







kafka的基本概念
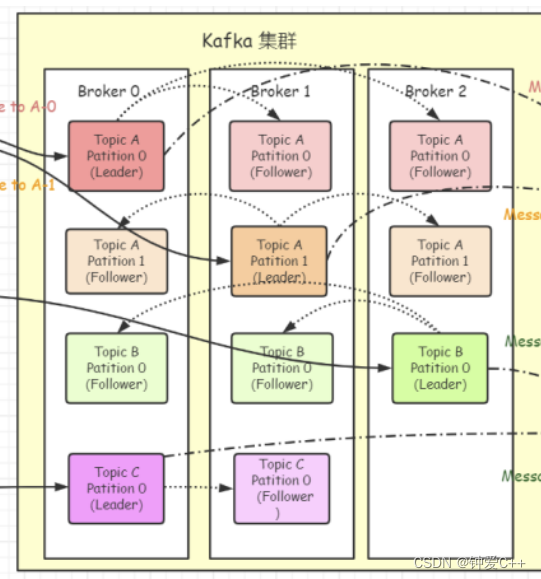
Kafka 中消息是以 Topic 进行分类的。
生产者生产消息,消费者消费消息,面向的都是同一个 Topic。
producer指明发送消息的topic,consumers指明接收消息的topic,以此来达到转发消息的目的。
Topic 是逻辑上的概念,而 Partition 是物理上的概念,每个 Partition 对应于一个 log 文件,该 log 文
件中存储的就是 Producer 生产的数据。
Partition是分区的概念,kafka可以根据topic类型设置多个分区,每个分区之间的数据是独立的。
设置多个分区的目的,主要是提高kafka的负载能力,数据写入时有多个分区可以为生产者提供服务,以
此减轻kafka单台主机的性能压力。同时,kakfa并不支持类似于mysql读写分离这样的主从机制,所有数
据的读写都是经过leader进程,所以使用多分区是很好的分摊性能压力的方式。
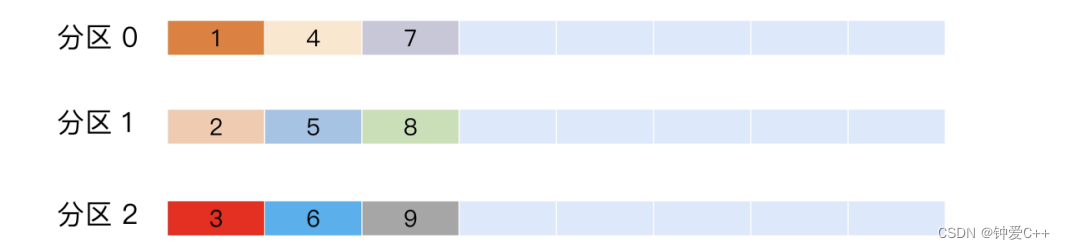
kafka中写入数据有两种写入数据的策略。
①顺序的写入 (Round-robin 策略)
比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二
条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分
配到分区 0。
②随机写入
按照 topic 随机将数据写入到不同的分区,显然这不是一种合理的方式,可能会造成数据分布不均匀。不
同的broker之间负载的压力不均衡。
在kafka中,同一个分区内的消息是可以保证有序的,但是无法保障消费者拉取时还是有序的。因为这个
消费者可能会从多个分区里拉取同一个类型的数据,拉取数据靠的是网络通信,到底哪个分区拉取的更
快,这个无法保证。
如果想要某种消息类型就是有序的,那就需要使用第三种写入策略。
③ 按消息键保序策略-Key-ordering 策略
Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务
含义的字符串,比如客户代码、部门编号或是业务 ID 等;也可以用来表征消息元数据。特别是在 Kafka
不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进 Key 里面的。一旦消息
被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的
消息处理都是有顺序的,故这个策略被称为按消息键保序策略。
Producer 生产的数据会不断追加到该 log 文件末端,且每条数据都有自己的 Offset。
消费者组中的每个消费者,都会实时记录自己消费到了哪个 Offset,以便出错恢复时,从上次的位置继
续消费。
总结写入消息的分区规则
1、指明 Partition 的情况下,直接将给定的 Value 作为 Partition 的值。
2、没有指明 Partition 但有 Key 的情况下,将 Key 的 Hash 值与分区数取余得到 Partition 值。
3、既没有 Partition 有没有 Key 的情况下,第一次调用时随机生成一个整数(后面每次调用都在这个
整数上自增),将这个值与可用的分区数取余,得到 Partition 值,也就是常说的 Round-Robin
轮询算法。
kafka拉取消息的策略
①range asigner策略
RangeAssignor 分配策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度, 然后将分
区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。
每一个主题,RangeAssignor策略会将消费组内所有订阅这个主题的消费者按照名称的字典序排序,然
后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分
区。
假设n= 分区数/消费者数量,m= 分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面
的(消费者数量-m)个消费者每个分配n个分区。
适用的场景 : 该消息的分区数能够整除消费组内订阅数,这样每个消费者消费的分区数量是均匀的。
不适用的场景:该消息的分区数不能够整除消费组内订阅数,这样每个消费者消费的分区数量是不均匀的,某些消费者的消费压力可能会比较大,造成某些分区内有很多消息无法被及时消费。
② round robin assigner策略
RoundRobinAssignor 分配策略的原理是将消费组内所有消费者及消费者订阅的所有主题的分 区按照字
典序排序,然后通过轮询方式逐个将分区依次分配给每个消费者。RoundRobinAssignor 分配策略对应
的Partition.assignment.strategy参数值为
org.apache.kafka.C1ients.Consumer.RoundRobinAssignor。
如果同一个消费组内所有的消费者的订阅信息都是相同的,那么RoundRobinAssignor分配策略的分区
分配会是均匀的。
适用的场景 : 一个消费组内,所有的消费者订阅情况是一样的,那么每个消费者分配的分区是均匀的。
不适用的场景:一个消费组内,所有的消费者订阅情况不一样,这样每个消费者消费的分区数量是不均匀的,某些消费者的消费压力可能会比较大,造成某些分区内有很多消息无法被及时消费。
当消费组内有消费者节点宕机后,会重新按照 RoundRobinAssignor 将所有分区重新分配给组内消费者。
③ 3 StickyAssignor分配策略
鉴于这两个目标, StickyAssignor分配策略的具体实现要比RangeAssignor和RoundRobinAssignor这
两种分配策略要复杂得多。 我们举 例来看一下StickyAssignor分配策略的实际效果。
假设消费组内有3个消费者(C0、C1和C2),它们都订阅了4个主题(t0、t1、t2、t3),并且每个主题有2个
分区。 也就是说,整个消费组订阅了t0p0、 t0p1、 t1p0、 t1p1、 t2p0、 t2p1、 t3p0、 t3p1这8个分
区。 最终的分配结果如下:
消费者C0: t0p0、t1p1、t3p0
消费者C1: t0p1、t2p0、t3p1
消费者C2: t1p0、t2p1
这样初看上去似乎与采用RoundRobinAssignor分配策略所分配的结果相同, 但事实是否真的如此呢?
再假设此时消费者 C1脱离了消费组, 那么消费组就会执行再均衡操作,进而消费分区会重新分配。 如
果采用RoundRobinAssignor 分配策略, 那么此时的分配结果如下:
消费者C0: t0p0、t1p0、t2p0、t3p0
消费者C2: t0p1、t1p1、t2p1、t3p1
如分配结果所示,RoundRobinAssignor分配策略会按照消费者C0 和C2进行重新轮询分配。 如果此时
使用的是StickyAssignor分配策略,那么分配结果为:
消费者C0: t0p0、t1p1、t3p0、t2p0
消费者C2: t1p0、t2p1、t0p1、t3p1
可以看到分配结果中保留了上一次分配中对消费者 C0 和C2的所有分配结果,并将原来消费者C1的 “ 负
担 “ 分配给了剩余的两个消费者 C0 和C2, 最终 C0 和C2的分配还保持了均衡。
如果发生分区重分配,那么对于同一个分区而言,有可能之前的消费者和新指派的消费者不是同一个,
之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。
StickyAssignor 分配策略如同其名称中的"st1cky" 一样,让分配策略具备一定 的 “ 黏性 ” ,尽可能地让
前后两次分配相同,进而减少系统资源的损耗及其他异常情况的发生。
stick assigner 分配策略和 round robin assigner 分配策略的主要区别是,当组内消费者宕机后/脱离后,stick assigner 会将该脱离
消费组的消费者订阅的分区数轮询的分配给组内的其他消费者。不会将所有的节点重新分配。














 2517
2517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









