







实战
https://v3-1.docs.kubesphere.io/zh/docs/
多租户系统
点击 页面——访问控制
对平台中的企业空间、帐户、以及角
色权限进行统─管理
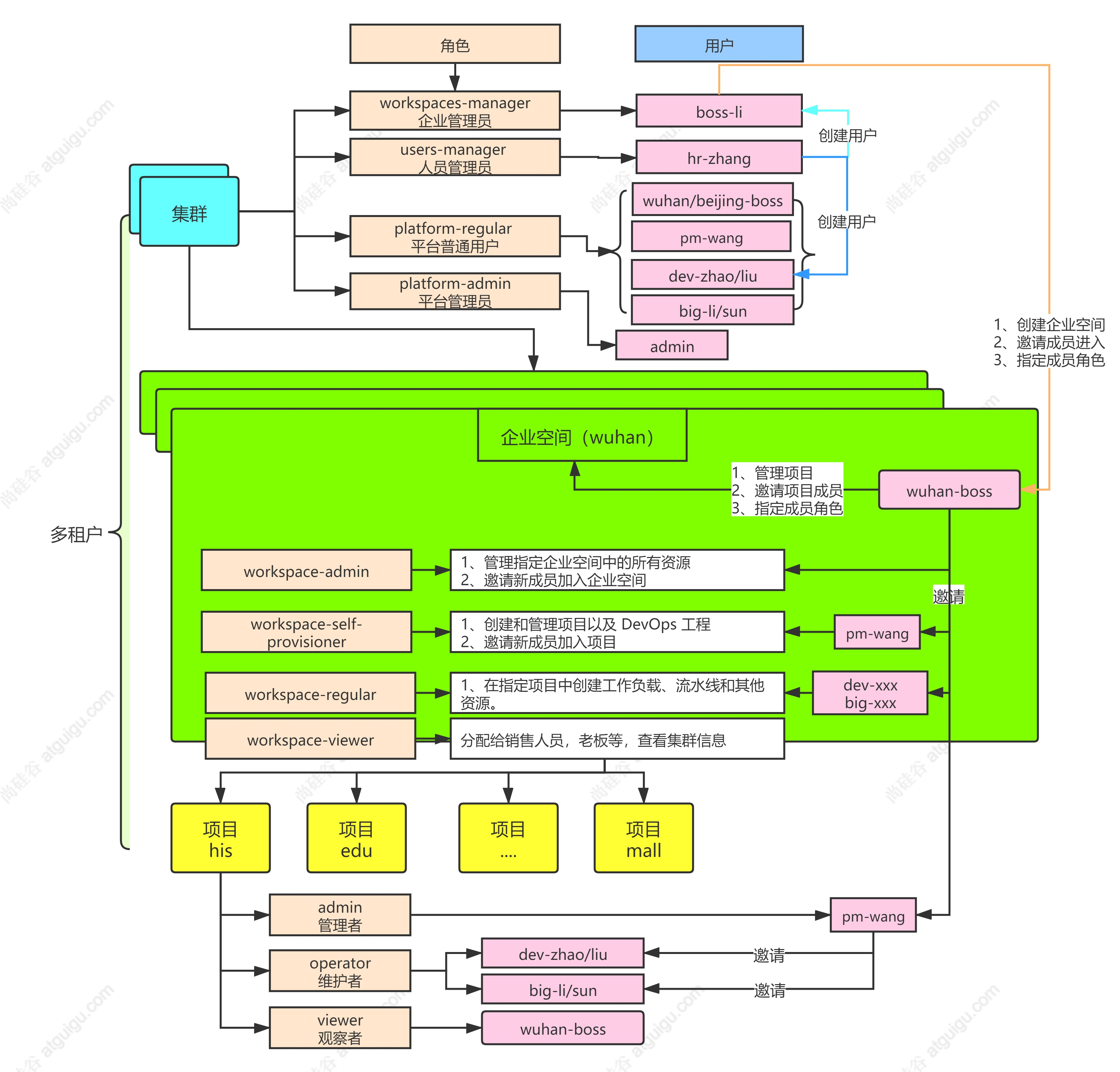
10个角色
- 集群
- platform-admin 平台管理员,最大的权限。
- users-manager 平台用户管理员,管理平台所有用户。
- workspaces-manager 平台企业空间管理员,管理平台所有企业空间。
- platform-regular 平台普通用户,在被邀请加入企业空间或集群之前没有任何资源操作权限。
- 企业空间
- 企业空间是一个组织您的项目和 DevOps 工程、管理资源访问权限以及在团队内部共享资源等的逻辑单元,可以作为团队工作的独立工作空间。
- wuhan-viewer企业空间的观察者,可以查看企业空间下所有的资源信…
- wuhan-regular企业空间普通成员,无法创建DevOps工程和项目。
- wuhan-self-provisioner企业空间普通成员,可以在企业空间下创建DevOps工…
- workspace-admin企业空间管理员,可以管理企业空间下所有的资源。
- 项目
- viewer
项目观察者,可以查看项目下所有的资源。 - operator
项目维护者,可以管理项目下除用户和角色之外的资源。 - admin
项目管理员,可以管理项目下所有的资源。
- viewer
人事 创建人员
-
创建一个人人事,角色为 users-manager。hr-zhang
-
登录人事 创建 boss-li,角色为:workspaces-manager
- 管理集团所有的分部 (子公司)
- 在 kuberSphere 叫:企业空间
- 武汉和深圳 公司的部署,都在自己的企业空间中。
-
登录 boss-li,boss里无法管理人员。只能看。创建企业空间
- 空间名称为:wuhan,别名为:wh
- 在创建shenzhen,管理者,默认为自己。
-
登录人事,创建 wuhan-boss,角色为:platform-regular 平台普通用户
- 创建shenzhen-boss,同样是 普通用户。
- 创建pm-wang,王总监,普通用户
- dev-zhao,开发 赵
- dev-liu
- big-li,李大牛。
- big-sun 孙大牛。
总boss 企业空间 分配管理
- 登录 boss-li,进入企业空间管理,企业成员。
- 进入,武汉空间,分配 wuhan-boss为 workspace-admin
- 进入,深圳空间,分配shenzhen-boo为 workspace-admin
分校长 企业空间管理员 邀请人
- 登录 wuhan-boss,企业空间管理,企业成员。
- 先把 大老板 boss-li移除了。(武汉自制)
- 邀请 big-sun和 big-li,dev-liu 和 dev-zhao 为:wuhan-regular企业空间普通成员,无法创建DevOps工程和项目。
- pm-wang 为:self-provisioner 企业普通成员,可以创建工程和项目。现在只有他。
总监创建项目 管理
-
登录 pm-wang,不具备 邀请别人的能力。
-
可以创建 项目,进行创建
- his,别名 his,商医通。
- edu,在线教育。
- mall,尚品汇
-
进入 his,点击 项目设置—项目成员—邀请成员
- big-sun 和为 admin 项目管理员,可以管理项目下所有的资源。
- big-li,dev-liu 和 dev-zhao 为 operator 项目维护者,可以管理项目下除用户和角色之外的资源。
创建商务观察者
-
登录人事hr-zhang,创建用户,hello-wang 王客户。platform-regular 平台普通用户。
-
登录 wuhan-boss,给hello-wang角色 wuhan-viewer
- 企业空间的观察者,可以查看企业空间下所有的资源信息。
-
登录hello-wang,此时 已经可以 看 wu-han下的所有项目了。
- 无所谓了(登录 pm-wang,给 hello-wang 查看商易通的权限)
regular
英
/ˈreɡjələ(r)/
adj.
恒定的,规则的(尤指间隔相同);经常做(或发生)的,频繁的;经常做某事的,常去某地的;惯常的,通常的;持久的,固定的;
n.
常客,老主顾;主力队员,经常参加某项活动的人;正规军人,职业军人;<美>普通产品,普通装;(区别于世俗教士的)修道者,教士
中间件部署实战
应用部署需要关注的信息【应用部署三要素】
1、应用的部署方式
2、应用的数据挂载(数据,配置文件)
3、应用的可访问性
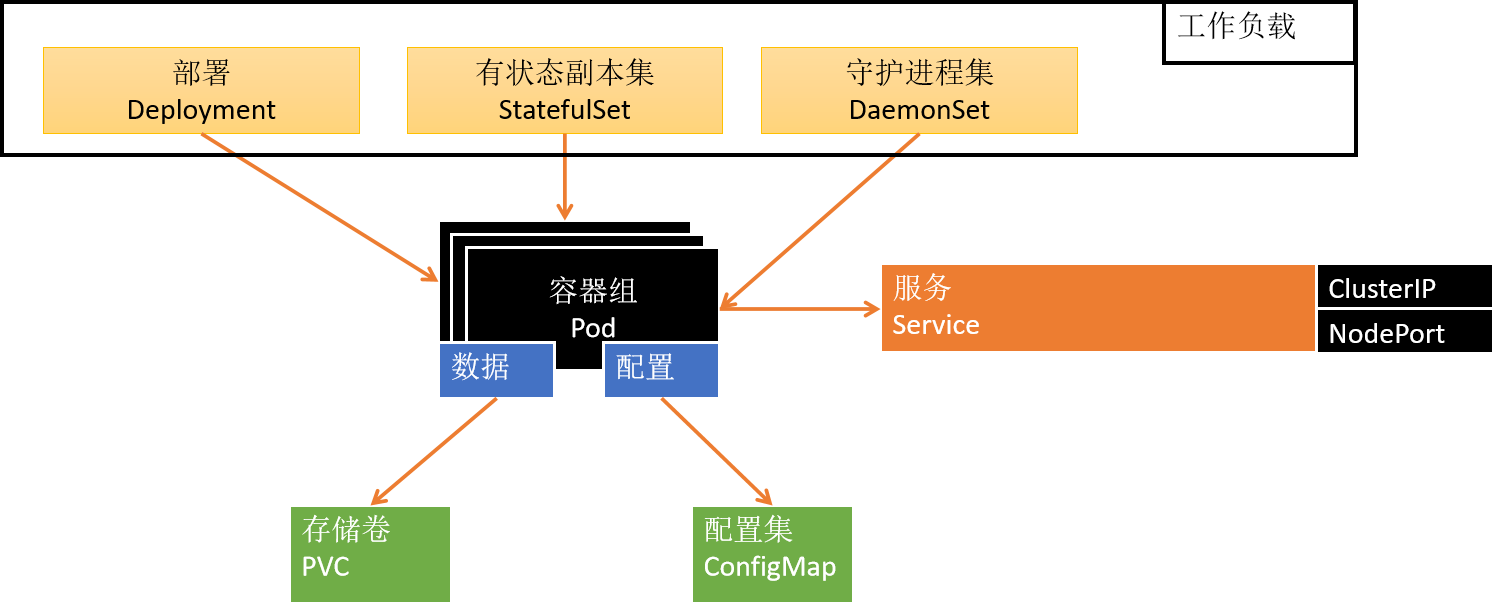
- 微服务 是 无状态应用。
- mysql,redis,有状态应用。
- 死了,重新拉起,数据还是在的。
- 守护进程,收集日志。有且仅有一份。
kubectl get ns #尚医通,是名称空间。
NAME STATUS AGE
default Active 12h
edu Active 75m
his Active 75m
1、应用的部署方式
2、应用的数据挂载(数据,配置文件)
3、应用的可访问性
1、部署MySQL
1、mysql容器启动
docker run -p 3306:3306 --name mysql-01 \
-v /mydata/mysql/log:/var/log/mysql \ #var/log 日志
-v /mydata/mysql/data:/var/lib/mysql \ #var/lib 数据
-v /mydata/mysql/conf:/etc/mysql/conf.d \ #etc/mysql 配置
-e MYSQL_ROOT_PASSWORD=root \
--restart=always \
-d mysql:5.7
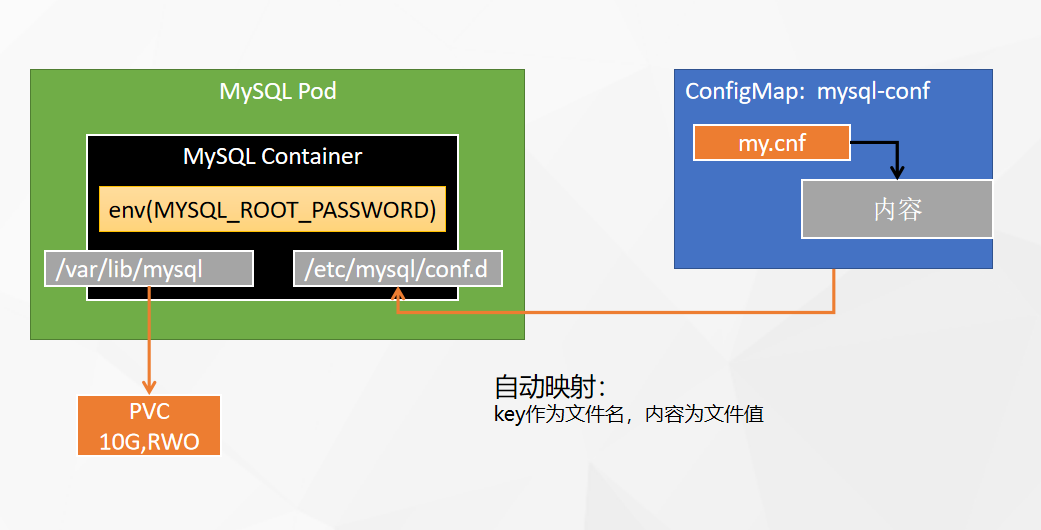
2、mysql配置示例
- 登录 dev-liu账号,在 his,选择配置,配置中心
- 创建名称为:mysql-conf,别名不用管。
- 添加数据 key为 my.conf,值为下面的值:
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
init_connect='SET collation_connection = utf8mb4_unicode_ci'
init_connect='SET NAMES utf8mb4'
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
创建 卷挂载
- 存储管理,存储卷。创建 mysql-pvc
- 访问模式选择:单节点读写
- 还有:多节点只读 和 多节点读写。
部署mysql
- 应用负载—工作负载—有状态副本集
- 名字为:his-mysql,镜像为 mysql:5.7.35,点击使用默认端口
- 资源限制:1 core,1000Mi 内存
- 创建环境变量:MYSQL_ROOT_PASSWORD,值:123456
- 同步主机时区。
- 下一步:
- 下一步:挂载存储——添加存储卷——选择已经创建好的
- 挂载方式读写,目录为:容器mysql的数据目录:/var/lib/mysql
- 点击 挂载配置文件 或 密钥:
- 选择已经创建好的 mysql-conf,只读,目录:/etc/mysql/conf.d
- 最终配置的my.conf,会放到这个目录下。
- 到此完结。
- 选择已经创建好的 mysql-conf,只读,目录:/etc/mysql/conf.d
- 下一步:挂载存储——添加存储卷——选择已经创建好的
3、mysql部署分析
测试分析
- 配置文件,修改了之后,容器内过一会就会刷新。
1、集群内部,直接通过应用的 【服务名.项目名】 直接访问
mysql -uroot -hhis-mysql-glgf.his -p
#DNS在服务处,可以看到。
#his-mysql-f3ch.his 我的为这个。his就是 名称空间。
kubectl get all -n his # 额能看到 pod,service,statefulset
# service/his-mysql-f3ch
#可以得出:dns就是service.名称空间。
#这个 dns,在其他pod,依然可以访问。应该是 同一个命名空间下的。
#其他知识:去nfs下,即可看到数据。挂载的位置。
/nfs/data/his-mysql-pvc-pvc-cbd45f24-84c0-45b8-827d-0398573f4ec6
自己创建服务
-
删除服务(别删 工作负载),自己创建 指定工作负载。
- 名称为:his-mysql,描述信息为:mysql的集群内服务名
- 访问类型:
- 选择:内部通过服务的后端Endpoint lP (集群外不能访问)
- 指定工作负载
- 端口,名称,容器,服务 都填3306。33060 也可以加上。
- 下一步:因为选的 访问类型 没IP,所以选不了 外网访问。
-
测试:dns 域名是自己定义的。his-mysql.his,好用。
-
svc的类型为:ClusterIP
-
重新创建一个 服务:his-mysql-node,说明为:外网访问。
- 访问类型,选择通过集群内部lP来访问服务Virtual lP
- 选中外网访问,选择 NodePort
-
之后 通过 端口,访问任一一台服务器,都能访问。
- svc为:3306:32101/TCP
-
并且:域名为:his-mysql-node.his,内部也可以访问。
- 生产环境,直接 删除这个 外部暴露的端口,只有内部才能连接。
MySQL 默认 TCP 端口号:
1、3306 用于 MySQL Classic 协议(服务器端口选项)
2、33060 用于 MySQL X 协议(服务器 mysqlx_port 选项)
3、33062 用于使用 MySQL Classic 协议的管理连接(服务器 admin_port 选项)
注意点 不要提前创建好 存储卷
- 提前创建好,在启动一份 mysql ,连接的还是 这个 存储卷。
- 应该是 每一个mysql,都有自己存数据的 地方。
- 之后 我们自己做数据同步,分库分表。
- 现在相当于,多个mysql 操作一个文件 存储的地方。
- 比如下面的redis,是 创建 工作负载的时候,指定的 存储卷。
- 把 pod 增加为3个,就会有3个存储卷。
svc 访问类型:
Virtual IP:通过集群内部lP来访问服务Virtual lP (集群外可以访问)
- 以集群为服务生成的集群内唯一的IP为基础,集群内部可以通过此IP来访问服务。
Headless:集群内部通过服务的后端Endpoint lP直接访问服务Headless (selector)
- 集群不为服务生成IP,集群内部通过服务的后端Endpoint IP直接访问服务。此类型适合后端异构的服务,比需要区分主从的服务。
Service外部访问方式:
https://blog.csdn.net/qq_41337034/article/details/109517493
NodePort和LoadBalancer
LoadBalancer类型
在那些支持外部负载均衡器的云提供者上面,将type字段设置为"LoadBalancer"会为你的Service设置好一个负载均衡器。该负载均衡器的实际的创建是异步进行的,并且该设置好均衡器会在该Service的status.loadBalancer字段中显示出来。例如:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376,
"nodePort": 30061
}
],
"clusterIP": "10.0.171.239",
"loadBalancerIP": "78.11.24.19",
"type": "LoadBalancer"
},
"status": {
"loadBalancer": {
"ingress": [
{
"ip": "146.148.47.155"
}
]
}
}
从外部负载均衡器的流量将会被引到后端的Pod,然而具体这个如何实现则要看云提供商。一些云提供商允许指定loadBalancerIP。在这种场景,负载均衡器将随用户指定的loadBalancerIP一起创建。如果字段loadBalancerIP没有指定,该负载均衡器会被指定一个短暂性的IP。如果指定了loadBalancerIP,但是云提供商不支持这个特性,这个字段会被忽略。
只有LoadBalancer大部分情况下只适用于支持外部负载均衡器的云提供商(AWS,阿里云,华为云等)使用。
k8s的LoadBalancer类型的Service依赖于外部的云提供的Load Balancer
Metallb的作用就是通过k8s原生的方式提供LB类型的Service支持,开箱即用。
遇到问题istio-sidecar
Post https://istio-sidecar-injector.istio-system.svc:443/inject?timeout=30s
参考:
http://t.zoukankan.com/fat-girl-spring-p-15153258.html
# 设置标签
$ kubectl label namespace default istio-injection=enabled
vim kube-apiserver
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorag
重启服务器,就好了。
2、部署Redis
1、redis容器启动
#创建配置文件
## 1、准备redis配置文件内容
mkdir -p /mydata/redis/conf && vim /mydata/redis/conf/redis.conf
##配置示例
appendonly yes
port 6379
bind 0.0.0.0
#docker启动redis
docker run -d -p 6379:6379 --restart=always \
-v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf \
-v /mydata/redis-01/data:/data \
--name redis-01 redis:6.2.5 \
redis-server /etc/redis/redis.conf
2、redis部署分析
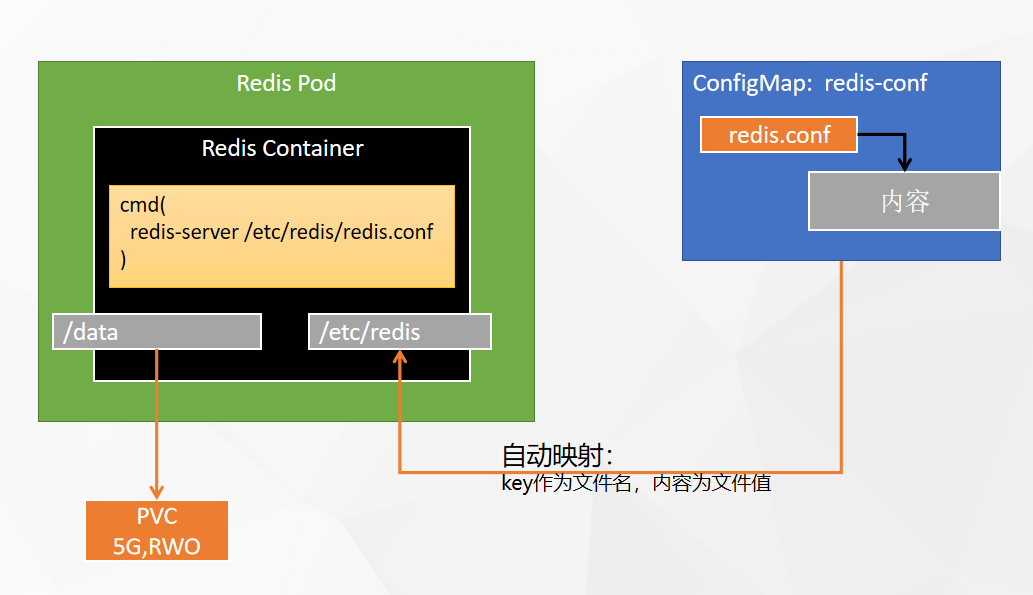
创建配置文件
-
名称为:redis-conf,
-
key为 redis.conf
-
value为:
-
appendonly yes port 6379 bind 0.0.0.0 #所有人都可以访问
-
-
创建 有状态部署
-
名字:his-redis
-
容器选:redis:latest,使用默认端口
-
资源限制 1core 和 1000Mi 内存。
-
启动命令:redis-server
- 参数:/etc/redis/redis.conf
-
同步主机时区。
-
添加存储卷模板:
- redis-pvc
- 存储卷容量:2G
- 读写的方式挂载,挂载到容器内部 /data 目录
-
创建配置文件:
- 选择 redis-config
- 只读,路径为:/etc/redis
创建服务
-
删除自己创建的服务,创建 his-redis,集群内访问(不生成IP)Headless模式。
-
选中 有状态副本集
-
端口,都填 6379
-
创建 his-redis-node 服务,
-
访问类型有IP的,Virtual IP
-
端口依然为 6379
-
打开外网访问,访问方式为 NodePort
3、部署ElasticSearch
elastic
adj.
有弹性的;灵活的
n.
弹性织物,松紧带
Search
v.
搜查,搜寻;搜查(地方,车辆),搜……的身;思索,细想(问题答案等);细察,细查;(用计算机)搜索,检索
n.
搜寻,搜查;探索,寻求;(计算机的)搜索,检索;<律>调查地产负担
1、es容器启动
# 创建数据目录
mkdir -p /mydata/es-01/data && chmod 777 -R /mydata/es-01
# 注意里面创建的 data 文件夹,也要777,否则 启动失败。
# 容器启动
docker run --restart=always -d -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" \
-v es-config:/usr/share/elasticsearch/config \
-v /mydata/es-01/data:/usr/share/elasticsearch/data \
--name es-01 \
elasticsearch:7.13.4
#具名卷挂载。会先把容器内的东西,复制一份到 挂载文件夹。
#这次 el,必须 具名挂载。
-v es-config:/usr/share/elasticsearch/config \
#全路径挂载,如果 /宿主机/data下没有东西。容器内也没有东西。
#配置文件是这样的。但是:像mysql的数据文件,也会把容器 复制到 宿主机。
-v /mydata/es-01/data:/usr/share/elasticsearch/data
2、es部署分析
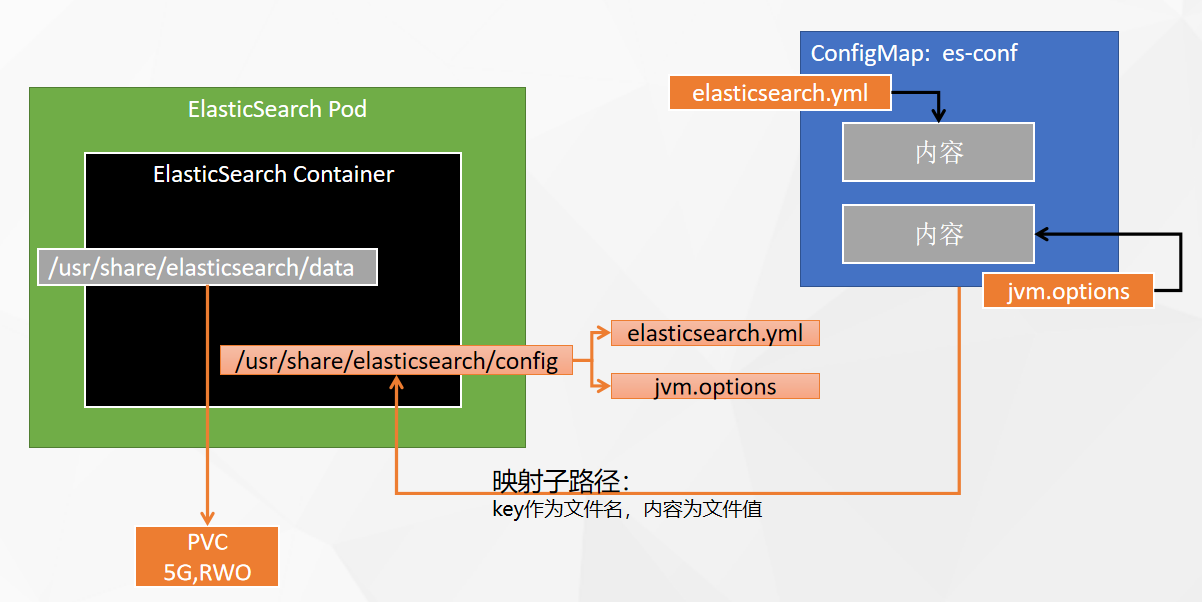
注意: 子路径挂载,配置修改后,k8s不会对其Pod内的相关配置文件进行热更新,需要自己重启Pod
创建配置文件
-
es-conf
-
键名:elasticsearch.yml
-
值
-
cluster.name: "docker-cluster" network.host: 0.0.0.0
-
-
键名:jvm.options
-
值
-
################################################################ ## ## JVM configuration ## ################################################################ ## ## WARNING: DO NOT EDIT THIS FILE. If you want to override the ## JVM options in this file, or set any additional options, you ## should create one or more files in the jvm.options.d ## directory containing your adjustments. ## ## See https://www.elastic.co/guide/en/elasticsearch/reference/current/jvm-options.html ## for more information. ## ################################################################ ################################################################ ## IMPORTANT: JVM heap size ################################################################ ## ## The heap size is automatically configured by Elasticsearch ## based on the available memory in your system and the roles ## each node is configured to fulfill. If specifying heap is ## required, it should be done through a file in jvm.options.d, ## and the min and max should be set to the same value. For ## example, to set the heap to 4 GB, create a new file in the ## jvm.options.d directory containing these lines: ## ## -Xms4g ## -Xmx4g ## ## See https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html ## for more information ## ################################################################ ################################################################ ## Expert settings ################################################################ ## ## All settings below here are considered expert settings. Do ## not adjust them unless you understand what you are doing. Do ## not edit them in this file; instead, create a new file in the ## jvm.options.d directory containing your adjustments. ## ################################################################ ## GC configuration 8-13:-XX:+UseConcMarkSweepGC 8-13:-XX:CMSInitiatingOccupancyFraction=75 8-13:-XX:+UseCMSInitiatingOccupancyOnly ## G1GC Configuration # NOTE: G1 GC is only supported on JDK version 10 or later # to use G1GC, uncomment the next two lines and update the version on the # following three lines to your version of the JDK # 10-13:-XX:-UseConcMarkSweepGC # 10-13:-XX:-UseCMSInitiatingOccupancyOnly 14-:-XX:+UseG1GC ## JVM temporary directory -Djava.io.tmpdir=${ES_TMPDIR} ## heap dumps # generate a heap dump when an allocation from the Java heap fails; heap dumps # are created in the working directory of the JVM unless an alternative path is # specified -XX:+HeapDumpOnOutOfMemoryError # specify an alternative path for heap dumps; ensure the directory exists and # has sufficient space -XX:HeapDumpPath=data # specify an alternative path for JVM fatal error logs -XX:ErrorFile=logs/hs_err_pid%p.log ## JDK 8 GC logging 8:-XX:+PrintGCDetails 8:-XX:+PrintGCDateStamps 8:-XX:+PrintTenuringDistribution 8:-XX:+PrintGCApplicationStoppedTime 8:-Xloggc:logs/gc.log 8:-XX:+UseGCLogFileRotation 8:-XX:NumberOfGCLogFiles=32 8:-XX:GCLogFileSize=64m # JDK 9+ GC logging 9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
-
-
创建有状态副本集
-
his-es
-
elasticsearch:7.13.4,使用默认端口
-
资源限制2核,1000Mi
-e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms512m -Xmx512m" \ -
同步主机时区
-
添加存储卷模板
- es-pvc
- 10G,读写,数据挂载的容器位置:/usr/share/elasticsearch/data
-
添加配置文件
- 找到 es-conf
- 添加配置:只读,路径为:/usr/share/elasticsearch/config/elasticsearch.yml
- 在添加子路径:elasticsearch.yml
- 在选择 特定的键 和 路径:elasticsearch.yml 挂载为:elasticsearch.yml
- 添加配置:只读,路径为:/usr/share/elasticsearch/config/jvm.options
- 在添加子路径:jvm.options
- 特定的键和路径:jvm.options jvm.options
-
删除默认的服务,创建自己的 his-es
- HTTP,端口为:9200,发送http请求的
- TCP,端口:9300。
- 创建一个 内部访问。
- 名字加上 node,创建一个外部访问的。
curl http://his-es.his:9200
可看到json
如果暴露外网,通过
http://172.31.0.11:32538/
4、应用商店
可以使用 dev-zhao 登录,从应用商店部署
找到 rabbitMq,
0.3.2[3.8.1],Mq的版本为 3.8.1
最新版本
-
打开数据的 持久化存储,
-
账号密码都叫 admin
-
等待部署完毕,选择服务,编辑 外网访问。选择 NodePort
-
在服务处,看到外部端口:5672:31934/TCP;15672:32167/TCP
-
任一一台机器访问即可:
5、应用仓库
使用企业空间管理员(wuhan-boss)登录,设置应用仓库
学习Helm即可,去helm的应用市场添加一个仓库地址,比如:bitnami
-
docker仓库,去:https://hub.docker.com/
-
k8s仓库,去https://helm.sh/
-
发布包比较多的公司:Bitnami
-
添加他们公司的仓库地址
helm repo add bitnami https://charts.bitnami.com/bitnami
-
-
使用 wuhan-boss,具有企业空间资质的管理员。
- 选择应用管理——应用仓库—— 名字为:bitnami
-
登录 开发人员dev-zhao,选择 应用负载——部署新应用,
- 来自应用模板——选择 bitnami,有很多。
在这里,我们不涉及高可用部署相关内容。想了解详情,可以关注后续的课程,或者大厂学苑 《拥抱云原生》专题














 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









