






前言
ElasticSearch的记录与学习,配套的学习课程,在此特别感谢图灵老师提供的课程
一、ElaticSearch课程介绍
1.1 数据分类
结构化数据:固定格式,有线长度,比如mysql存储的数据
非结构化数据:不定长,无固定格式,不如邮件,word文档,日志
半结构化数据:前两者结合,比如xml,html
1.2 搜索分类:
结构化数据搜索:使用关系型数据库
非结构化数据搜索:顺序扫描、全文检索
1.2.1 顺序扫描(效率低、搜索的结果可能不是期望的):
如果需要搜索"ABCD"这样的关键词时也会出现"A",“AB”,“BC”,”ABC“,需要用到全文检索
1.2.2 全文检索
全文检索是指:
通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在吧文本中的位置,以及出现的次数
用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
搜索原理简单概括为这么几步:
内容爬取,停顿词过滤比如一些无用的像"的","了"之类的语气词/连接词
内容分词,提取关键词
根据关键词简历倒排索引
用户输入关键词进行搜索
1.3 正排索引与倒排索引


1.4 正排索引
二、ElasticSearch简介
2.1 ElasticSearch是什么
ElasticSearch(简称ES)是一个分布式、RESTful风格的搜索和数据分析引擎,是用Java开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。客户端支持Java、.NET(C#)、PHP、Python、Ruby等多种语言
官方网站:ElasticSearch的官网
下载地址:ElasticSearch的下载地址
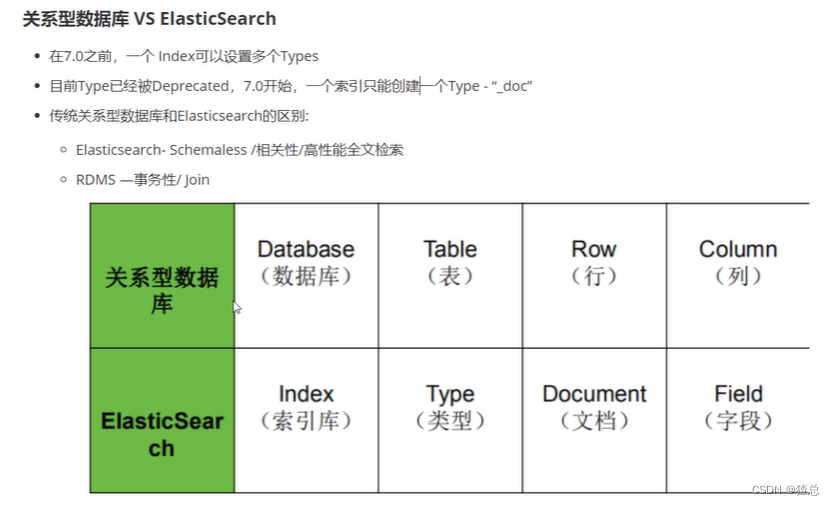
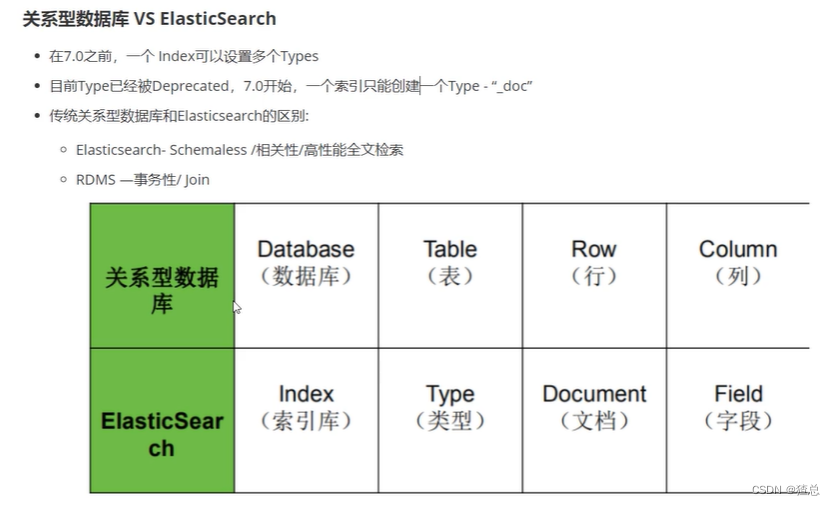
2.1.1 关系型数据库 VS ElasticSearch
2.2 ElasticSearch的特性
现在8.X版本的很少人用,现在最主要流行的应该是7.X



2.3 ElasticSearch与Solr的比较
当单纯的对已有数据进行搜索时,Solr更快
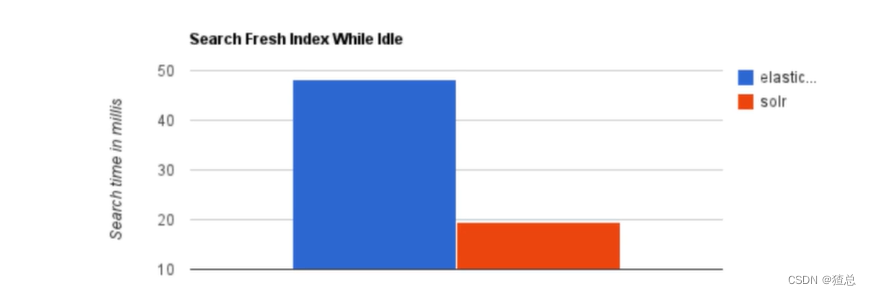
当实时建立索引时,Solr会产生io阻塞,查询性能较差,ElasticSearch有明显的优势
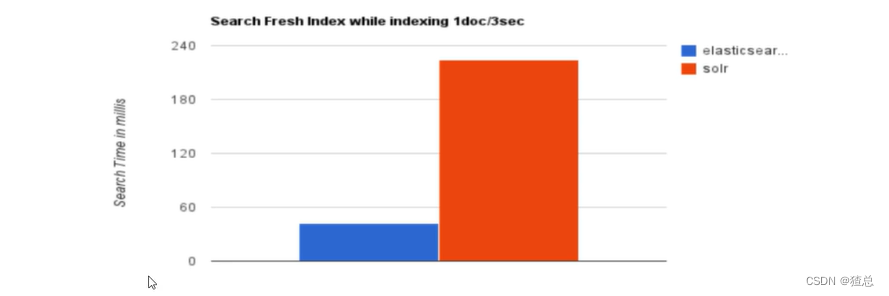
许多大型互联网公司通过测试,将搜索引擎从Solr转为ElasticSearch查询速度提升了50倍
2.4 Elastic Stack介绍
在Elastic Static之前我们听说过ELK,ELK分别是Elasticsearch,Logstash,Kibana者三款软件在一起的简称,在发展过程中又有新成员Beats加入,形成了Elastic Stack
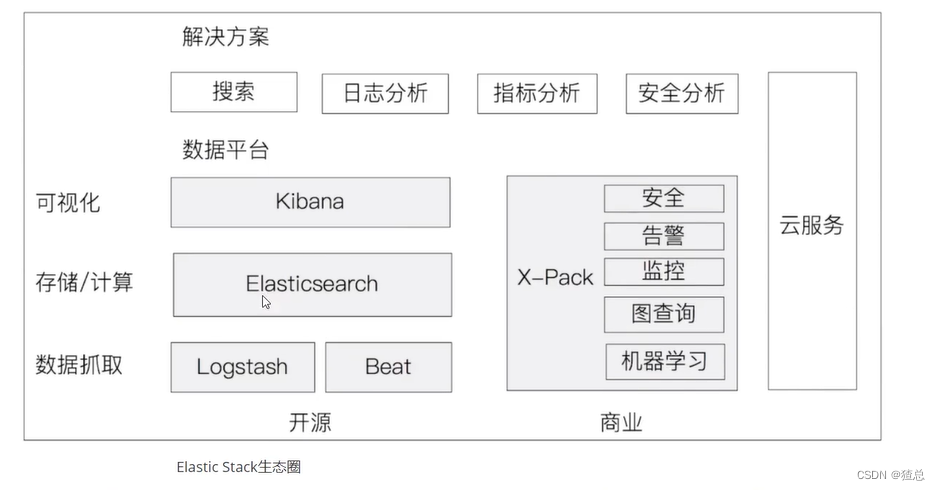
Elasticsearch作为数据存储和搜索、是生态圈的基石,Kibana在上层提供给用户一个可视化及操作的界面,Logstash和Beat可以对数据进行收集。X-Pack部分是Elastic公司提供的商业项目
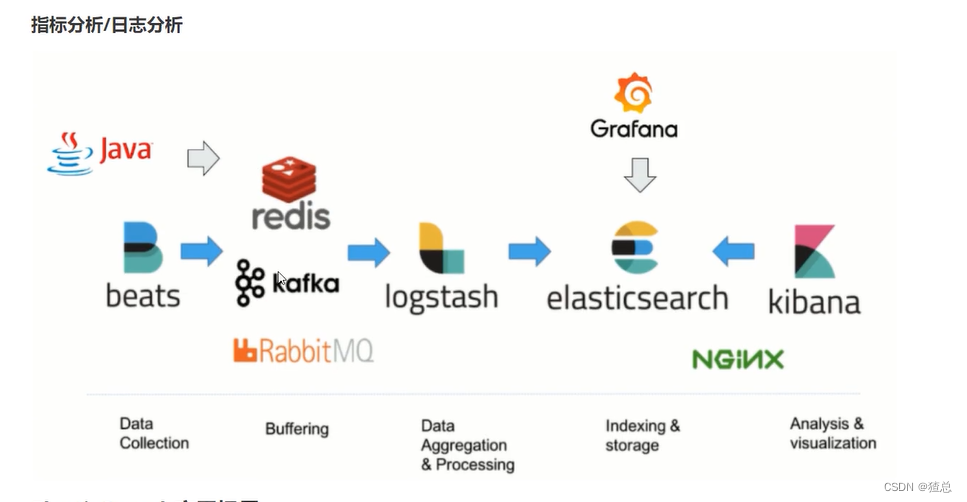
2.5 ElasticSearch应用场景

2.6 ElasticSearch下载安装
参考的视频:ElasticSearch的安装
2.7 ElasticSearch的目录结构

2.8 主配置文件elasticsearch.yml


2.9 ElasticSearch服务启动
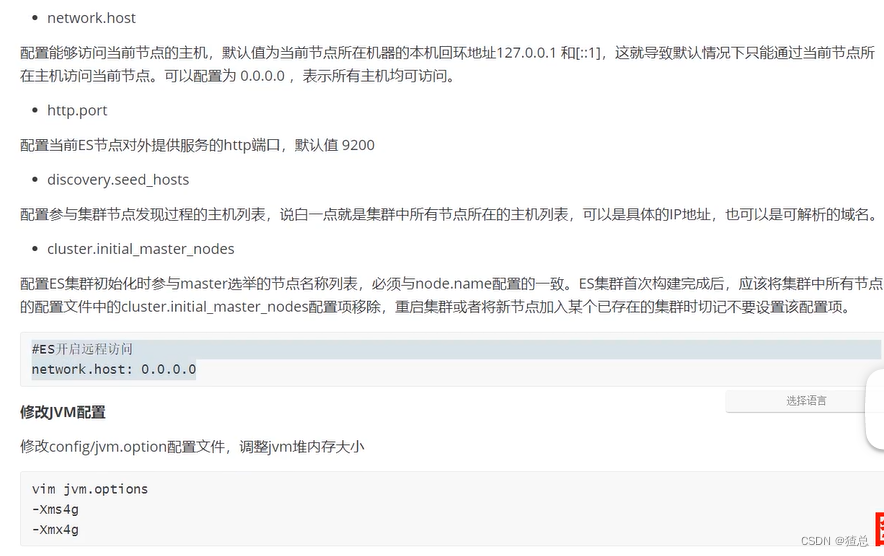
Linux下的安装:Linux下的安装
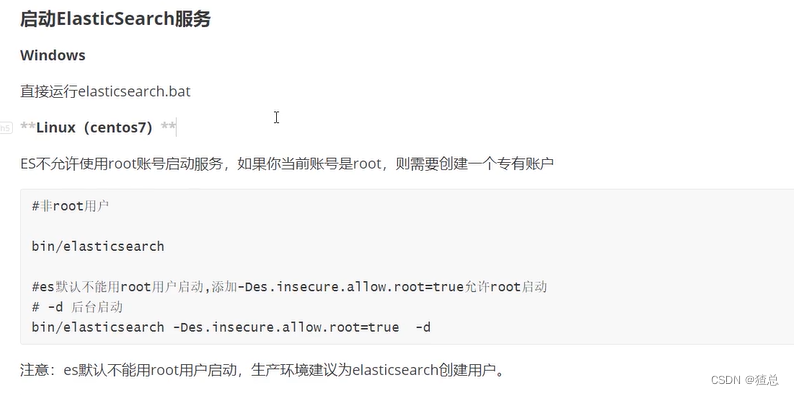
localhost:9200/
出现以下消息代表启动成功
2.10 客户端Kibana的安装
下载地址:Kibana的下载
参考视频:Kibana的下载参考

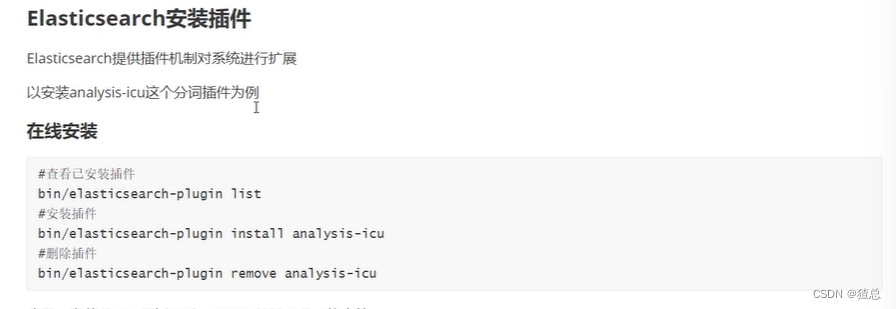
三、ElasticSearch插件安装(分词器)
3.1 在线安装
3.2 离线安装
下载地址:IK分词器安装


四、ElasticSearch索引操作
4.1 关系型数据库 VS ElasticSearch
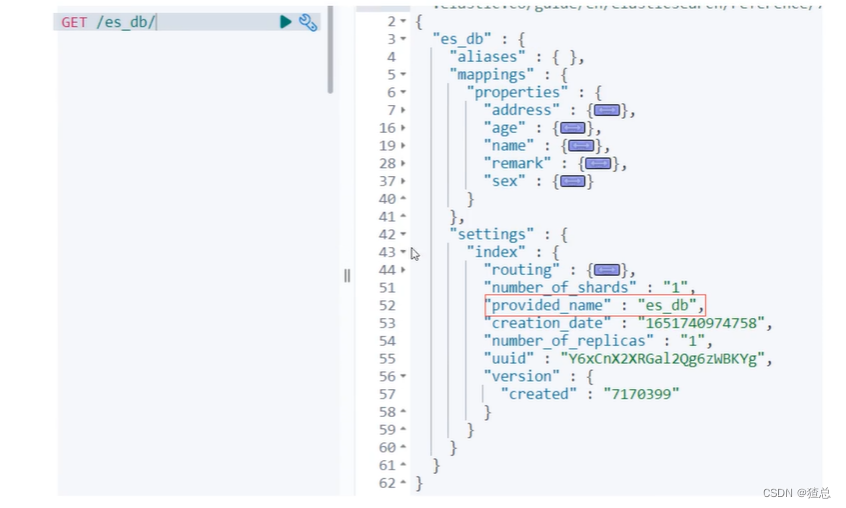
4.2 索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
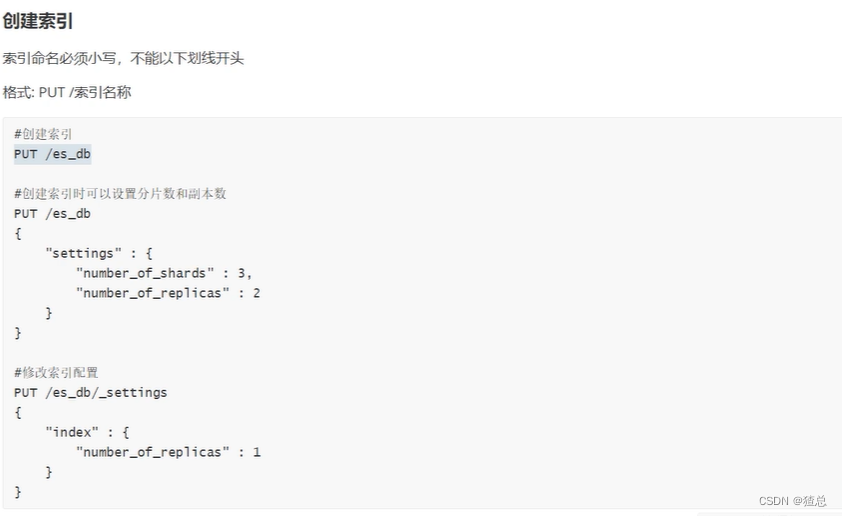
4.2 创建索引
启动Kibana,在localhost:5601控制台下进行操作
4.3 简单的指令
#查看分词效果
GET _analyze
{
"analyzer": "ik_max_word",
"text": "广州白云山"
}
#创建索引
PUT /es_db
#查询索引
GET /es_db
#es_db是否存在
HEAD /es_db
#删除索引
DELETE /es_db
#使用ik分词器
PUT /es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type"
:"ik_max_word"
}
}
}
GET /es_db/_settings
#关闭索引
POST /es_db/_close
#打开索引
POST /es_db/_open
#重建索引
POST _reindex
{
"source": {
"index":"es_db"
},
"dest":{
"index": "es_db2",
"version_type": "external"
}
}
#查询第一条数据
GET /es_db/_doc/1
#查询前10条文档(es默认的分页机制为每页10条,所以只能查到前10条文档,可以通过修改size来修改)
GET /es_db/_doc/_search
#创建文档,指定id
PUT /es_db/_doc/1
{
"name":"张三",
"sex":1,
"age":25,
"address":"广州天河公园",
"remark":"java developer"
}
创建ik分词器
PUT /es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type"
:"ik_max_word"
}
}
}
GET /es_db/_settings
结果显示成功

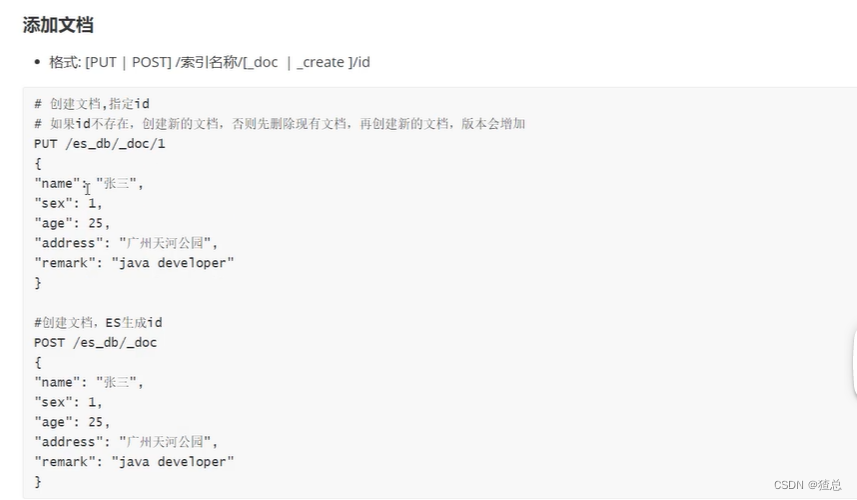
五、 添加文档操作
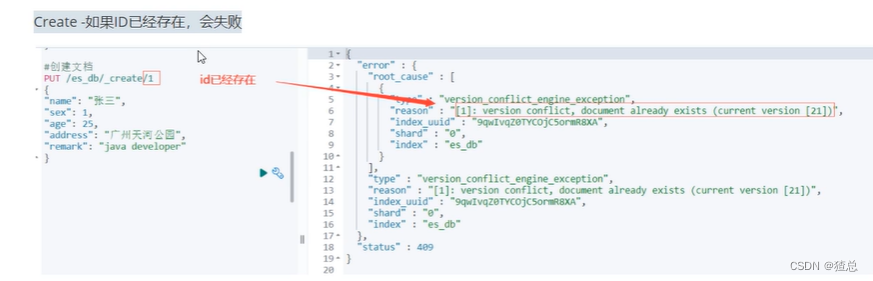
_doc与_create区别:_doc当文档存在会进行覆盖。_create当文档存在会报错,不允许一个id重复创建
PUT 用法:需要写ID,会把原来的文档先删掉再执行PUT (覆盖)
POST用法:可以不写ID,会一直添加新的数据,不会删除原有的数据。
#PUT创建文档,指定id,id相同时会覆盖
PUT /es_db/_doc/1
{
"name":"张三",
"sex":1,
"age":25,
"address":"河南天健湖公园",
"remark":"java developer"
}
PUT /es_db/_doc/1
{
"name":"张三xxx",
"sex":1,
"age":25,
"address":"河南天健湖公园",
"remark":"java developer"
}
#POST方法指定id,与PUT一样会覆盖原文档
#POST方法不指定id,不会覆盖任何文档,会往后添加新的文档
POST /es_db/_doc
{
"name":"张三2",
"sex":1,
"age":25,
"address":"河南天健湖公园",
"remark":"java developer"
}
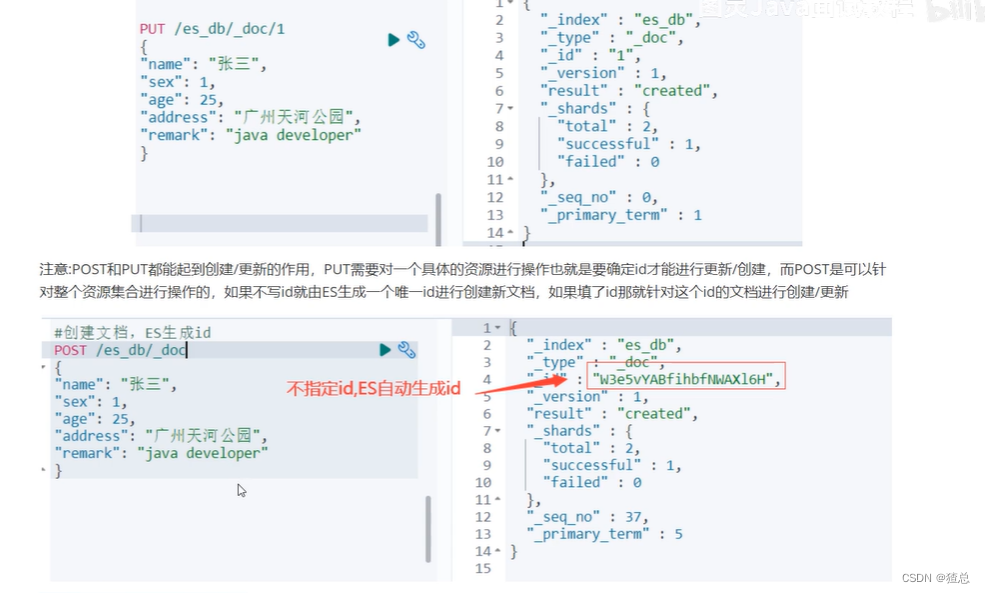
六、 更新文档操作
_update:更新文档
_update_by_query:更新符合条件的文档
POST /es_db/_update/1
{
"doc":{
"age":30
}
}
结果显示发现,每次进行数据更新版本号都会发生变化(数据必须更新,如果与原数据相同不发生变化),可以保证幂等性
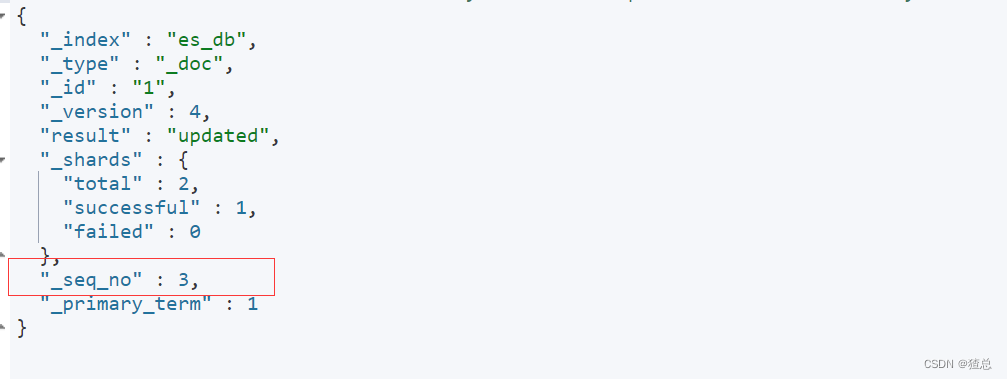
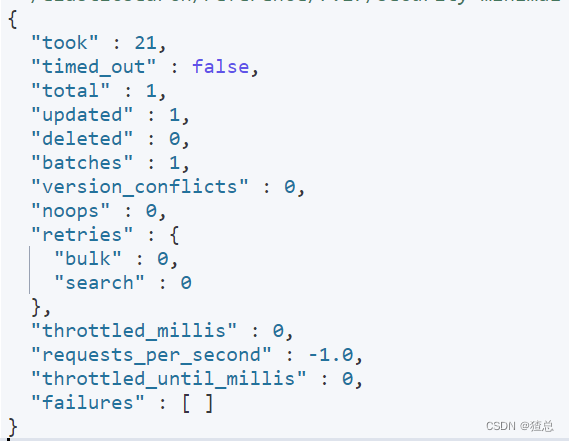
#更新符合条件的文档 _update_by_query 更新id为1的age属性为30
POST /es_db/_update_by_query
{
"query": {
"match": {
"_id": "1"
}
},
"script": {
"source": "ctx._source.age = 30"
}
}
结果显示,“updated”:1,更新一个,发现年龄再次被修改(在运行之前已经将年龄修改为了25)

七、查询文档操作
根据ID查询
#查询第一条数据
GET /es_db/_doc/1
#查询前10条文档
GET /es_db/_doc/_search
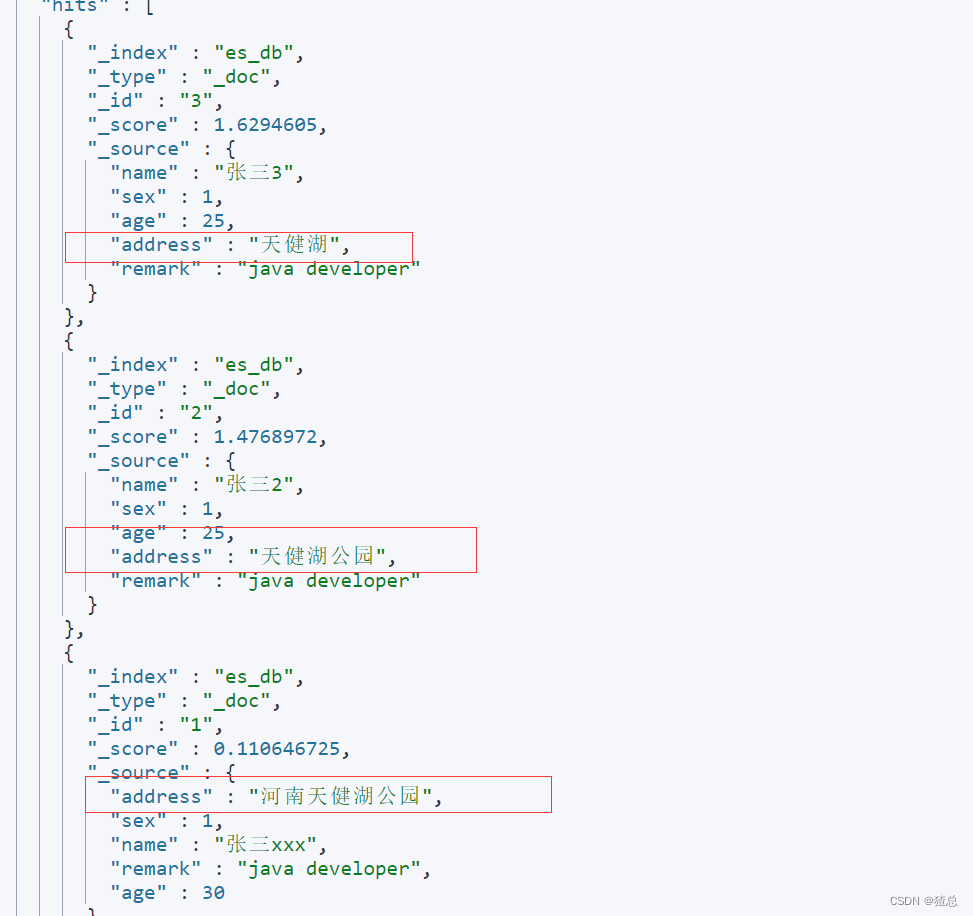
#第一种 查询address中带有天健湖的文档
#进行查询
GET /es_db/_search
{
"query":{
"term": {
"address": {
"value": "天健湖公园"
}
}
}
}
#第二种 查询address中带有天健湖的文档 此处是因为ik分词器进行的分词
GET /es_db/_search
{
"query":{
"match": {
"address": "天健湖公园"
}
}
}
结果显示
第一种没有使用ik分词器查询的结果

第二种ik分词器查询的结果,会发现"天健湖"也在查询范围内
其他的查询操作

八、批量写入_bulk操作


GET /article/_search
#批量创建数据 使用的"create" 在article的索引下批量创建 已存在的ID重复创建会抛出异常
POST _bulk
{"create":{"_index":"article","_type":"_doc","_id":4}}
{"id":4,"title":"lyf","content":"es学习666","tags":["java","ElasticSearch"],"creatime":"155601539274"}
{"create":{"_index":"article","_type":"_doc","_id":5}}
{"id":5,"title":"fyl","content":"es学习999","tags":["java","ElasticSearch"],"creatime":"155601539274"}
#批量创建数据 使用的"index" 在article的索引下批量创建 已存在的ID会覆盖掉原先的文档,索引新的文档
POST _bulk
{"index":{"_index":"article","_type":"_doc","_id":4}}
{"id":4,"title":"lyf","content":"es学习666","tags":["java","ElasticSearch"],"creatime":"155601539274"}
{"index":{"_index":"article","_type":"_doc","_id":5}}
{"id":5,"title":"fyl","content":"es学习777","tags":["java","ElasticSearch"],"creatime":"155601539274"}
#批量删除
POST _bulk
{"delete":{"_index":"article","_type":"_doc","_id":4}}
{"delete":{"_index":"article","_type":"_doc","_id":5}}
#批量更新
POST _bulk
{"update":{"_index":"article","_type":"_doc","_id":4}}
{"doc":{"content":"批量更新ES"}}
{"update":{"_index":"article","_type":"_doc","_id":5}}
{"doc":{"title":"更新lyf"}}
}
批量添加,"created"对于已经存在的ID会报错,"index"对于已经存在的ID会覆盖原先的文档
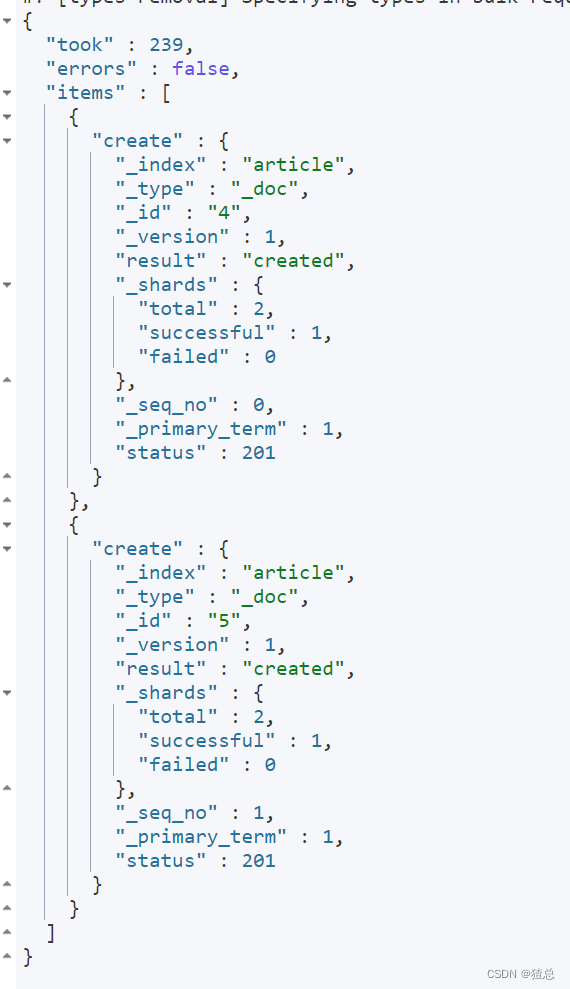
批量修改,“update”,不存在的文档会报错

九、批量读取
es的批量查询可以使用mget和msearch两种,其中mget是需要我们知道它的id,可以指定不同的index,也可以指定返回值source。msearch可以通过字段查询来进行一个批量的查找

_mget的使用
#批量读取不同index下的文档
GET _mget
{
"docs":[
{
"_index":"es_db",
"_id":1
},
{
"_index":"article",
"_id":4
}
]
}
#简化后读取es_db文档下指定的id
GET /es_db/_mget
{
"ids":["1","2"]
}
获取到的不同index下的结果

获取到的es_db下指定id的结果

_msearch的使用
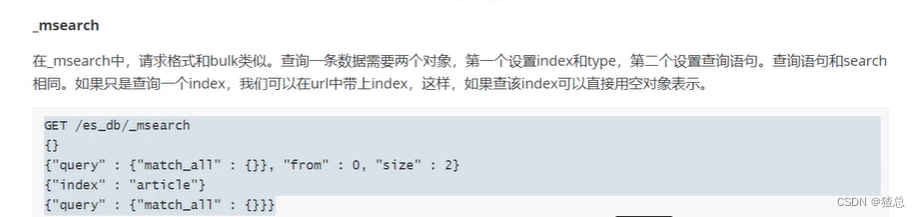
#查询es_db的前两条文档与article中的全部文档
GET /es_db/_msearch
{}
{"query":{"match_all":{}},"from":0,"size":2}
{"index":"article"}
{"query":{"match_all":{}}}
#查询es_db下的前两条文档与article下的title中有es的文档
GET /_msearch
{"index":"es_db"}
{"query":{"match_all":{}},"from":0,"size":2}
{"index":"article"}
{"query":{"match_all":{"title":"es"}}}
GET /es_db/_msearch

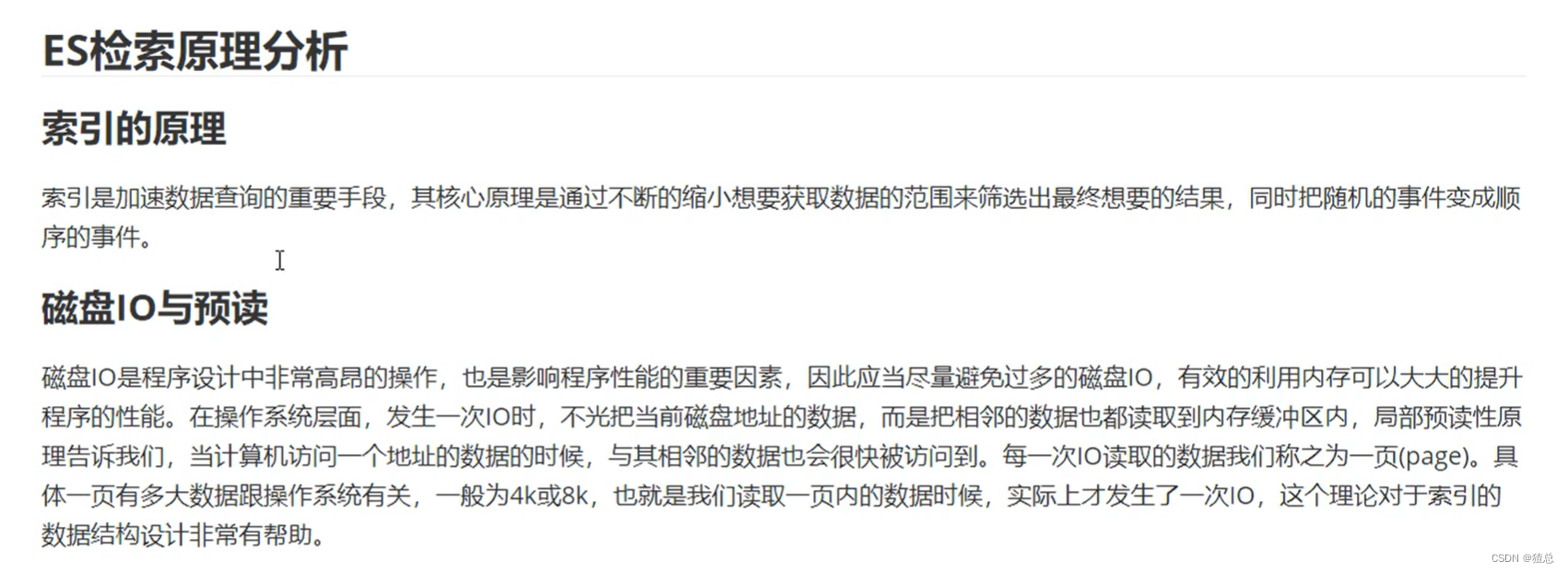
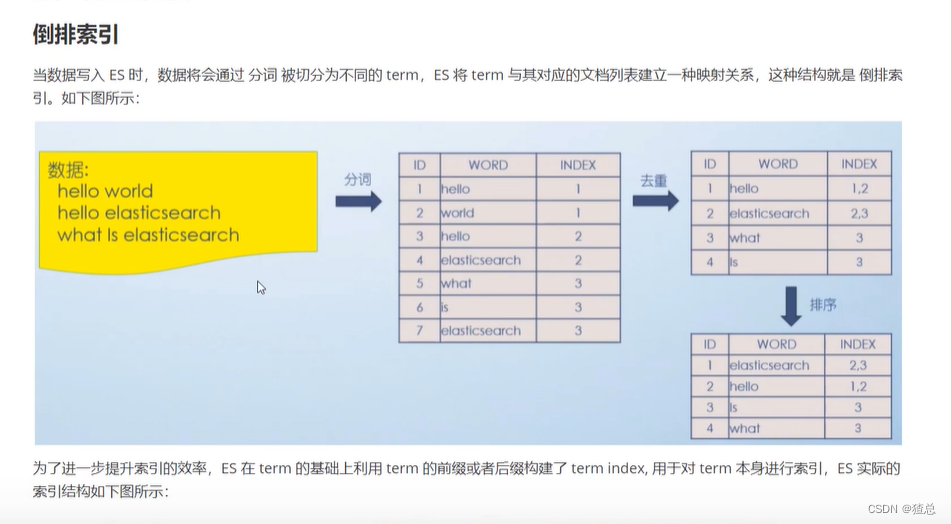
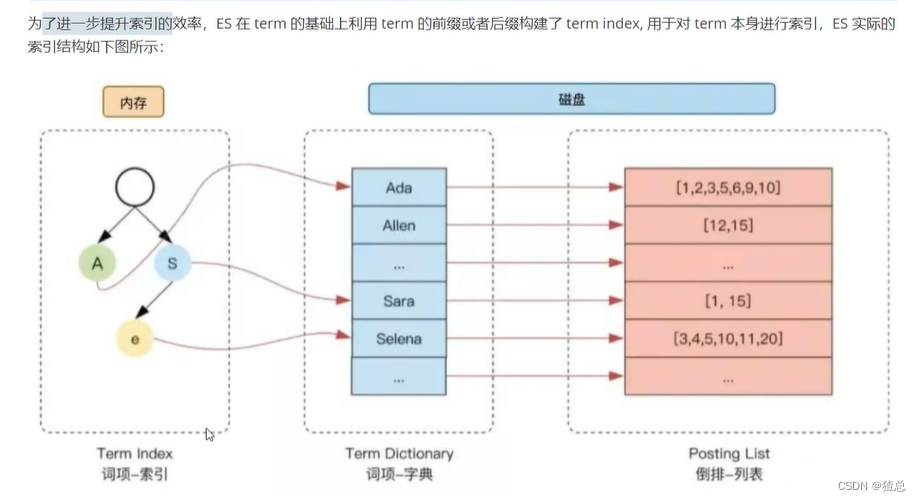
十、ES检索原理分析


十一、ES高级查询Query DSL
ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL(Domain Specified Language),Query DSL是利用Rest API传递JSON格式的请求体(RequestBody)数据与ES进行交互,这种方式的丰富查询语句让ES检索变得更加强大,更简洁
学习文档
语法
GET /es_db/_doc/_search (json请求体数据)
可以简化为下面写法
GET /es_db/_search (json请求体数据)
11.1示例数据
#指定ik分词器 重中之重!!!
PUT /es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type"
:"ik_max_word"
}
}
}
#创建文档,指定id
PUT /es_db/_doc/1
{
"name":"张三",
"sex":1,
"age":25,
"address":"天健湖",
"remark":"java developer"
}
PUT /es_db/_doc/2
{
"name":"李四",
"sex":1,
"age":30,
"address":"天健湖公园",
"remark":"java developer"
}
PUT /es_db/_doc/3
{
"name":"王五",
"sex":1,
"age":31,
"address":"郑州天健湖公园",
"remark":"java developer"
}
PUT /es_db/_doc/4
{
"name":"老六",
"sex":1,
"age":18,
"address":"郑州天健湖",
"remark":"java developer"
}
PUT /es_db/_doc/5
{
"name":"刘七",
"sex":1,
"age":40,
"address":"公园",
"remark":"java developer"
}
PUT /es_db/_doc/6
{
"name":"老八",
"sex":1,
"age":10,
"address":"郑州人民公园",
"remark":"java developer"
}
#根据ik分词器进行分词查询 如果没有使用分词器那么查天健湖公园查不到
GET /es_db/_search
{
"query":{
"match": {
"address": "天健湖公园"
}
}
}
#es默认的分词设置是standard,会单字拆分,不推荐使用,看好义务再选择
POST _analyze
{
"analyzer": "standard",
"text": "中华人民共和国"
}
单字拆分结果

ik分词器结果

11.2 查询所有match_all
使用matchc_all,默认只会返回10条数据
原因:_search查询默认采用的是分页查询,每页记录数size的默认值为10,想要显示更多数据,需要修改size
#查询索引es_db下id为1的文档
GET /es_db/_doc/1
#修改size为5,查询es_db下前5条数据(如果加入了from则代表从第5条开始,那么查询的为第二页的文档)
GET /es_db/_search
{
"query":{
"match_all":{}
},
"size":5,
"from":5
}
}
11.2.1 _search查询下的size属性大小解析
size属性是否可以无限增大?
否!在es的默认机制下,size属性最大值为10000,但是该size属性可以通过index.max_result_window进行修改
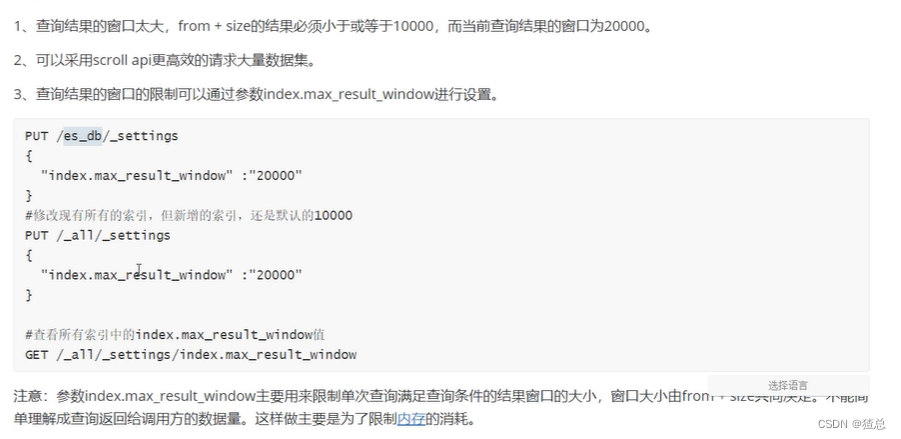

一般情况下,不建议使用from+size来对内存进行调整,es限制size的目的是为了限制内存的浪费,而如果需要处理大量的数据可以使用分页查询Scroll
11.3 ES深分页查询Scroll
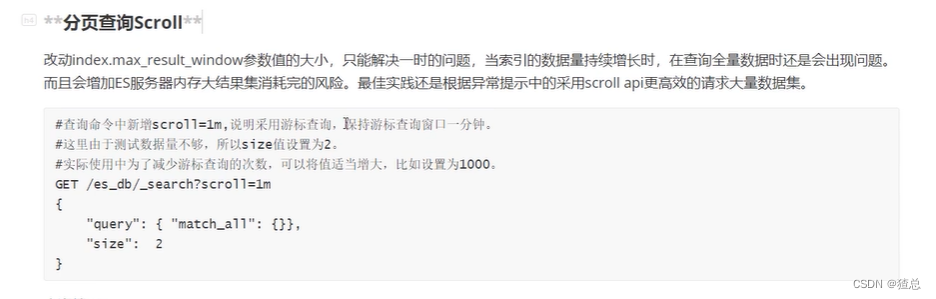
#scroll分页
GET /es_db/_search?scroll=1m
{
"query":{"match_all": {}},
"size":3
}
#通过_scroll_id再次获取
GET /_search/scroll
{
"scroll":"1m",
"scroll_id":
"FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFkFadmNCZUFlUUoyeVhjbElDaG42eEEAAAAAAAAd7RZSSVlqZUs0eFMzU2VGTFlmaWlFc0V3"
}
查询结果

11.4 排序sort与返回指定字段_source
降序desc,升序asc
#通过age做降序
GET /es_db/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"age":"desc"
}
]
}
#排序与分页组合
GET /es_db/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"age":"desc"
}
],
"from":5,
"size":5
}
#返回指定字段_source
GET /es_db/_search
{
"query": {
"match_all":{}
},
"_source": ["name","address"]
}
十二、各种查询操作
12.1 match匹配

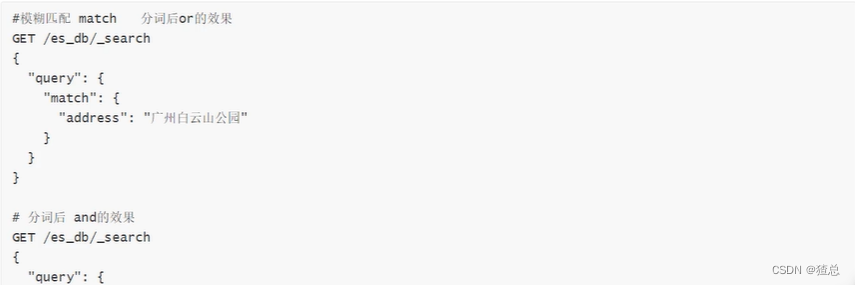

#match查询 or关系 会查询郑州或者公园
GET /es_db/_search
{
"query": {
"match":{
"address": "郑州公园"
}
}
}
#match查询 and关系
GET /es_db/_search
{
"query": {
"match":{
"address":{
"query": "郑州公园",
"operator": "and"
}
}
}
}
#match查询 匹配3个词 可以让结果更加精确
GET /es_db/_search
{
"query": {
"match":{
"address":{
"query": "天健湖公园",
"minimum_should_match": 3
}
}
}
}
查询结果
or关系:会查询带有"郑州"或者"公园"两个关键字的文档
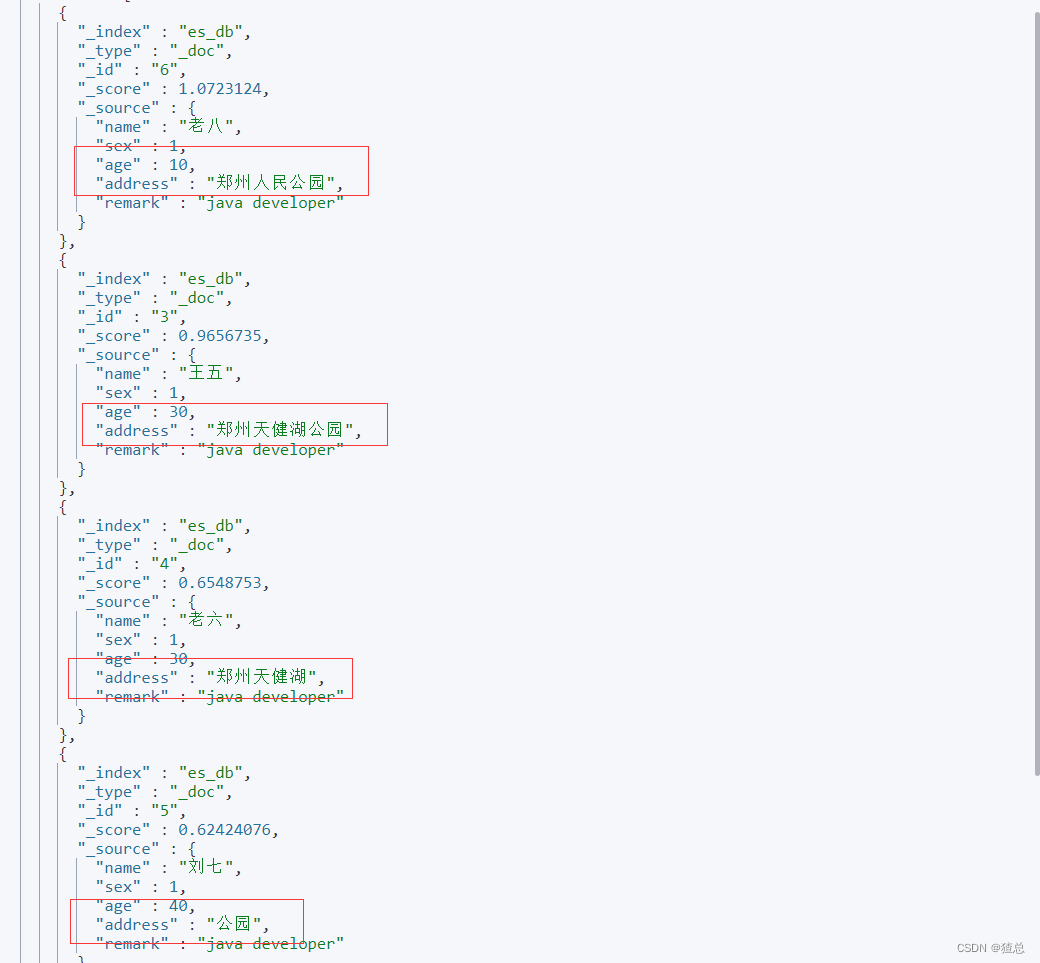
and关系:会查询包含有"郑州"和"公园"两个关键字的文档

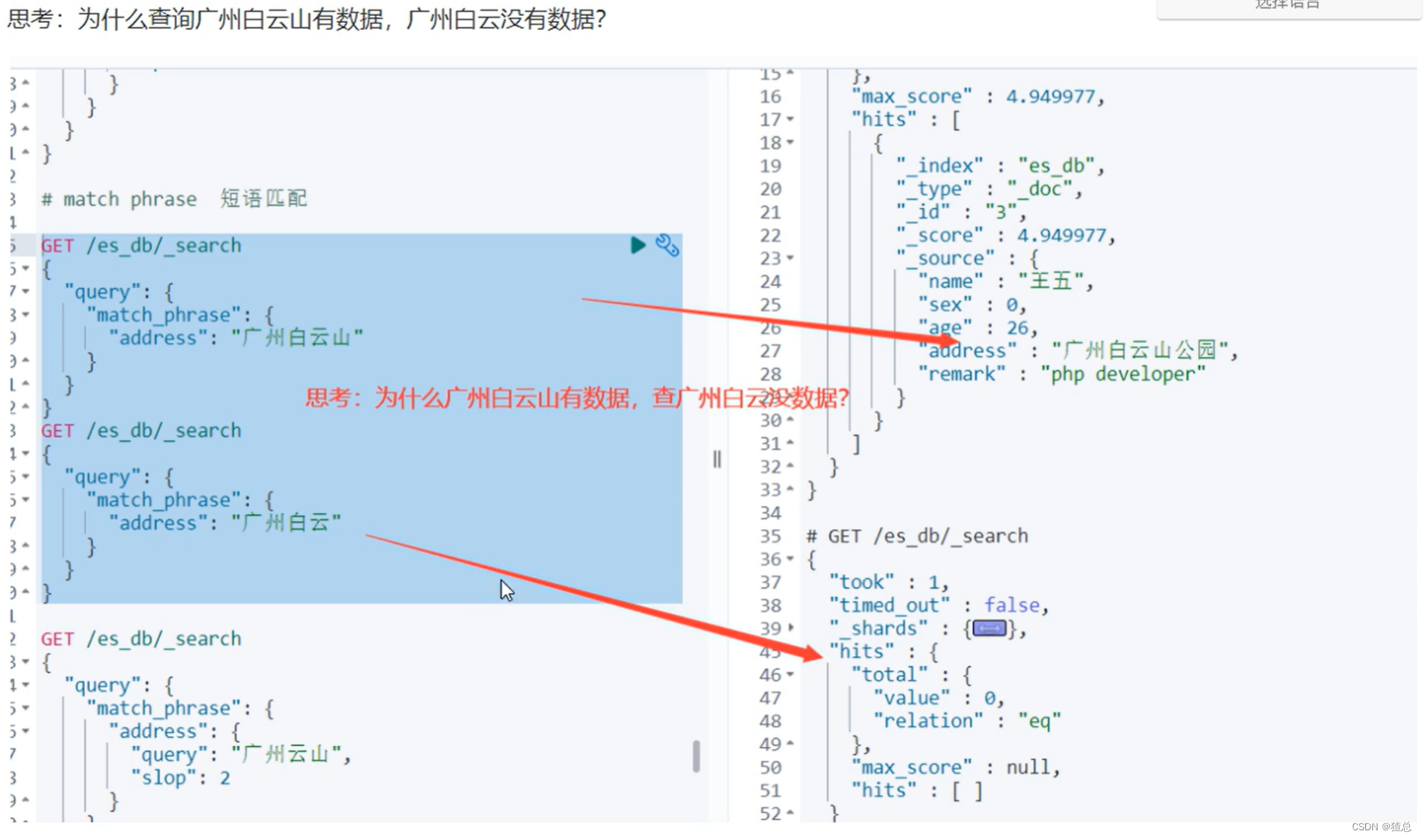
12.2 短语匹配match_phrase
与match的区别:对分词以后的顺序有要求,顺序必须与分词的顺序相同,而match并没有这样要求



#match匹配
GET /es_db/_search
{
"query": {
"match": {
"address": "郑州天健湖"
}
}
}
#match_phrase短语匹配,匹配相邻的词条
GET /es_db/_search
{
"query": {
"match_phrase": {
"address": "郑州天健湖"
}
}
}
#match_phrase短语匹配,slop解决词条间隔问题 (词条间隔2条仍然能匹配到)
#比如查询广州白云无数据,但是查询广州白云山有,原因是广州与白云山为相邻词条,使用slop可以查询到白云
GET /es_db/_search
{
"query": {
"match_phrase": {
"address": {
"query": "郑州天健",
"slop": 2
}
}
}
}
match匹配结果,发现只要带有郑州或者天健湖就会被查询到

match_phrase短语匹配结果:发现郑州在前,天健湖在后才能匹配上

12.3 多字段匹配multi_match
可以根据字段类型,决定是否使用分词查询,得分最高的在前面

#多字段匹配multi_match 通过指定需要查询的文档属性,查询满足当前值的所有文档
GET /es_db/_search
{
"query": {
"multi_match": {
"query": "郑州老六",
"fields": [
"address",
"name"
]
}
}
}

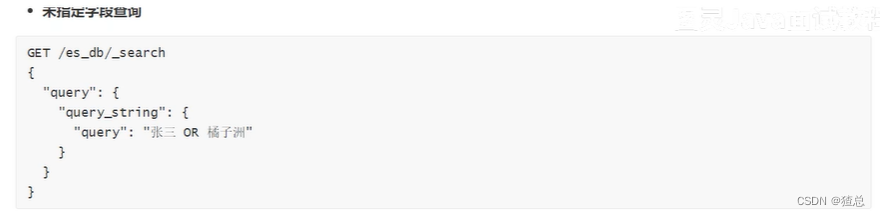
12.4 query_string查询
允许我们在单个查询字符串中指定AND | OR | NOT条件,同时也和multi_match query一样,支持多字段搜索。match需要指定字段名,query_string是在所有字段中搜索,范围更广泛
注意:插叙你断分词就将查询条件分词查询,查询字段不分词将查询条件不分词查询。全部都需要大写
#query string 不指定字段查询
GET /es_db/_search
{
"query": {
"query_string": {
"query": "老六 OR 天健 OR 公园"
}
}
}
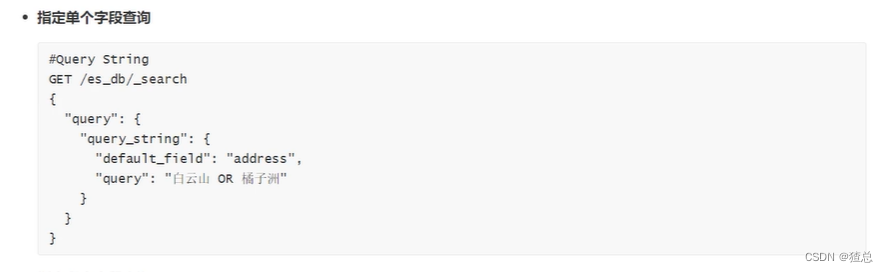
#query string 指定单个字段查询
GET /es_db/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "天健 OR 公园"
}
}
}
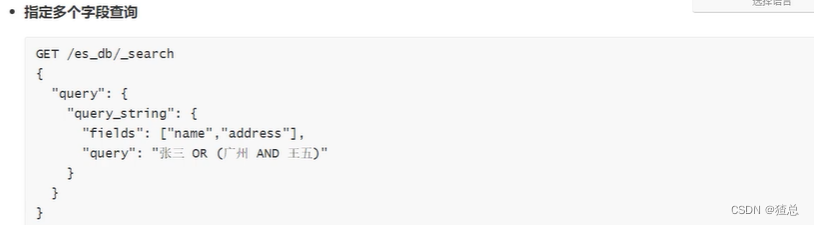
#query string 指定多个字段查询
GET /es_db/_search
{
"query": {
"query_string": {
"fields": ["name","address"],
"query": "天健 OR (郑州 AND 公园)"
}
}
}
12.5 simple_query_string查询
类似Query String,但是会忽略错误的语法,同时只支持部分查询语句,不支持AND OR NOT,会当作字符串处理。
+ 替代AND
| 替代OR
- 替代NOT
全部都需要大写
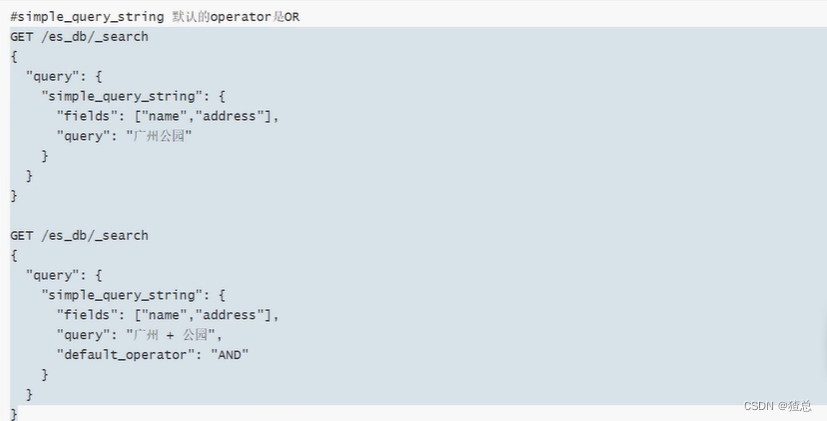
#simple_query_string默认为OR,使用下列操作改为AND,而且必须大写
GET /es_db/_search
{
"query": {
"simple_query_string": {
"fields": ["name","address"],
"query": "郑州公园",
"default_operator":"AND"
}
}
}
GET /es_db/_search
{
"query": {
"simple_query_string": {
"fields": ["name","address"],
"query": "郑州 + 公园",
}
}
}
十三、关键字查询Term

使用keyword,"广州白云山公园”为一个整体,不再分词

如果不用keyword,查iPhone则为小写iphone,无法查询到结果。如果想要查iPhone则需要用到keyword

#keywords的使用
#使用keyword不再进行分词,为一个整体
GET /product/_search
{
"query":{
"term": {
"address.keyword": {
"value": "郑州天健湖公园"
}
}
}
}
#查询英文不用keywords默认为小写
GET /product/_search
{
"query":{
"term": {
"productName.keyword": {
"value": "iPhone"
}
}
}
}
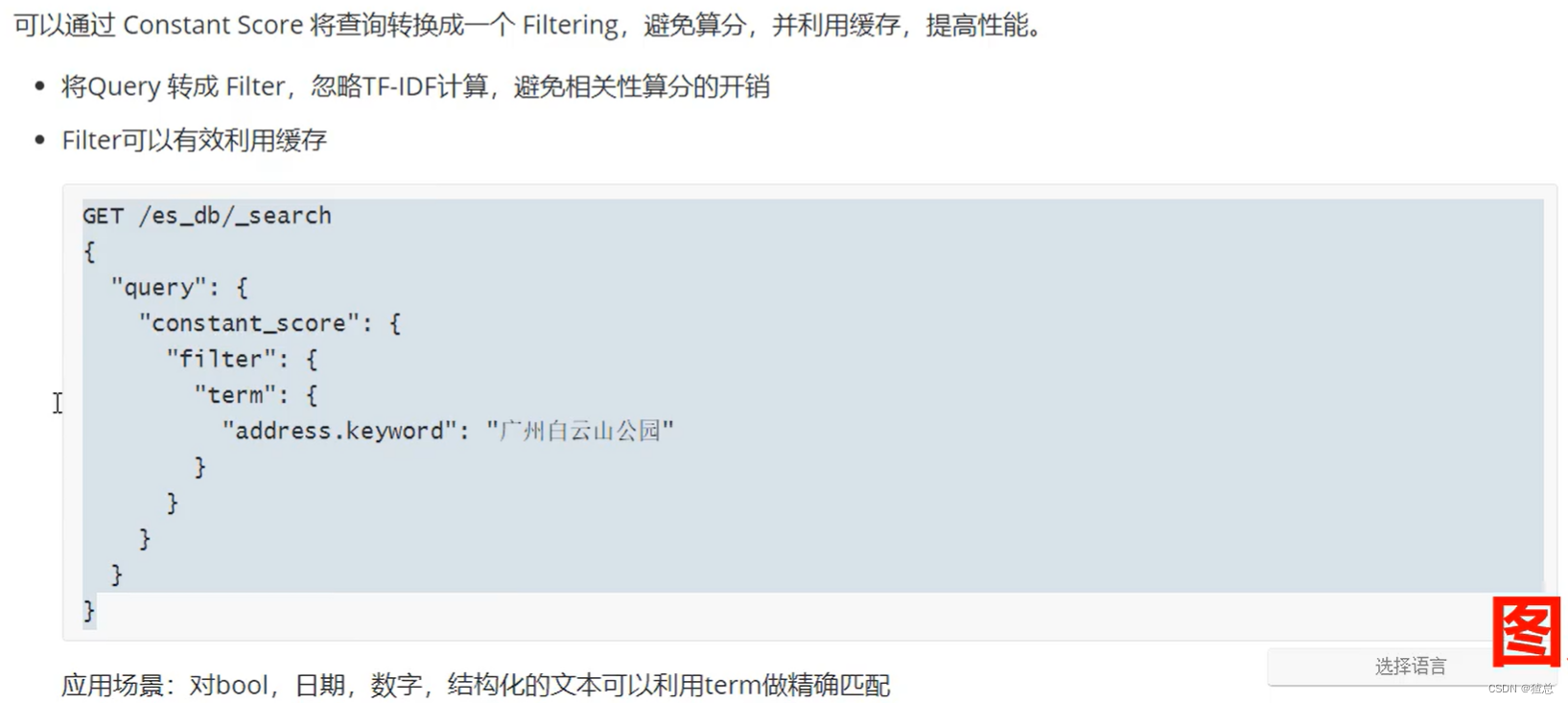

#使用Constant Score转换为Filtering避免算分,查询结果max_score为1.0
GET /es_db/_search
{
"query":{
"constant_score": {
"filter": {
"term": {
"address.keyword": "郑州天健湖公园"
}
}
}
}
}
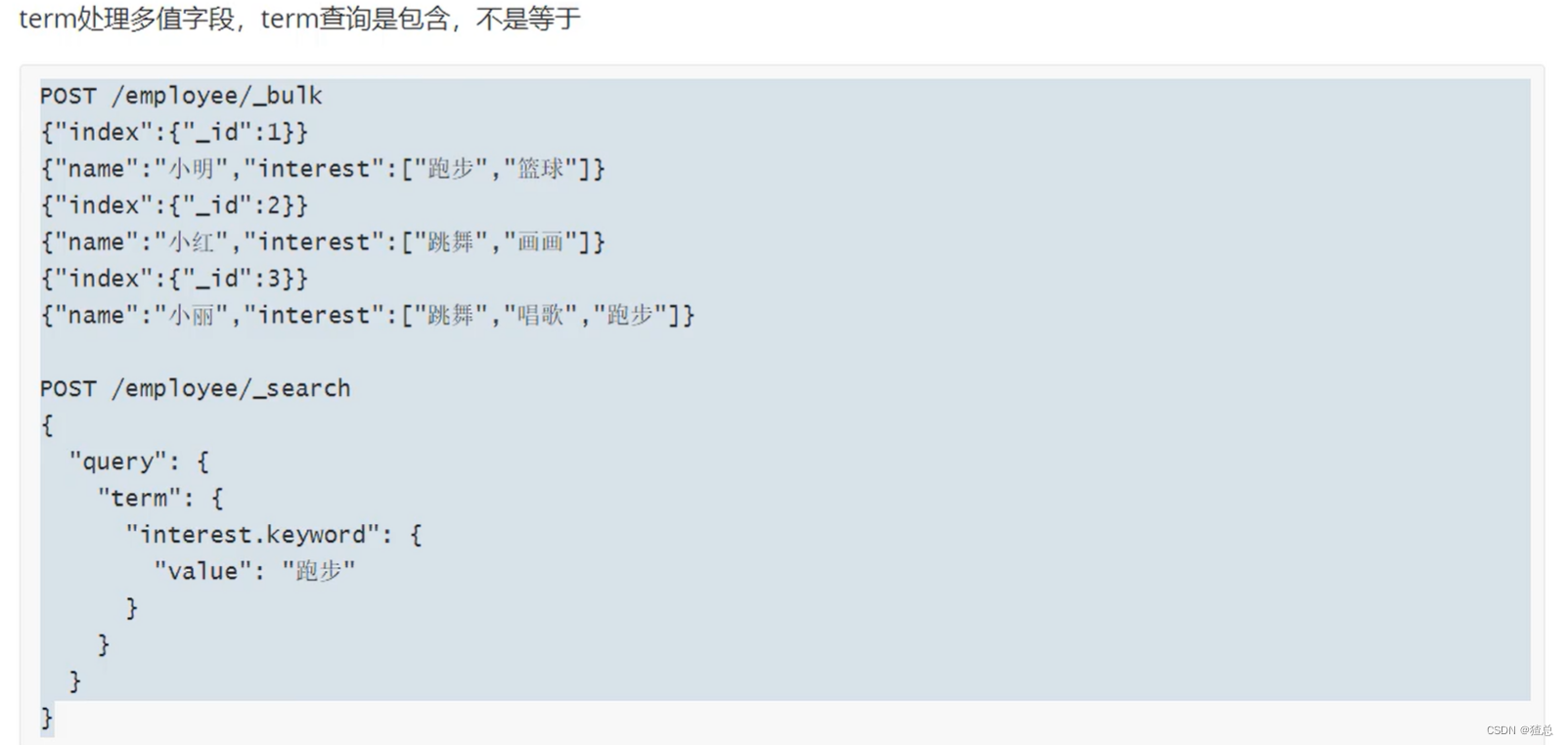
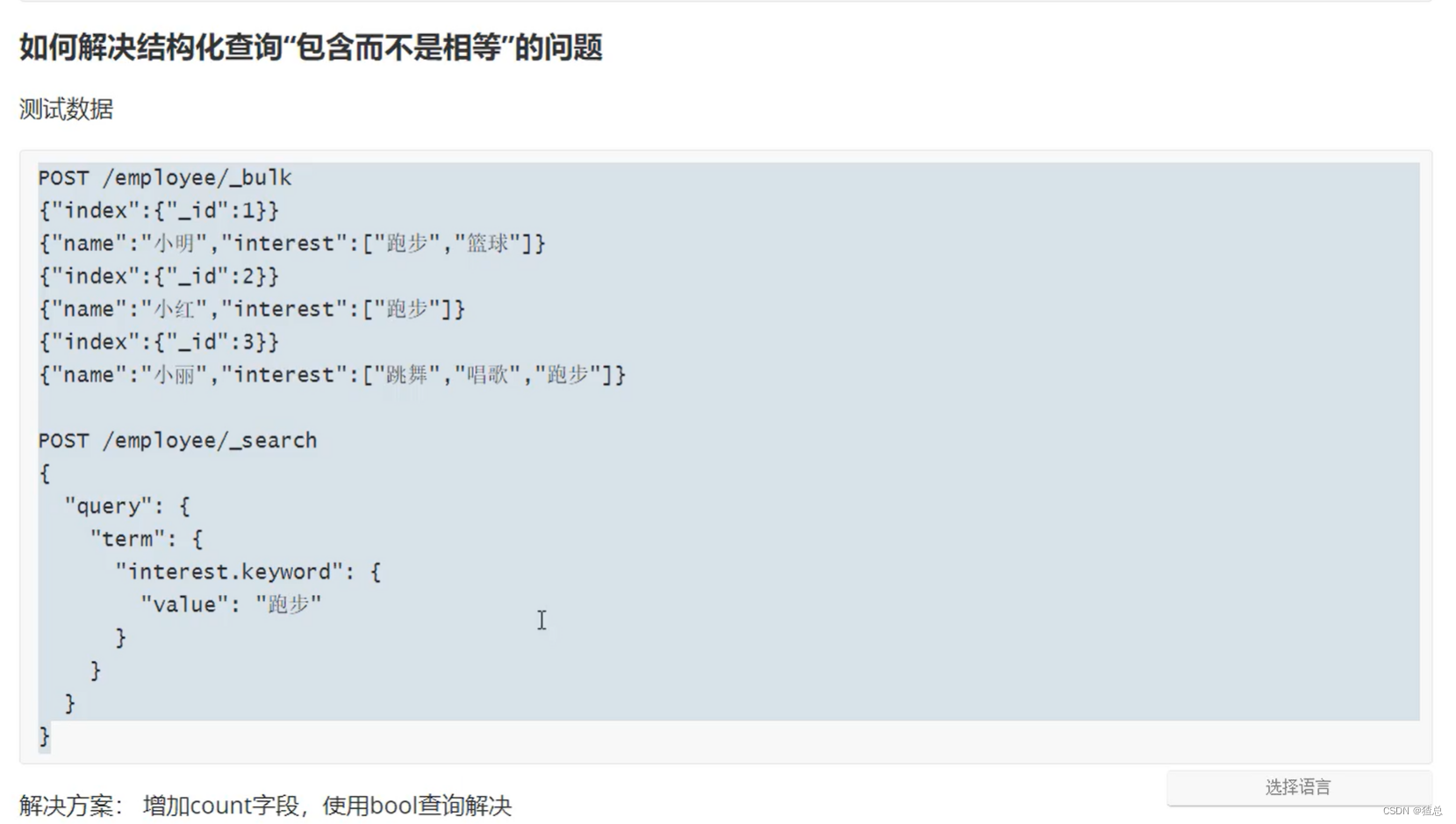
#处理多值字段,结果显示是包含而不是相等(只要带有该值即可)
POST /employee/_bulk
{"index":{"_id":1}}
{"name":"小明","interest":["跑步","篮球"]}
{"index":{"_id":2}}
{"name":"小红","interest":["跳舞","唱歌"]}
{"index":{"_id":3}}
{"name":"小刚","interest":["篮球","跳舞","跑步"]}
POST /employee/_search
{
"query": {
"term": {
"interest.keyword": {
"value": "跑步"
}
}
}
}
这样做可以有效的提高性能,利用缓存
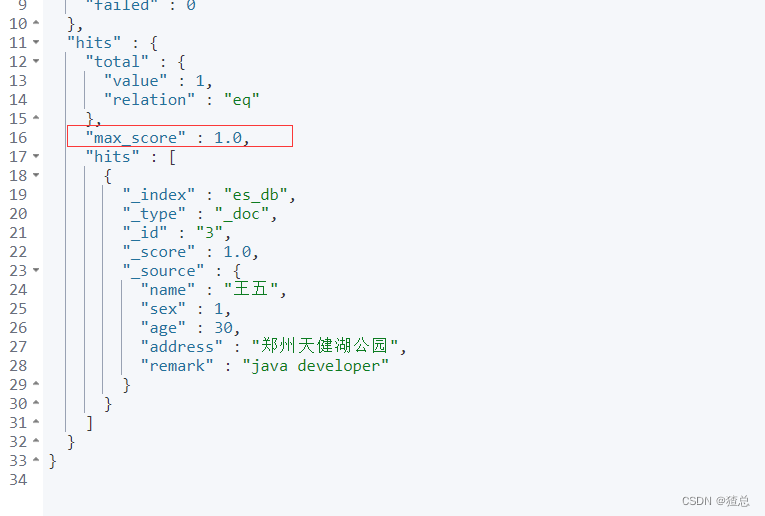
处理多指字段,包含"跑步"即可

十四、prefix前缀搜索与wildcard通配符查询
14.1 prefix前缀搜索
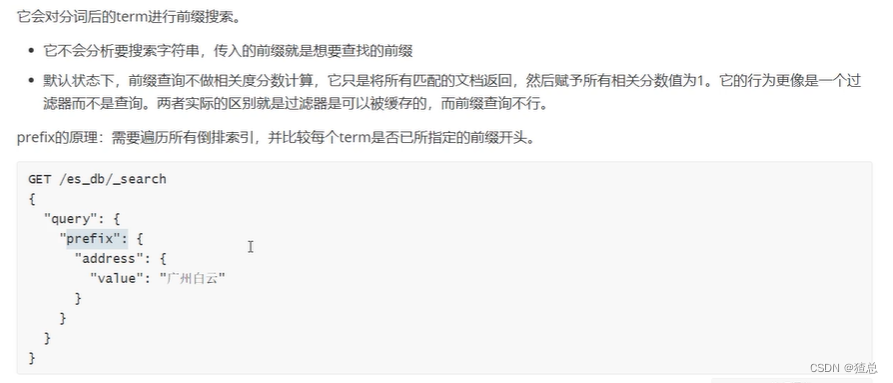
#prefix前缀搜索 如果要有结果的话那一定是某一个值的前缀
GET /es_db/_search
{
"query": {
"prefix": {
"address": {
"value": "天"
}
}
}
}
14.2 wildcard通配符查询
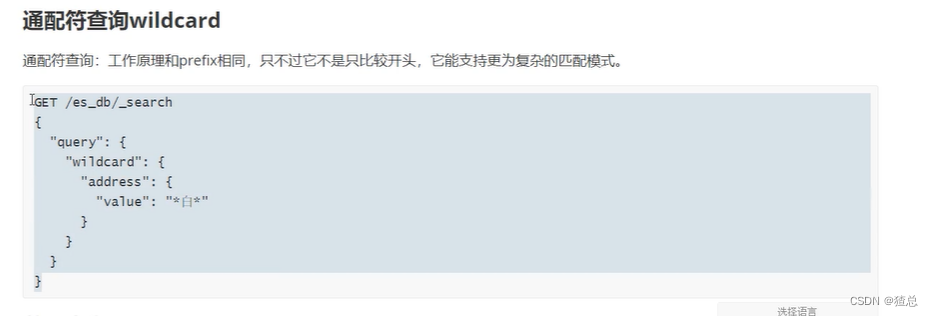
#wildcard通配符查询
GET /es_db/_search
{
"query": {
"wildcard": {
"address": {
"value": "*健*"
}
}
}
}
十五、范围查询range
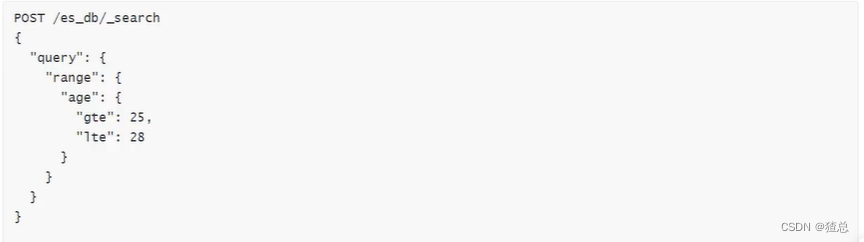
查询年龄为25到28(包含)的文档
查询年龄为25到28的文档,但是按照年龄降序,只查2名,查看他们的"name",“age”,"book"属性

查询当前时间-2年,2020年往后的数据

十六、多id查询ids
ids关键字:值为数组类型,用来根据一组id获取多个对应的文档
#多id查询ids
GET /es_db/_search
{
"query": {
"ids":{
"values": [1,2]
}
}
}

十七、模糊查询fuzzy
在实际的搜索中,我们有时候会打错字,从而导致搜索不到。在ElasticSearch中,我们可以使用fuzziness属性来进行模糊查询,从而达到搜索有错别字的情形



#模糊查询 fuzziness:2 可以错两个字
GET /es_db/_search
{
"query": {
"fuzzy": {
"address": {
"value": "田健壶",
"fuzziness": 2
}
}
}
}

十八、高亮hightlight(可以在搜索到匹配文档字段数据时变色,很常见的功能)
18.1 高亮的使用
18.2 高亮查询

指定ik分词器
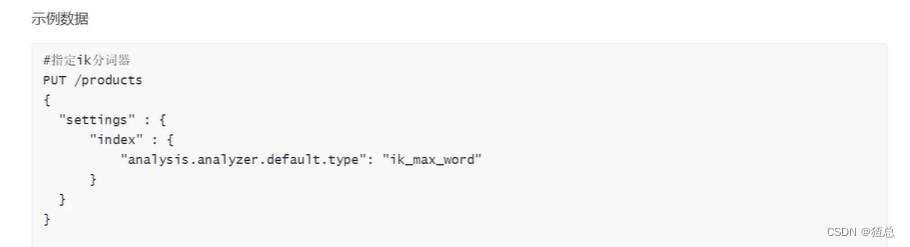
添加数据


数据测试

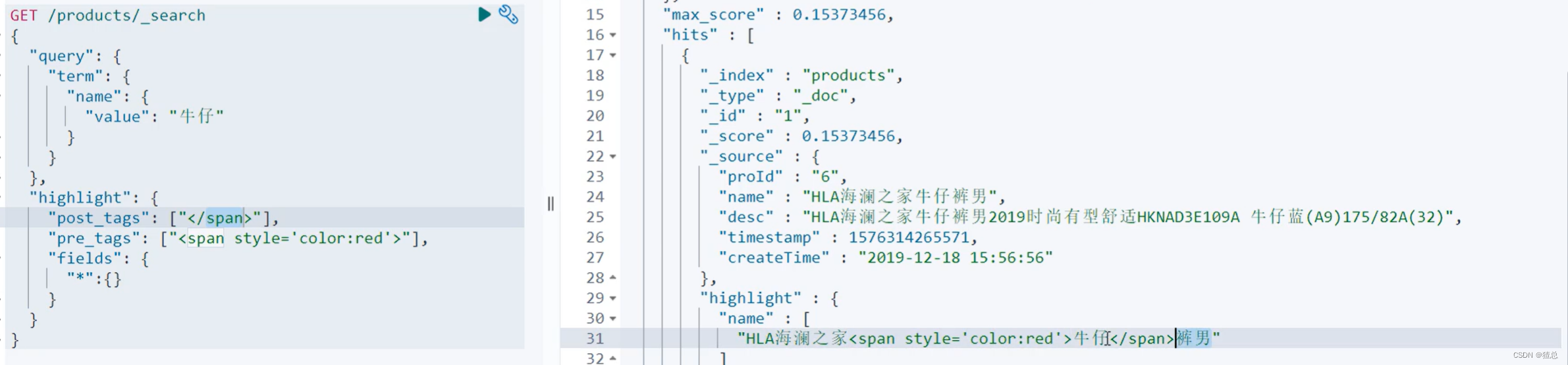
require_field_match(需要属性字段匹配) 默认为true,如果为true,只有当前字段完成hightlight
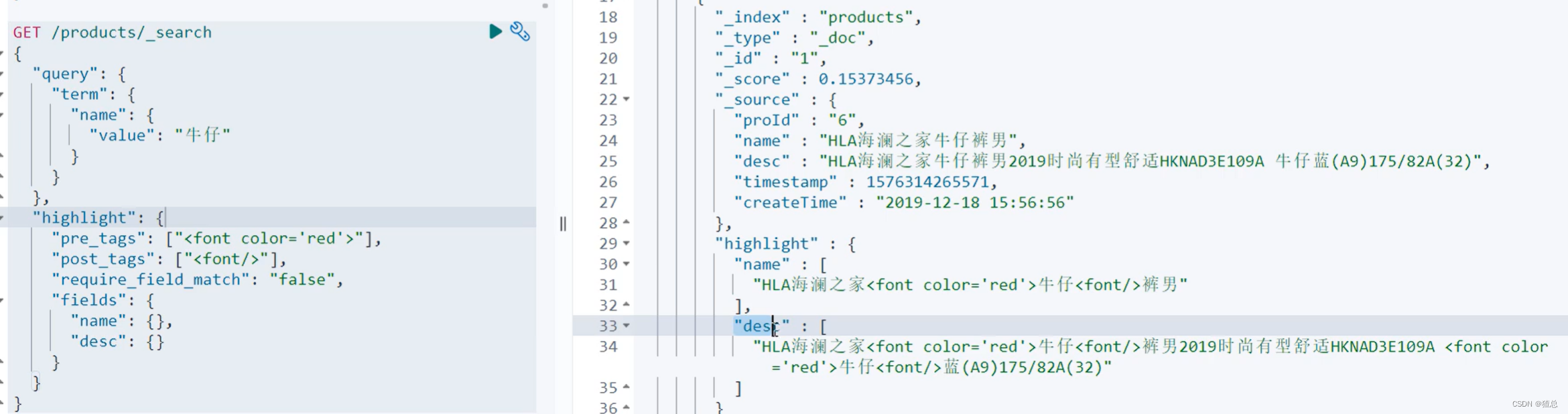
require_field_match(需要属性字段匹配) 默认为false,可以实现多字段完成一个heightlight
高亮功能的使用!!!很重要
十九、相关性和相关性算分

19.1 相关性(Relevance)
搜索的相关性算分,描述了一个文档和查询语句匹配的程度。ES会对每个匹配查询条件的结果进行算分_score
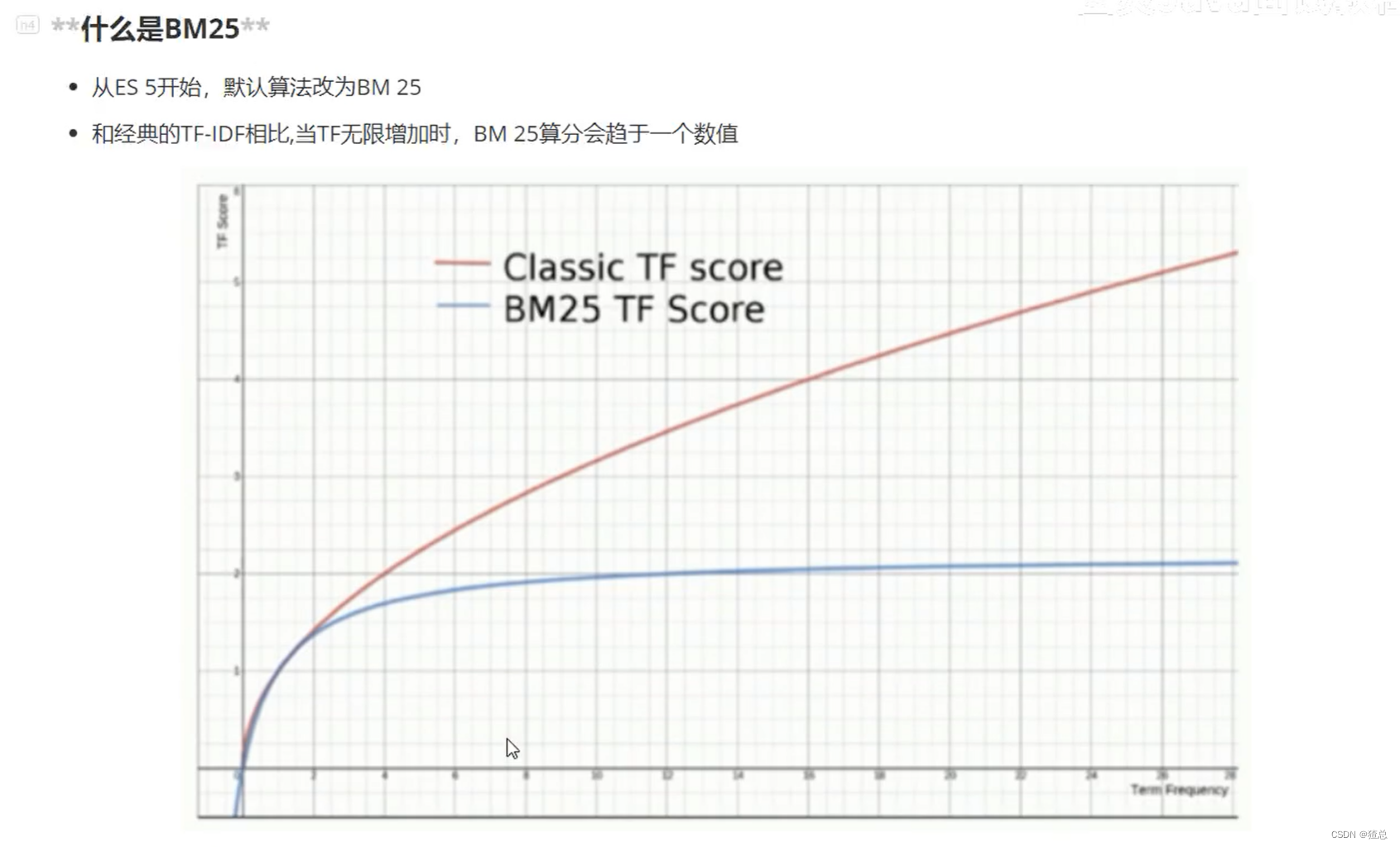
打分的本质是排序,需要把最符合用户需求的文档排在前面。ES 5之前,默认的相关性算分采用TF-IDF,现在采用BM 25

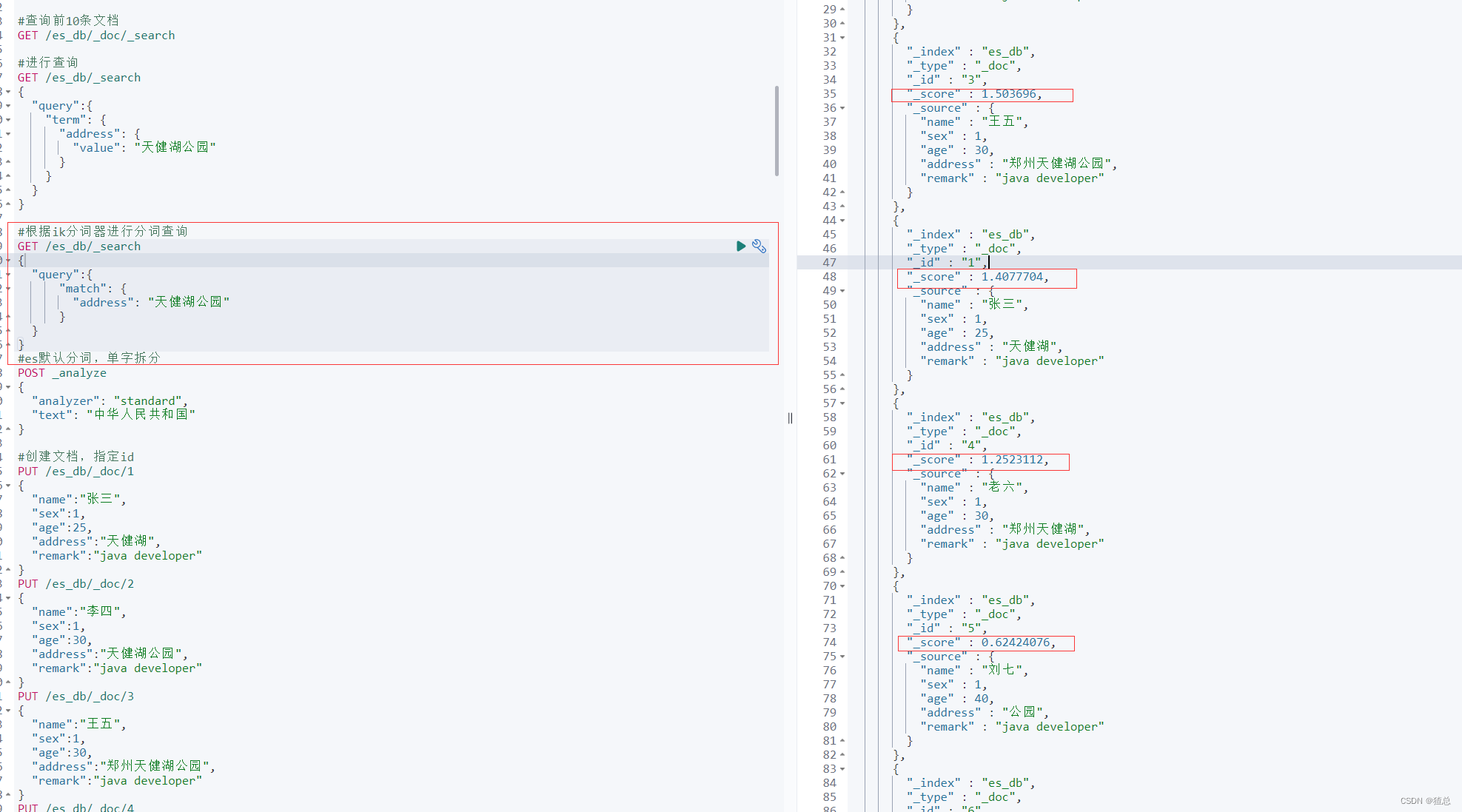
TF-IDF

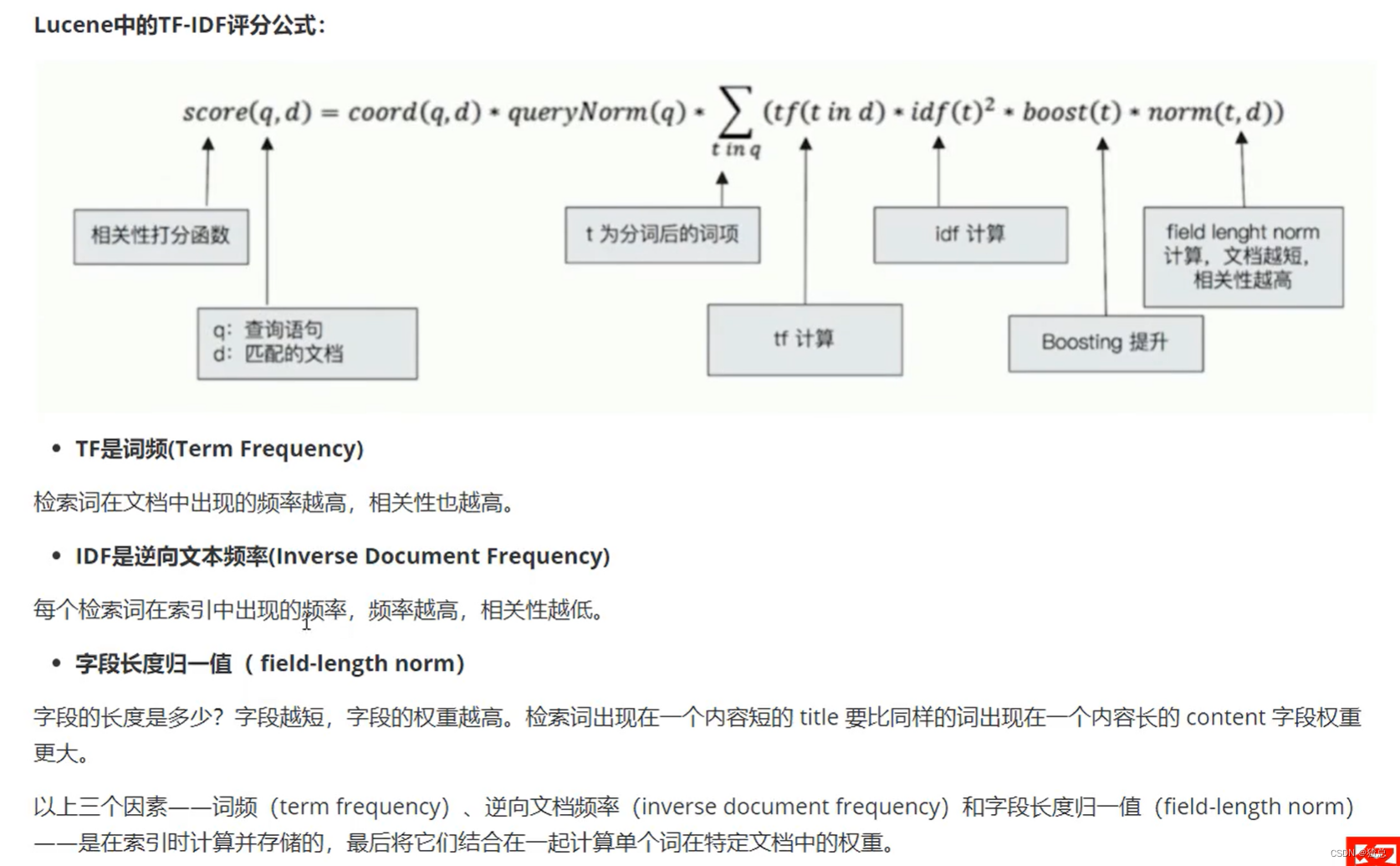
BM 25
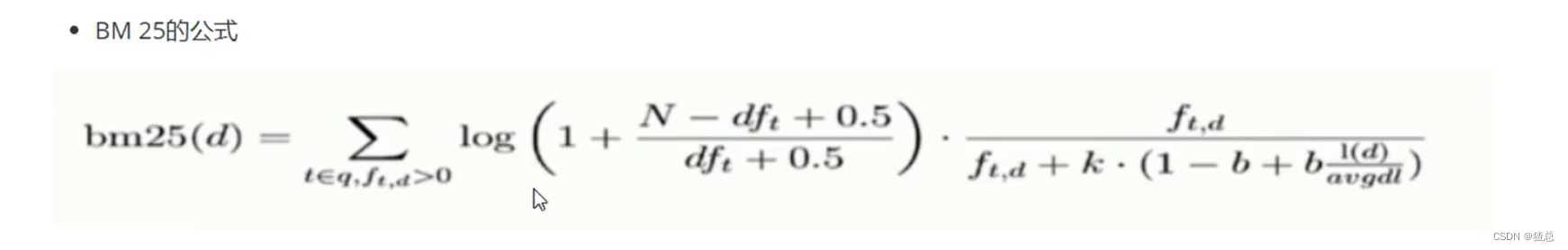
通过Explain API查看TF-IDF
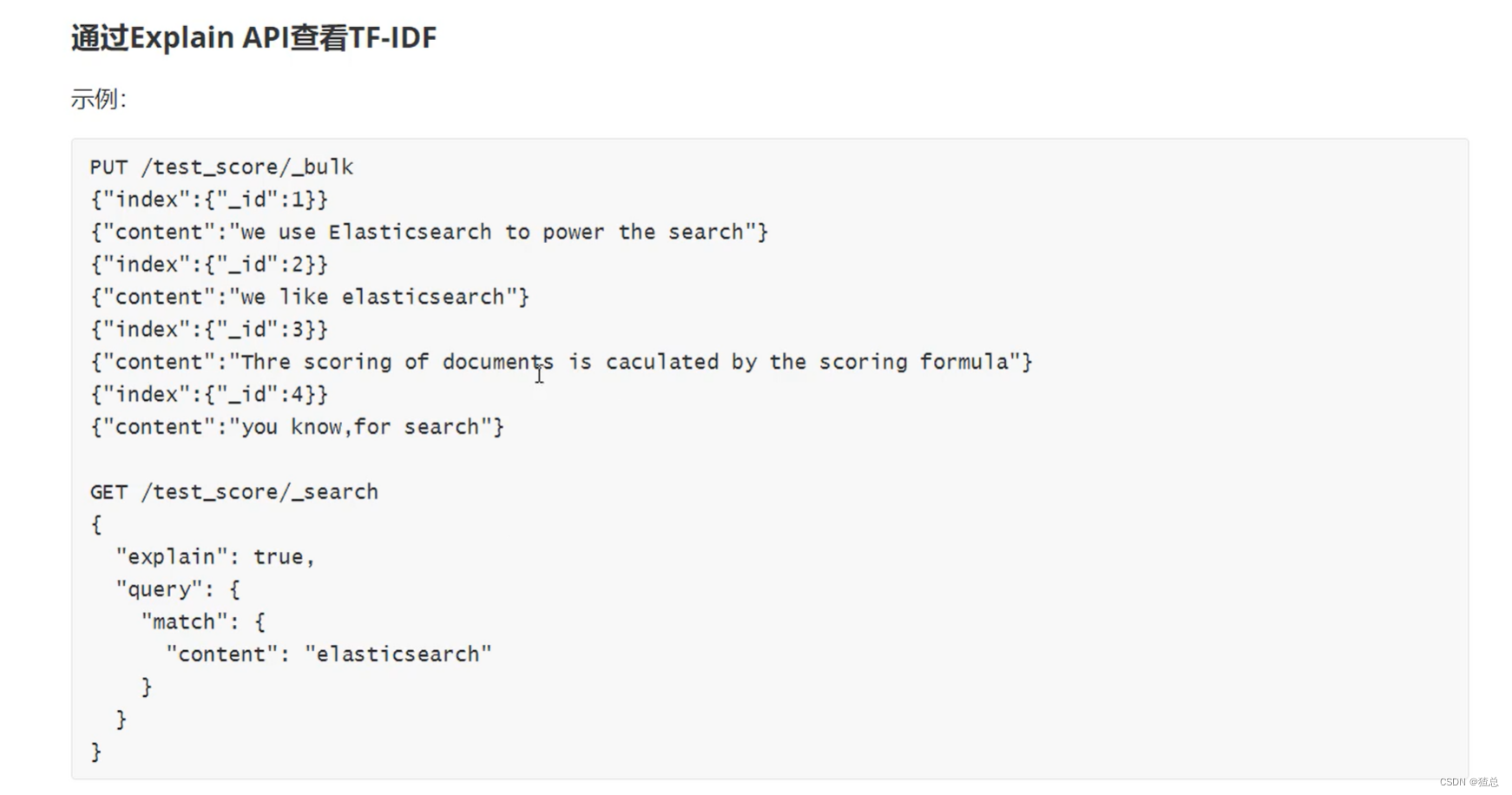
Boosting Relevance
应用场景:把不需要查询的文档但又会被查出来的文档往后放,让需要查询的文档靠前


当negative_boost为1时(正常情况),包含了该项数据的结果靠前了
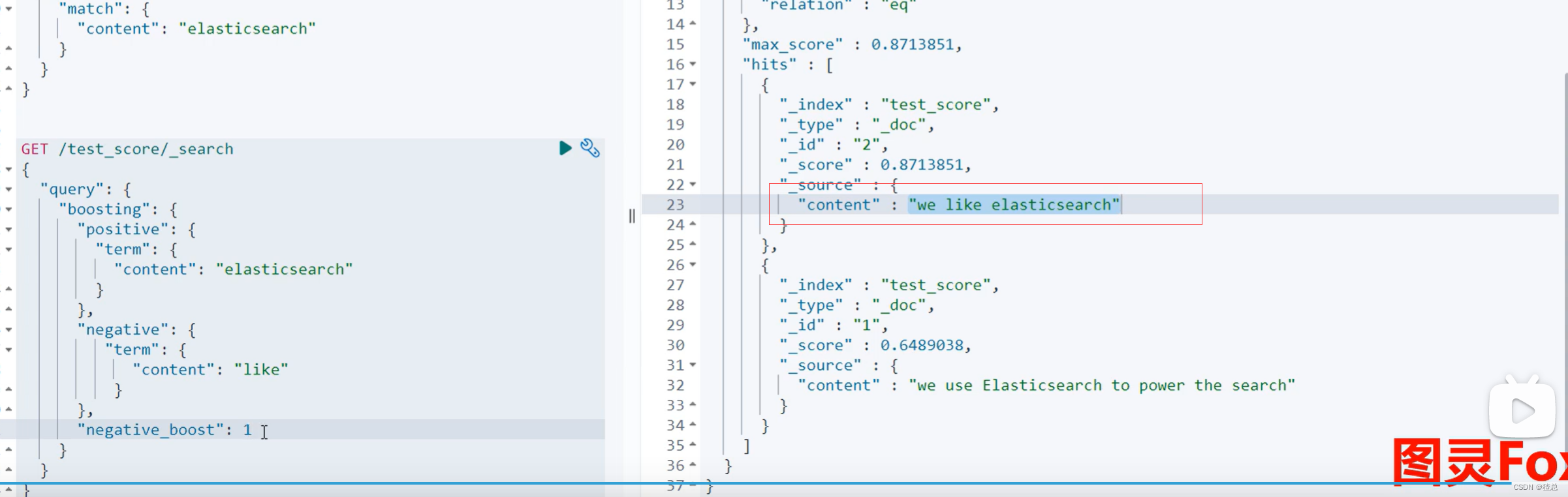
当negative_boost为0.5时,包含了该项数据的结果靠后了,把不需要的数据往后放了
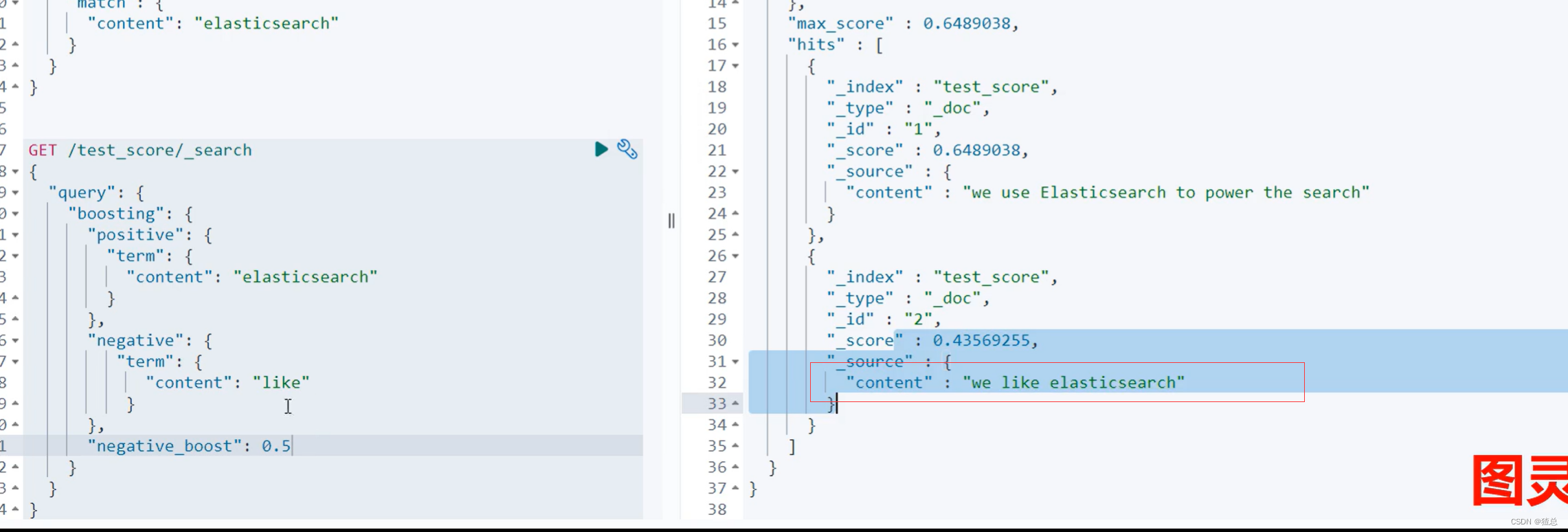
二十、布尔查询bool Query


# must 必须匹配天健湖公园,并且性别为1,进行算分
GET /es_db/_search
{
"query": {
"bool": {
"must":[
{
"term": {
"sex": {
"value": 1
}
}
},
{
"match":{
"address": "天健湖公园"
}
}
]
}
}
}
# filter 不进行算分
GET /es_db/_search
{
"query": {
"bool": {
"filter":[
{
"term": {
"sex": {
"value": 1
}
}
},
{
"match":{
"address": "天健湖公园"
}
}
]
}
}
}
# should sex为1或者address为天健湖公园,只要符合其中一个就可以
#如果写了"minimum_should_match": 1,则代表至少要匹配上一个,2的话在这里代表全部都要匹配
GET /es_db/_search
{
"query": {
"bool": {
"should":[
{
"term": {
"sex": {
"value": 1
}
}
},
{
"match":{
"address": "天健湖公园"
}
}
],
"minimum_should_match": 2
}
}
}
# must_not,不满足当前条件的,满足条件的不匹配,不满足才匹配
GET /es_db/_search
{
"query": {
"bool": {
"must_not":[
{
"term": {
"sex": {
"value": 0
}
}
},
{
"match":{
"address": "公园"
}
}
]
}
}
}
must必须匹配,相当于&&,进行算分

filter必须匹配,不进行算分
should,相当于 ||,进行算分
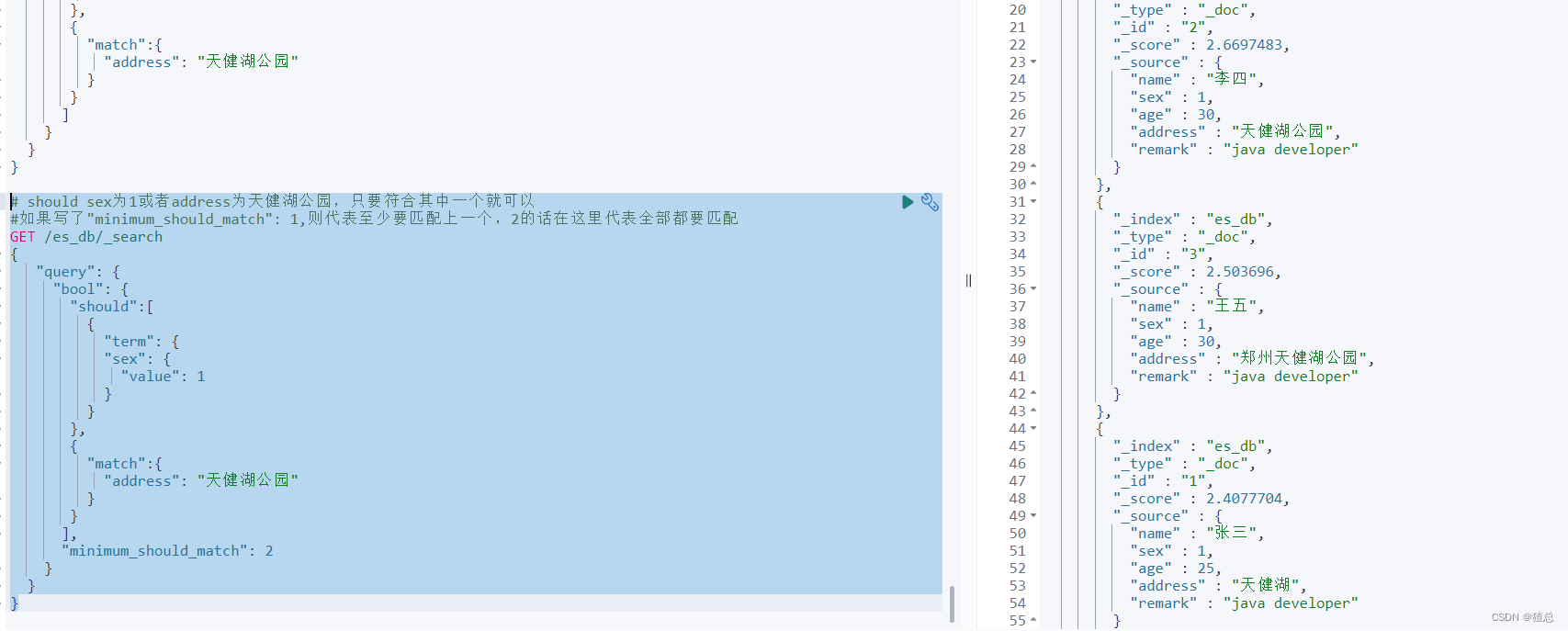
must_not,相当于!,不满足当前条件的,不进行算分
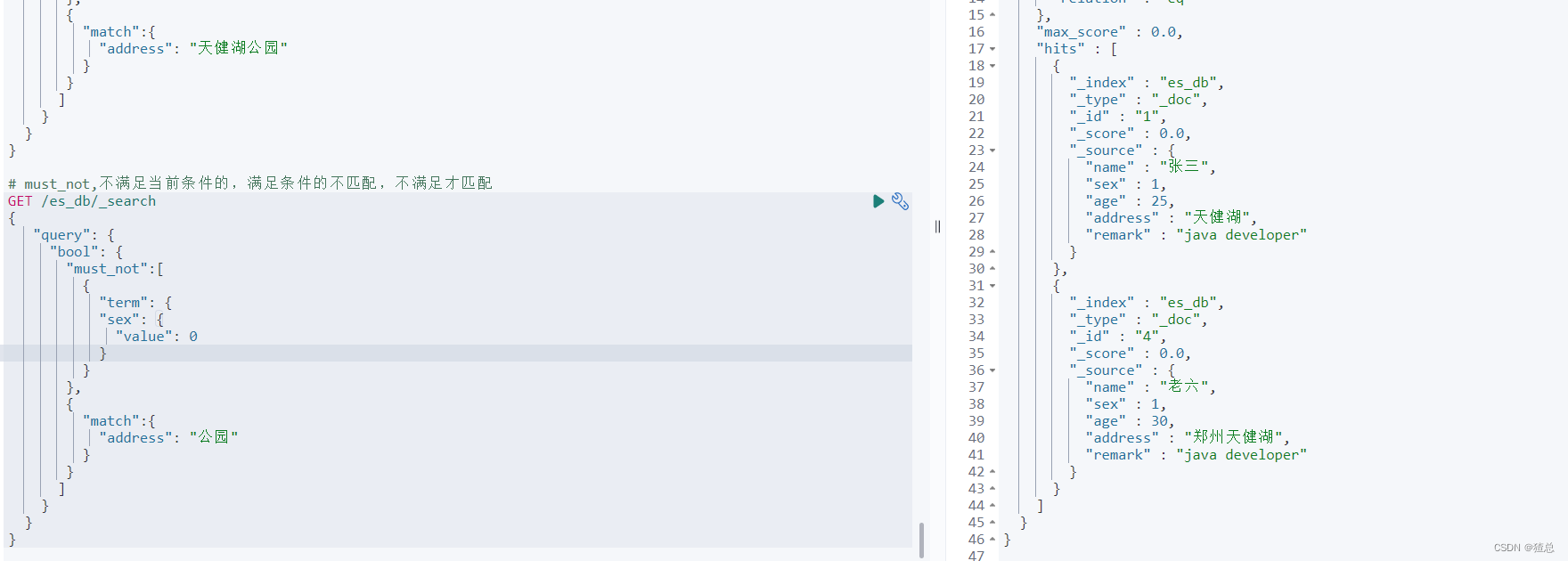
混合使用
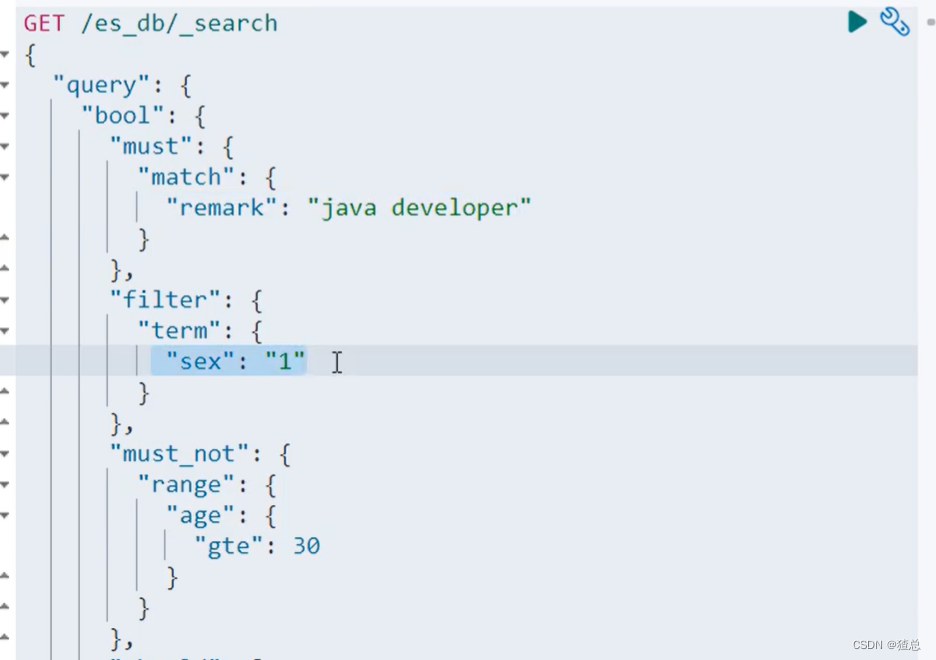
首先,“remark"必须为"java developer”,性别必须为"1",年龄不能大于等于(小于)30,然后再匹配"广州天河公园"或者是"广州白云山公园",最少满足一个条件,因为使用了keyword所以不分词

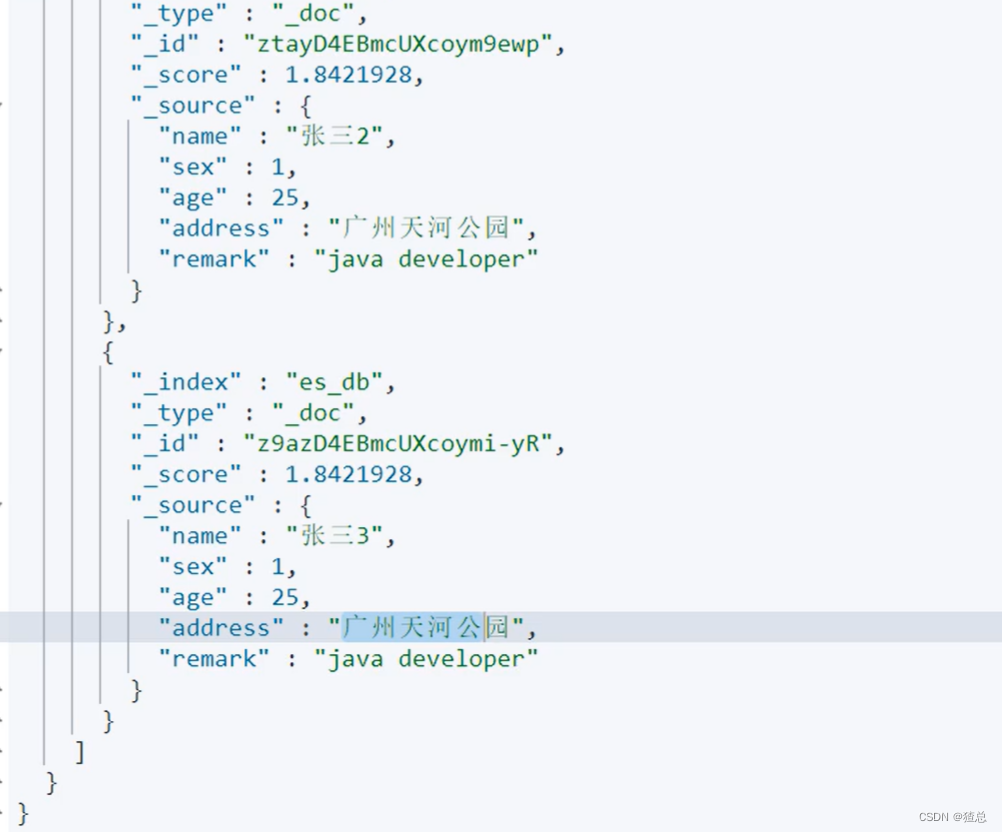
结果显示
二十、如何解决结构化问题“包含而不是相等”
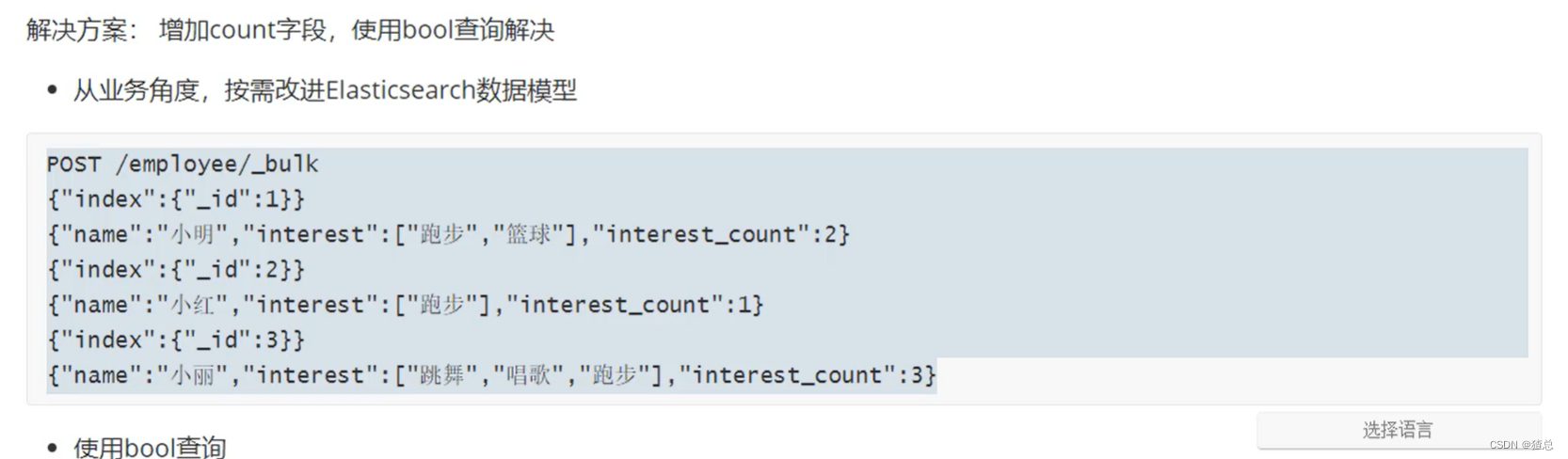
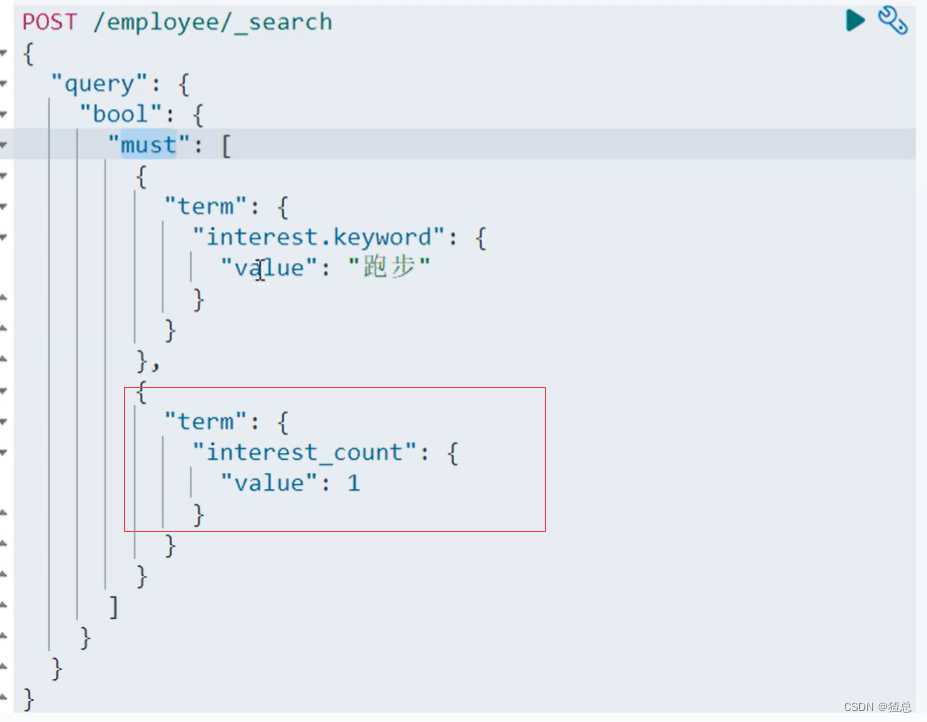
可以指定"interest_count",几个爱好数

查询的时候查询"interest_cout"为1,即可查询到爱好只有跑步的文档
二十一、控制字段的Boosting
21.1 利用bool嵌套实现should not逻辑(bool中的shuold再嵌套bool,实现must not)
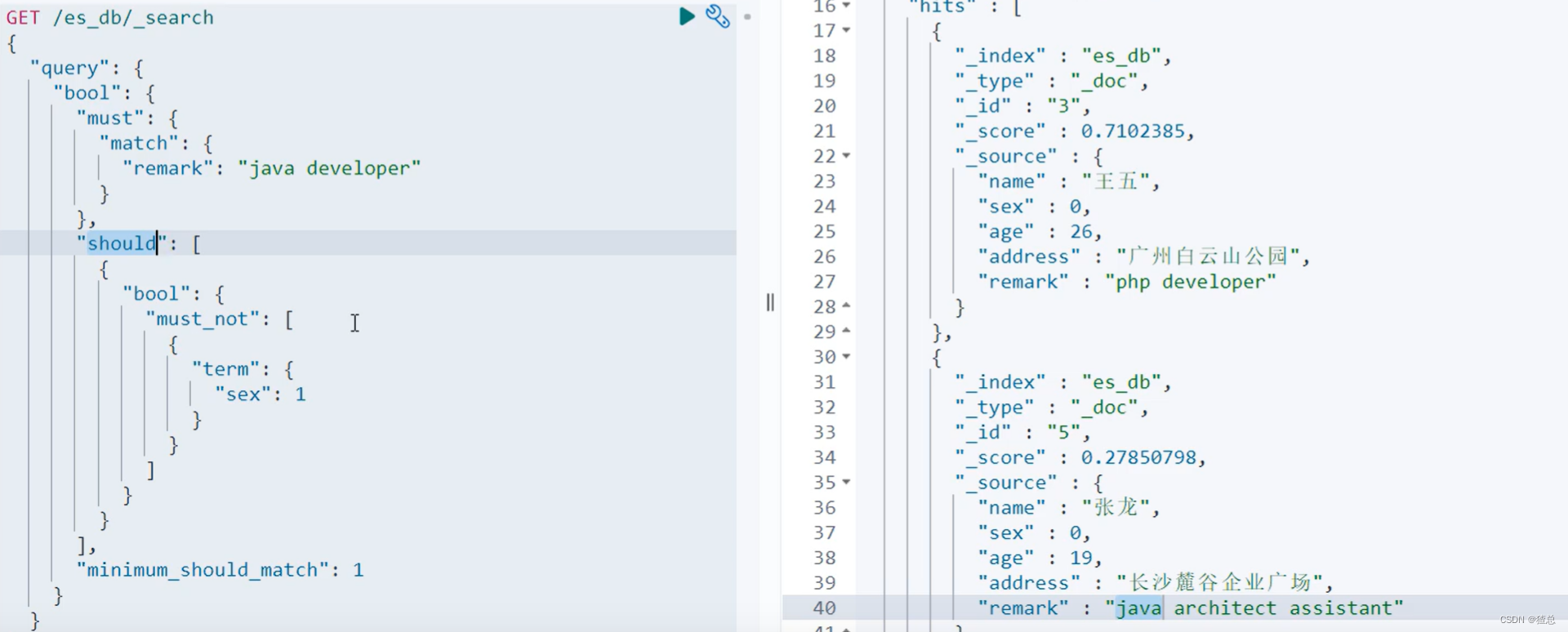
必须匹配"remark"为"java developer"的,并且should满足其中一个,在should中再次嵌套"bool",并且在"bool"中取"must_not",性别不为"1"的
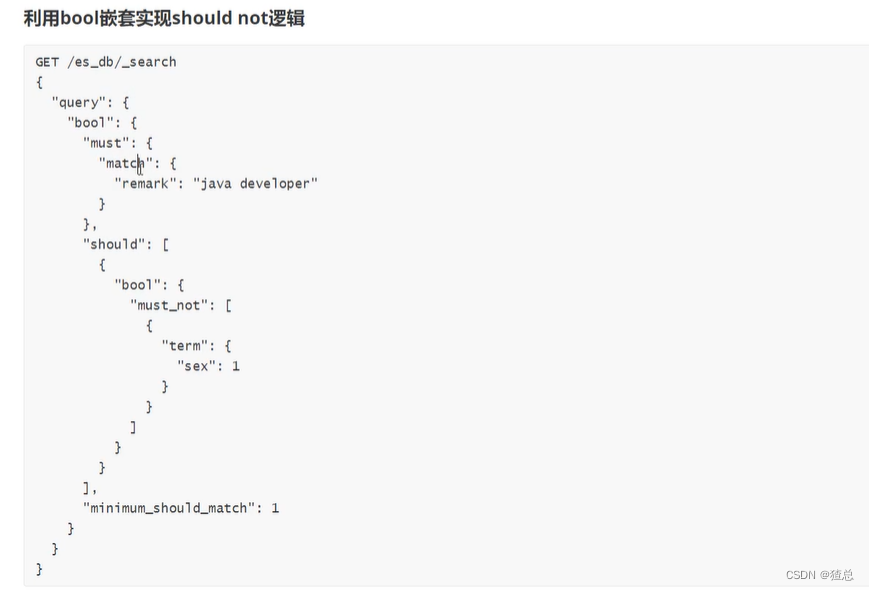
查询结果
21.2 使用should通过boost来对不同字段的相关性进行算分
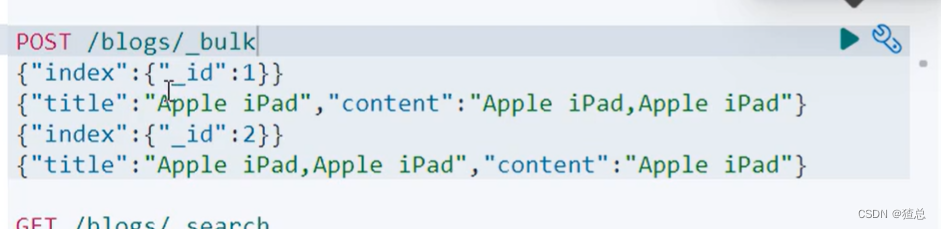
设置"content"的"boost"为4,相关性比"title"高,则主要根据"content"中的内容进行排序,内容越贴近分越高
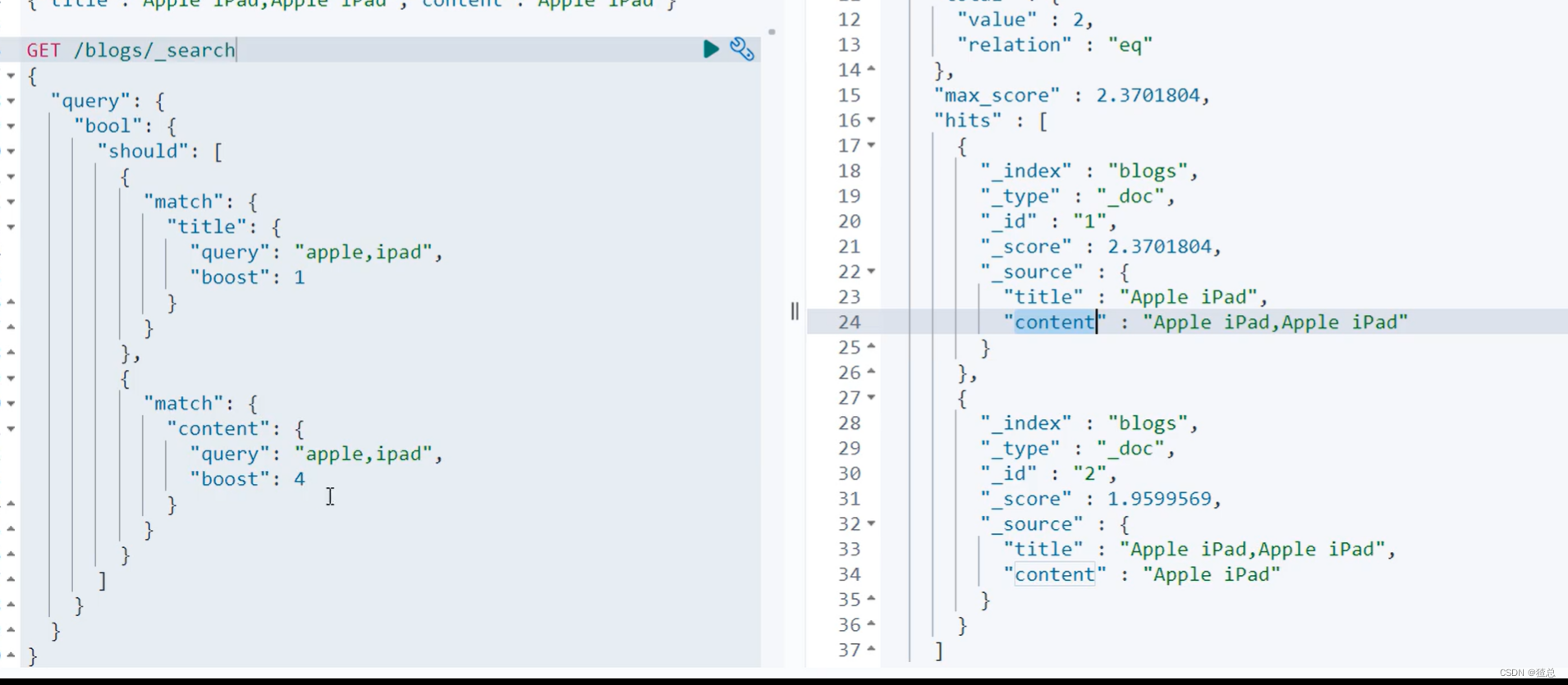
21.3 利用must not排除不需要的文档 或者 降低它的相关性
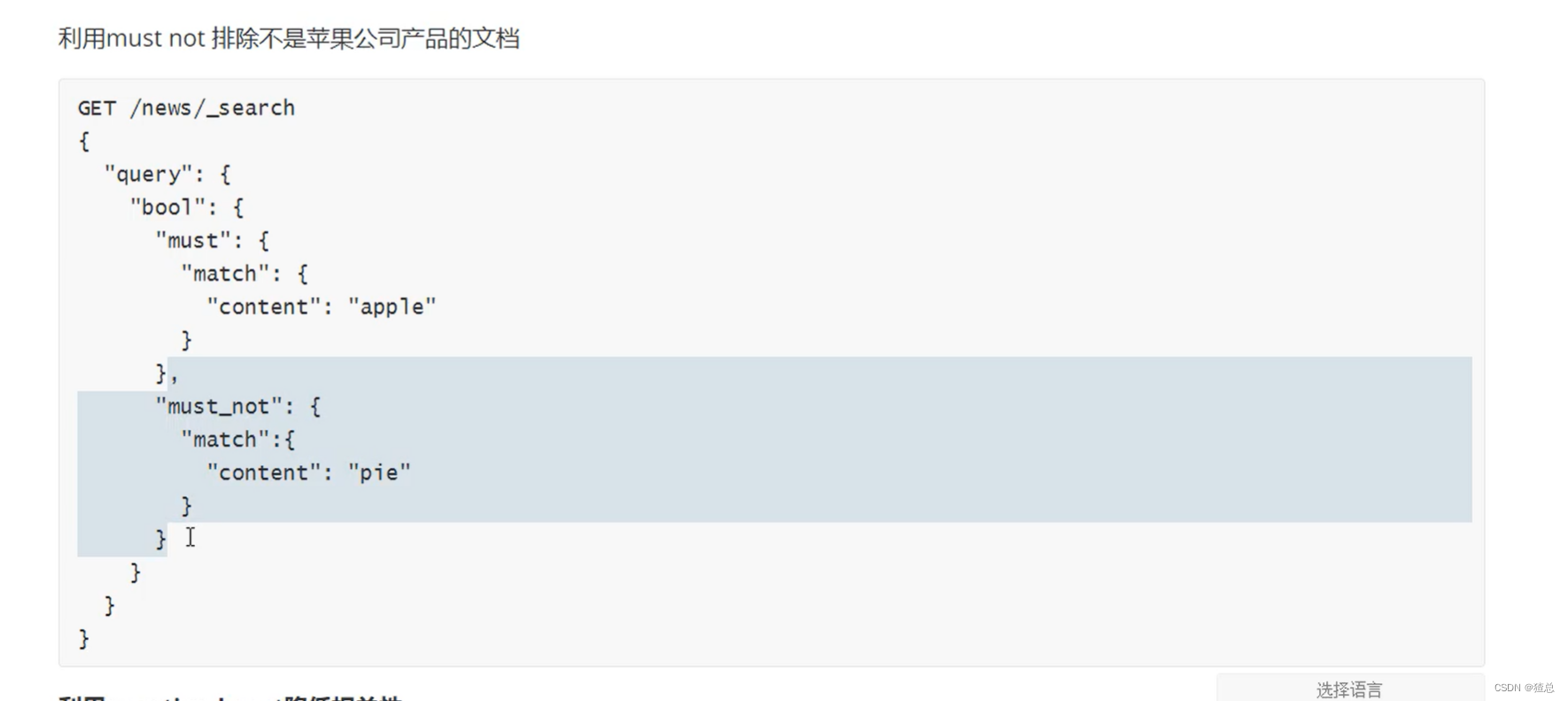
must not排除不需要的文档
想要展示的数据是苹果公司产品而不是苹果派和苹果汁,但是查询结果苹果派和苹果汁,apple的词频更高,所以在前面
使用must not来排除pie,这样可以排除"content"中带有pie的文档
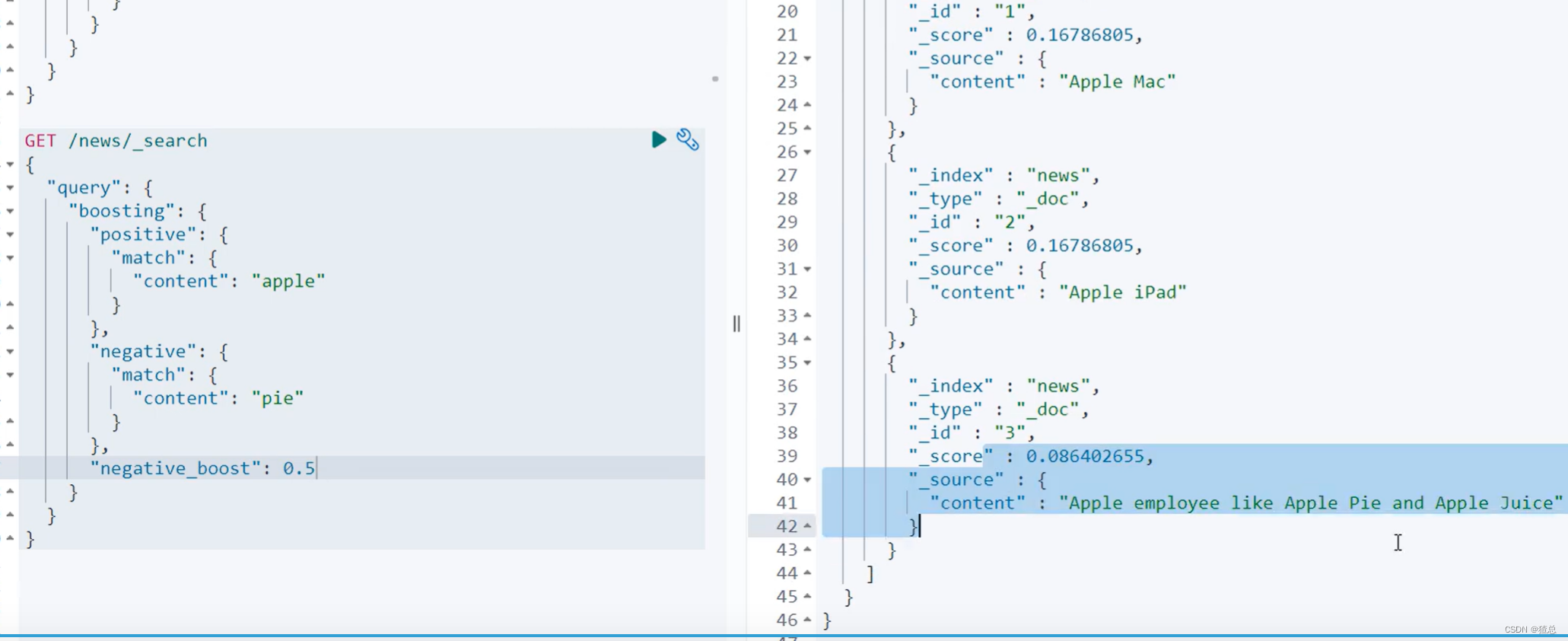
利用negative_boost降低相关性
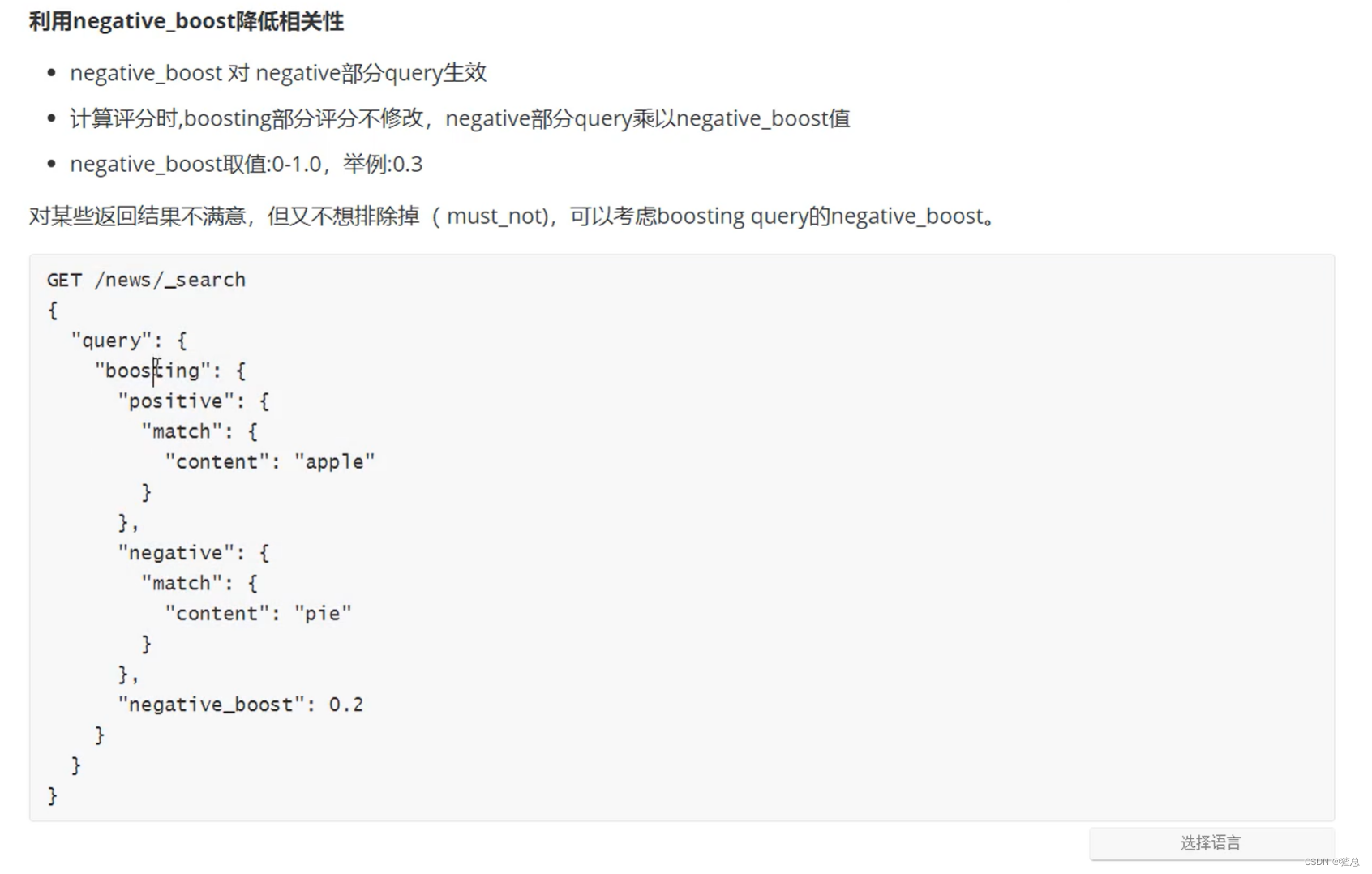
使用negative_boost降低"content"中带有"pie"的相关性
二十二、文档动态映射和静态映射

22.1 动态映射

22.2 静态映射

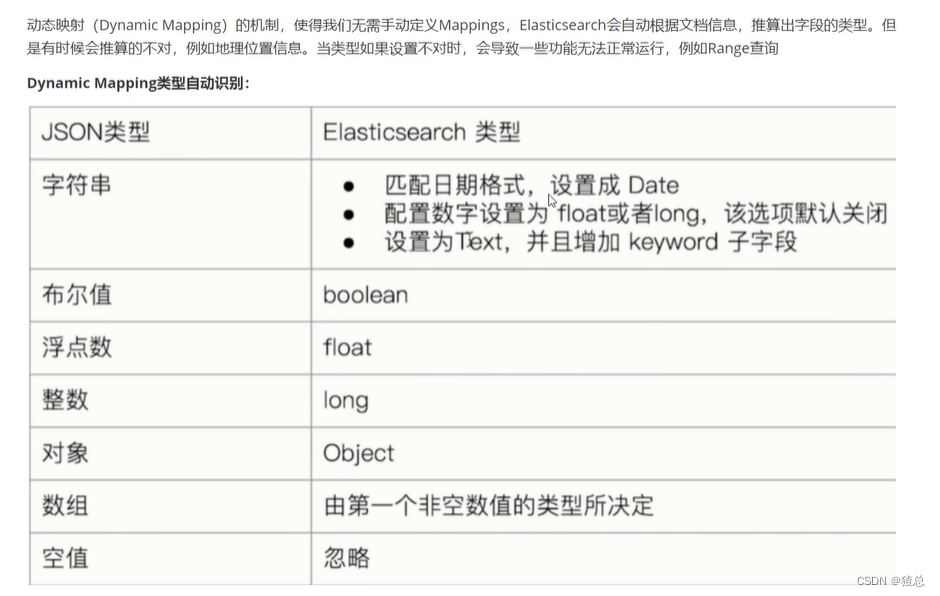
22.3 Dynamic Mapping类型自动识别
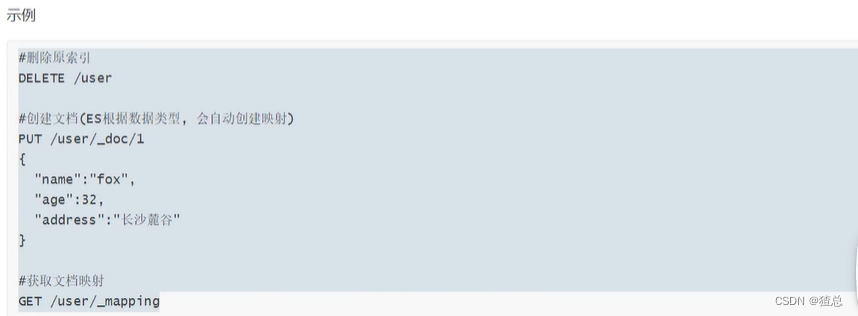
获取文档的映射
22.4 更改Mapping之新增加字段


进行测试

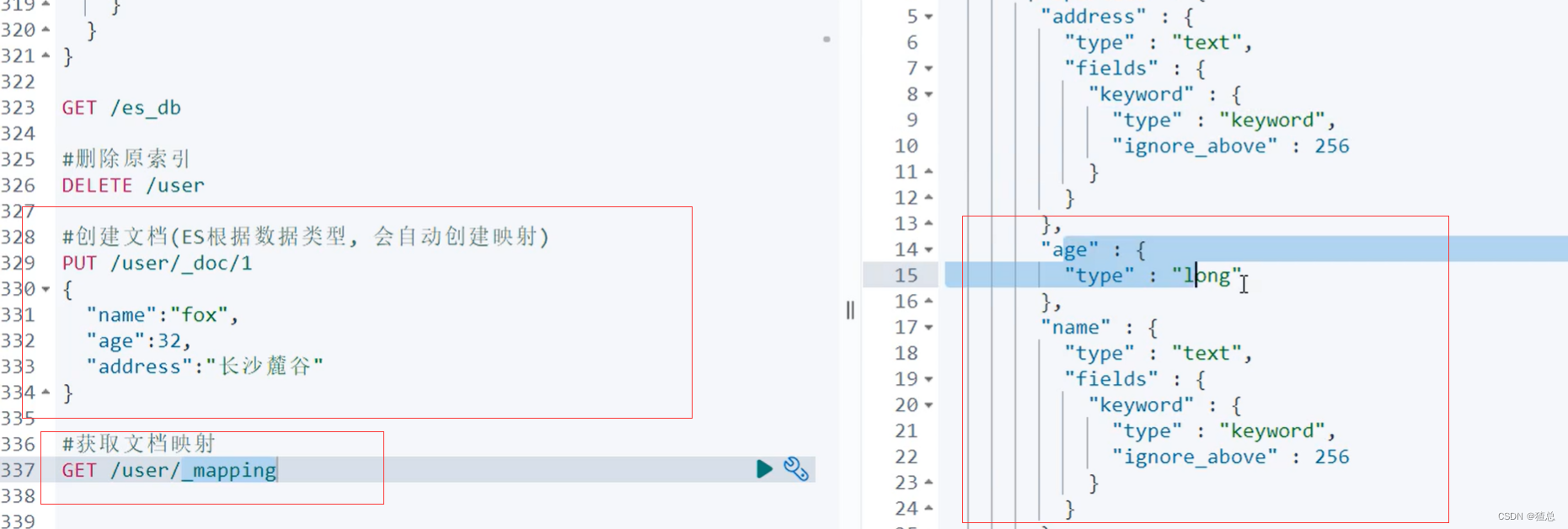
22.5 reindex对已有字段的Mapping进行修改
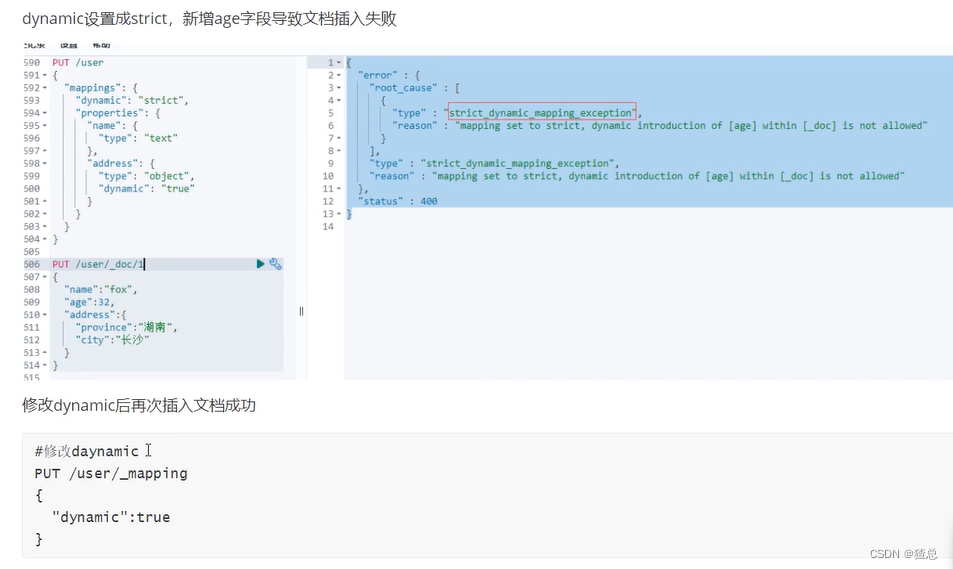
修改dynamic为true,可以插入新的字段,再次插入新的字段"age"发现成功



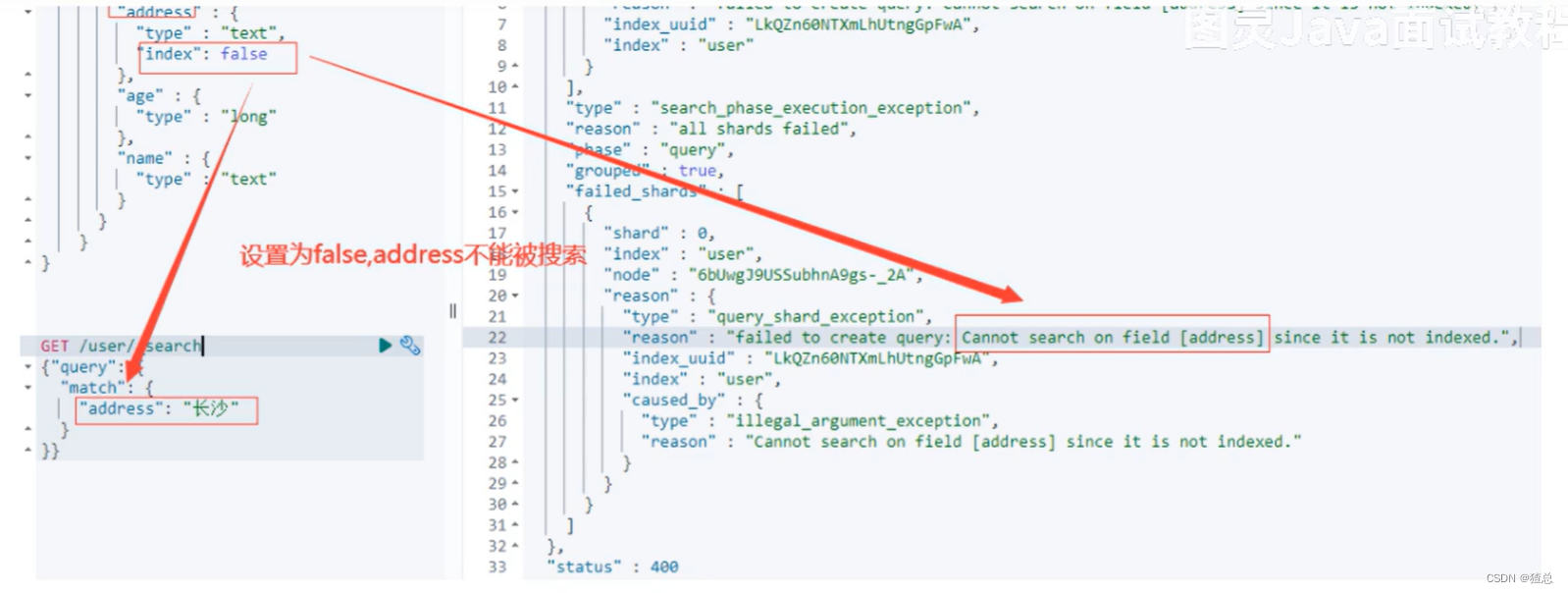
22.6 Mapping常见参数设置



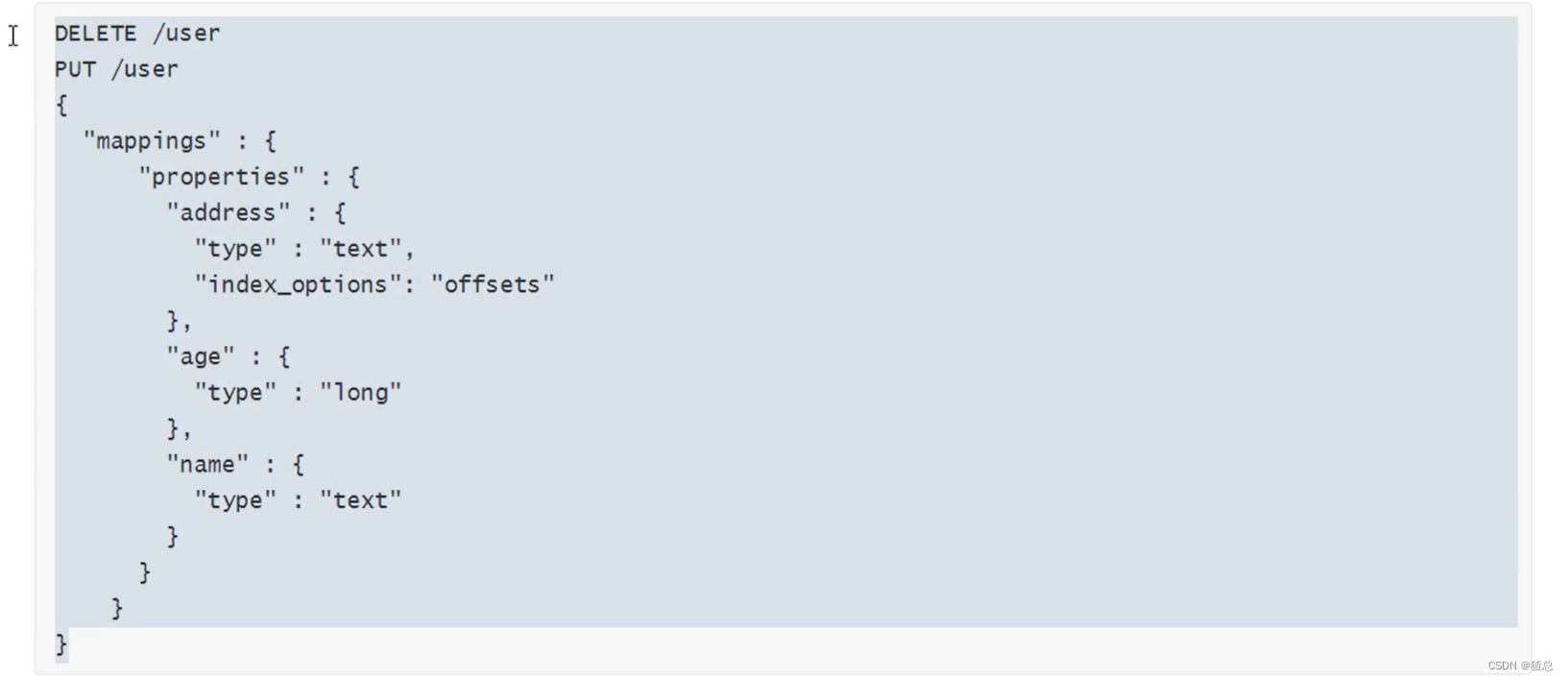


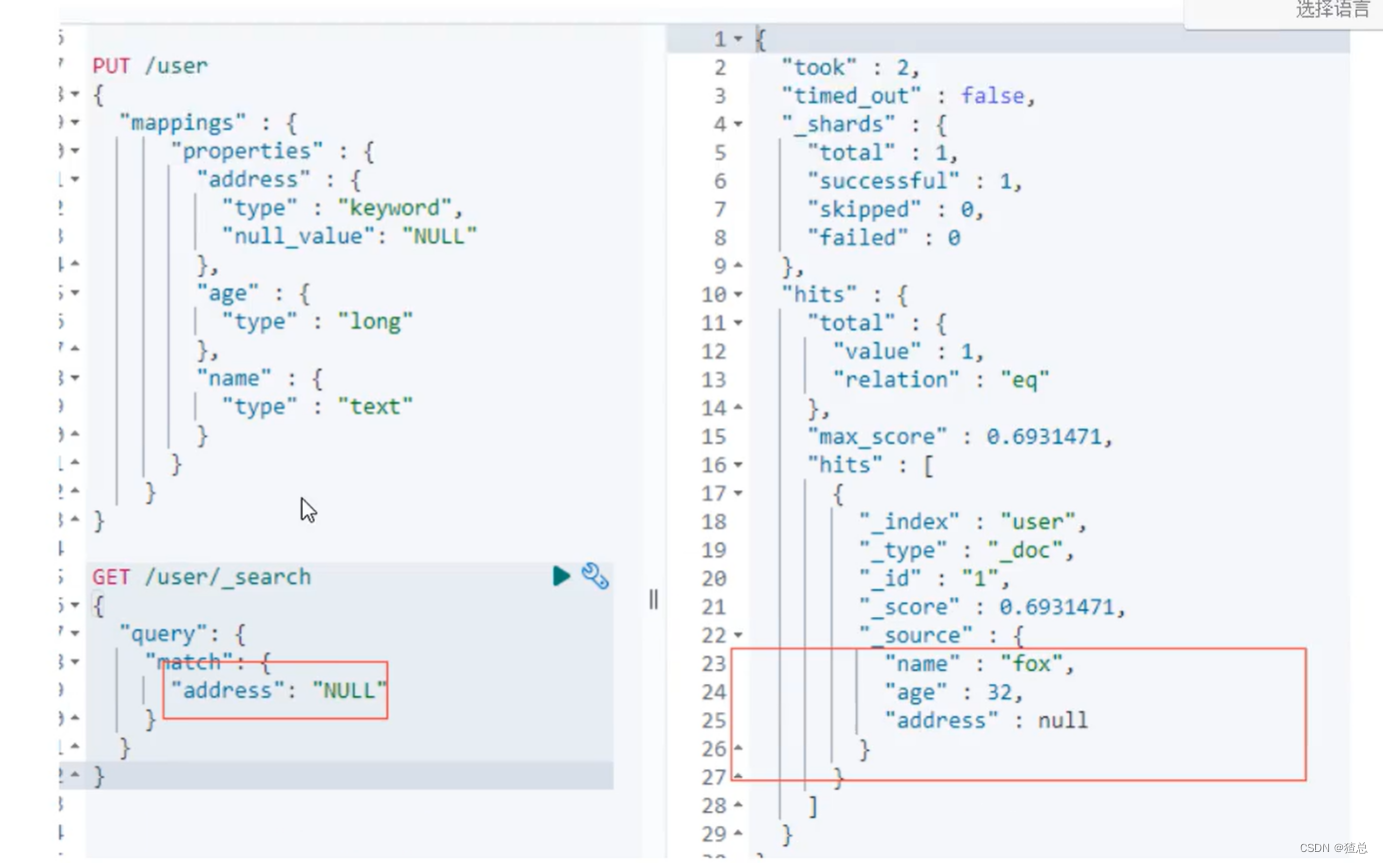
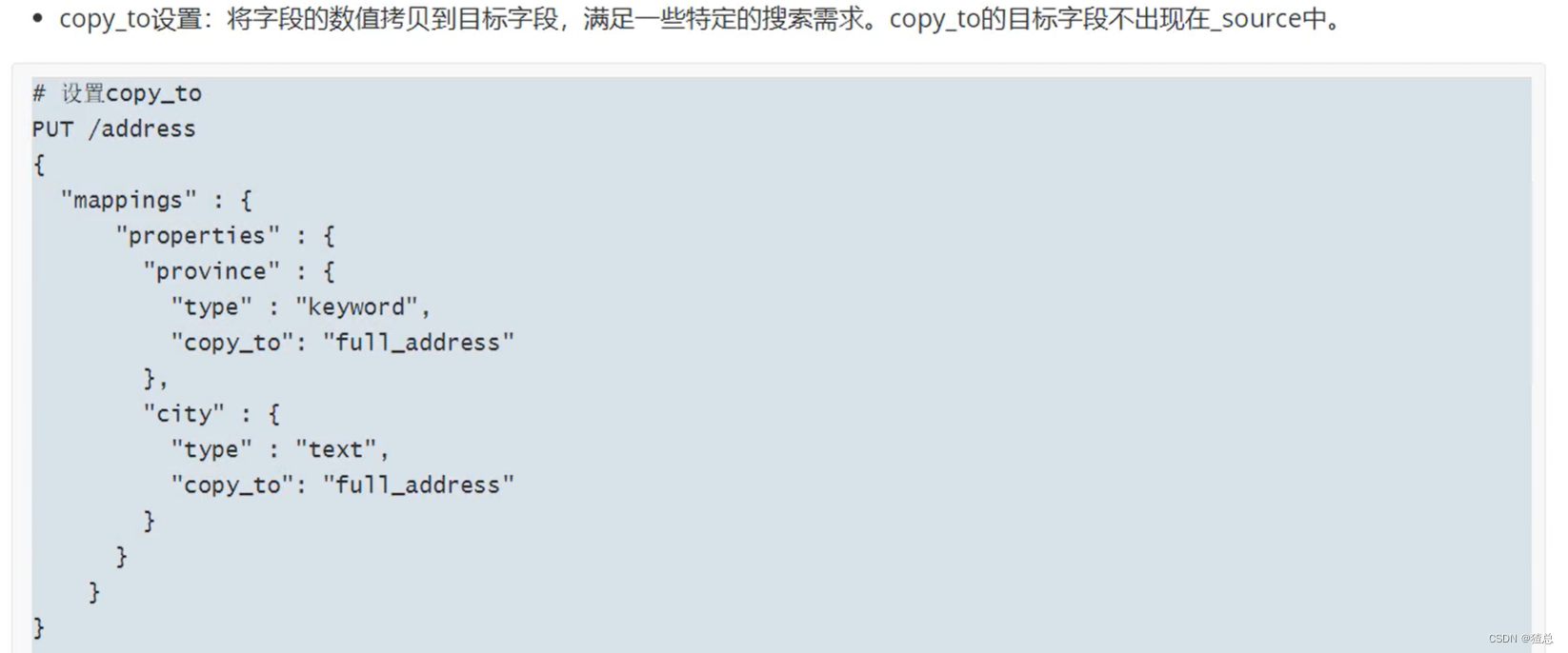

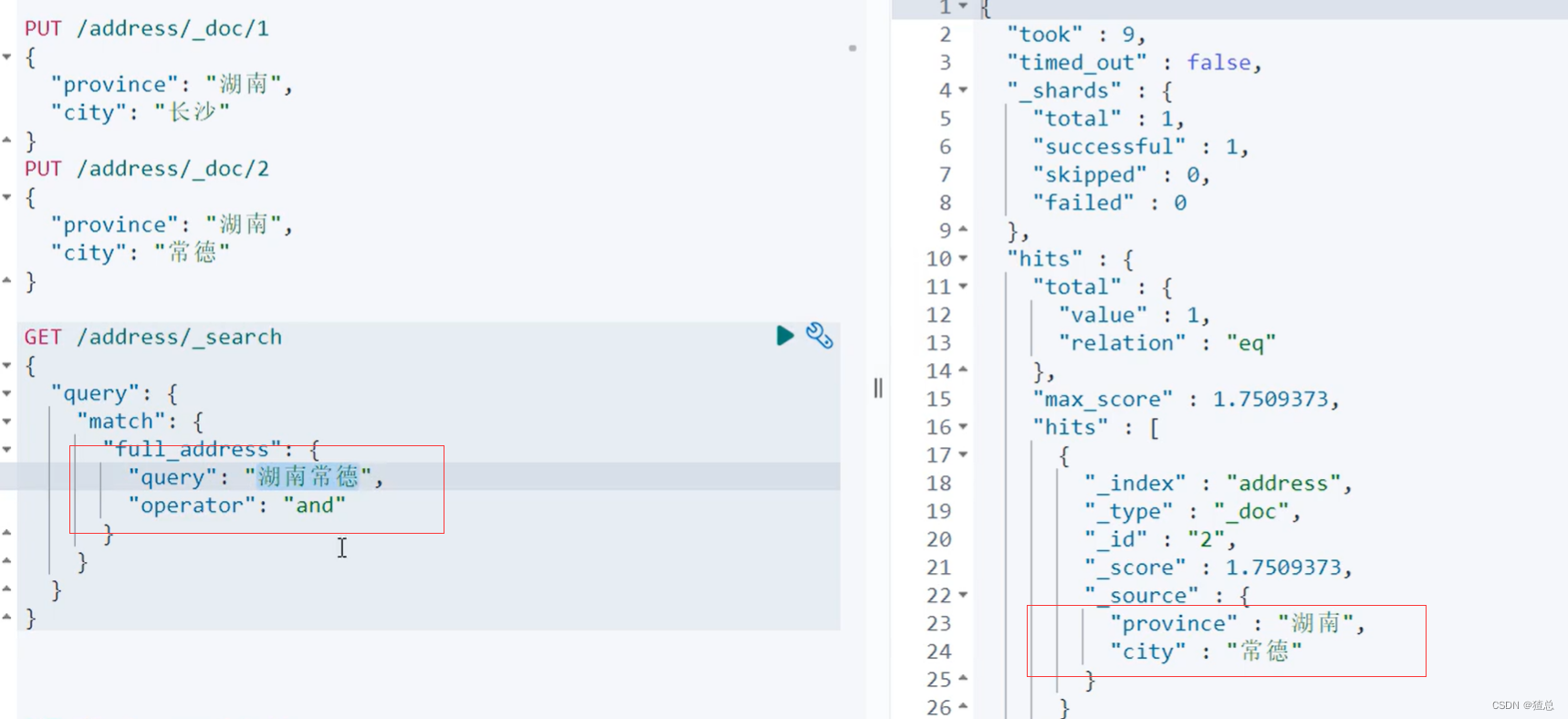
22.7 Dynamic Template详解
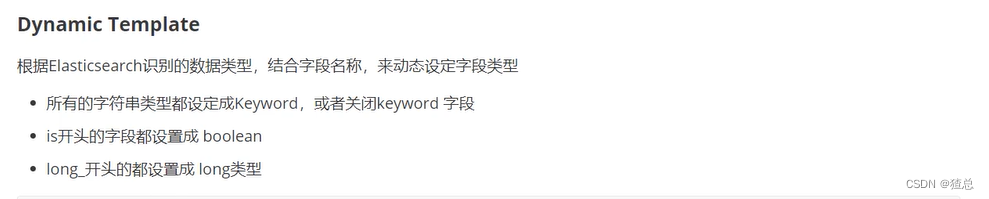


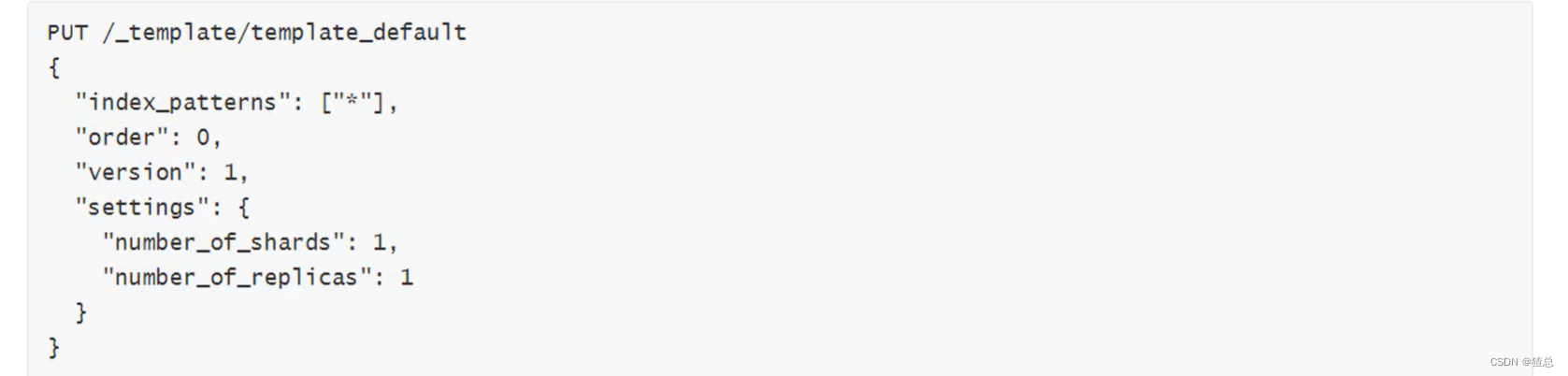
22.8 Index Template详解


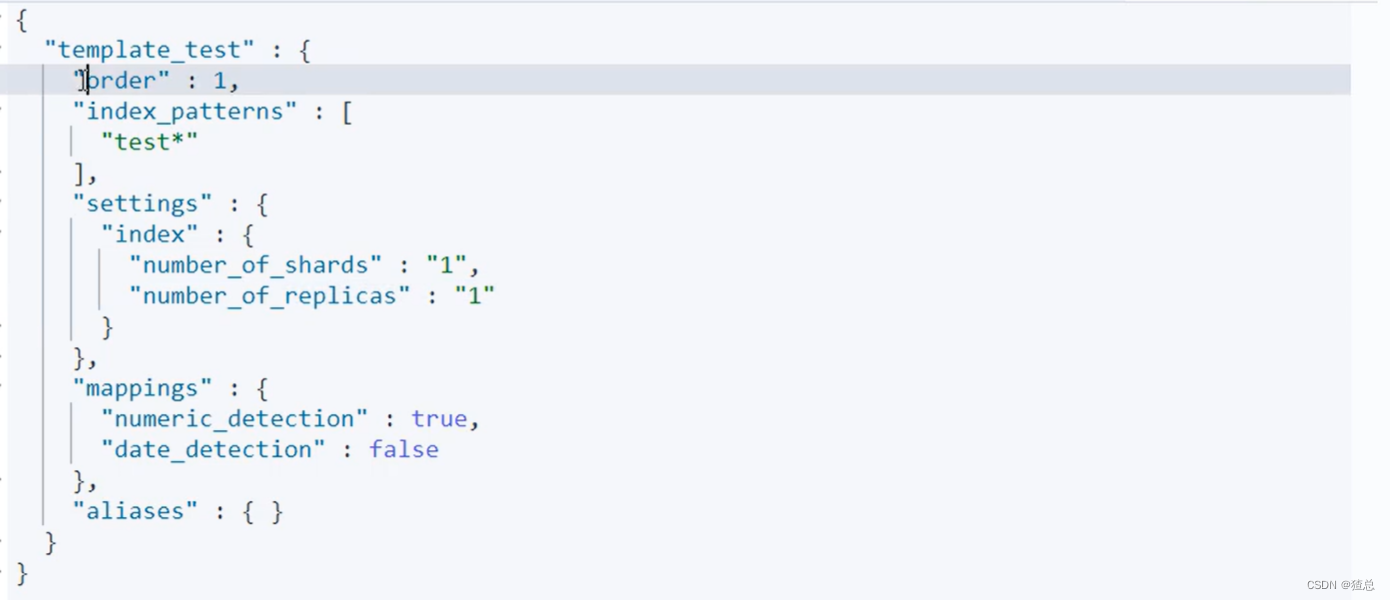
order为1覆盖了order为0,index_pattern变为了"test*"
准备数据

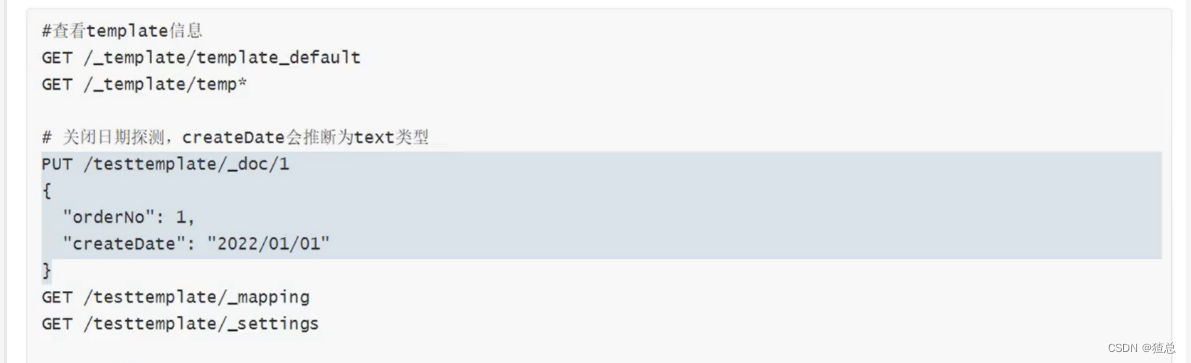

关闭日期探测
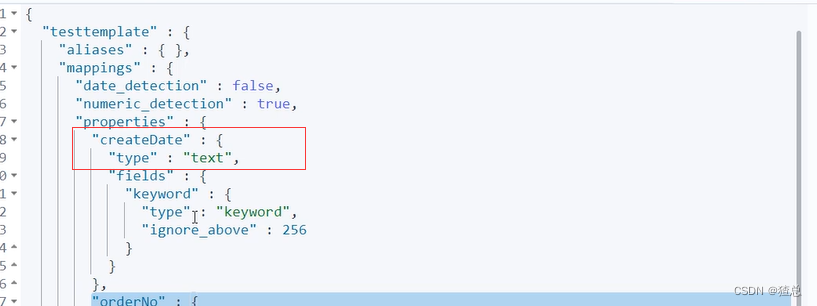
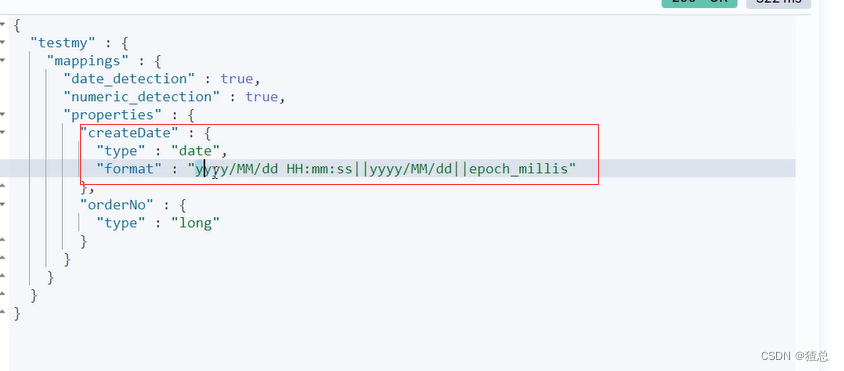
开启日期探测














 2903
2903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









