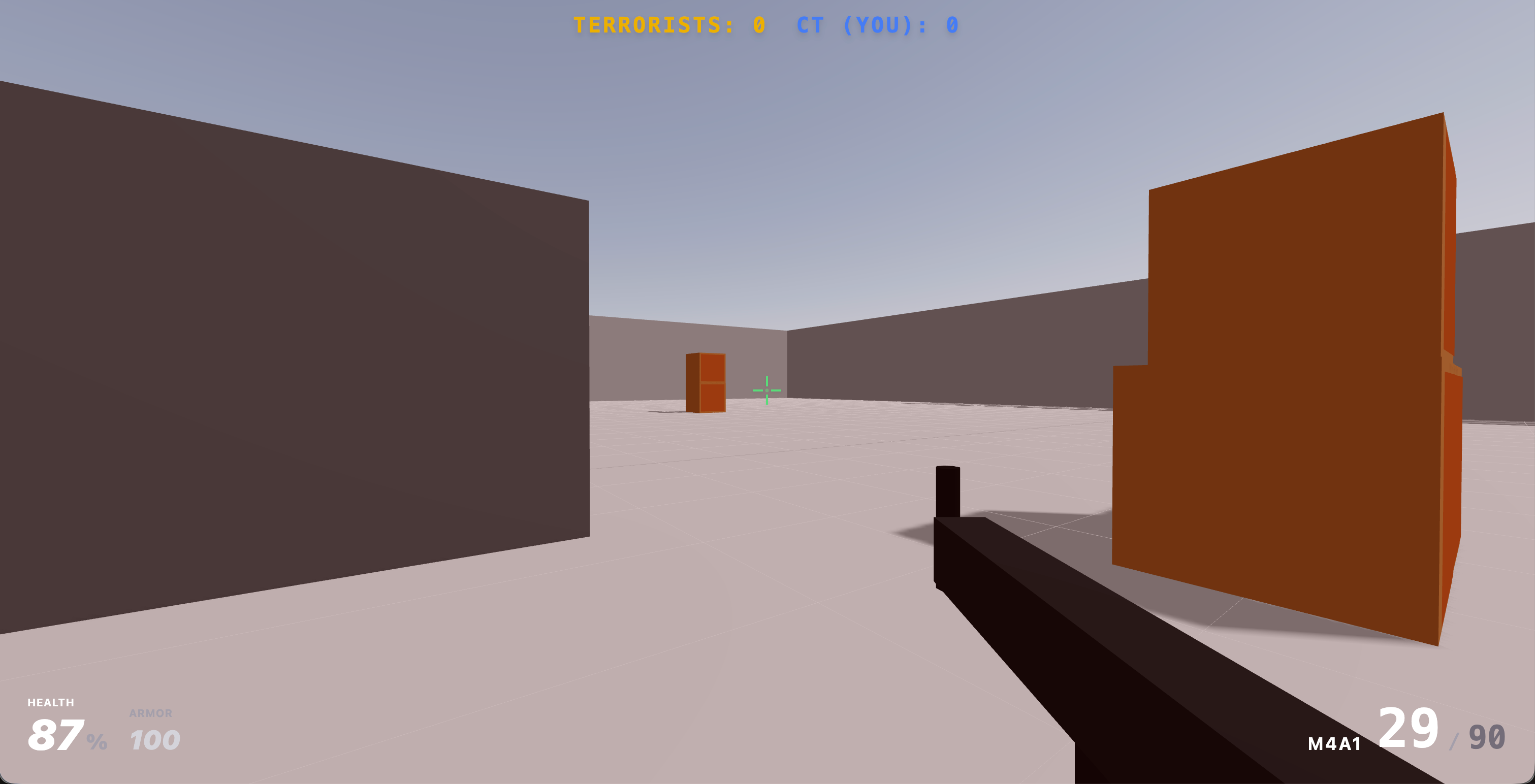
再让AI帮我丰富一下提示词,它做出来了一个枪战demo,画面风格很像UE的模板场景,碰撞、射击、跳跃等功能均正常。
新的IDE
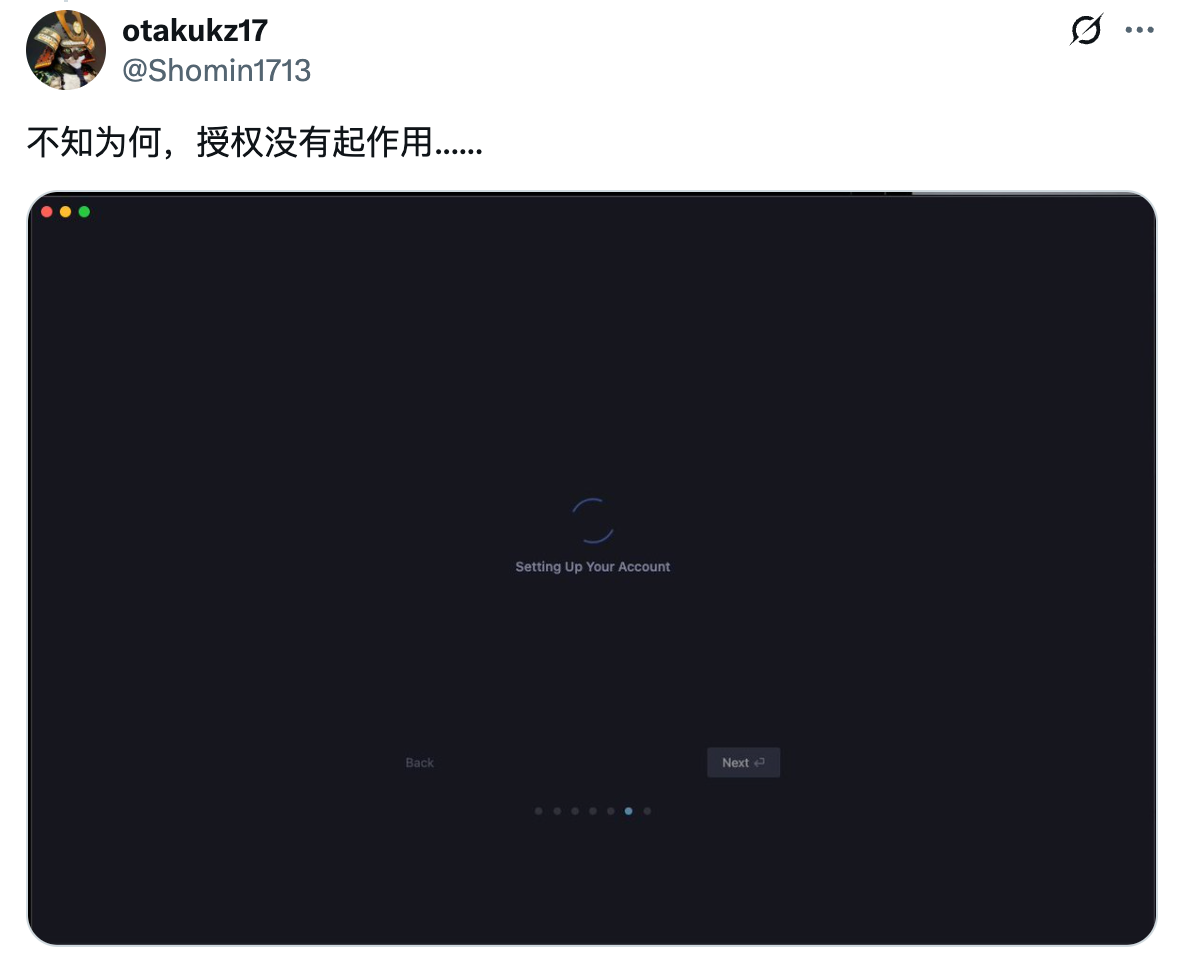
此外,Google 还发布了一个agent IDE,叫做antigravity[3],我第一时间下载了一下。
但目前登录存在问题,无法授权登录,看了下论坛,估计是官方还没正式开放,也有可能是受到cloudflare挂掉的影响。
等修复之后,后面再测试一下该模型的后端能力。
总结
Gemini 3 Pro 没有让人失望,尤其是其前端能力,再次得到了进化。
这款模型的提升幅度可谓是断档式的,而且 Google 的 Token 额度一贯给得很大方,Vibe Coding 迎来黄金时期了。
参考
[1] https://blog.google/technology/developers/gemini-3-developers
[2] https://aistudio.google.com
[3] https://antigravity.google/product



















 7510
7510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











