







1、本文部分内容参考自:Solr 集成ikanalyzer ,内含下载地址以及部分配置。
下载地址:https://search.maven.org/search?q=com.github.magese
下载jar的格式,由于我们使用的solr是8.2.0的,所以ik也需要下载8.2.0版本的。

2、将下载的文件放到我们Web的目录下:
E:\Solr\solr-8.2.0\server\solr-webapp\webapp\WEB-INF\lib
3、在我们的Core的配置目录下(E:\Solr\solr-8.2.0\server\solr\QuestionBank\conf)的managed-schema文件,增加以下代码
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>4、重启solr,进行查看配置是否成功。
重启命令:solr restart -p 8985

5、结果预览

6、配置字段SearchContent为text_ik,进行分词查询
<field name="SearchContent" type="text_ik" indexed="true" stored="true" omitNorms="true"/> 注意,得加上omitNorms="true".
具体字段的意思,可以参考网址:https://www.jianshu.com/p/68ec75205ec0
7、重启solr
solr restart -p 8985
8、因为改了字段类型,为了不影响使用,需要重新建立索引。
这里采取的措施是,先删除数据, 再重新新增数据。
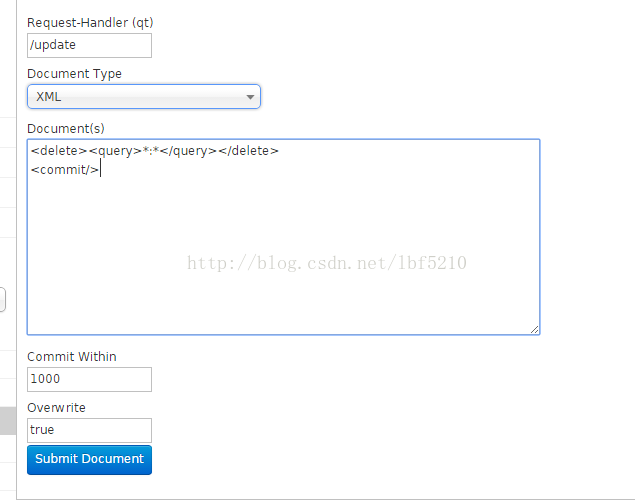
在Documents中选择,XML类型,如上图,输入下面的内容, 提交。即可删除所有数据。
<delete><query>*:*</query></delete>
<commit/>然后再改为Json类型,提交数据
{"ID":2,"SubjectID":1,"KnowledgeID":258,"TypesID":15,"DifficultyID":3,"Content":"<p>局域网中以太网采用的通信协议是<u> </u>。</p>","SearchContent":"局域网中以太网采用的通信协议是。"},
{"ID":3,"SubjectID":1,"KnowledgeID":257,"TypesID":15,"DifficultyID":2,"Content":"<p>信息技术就是计算机技术( )</p>","SearchContent":"信息技术就是计算机技术( )"}9、进行分词匹配查询
 搞定,收工。
搞定,收工。














 2004
2004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









