






一、yolov4模型背景
在当今的计算机视觉领域,目标检测是一项至关重要的任务,它旨在识别图像或视频中的物体,并准确地定位其位置。随着深度学习的快速发展,越来越多的目标检测算法被提出,其中You Only Look Once(Yolo)系列算法以其出色的速度和精度在业界备受瞩目。
Yolo算法自诞生以来,经过多个版本的迭代优化,逐渐在目标检测领域占据了一席之地。其中,YoloV4更是在保持高速度的同时,进一步提升了检测精度,成为当前目标检测领域的佼佼者。YoloV4的成功,离不开其强大的模型架构和一系列优化策略。它整合了Mish激活函数、CSPNet结构、SPP模块以及多尺度特征融合等技术,从而显著提升了模型的性能。
在训练YoloV4模型时,数据集的选择和处理至关重要。通常,大型图像数据集如COCO被用于训练,这些数据集包含了丰富的物体类别和各种场景,为模型提供了充足的学习样本。在数据预处理阶段,需要对数据集进行划分,包括训练集、验证集和测试集,并对图像中的目标位置与类别信息进行标注。此外,为了加速模型的收敛并提高最终性能,部分组件如Backbone可以选择预训练权重进行初始化。
在训练过程中,YoloV4采用了多任务损失函数,包括分类损失、定位损失和置信度损失,以全面评估模型的性能。同时,YoloV4还验证了最先进的Bag-of-Freebies和Bag-of-Specials方法在训练期间的影响。这些方法包括数据增强、网络正则化、损失函数的设计等,旨在进一步提升模型的泛化能力和稳定性。
值得一提的是,YoloV4还针对单GPU训练进行了优化。通过修改最先进的方法,如CBN、PAN、SAM等,使得YoloV4能够在一块GPU上实现高效训练。
二、yolov4模型概述及训练过程
1.模型训练概述
YoLo V4在前代基础上整合了大量优化策略,如Mish激活函数、CSPNet结构、SPP模块以及多尺度特征融合等,以提升模型性能。模型的整体架构采用“Backbone-Neck-Head”的经典设计,其中Backbone用于提取丰富的底层到高层语义特征,Neck部分进行跨层特征融合,Head负责输出预测框及其置信度。
2.训练思路
(1)验证模型在训练集上的性能,确保模型没有出现过拟合或欠拟合的问题。
(2)评估模型的准确性、召回率、F1值等关键指标,以判断模型是否满足实际应用需求。
(3)通过调整模型的参数或优化策略,进一步提升模型在训练集上的性能。
3.测试过程:
(1)数据准备:将训练集按照一定比例划分为训练子集和验证子集。训练子集用于模型训练,验证子集用于测试模型性能。
(2)模型训练:使用训练子集对YoloV4模型进行训练。在训练过程中,可以调整学习率、批次大小、优化器等参数,以优化模型的训练效果。
(3)模型评估:在训练完成后,使用验证子集对模型进行评估。计算模型在验证子集上的准确率、召回率、F1值等指标,以评估模型的性能。
(4)结果分析:根据评估结果,分析模型在训练集上的表现。
三、训练测试事例
1.准备测试集数据开始训练
当前的文件夹目录:
2.测试并导入PyCharm未导入的库
(1)使用train这个文件进行测试训练,运行后会显示未导入的库和包,例如:
import datetime
import os
from functools import partial
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch import nn
from torch.utils.data import DataLoader
from nets.yolo import YoloBody
from nets.yolo_training import (YOLOLoss, get_lr_scheduler, set_optimizer_lr,
weights_init)
from utils.callbacks import EvalCallback, LossHistory
from utils.dataloader import YoloDataset, yolo_dataset_collate
from utils.utils import (get_anchors, get_classes, seed_everything,
show_config, worker_init_fn)
from utils.utils_fit import fit_one_epoch个人建议使用清华源的链接在终端导入库速度较快且准确,导入库链接:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple +所需导入的库即可。
(2)首先运行voc_annotation.py文件
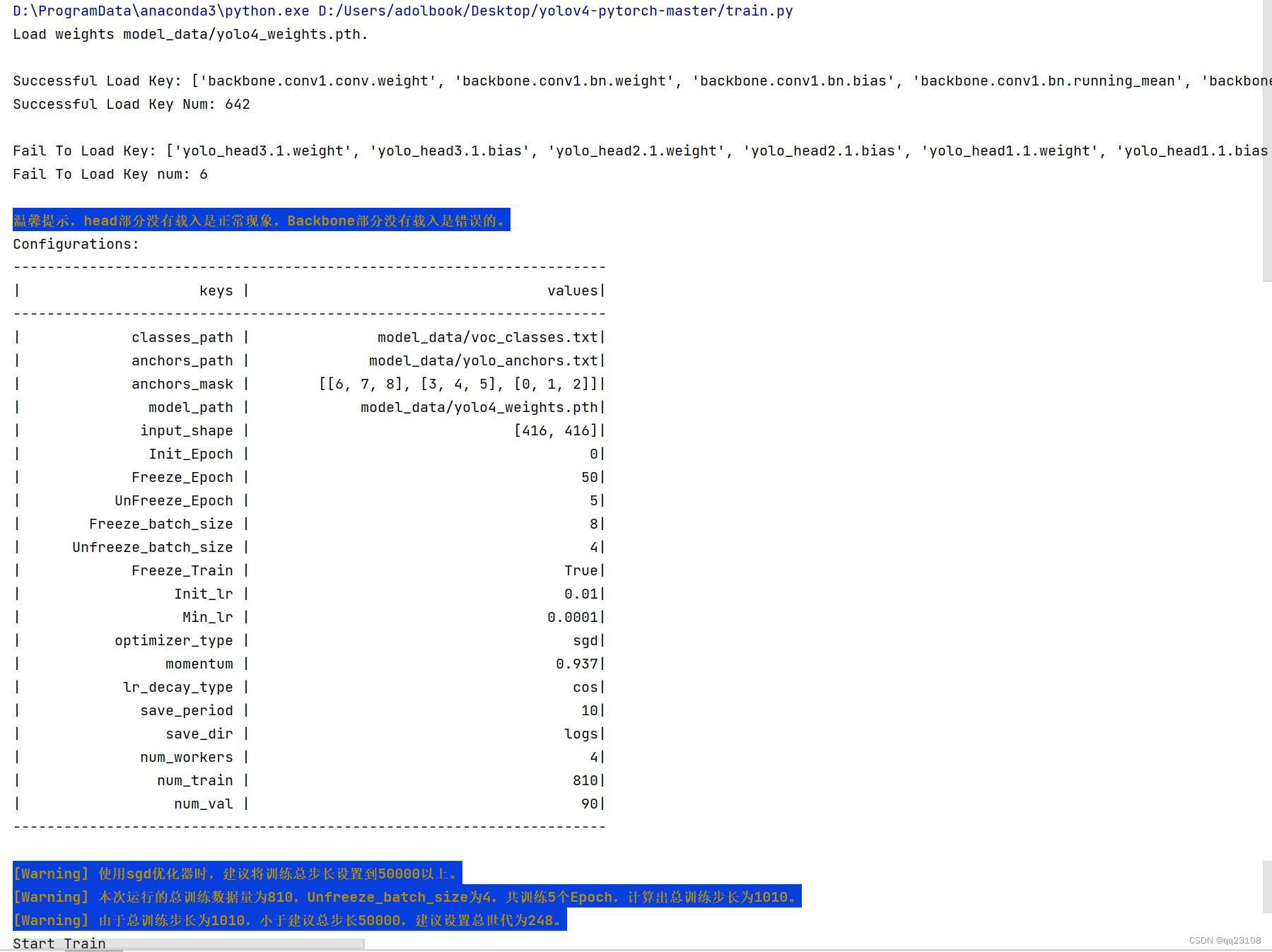
运行成功后返回数据:
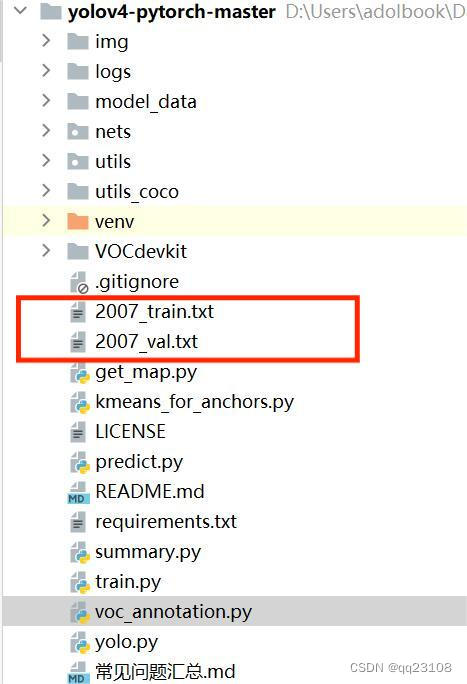
运行正确后目录则会生成两个新文件:
(3)进行train.py文件进行测试训练
a.这里需要注意文件存放的位置,需修改文件保存的目录
with open('D:\\Users\\adolbook\\Desktop\\yolov4-pytorch-master\\2007_train.txt','r', encoding='utf-8') as f:
train_lines = f.readlines()
with open('D:\\Users\\adolbook\\Desktop\\yolov4-pytorch-master\\2007_val.txt','r', encoding='utf-8') as f:
b.测试训练集次数,训练次数越多,准确率越高。因时间问题,采取的是5次测试训练为例,大家有时间的话可以测试两百次以上......以下是测试结果事例:

(4)运行predict.py文件
a.将图片文件放入img文件夹中进行运行
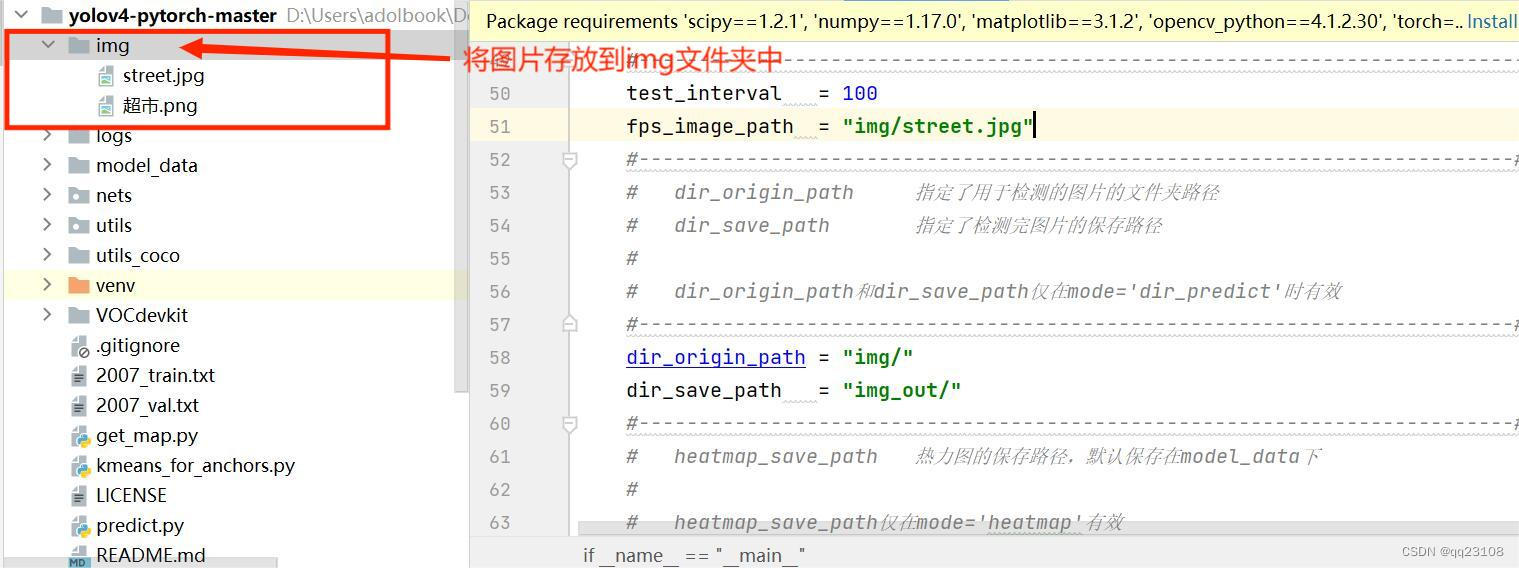
将图片所在位置填入Input image filename中:
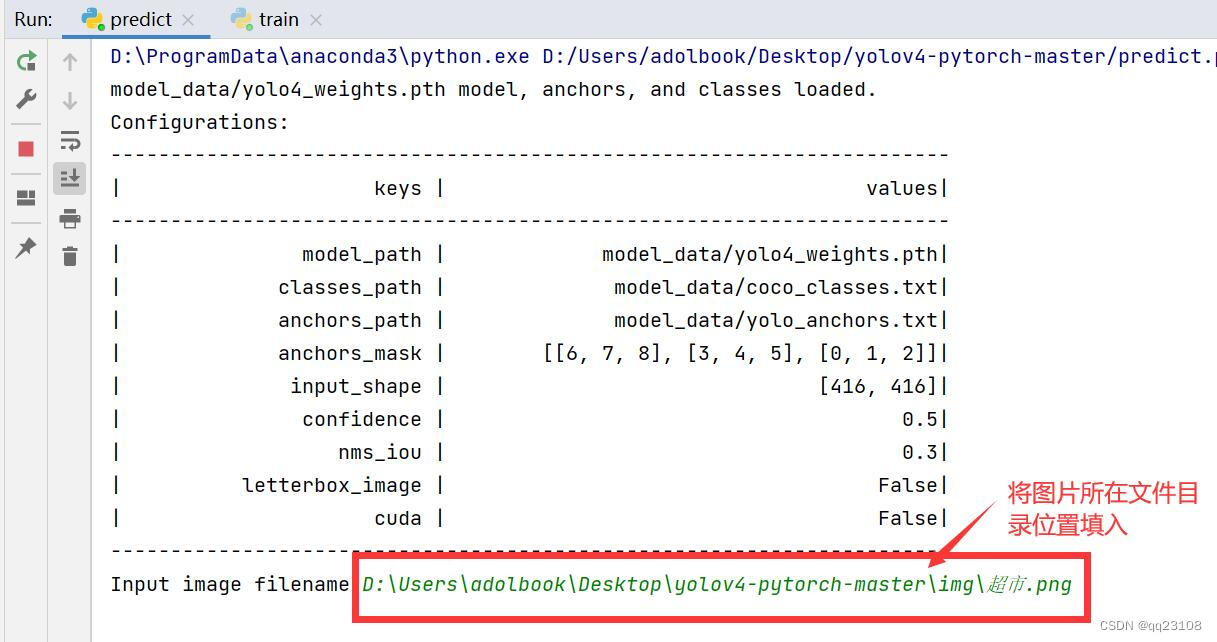
运行成功结果如下:


(5)以上运行过程就是对yolov4模型测试训练集的运行过程。
四、YOLOv4模型测试训练的实验过程分析与结果反思,主要涉及到模型的搭建、训练过程、测试表现以及结果的分析与优化。以下是对这一过程的具体分析与反思:
1.模型搭建与训练过程
在模型搭建阶段,我们首先需要在PyTorch或TensorFlow等深度学习框架下搭建YOLOv4的网络结构。然后,设置好学习率、优化器(如Adam)以及批次大小等关键参数。在此过程中,对于学习率的选择和优化器的配置,需要根据具体的任务和数据集进行调整,以找到最佳的模型训练效果。
训练过程中,我们采用了多任务损失函数,包括分类损失、定位损失和置信度损失,以全面评估模型的性能。同时,我们采用了分阶段训练策略,先训练Backbone,然后逐步加入Neck和Head部分进行联合训练。这种渐进式的训练方式有助于模型稳定收敛。此外,我们还采用了余弦退火策略调整学习率,使得模型在初始阶段能较快收敛,在后期又能精细优化参数。
在数据增强方面,我们使用了随机翻转、裁剪、缩放、颜色抖动等策略,以增加模型的泛化能力。同时,也尝试了Mosaic数据增强、Mixup和Cutout等方法,这些方法在一定程度上提高了模型的性能。
2.测试表现与结果分析
经过训练后,我们在测试集上对模型进行了评估。评估指标主要包括准确率、召回率、mAP等。通过对比不同训练策略和数据增强方法下的模型性能,我们发现采用分阶段训练策略和余弦退火学习率调整策略的模型在性能上表现更佳。同时,数据增强策略也显著提高了模型的泛化能力。
然而,我们也发现了一些问题。例如,在某些复杂场景下,模型的定位精度和识别率仍有待提高。这可能是由于模型结构或参数设置不够合理,或者数据集的多样性和丰富性不足导致的。
3.结果反思与优化建议
针对以上问题,我们进行了深入的反思,并提出了以下优化建议:
(1)进一步优化模型结构和参数设置,尝试使用更先进的网络结构和优化算法,以提高模型的性能。
(2)增加数据集的多样性和丰富性,收集更多的样本和标注数据,以提高模型的泛化能力。
(3)尝试使用更复杂的数据增强策略,如自对抗训练等,以进一步提高模型的性能。
(4)对模型进行更细致的调优和测试,以找到最佳的模型配置和参数设置。
总之,通过对YOLOv4模型测试训练的实验过程进行分析与反思,我们可以找到模型存在的问题和不足,并提出相应的优化建议。这将有助于我们更好地应用YOLOv4模型于实际任务中,并取得更好的性能表现。















 4609
4609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









