







摘要
我们提出了一个在线哈希学习算法。
1,更新的哈希模型被上一次学习的哈希函数惩罚,目的是保持上一轮中
的重要信息。
2,我们也提出了一个累积损失的紧边界。
(总结:这篇论文新颖的地方就在于
1,![]() 这里的f其实在求导中视为常数,一个是利用最新的的权重得到的
这里的f其实在求导中视为常数,一个是利用最新的的权重得到的 ,
另一个就是手动得到最优的 ,有效地解决了离散化不好求导的问题。
2,另一个就是![]() 的更新法,硬把最优的
的更新法,硬把最优的
和次优的 加了一个margin.这样来学习
.
3,还要一个就是最优的 的手动设置法。)
提出算法
- 数据预处理
首先我们用核函数对数据进行预处理,![]() .
.
然后对预处理之后的数据进行哈希码的学习,![]() .
.
直接优化这个离散化的式子太麻烦了,所以我们选择结构性预测:![]() .
.
这样产生的这个h就是一个实值了。
- 在线学习算法
我们输入数据点对,然后得出它们的相似度:
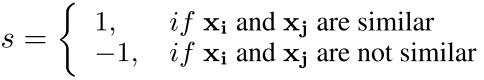
这时,我们把 和
的哈希码定义为
和
.
然后就可以得到相似点对 ![]() .
.
标签信息告诉我们哪一个对相似,哪一个对不相似,这样我们就可以得到最优的哈希码表示
![]() .这个最优的哈希码表示可以指导映射函数的学习
.这个最优的哈希码表示可以指导映射函数的学习 . 这可以视作一个回归过程。
然后我们可以计算相似度分数:
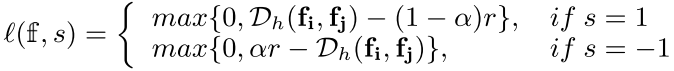
我们可以通过设置 ![]() 来找到最优的哈希码,然后我们定义:
来找到最优的哈希码,然后我们定义:
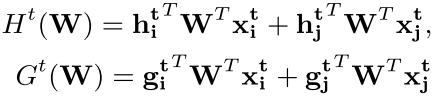
其中, 和
是
和
的哈希码映射,当然我们有
![]()
![]() .
.
现在我们想得到 ![]() 尽得到的
尽得到的 ![]() 尽可能地靠近
尽可能地靠近 ![]() .所以,我们得到的
.所以,我们得到的 ![]() 应该
应该
满足![]() .
.
所以,我们得到我们的损失函数:
![]()
这里 l 的平方根的作用实际上就相当于triplet里面的margin.把 学习的哈希码
和最优的哈希码
![]()
给隔开,用以学习一个新的 .
这里为什么用![]() 做这个margin,主要的原因有两点(第二点不一定对):
做这个margin,主要的原因有两点(第二点不一定对):
1,它有可调节性,越大说明 ![]() 该与
该与 ![]() 隔得越开。
隔得越开。
2,后面证明了![]() ,就算未知的T个加起来也是上界的,所以更不用说一个样本了。因为它是
,就算未知的T个加起来也是上界的,所以更不用说一个样本了。因为它是
有界的,所以这个margin不会大到太离谱。
- 总体的损失函数
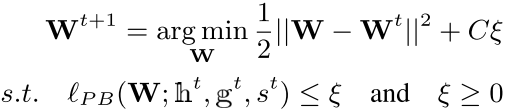
这里用到两点trick:
1,为损失函数定义一个上界,然后最小化这个上界就相当于最小化这个损失函数。
2,这里采用了传说中的 被动-主动 策略,被动在于尽可能保证![]() .
.
主动就在于又要尽可能保证![]() .
.
算法求解
最优化问题的拉格朗日形式:
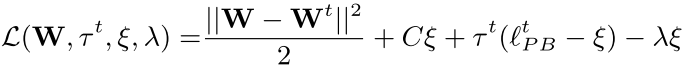 .....................(1)
.....................(1)
![]() 和
和 ![]() 是拉格朗日乘子。
是拉格朗日乘子。
- W-step
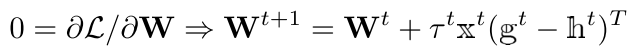 ............................ (2)
............................ (2)
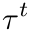 -step
-step
![]() .............................................................(3)
.............................................................(3)
将(2)(3)带入(1)得到,
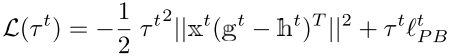 .......................................................(4)
.......................................................(4)
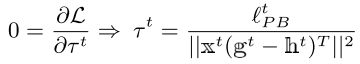
因为 ![]() ,所以我们可以得到,
,所以我们可以得到,
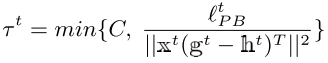
- 最终形式
最终形式可以写成
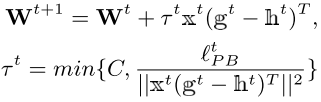
损失界限
(这里主要是为了证明 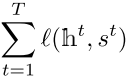 是有界的,这样也就可以代表单个
是有界的,这样也就可以代表单个![]() 是有界的,不至于把这个margin搞得太离谱,
是有界的,不至于把这个margin搞得太离谱,
这只是窃以为。)
以下几个式子可以用来证明(不再详述):
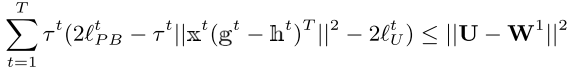
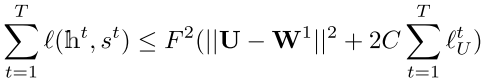
最优化哈希码的推导
我们的最优化哈希码就是![]()
![]() ,满足的是
,满足的是 ![]() .
.
这里我们只考虑两个样本不相似的情况。
我们把 ![]() 的第k位设置为
的第k位设置为 ![]() ,所以
,所以 ![]() 与
与 ![]() 的距离就是
的距离就是
![]()
其中,我们设
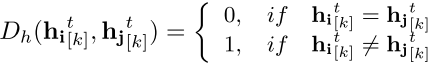
相同的位的数目是 ![]()
![]() ,
,
不相同的位的数目是![]() .
.
如果对于两个样本不相似的话,我们就要把这两个样本相同的位选择一个取反。
我们要选择哪一个位取反呢?其实就是要保留两个样本中哈希码乘以实值(全部都是正数)最大的那个。
对哈希码乘以实值小的那一个样本的位进行取反。
![]()
为什么呢?因为大的那一个样本的位,证明这个样本的这个位已经训练地很好了,小的那一个还不稳定,
所以就要改那个不稳定的,这样对映射矩阵也就改动得小一点。
总体算法

位选择与取反算法(对两个不相似的样本的情况)
















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









