







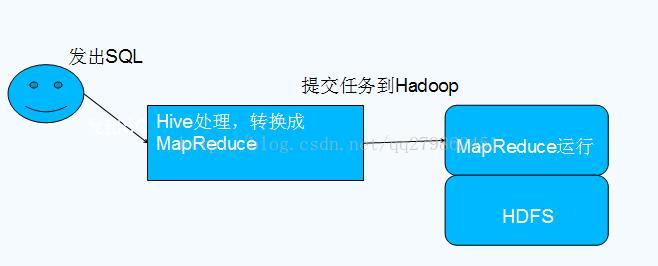
什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 - 本质是将SQL转换为MapReduce程序

Hive的特点
•可扩展Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
•延展性Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
•容错良好的容错性,节点出现问题SQL仍可完成执行
Hive与Hadoop的关系
hive环境搭建:
由于hive是基于Hadoop的。所以首先要保证你的hadoop环境是能够更正常运行的。对于haddop环境的搭建,请参照之前的文章。
1.hive的下载:http://mirror.bit.edu.cn/apache/hive/
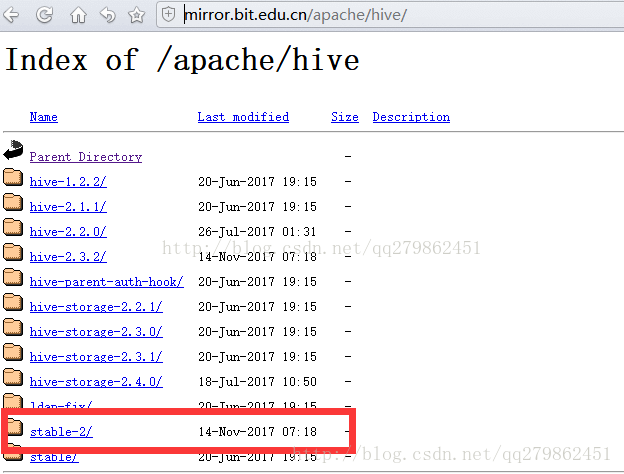
2.上传
3.解压 tar -zxvf apache-hive-2.3.2-bin.tar /usr/local/hive
4.配置
① 配置环境变量
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
export HIVE_HOME=/usr/local/hive
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HIVE_HOME/bin

② 重新加载环境变量配置
source /etc/profile
③ 验证环境变量配置是否确 echo $HIVE_HOME

④ 执行hive命令,验证hive运行是否正常,hive需要运行在hadoop上,所以在运行之前,请先启动你的hadoop
如果有相应的输出,则hive基本环境正常。
④ hive常用配置
1 cd /usr/local/hive/conf
2 cp hive-default.xml.template hive-site.xml
3 修改 hive.metastore.schema.verification 设定为false
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
4 创建/usr/local/hive/temp目录,替换${system:java.io.tmpdir}为该目录
在hive的安装目录下创建一个tmp临时目录
mkdir tmp
5 替换${system:usr.name} 为root
6 schematool -initSchema -dbType derby 格式化hive内嵌derby数据库
会在当前目录下建立metastore_db数据库
注意:每次执行hive时应该还在同一目录,hive会默认到当前目录下寻找metostore,如果没有就会创建一个新的。那么之前的数据就不能正常使用了
遇到问题,将metastore_db删掉,重新执行命执行命令,实际工作中,经常使用mysql作为metastore的数据库存储
7、启动hive
8、观察hadoop fs -ls /tmp/hive中目录的创建
9、1 show databases;![]()
2 use default;![]()
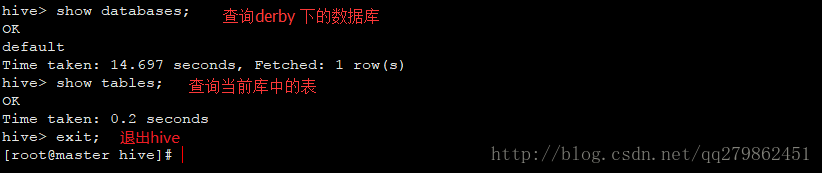
3 create table wordcount(line string);

4 show tables;

5 des wordcount;
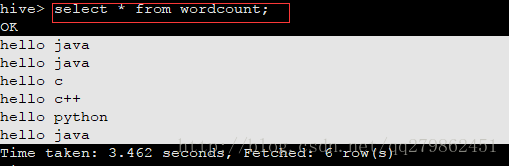
6 select * from wordcount;
7 drop table doc;
10、观察hadoop fs -ls /user
11、启动yarn
12、使用hive完成wordcount程序的功能:
1 load data inpath '/input' overwrite into table wordcount #将hdfs将根目录下的input目录下的文件中的输入载入到wordcount表中。

2 select * from wordcount;#查询表中的数据
3 select split(line,' ')from wordcount;#将数据库中的数据line字段按照空格进行分割

4 select explode(split(line,' '))from wordcount;#将上边获取到的每一行中的数组数据中的每个单词单独读取作为一行输出

select explode(split(line,' '))from wordcount;
为表添加一个新的列,使用上边的查询结果进行填充
5 select word,count(1) as count from (select explode(split(line,' '))as word from wordcount) w group by word;
执行过程
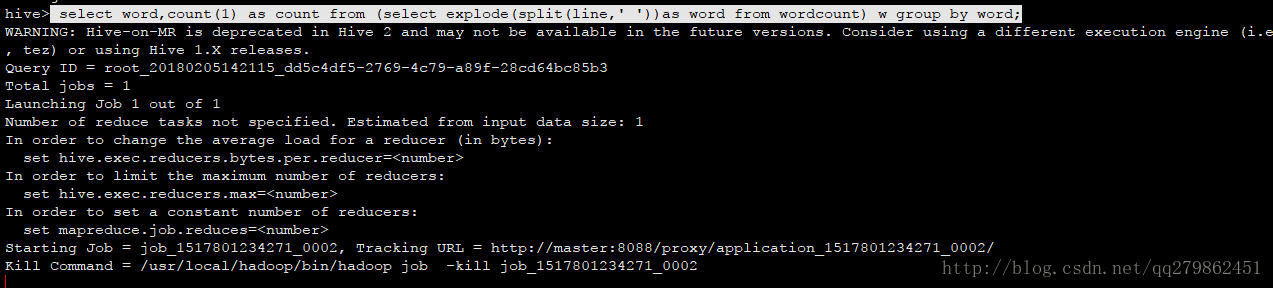
执行结果:

13 使用sougou搜索目录做实验 数据文件链接:https://pan.baidu.com/s/1dSqYuy 密码:bvtu
1将日志文件上传到hdfs系统,启动hive
2 根据搜狗日志文件 创建数据表
create table sqr(qtime string,qid string,qword string,a string, url string) row format delimited fields terminated by ',';
desc sqr; 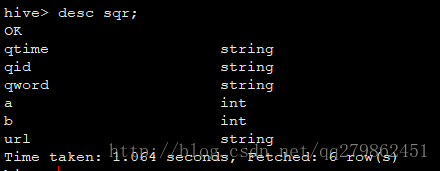
4 载入数据

load data inpath '/sogou.dic' into table sqr;
5 计算统计结果
create table sql_result as select keyword,count(1) as count from (select qword as keyword from sqr) t group by keyword order by count desc;















 1666
1666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









