










介绍
目前网络中出现了好多各种面试题的汇总,有真实的也有虚假的,所以今年我将会汇总各大公司面试比较常见的问题,逐一进行解答。会一直集成,也会收集大家提供的面试题,如有错误,请大家指出,经过排查存在,会及时更新
备注:针对里面没有完成的已标记*,后期将会出一期算法提
面试题汇总
1.设备开机到屏幕的显示过程
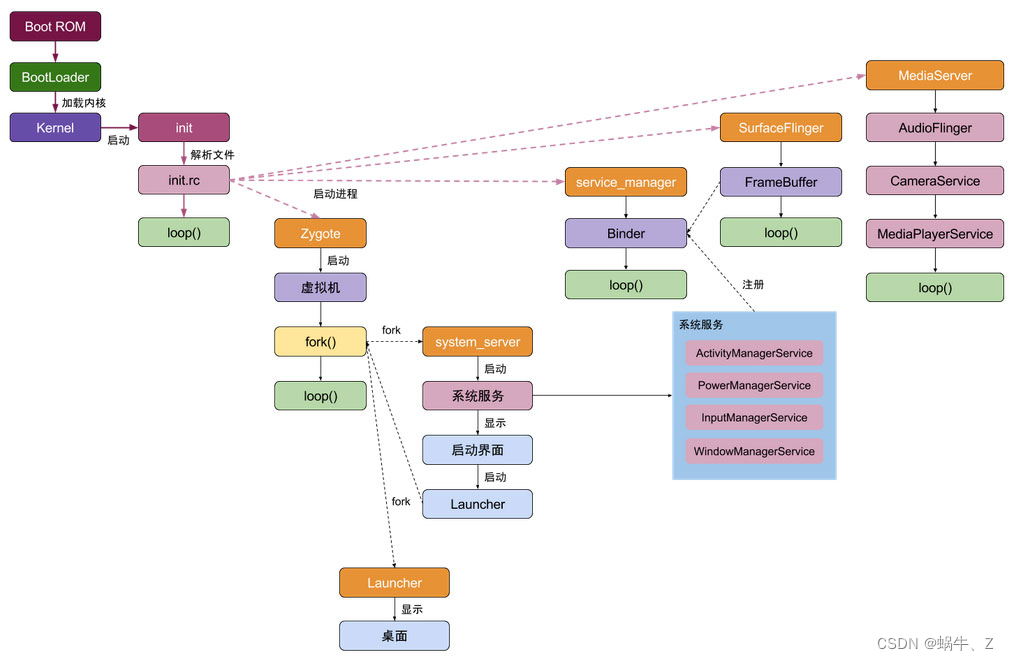
正常android设备开机经历三次动画,Linux内核的启动画面、Init进程启动过程中加载动画、系统服务启动过程中的动画。
这些画面的显示的过程不同,但最终是通过framebuffer显示的,每层对它显示的过程进行了封装。即无论是哪一个画面,它们都是在一个称为帧缓冲区(frame buffer,简称fb)的硬件设备上进行渲染的
1、第一个启动画面:机器人
比较直接的使用framebuffer,通过最终的info->fbops->fb_imageblit(info, image); 调用实现画面的显示,回调函数fb_imageblit就是用来在指定的帧缓冲区硬件设备渲染指定的图像的
2、第二个启动画面
调用load_565rle_image(INIT_IMAGE_FILE)来显示画面,最终调用framebuffer中的接口fb_open来打开设备文件/dev/graphics/fb0,打开了设备文件/dev/graphics/fb0之后,我们就可以将文件/initlogo.rle的内容输出到帧缓冲区硬件设备中去了
3、第三个启动画面
主要由系统服务SurfaceFlinger来完成。应用程序bootanimation来负责显示的,bootanimation在启动脚本init.rc中被配置成了一个服务。当SurfaceFlinger服务启动的时候,它会通过修改系统属性ctl.start的值来通知init进程启动应用程序bootanimation,以便可以显示第三个开机画面,而当System进程将系统中的关键服务都启动起来之后,ActivityManagerService服务就会通知SurfaceFlinger服务来修改系统属性ctl.stop的值,以便可以通知init进程停止执行应用程序bootanimation。
2.分屏是怎么实现*
3.如果让你实现一个类似AMS,WMS的服务
如果实现一个自己的服务,我们先了解AMS,WMS的基本原理,以及服务的至少包含了什么。
在Android Framework中,AMS还是WMS,都是在zygote进程中创建的,而且服务之间的通讯是通过binder机制,所以每个服务至少拥有自己的IBinder,每个服务的和外界的通讯交互,又是基于AIDL原理来完成,所以要提供一个我们自己的AIDL文件。
在Context中定义服务标识
在SystemServer中启动服务
在SystemServiceRegisty中注册服务管理类
修改Android.mk文件
4.Glide介绍
1.介绍一下Glide缓存
Glide的缓存和Pisco以及ImageLoad的是一样,采用两种缓存,内存缓存和磁盘缓存。
内存缓存:内存缓存中又分为Lru和弱引用缓存
sdcard缓存:防止应用重复从网络或其它地方下载和读取数据
缓存的目的:提高资源重复使用,降低设备自身性能的消耗。
2. Glide的优点
1.使用简单,易上手,采用链式设计,不需要更多的配置即可使用
2.占用内存更小,默认使用RGB_565格式
3.支持gif资源
4.缓存优化,支持内存分级缓存:正在使用的图片,弱引用缓存;已使用过的图片LruCache缓存,根据不同尺寸的ImageView缓存不同的尺寸
5.有对生命周期进行管理,防止内存泄露
3.怎么绑定生命周期
Glide.with(target),通过不同的对象,获取不同的对象资源,然后将这个对象添加到lifecycle的生命周期管理中。这些管理在RequestManagerRetriever进行创建与缓存。
4.缓存原理
1.支持哪几种缓存
- DiskCacheStrategy.ALL:原始图片和转换过的图片都缓存
- DiskCacheStrategy.RESOURCE:只缓存原始图片
- DiskCacheStrategy.NONE:不缓存
- DiskCacheStrategy.DATA:只缓存使用过的图片
5.说说Glide的三级缓存原理
在请求资源的时候,先是通过ActiveResource使用弱引用来缓存资源的,如果如果找到,加载完毕,如果未命中,再进行MemoryCache来进行查询,如果在内存中找到,缓存至ActiveResource,并加载完毕,如果未找到,再通过diskcache进行查找,如果找到,缓存至memoryCache,再缓存至ActiveResource,并完成加载,如果未找到,那就得从资源的请求原始位置(如:网络服务器、本地资源、sdcard等)进行请求,请求成功,缓存到diskcache,再缓存到memorycache再到ActiveResource,最后完成加载。
5.1简单说一下内存泄漏的场景
Glide的with绑定对象有context、Activity、fragment、view。Activity和fragment可以通过lifecycle完成生命周期的绑定,可以在页面销毁不可以的时候,停止资源的请求。但是在context或者view的时候,无法去监控到生命周期变化,存在内存泄露的风险,view或者context(getApplicationContext)。在非生命周期的组件上进行时,会采用Application的生命周期贯穿整个应用,所以applicationManager只有在应用程序关闭时终止加载
6.Android设备启动流程
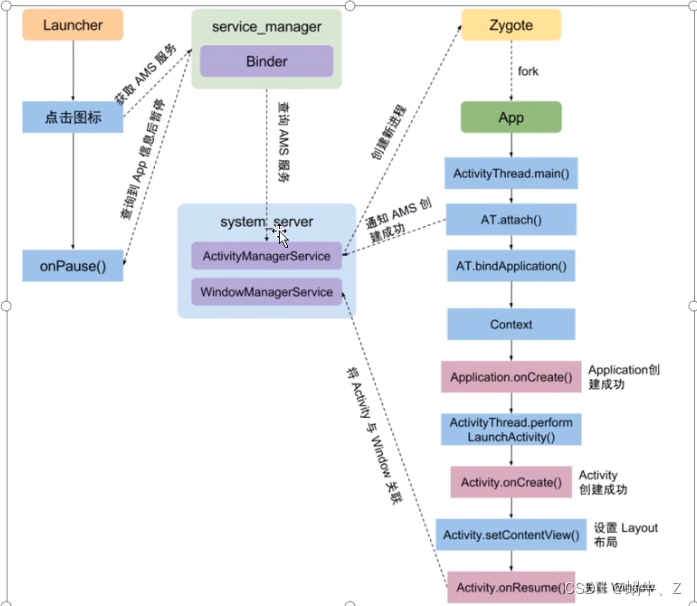
7.APP启动流程
App启动,先init进程初始化,zygota fork一个进程,先要为进程做准备,先为进程创建一个binder,然后在反射获取到进程的main函数,做一些初始化。进程创建自己的Stub,交给systemManger
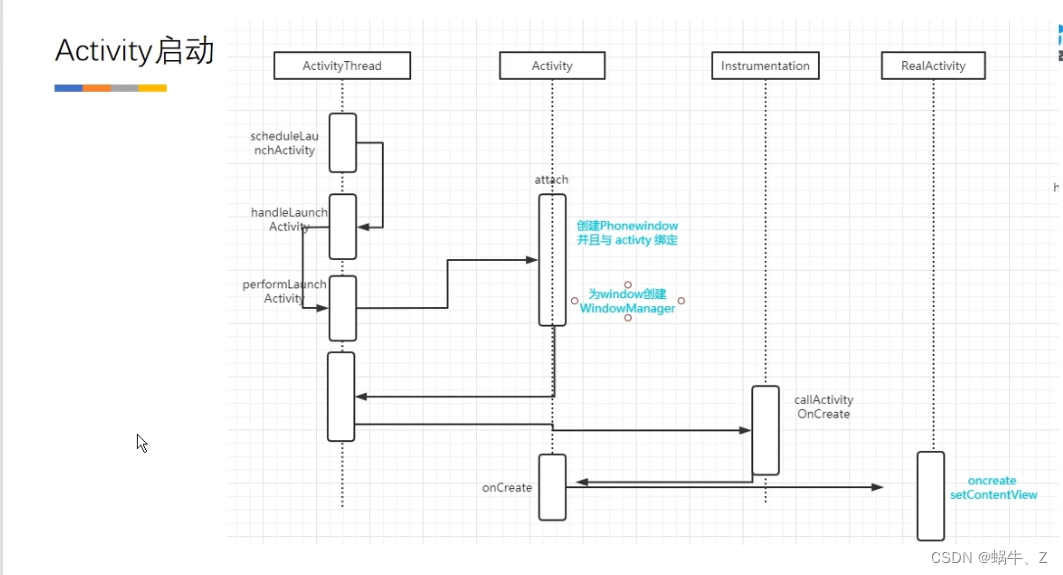
8.Activity的启动流程
9.IntentService与Service的区别?Service两种启动方式
IntentService与Service都是服务,
Service 是长期运行在后台的应用程序组件,如果直接把耗时操作放在 Service 的 onStartCommand() 中,很容易引起 ANR .如果有耗时操作就必须开启一个单独的线程来处理
IntentService 是继承于 Service 并处理异步请求的一个类,在 IntentService 内有一个工作线程Handler来处理耗时操作,每次执行完一次都会调用stopSelf。
9.1IntentService与Service的不同:
(1)Service直接 创建一个默认的工作线程,该线程执行所有的intent传递给onStartCommand()区别于应用程序的主线程。
(2)IntentService直接创建一个工作队列,将一个意图传递给你onHandleIntent()的实现,所以我们就永远不必担心多线程。
(3)IntentService当请求完成后自己会调用stopSelf(),所以你就不用调用该方法了,结束自己。
(4)Service默认实现onStartCommand(),IntentService也调用,但是会执行onstart,将意图工作队列,然后发送到你onHandleIntent()实现。我们需要做的就是实现onHandlerIntent()方法
(5)构造函数不同,IntentService必须提供一个服务名称,省去Service中手动开线程的麻烦,当操作完成时,我们不用手动停止Service。
startService与bindService的对比
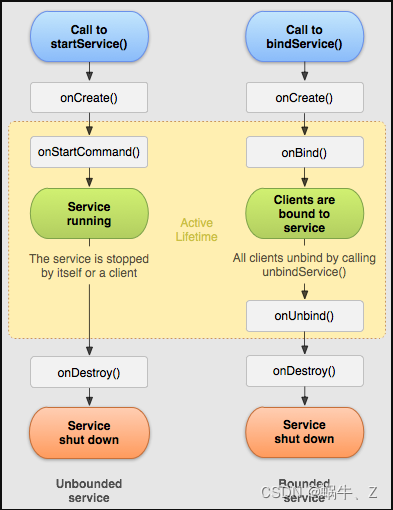
9.2两种启动方式
1.startService
如果通过startservice()启动,是无法和service进行通讯,因为就是简单的启动,比如长期需要活跃在后台,startService启动的服务,如果需要停止,通过StopService
2.bindService
绑定,绑定可以提供通讯,也就是通过ServiceConnection,获取到IBinder,来完成数据的交互
bindService:可以多次bindService,但是onBind只会调用一次,但是解绑UNBindService只有一次,否则会报错。所以在绑定与解绑回调的时候,可以通过一个字段记录,方便操作绑定
10.为什么通知zygote启动的时候采用socket并不是binder?
锁死,
binder是多线程,支持异步调用。异步调用就会存在等待锁死状态。socket是不支持多线程,
11.跨进程通讯为什么采用bind而不是socket*
12.binder通讯最大是多大,如何突破
在linux底层中,ProcessState.cpp文件已定义好了Binder通信最大可以传输是1MB-8KB.
#define BINDER_VM_SIZE ((1 * 1024 * 1024) - sysconf(_SC_PAGE_SIZE) * 2)http://androidxref.com/9.0.0_r3/xref/frameworks/native/libs/binder/ProcessState.cpp
也就是1MB减去两个页面的大小。
12.1如何突破:
正常应用,我们都是Zygote进程孵化出来的,Zygote进程的初始化Binder服务的时候提前调用了ProcessState这个类,所以普通的APP进程上限就是1MB-8KB。
Binder服务的初始化有两步,open打开Binder驱动,mmap在Binder驱动中申请内核空间内存,所以我们只要手写open,mmap就可以轻松突破这个限制
核心文件:
http://androidxref.com/9.0.0_r3/xref/frameworks/native/cmds/servicemanager/bctest.c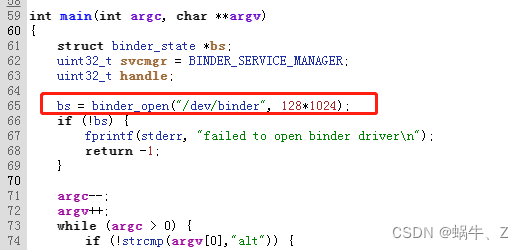
在创建binder的时候,修改即可。但是这个也不是无限制突破的
http://androidxref.com/kernel_3.18/xref/drivers/staging/android/binder.c
在binder.c文件中
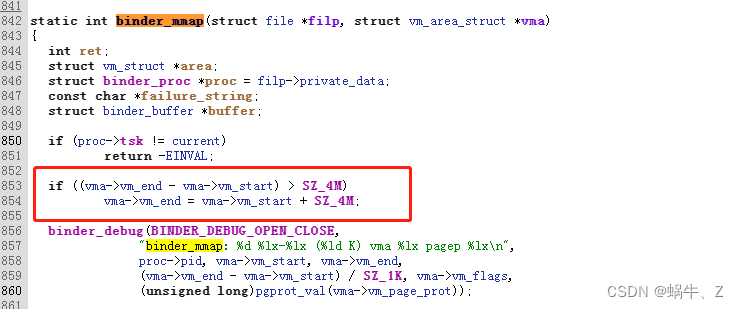
有对4M进行验证,但是在bind_mmp中

对异步的buffer_size进行了取一半,也就是同步是4M,异步是一半大小
13.zygote进程启动流程*
14.ANR超时时间
ANR产生的时候会有一个定时器,系统内部已定义好各种超时时间。
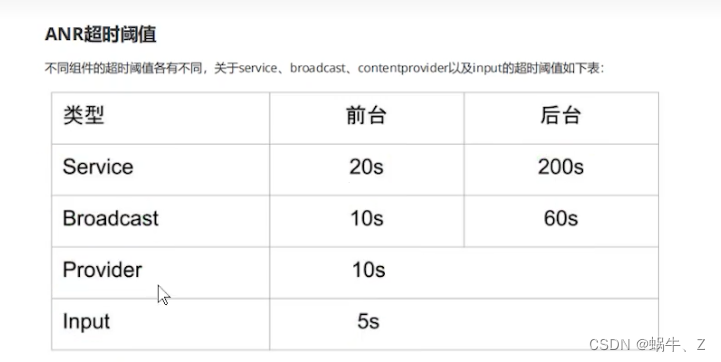
ANR即(application not responding),即应用无响应
Crash:是指程序中可能会出现你未捕获到的异常
14.SystemSver进程执行过程
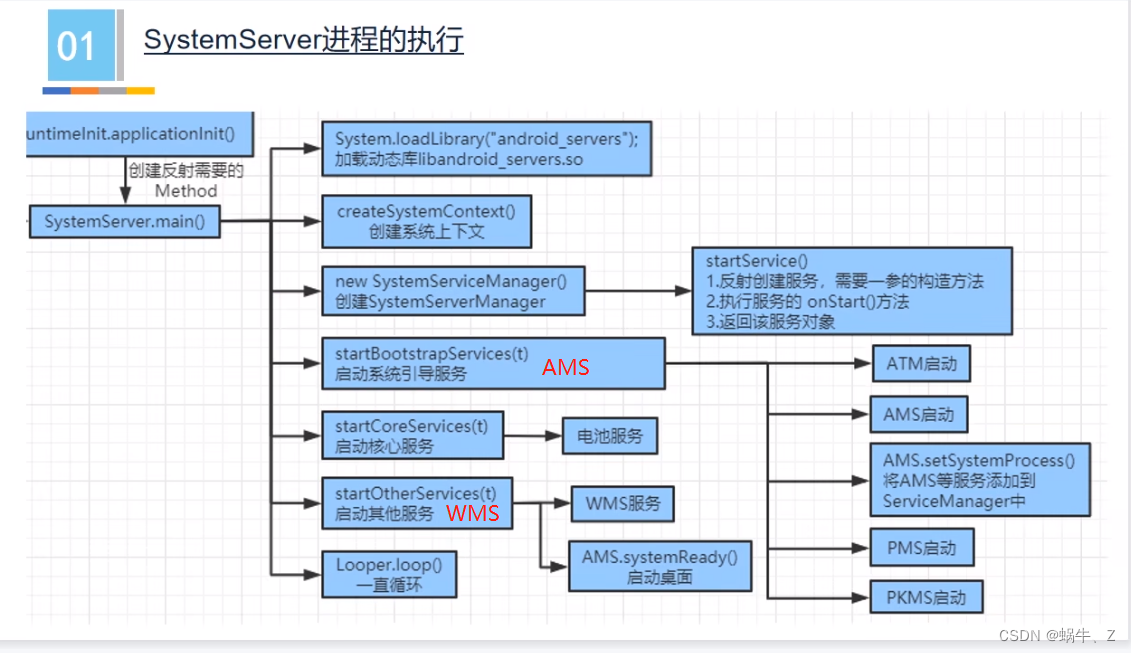
15.Init进程
介绍:
init进程会走 main.cpp,然后分阶段的去执行main函数,这个调用是循环的方式最后一个阶段是SecondStageMain,里面执行了一个非常重要的方法LoadBootScripts(am,sm),这个东西解析了一个init.rc 文件,并将这些命令写到am 和 sm中,在while循环里面,通过ExecuteOneCommand去执行这些命令。其中就包含了启动 zygote的命令。当然,这个while循环是一个死循环,为什么是死循环呢?进程一定是活着的。那要是没事做怎么办呢?睡眠,等待。那就是有用epoll.Wait
15.1init启动过程:
1.挂载文件: 识别各类文件,相当于解析硬盘2.设置selinux --安全策略
3.启动属性服务
4.解析init.rc
5.循环处理脚本---包括启动zygote,包括启动servcieManager进程
6.循环等待
核心:init进程启动了zygote,启动了 servcieManager (binder服务管家) 进程
16.浅谈一下AMS、WMS、PMS
AMS、WMS、PMS都叫服务,AMS的核心是管理四大组件的生命周期,WMS负责窗口和View的绘制与显示,PMS是包的管理。这些服务都属于Framework层,这些服务又称为进程,他们之间的交互都是通过Binder的机制,通过AIDL来完成。
17.view的事件分发机制
事件分发有两种,第一是View,第二是ViewGroup。事件分发主要有三大核心
1.public boolean dispatchTouchEvent(MotionEvent event) —— 分发事件
2.public boolean onInterceptTouchEvent(MotionEvent event) —— 拦截事件
3.public boolean onTouchEvent(MotionEvent event) —— 消费事件
MotionEvent 主要分为以下几个事件类型:
- ACTION_DOWN 手指开始触摸到屏幕的那一刻响应的是DOWN事件
- ACTION_MOVE 接着手指在屏幕上移动响应的是MOVE事件
- ACTION_UP 手指从屏幕上松开的那一刻响应的是UP事件
执行顺序:ACTION_DOWN -> ACTION_MOVE -> ACTION_UP
1.分发事件
事件分发是核心的一个步骤,如果分发没弄懂,我们会发现事件其他view的事件好像都没有往下继续了。
一般在这个方法里必须写 return super.dispatchTouchEvent 。如果不写super.dispatchTouchEvent,而直接改成return true 或者 false,则事件传递到这里时便终止了,既不会继续分发也不会回传给父元素。
2.拦截
只有ViewGroup才有这个方法。View只有dispatchTouchEvent和onTouchEvent两个方法。因为View没有子View,所以不需要拦截事件。而ViewGroup里面可以包裹子View,所以通过onInterceptTouchEvent方法,ViewGroup可以实现拦截,拦截了的话,ViewGroup就不会把事件继续分发给子View了,也就是说在这个ViewGroup中的子View都不会响应到任何事件了。onInterceptTouchEvent 返回true时,表示ViewGroup会拦截事件。
3.消费
消费也是我们常写的,ontouch事件,onTouchEvent 返回true时,表示事件被消费掉了。一旦事件被消费掉了,其他父元素的onTouchEvent方法都不会被调用。如果没有人消耗事件,则最终当前Activity会消耗掉。则下次的MOVE、UP事件都不会再传下去了。
需要注意的一些事项:
- 一般我们在自定义ViewGroup时不会拦截Down事件,因为一旦拦截了Down事件,那么后续的Move和Up事件都不会再传递下去到子元素了,事件以后都会只交给ViewGroup这里。
- 一个Down事件分发完了之后,还有回传的过程。因为一个事件分发包括了Action_Down、Action_Move、Action_Up这几个动作。当手指触摸到屏幕的那一刻,首先分发Action_Down事件,事件分发完后还要回传回去,然后继续从头开始分发,执行下一个Aciton_Move操作,直到执行完Action_Up事件,整个事件分发过程便到此结束
18.okhttp框架原理
OKHttp 请求的整体流程?
- 通过建造者模式构建 OKHttpClient 与 Request
- OKHttpClient 通过 newCall 发起一个新的请求
- 通过分发器维护请求队列与线程池,完成请求调配
- 通过默认拦截器完成请求、重定向,缓存处理,连接等一系列操作
- 得到回调结果
OkHttp网络缓存如何实现?
OKHttp 默认只支持 get 请求的缓存。
1.第一次拿到响应后根据头信息决定是否缓存
2.下次请求时判断是否存在本地缓存,是否需要使用对比缓存、封装请求头信息等等
3.如果缓存失效或者需要对比缓存则发出网络请求,否则使用本地缓存
Dispatcher的功能是什么?
核心是维护任务队列,负责将每一次请求进行分发,压栈到自己的线程池,并通过调用者自己不同的方式进行异步和同步处理。
OkHttp 设置了默认的最大并发请求量 maxRequests = 64 和单个 Host 主机支持的最大并发量 maxRequestsPerHost = 5
OKHttp有哪些拦截器,分别起什么作用
1、RetryAndFollowUpInterceptor
重定向的后续请求还有一些连接跟踪工作。
2、BridgeInterceptor
这里会为用户构建一个能够进行网络访问的请求,同时后续工作将网络请求回来的响应Response转化为用户可用的Response,比如添加文件类型,content-length计算添加,gzip解包。
3、CacheInterceptor
缓存拦截器,如果命中缓存则不会发起网络请求。
4、ConnectInterceptor
这里主要就是负责建立连接了,会建立TCP连接或者TLS连接,以及负责编码解码的HttpCodec
5、CallServerInterceptor
这里就是进行网络数据的请求和响应了,也就是实际的网络I/O操作,通过socket读写数据。
OkHttp有哪些优势?
1.支持http2,对一台机器的所有请求共享一个Socket
2.内置连接池,支持连接复用,减少延迟
3.支持透明的gzip压缩响应体
4.响应缓存可以完全避免网络重复请求
5.请求失败时自动重试主机的其他IP,自动重定向
6.丰富的Api,可扩展性好。
19.介绍一下binder通讯机制AIDL
Binder 是一种进程间通信机制,Binder自身是驱动层,通讯是通过AIDL来完成, 整个app属于客户端,系统是服务端,他们之间的通讯就是通过IPC交互,中间服务就是SystemService,在整个Framework层,所有的服务都是通过Binder来通讯。
优点:性能,稳定性,安全性
设计:Client/Server/ServiceManager/驱动
实现:AIDL
20.谈一下handler
Handler是Android中的异步消息处理机制。当发送一个消息之后,这个消息是进入一个消息队列(MessageQueue),在消息队列中通过Looper去循环的获取队列中的消息,然后将消息分派给对应的处理者进行处理。也是活跃在UI线程的消息,核心是Looper。
核心模块
1.Message:消息体
2.MessageQueue:存储handler发送过来的消息
3.Looper:循环器,它是消息队列和handler的通信媒介,1:循环的取出消息队列中的消息;2:将取出的消息发送给对应的处理者
4.Handler:主线程和子线程的通信媒介,1:添加消息到消息队列; 2:处理循环器分派过来的消息
handler消息发送过程:
消息Message的封装,通过sendMessage将消息体,通过Handler进行消息的转发,真正消息处理在MessQueue中,消息队列,在消息队列中enqueueMessage方法中,有个for(;;)循环体在处理消息,处理消息入队,进行事件转发。
子线程中维护的Looper,如何终止消息循环?
调用Looper的quit()(清空所有的延迟和非延迟的消息)和quitSafely()(只清空延迟消息); 这个方法会调用MessageQueue的quit()方法,清空所有的Message,并调用nativeWake()方法唤醒之前被阻塞的nativePollOnce()(管道消息队列),使得方法next()方法中的for循环继续执行,接下来发现Message为null后就会结束循环,Looper结束。如此便可以释放内存和线程
handler导致内存泄漏的原因
导致内存泄露最常见的场景是持有对象已消息,但是handler的消息还没有被消费完,由于handler非内部静态类,GC在回收时,不会考虑非静态到。
解决方案:
1.采用弱引用WeakReference
2.申请为内部静态类
handler postDelayed延迟提交采用了什么?
handler的延迟是调用了系统的epoll机制,通过管道去处理这些消息。
Handler为何使用管道而非binder
1.内存角度:binder通信过程中,涉及到一次内存拷贝,handler机制中的Message根本不需要拷贝,本身就是在同一片内存。
2.CPU角度:Binder通信底层驱动需要创建一个binder线程池,每次通信涉及binder线程的创建和内存的分配等比较浪费CPU资源,handler几乎不涉及到
21.什么是线程安全?什么样线程不平安?如何实现线程平安?
线程安全:
指多个线程在执行同一段代码的时候采用加锁机制,使每次的执行结果和单线程执行的结果都是一样的。
线程不平安:
是指不提供加锁机制保护的保护下,有可能出现多个线程先后更改数据造成所得到的数据不一致
如何实现线程平安:
1.对象上锁synchronized(object)
2.方法上锁 synchronized log()
3.Lock
22.Thread和HandlerThread的差异
HandlerThread与Thread都是线程,HandlerThread的解决了Handler在子线程创建的问题
通过HandlerThread完美解决了子线程更新UI等问题。
23.HashMap 底层实现原理是什么?HashMap 和 HashTable 有什么区别
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
HashMap 和 HashTable 有什么区别
HashMap和Hashtable都实现了Map接口。
主要的区别有:线程安全性,同步(synchronization),以及速度。
- HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
- HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
- 由于Hashtable是线程安全的也是synchronized,在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
- HashMap不能保证随着时间的推移Map中的元素次序是不变的。
HashMap同步
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
24.Hash冲突
哈希算法:根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上的算法。也称为散列算法、杂凑算法。
由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,因此总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突。
解决哈希冲突的方法一般有:
1.开放寻址法
2.链地址法(拉链法)
3.再哈希法
4.建立公共溢出区等方法
25.LeakCanary 了解过嘛?如何收集crash的日志?在release环境中为什么不建议使用
参考这边:
Android 性能优化之内存优化与泄漏分析工具LeakCanary_android 内存泄漏工具_蜗牛、Z的博客-CSDN博客
由于LeakCanary自身的监控原因,对设备的性能消耗很大,在debug下面可以协助排查问题,但是在release包下,就非常影响体验。
26.如何监控 UI 卡顿以及优化
UI卡顿最直接的表象是应用操作不流畅,导致这个问题其实很多。
导致卡顿:
1.嵌套过多
2.view过渡绘制
3.内存不足,频繁手动GC
4.线程阻塞
优化工具:
-
检测布局层级工具:Layout Inspector
-
查看系统资源使用情况:systrace
-
帧率监控:Choreographer
-
日志:Looper 机制
27.UI 布局如何优化的?
1、移除不必要的background,避免过度绘制;
2、对于公共使用的布局提取出来,使用 include 进行引入;
3、使用 merge 减少层级嵌套;
4、适当使用 ViewStub 控件;
5、建议使用Android推出的ConstaintLayout布局,可以实现扁平化布局,减少层级。
28.优化
线程的卡顿,block和wait
1.Thread.getAllStackTraces()获取当前所有线程
2.ANR日志
3.Trace:插桩,查看。 Trace.beginSection("");Trace.endSection();
4.引进启动框架:alpha
5.atlas 绕过安全检查
启动优化
1.引入startUp组件,将耗时丢入startUp
2.不需要提前初始化的可以抽到其他地方
3.移除不用的业务
闪屏优化:把预览窗口实现成闪屏的效果
业务梳理:懒加载要防止集中化,非必要的模块可以降低处理机制,新增异步线程
业务优化:算法优化,减少不必要的业务查询,下掉不用的业务
线程优化:减少 CPU 调度带来的波动,让应用的启动时间更加稳定,控制线程数,统一管理线程,线程的回收。引入优秀的启动框架,Pipeline等
GC 优化:
// GC使用的总耗时,单位是毫秒Debug.getRuntimeStat("art.gc.gc-time");
// 阻塞式GC的总耗时Debug.getRuntimeStat("art.gc.blocking-gc-time");
系统调用优化:不要在systemService做初始化,出现资源争夺情况。不然会导致cpu轮转,核心线程无法获取到cpu的时间分配
Dex:dex拆包优化,https://github.com/facebook/redex,
verf 绕开:dalvik_hack-3.0.0.5.jar,
AndroidRuntime runtime = AndroidRuntime.getInstance();
runtime.init(context);
runtime.setVerificationEnabled(false);
29.MVVM 了解过嘛?谈一下用到了思路以及使用了什么
MVC、MVP、MVVM只是一种设计模式。核心是思路,这些模式最终就是进行解耦。MVVM主要涉及到ViewModel、LiveData以及dataBinding的使用。
MVVM是一种软件架构模式,主要View(视图),Model(模型)、ViewModel(视图模型),简称为M-V-VM。
Model:是应用程序的数据源,主要包含了应用的业务逻辑与数据部分
View: 是应用的界面,负责将数据展示或者绑定到UI上,处理输入和输出。
ViewModel:是连接数据与视频的中间层,负责将数据处理成符合视图展示或者将视图中的数据处理成数据源的使用格式。
在MVVM中,Model与View的绑定与更新是通过ViewModel,View或者Model数据更新完,可以通过ViewModel更新各自的宿源。
资料:
Android MVVM之ViewModel的详解与使用_mvvm viewmodel_蜗牛、Z的博客-CSDN博客
Android MVVM模式之LiveData详解与使用_android livedata mvvm_蜗牛、Z的博客-CSDN博客
在MVVM中,ViewModel和LiveData也是一个很好的搭档,需要的可以看以上的文章
30.volatile是什么,如何保证并发的一致性
Java volatile关键字作用是,使系统中所有线程对该关键字修饰的变量共享可见,可以禁止线程的工作内存对volatile修饰的变量进行缓存。
作用:
1.可见性:当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值
2.有序性:在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序
3.原子性:是一个操作是不可再分割的,就像原子一样,可以理解为操作只有一步,一步已经是最小步骤了,自然就不能再分了
volatile不能保证原子性
在多线程下,如果你修饰过的数据应该保持原子性,但是多线下由于线程涉及到cpu以及时间轮片的问题,就存在无法保证了。在for大并发下,volatile的原子性是无法得到保证的。
如何解决:
1.AtomicInteger
2.synchronized
31.了解过jetpack组件嘛?
Jetpack 是一个由多个库组成的套件,可帮助开发者遵循最佳实践、减少样板代码并编写可在各种 Android 版本和设备中一致运行的代码,让开发者可将精力集中于真正重要的编码工作。
1.Room
2.workmanger
3.startup
4.Navigation
5.Paging
6.Lifecycle
7.AndroidX
8.Compose
9.Camer2
32.谈一谈List和LinkList的区别
List和LinkList都是作为数组来用,list的队列数组,linklist的链表数组。
有以下的不同点:
1.List是实现了基于动态数组的数据结构;它可以以O(1)时间复杂度对元素进行随机访问;与此对应,LinkedList基于链表的数据结构存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n);
2.对于随机访问get和set,List觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素;
经常要新增和删除数据,可以考虑linklist,随机访问和遍历数据,list优先
33.内存泄露和内存溢出
内存溢出(out of memory):是指程序在申请内存时,没有足够的内存空间供其使用,出现out of Memory 的错误,比如申请了一个integer,但给它存了long才能存下的数,这就是内存溢出,通俗来讲,内存溢出就是内存不够用。
内存泄漏(Memory Leak):是指程序使用new关键字向系统申请内存后,无法释放已经申请的内存空间,一次内存泄漏可以忽略,但多次内存泄漏堆积后会造成很严重的后果,会占用光内存空间。
以发生的方式来看,内存泄漏可以分为以下几类:
常发性内存泄漏:发生内存泄漏的代码会被执行多次,每次执行都会导致一块内存泄漏;
偶发性内存泄漏:发生内存泄露的代码只有在某些特定的环境或情况下才会发生;
一次性内存泄漏:发生内存泄漏的代码只会被执行一次,或是由于算法上的缺陷,导致总会有一块且仅有一块内存发生泄漏;
隐式内存泄漏:程序在运行过程中不停的分配内存,但是直到程序结束的时候才会释放内存;
常见造成内存泄漏的原因:
单例模式引起的内存泄漏:由于单例的静态特性使得单例的生命周期和程序的生命周期一样长,如果一个对象(如Context)已经不再使用,而单例对象还持有对象的引用就会造成这个对象不能正常回收;
Handler引起的内存泄漏:子线程执行网络任务,使用Handler处理子线程发送的消息,由于Hnadler对象是非静态匿名内部类的实例对象,持有外部类(Activity)的引用,在Handler Message中,Looper线程不断轮询处理消息,当Activity退出时还有未处理或正在处理的消息时,消息队列中的消息持有Handler对象引用,Handler又持有Activity,导致Activity的内存和资源不能及时回收;
线程造成内存泄漏:匿名内部类Runnable和AsyncTask对象执行异步任务,当前Activity隐式引用,当前Activity销毁之前,任务还没有执行完,将导致Activity的内存和资源不能及时回收;
资源对象未关闭造成的内存泄漏:对于使用了BroadcastReceiver、File、Bitmap等资源,应该在Activity销毁之前及时关闭或注销它们,否则这些资源将不会回收,造成内存泄漏;
内存泄漏的检测工具:LeakCanary
LeakCanary是Square公司开源的一个检测内存泄漏的函数库,可以在开发的项目中集成,在Debug版本中监控Activity、Fragment等的内存泄漏,LeakCanaty集成到项目之后,在检测内存泄漏时,会发送消息到系统通知栏,点击后会打开名称DisplayLeakActivity的页面,并显示泄露的跟踪信息,Logcat上面也会有对应的日志输出
34.谈一下包瘦身的思路
包瘦身的目标是减小出包后的文件大小。文件大小是由:资源、代码、附件等组成
删除无用的资源,将大文件资源通过网络进行下载,对资源图片进行压缩,启用代码混淆、无用的代码进行删除,重复的代码进行抽取与公用,布局文件多用style和include。基类的高度集成和封装
35.什么是堆,什么是栈。用来做什么的
堆:是计算机科学中的一种特别的树状数据结构。通常是一个可以被看做一棵树的数组对象。若是满足以下特性,即可称为堆
栈:它是一种运算受限的线性表
作用
堆:堆是存储时的单位,对于绝大多数应用来说,这块区域是 JVM 所管理的内存中最大的一块。线程共享,主要是存放对象实例和数组。
栈:存放了编译期可知的各种基本类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型)和 returnAddress 类型(指向了一条字节码指令的地址)
36.Android中UI的刷新过程
view的刷新,最后是调用自身的invalidate(),invalidata货一直调用parent,parent会一层一层的扫,最终走到decodeView,decodview最终是我们的当前窗口的view,decodeview会走到windowmanager,刷新完以后,再遍历一遍。
自定义一个View的时候,我们会通过invalidate()来刷新UI,实现重绘。比如最简单的view.setVisibility()的调用路径:
------->view.setVisibility()
----------->view.view.setFlags()
-------------->View.requestLayout()
---------------->ViewGroup.requestLayout()
------------------>ViewRootImpl.requestLayout()
37.SurfaceFlinger
双缓冲:
双缓冲就是渲染第一帧的同时已经在绘制第二帧的内容,等到第二帧绘制完毕后就显示出来
38.kotlin的协程
Android kotlin实战之协程suspend详解与使用_android suspend_蜗牛、Z的博客-CSDN博客
39.子线程创建handler
Android Handler的内存抖动以及如何在子线程创建Handler详解_android子线程创建handler_蜗牛、Z的博客-CSDN博客
40.动画了解嘛?三种动画是指:,复杂动画集合*
41.黑白屏优化
黑白屏的问题,一部分是启动冷起动,设备性能低导致。这种问题可以先从启动优化着手坚决问题。
第二,可以通过优化主题,给主动页设置启动动画或者默认背景图等方式
42.HashMap 何时扩容
当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能,扩容是2^-1
43.HTTP 与 HTTPS 有什么区别*
44.HashMap为什么引入红黑树
而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。在jdk1.8版本后,java对HashMap做了改进,在链表长度大于8的时候,将后面的数据存在红黑树中,以加快检索速度
45.内存优化思路
1.按设备分类优化
1.内存过低的
2.资源优化
3.页面优化
4.Bitmap 优化,888->565
5.文件的优化
6.新增异常监控
46.线程池
在说到多线程,往往离不开线程数,线程数到底开多少合适?并不是说线程数越大越好。正常的线程数是和cpu的内核数有关,太多,导致cpu过渡符合,引起卡顿,太少达不到多线程效果,cpu也么有被完全利用,所以线程数多少,往往决定多线程的合理效率。
在java体系中ThreadPoolExecutor为我们提供了一个线程池
1、corePoolSize:
核心线程数。默认情况下线程池是空的,只是任务提交时才会创建线程。如果当前运行的线程数少于corePoolSize,则会创建新线程来处理任务;如果等于或者等于corePoolSize,则不再创建。如果调用线程池的prestartAllcoreThread方法,线程池会提前创建并启动所有的核心线程来等待任务。
2、maximumPoolSize:
线程池允许创建的最大线程数。如果任务队列满了并且线程数小于maximumPoolSize时,则线程池仍然会创建新的线程来处理任务。
3、keepAliveTime:
非核心线程闲置的超时事件。超过这个事件则回收。如果任务很多,并且每个任务的执行时间很短,则可以调大keepAliveTime来提高线程的利用率。另外,如果设置allowCoreThreadTimeOut属性来true时,keepAliveTime也会应用到核心线程上。
4、TimeUnit:
keepAliveTime参数的时间单位。可选的单位有天Days、小时HOURS、分钟MINUTES、秒SECONDS、毫秒MILLISECONDS等。
5、workQueue:
任务队列。如果当前线程数大于corePoolSzie,则将任务添加到此任务队列中。该任务队列是BlockingQueue类型的,即阻塞队列(阻塞队列在另一篇博文中会提到)。
ThreadFactory:线程工厂。可以使用线程工厂给每个创建出来的线程设置名字。一般情况下无须设置该参数。
7、RejectedExecutionHandler:
饱和策略。这是当前任务队列和线程池都满了时所采取的应对策略,默认是AbordPolicy,表示无法处理新任务,并抛出RejectedExecutionException异常。
线程池的种类:
1.newCachedThreadPool创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们
2.newFixedThreadPool创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程
3.newScheduledThreadPool创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行
4.newSingleThreadExecutor:返回一个线程池(这个线程池只有一个线程),这个线程池可以在线程死后(或发生异常时)重新启动一个线程来替代原来的线程继续执行下去!
最大线程数:
如果是CPU密集型应用,则线程池大小设置为N+1
如果是IO密集型应用,则线程池大小设置为2N+1
最小线程数:2(多线程,如果线程是1,那么就是单线程)
47.Activity的五种启动模式
1.singleInstance:单例模式,只允许一个Activity的实例运行。这个Activity会有唯一的task栈只允许它自身在其中运行,每次被加载的时候都被会把这个栈带到前台,同时会调用Activity的onNewIntent方法进行通知。如果这个Activity尝试去启动一个新的Activity,那么新创建的Activity和当前Activity必须是不同的Task栈。。在浏览器开发中比较常见模式
2. standard:标准模式,默认的类型,每次使用时通常创建一个新的活动对象,虽然这样的行为会因为引入其它参数配置而发生改变,比如Intent.FLAG_ACTIVITY_NEW_TASK。
3.singleTask:栈内复用,在启动Activity的时候,如果栈中存在一个这样的Activity,会通过在当前栈中把Activity对象带到前台的方式来替代新创建一个对象。启动的时候那个已存在的实例对象中onNewIntent方法会收到通知,并且会有Intent.FLAG_ACTIVITY_BROUGHT_TO_FRONT的标记。这是singleTop类型的扩展,如果目标Activity就处于栈顶部,则不会有FLAG_ACTIVITY_BROUGHT_TO_FRONT标记
4.singleInstancePerTask:Activity只能作为Task栈的根结点(第一个被创建)运行,因此栈中只可能有一个该Activity的实例。对比singleTask类型,如果设置了FLAG_ACTIVITY_MULTIPLE_TASK标记该Activity可以在不同的栈生成多个不同的实例。
5.singleTop:栈顶模式,在启动Activity的时候,如果前台中存在一个相同Activity类的实例与用户交互,则直接使用这个实例。这个存在的实例在启动的时候会通过onNewIntent方法收到通知。
48.viewpage的懒加载了解过嘛?如何实现
Android Fragment懒加载机制分析与详解_蜗牛、Z的博客-CSDN博客
48.应用安全*
50.recyclerview
recycleview有四级缓存
1.mAttachedScrap(屏幕内),用于屏幕内itemview快速重用,不需要重新createView和bindView
2.mCacheViews(屏幕外),保存最近移出屏幕的ViewHolder,包含数据和position信息,复用时必须是相同位置的ViewHolder才能复用,应用场景在那些需要来回滑动的列表中,当往回滑动时,能直接复用ViewHolder数据,不需要重新bindView。
3.mViewCacheExtension(自定义缓存),不直接使用,需要用户自定义实现,默认不实现。
4.mRecyclerPool(缓存池),当cacheView满了后或者adapter被更换,将cacheView中移出的、ViewHolder放到Pool中,放之前会把ViewHolder数据清除掉,所以复用时需要重新bindView。这个缓存池是一个二维数组 外部是ScrapData 的SparseArray数组,内部是ArrayList数组。
RecyclerView性能优化
1.bindViewHolder方法是在UI线程进行的,此方法不做耗时操作,不然将会影响滑动流畅性。比如进行日期的格式化
2.对于新增或删除的时候,可以进行局部刷新,少用全局刷新
3.对于itemVIew进行布局优化,比如少嵌套等
4.API>21,及以上使用Prefetch 功能,也就是预取功能,嵌套时且使用的是LinearLayoutManager,子RecyclerView可通过setInitialPrefatchItemCount设置预取个数
5.加大RecyclerView缓存,比如cacheview大小默认为2,可以设置大点
6.如果高度固定,可以设置setHasFixedSize(true)来避免requestLayout浪费资源
7.如果多个RecycledView 的 Adapter 是一样,,可以通过设置 RecyclerView.setRecycledViewPool(pool);来共用一个 RecycledViewPool
8.在滑动过程中停止加载的操作
9.用notifyDataSetChange时,适配器不知道整个数据集中的那些内容以及存在,再重新匹配ViewHolder时会花生闪烁。设置adapter.setHasStableIds(true)
10.更新采用局部更新
51.Java中线程安全的基本数据结构有哪些
HashTable: 哈希表的线程安全版、效率低
ConcurrentHashMap:哈希表的线程安全版、效率高、用于替代HashTable
Vector:线程安全版Arraylist
Stack:线程安全版栈
BlockingQueue及其子类:线程安全版队列
52.Collection和Collections有什么区别
1、Collection是一个集合接口、它提供了对集合对象进行基本操作的通用接口方法、所有集合都是它的子类、比如List、Set等
2、Collections是一个包装类、包含了很多静态方法、不能被实例化、而是作为工具类使用、比如提供的排序方法:
Collections.sort(list)、提供的反转方法:Collections.reverse(list)
53.HashMap和Hashtable有什么区别
1、HashMap是Hashtable的轻量级实现、HashMap允许key和value为null、但最多允许一条记录的key为null.而HashTable不允许
2、HashTable中的方法是线程安全的、而HashMap不是、在多线程访问HashMap需要提供额外的同步机制
3、Hashtable使用Enumeration进行遍历、HashMap使用Iterator进行遍历
54.如何决定使用HashMap还是TreeMap
如果对Map进行插入、删除或定位一个元素的操作更频繁、HashMap是更好的选择、如果需要对key集合进行有序的遍历、TreeMap是更好的选择
65.canvas与surface的区别*
55.dns优化*
56.http2.0与1.1的区别*
57.锁的介绍与使用
58.hookt技术有了解嘛?谈一谈反射和劫持
Android Java反射与Proxy动态代理详解与使用基础篇(一)_androidjavaproxy_蜗牛、Z的博客-CSDN博客
59.自动化打包接触过嘛?jenkins*
60.谈谈Android系统的内存管理
物理内存即移动设备上的ram,当启动一个android程序时,会启动一个dalvik vm进程,系统会给它分配固定的内存空间,这块内存空间会映射到ram上某个区域。然后这个android程序就会运行在这块空间上。java里会将这块空间分成stack栈内存和heap堆内存。栈里存放对象的引用,堆里存放实际对象数据。
在程序运行中会创建对象,如果未合理管理内存,比如不及时回收无效空间就会造成内存泄露,严重的话可能导致使用内存超过系统分配内存,即内存溢出oom,导致程序卡顿甚至直接退出。
61SystemUI的流程
SystemUI 是一个 persistent 应用,它由操作系统启动,主要流程为:
1.Android 系统在开机后会创建 SystemServer 进程,它会启动各种系统所需要的服务,其中就包括 SystemUIService。
2.SystemUIService 启动后进入到应用层 SystemUI 中,在 SystemUIApplication 它首先会初始化监听boot completed 等通知,待系统完成启动后会通知各个组件 onBootCompleted。
3.在进入 SystemUIService 中依然执行的 SystemUIApplication 中的startServicesIfNeeded() 无参方法启动所有 SystemUI 中的组件。
4.最终的服务启动逻辑都是在 SystemUIApplication 里面,并且都保存在 mServices 数组中。
62.下JVM的了解,内存模型,可达性分析,引用计数法,四种引用
内存模型:
JVM内存模型可以分为两个部分,如下图所示,堆和方法区是所有线程共有的,而虚拟机栈,本地方法栈和程序计数器则是线程私有的。
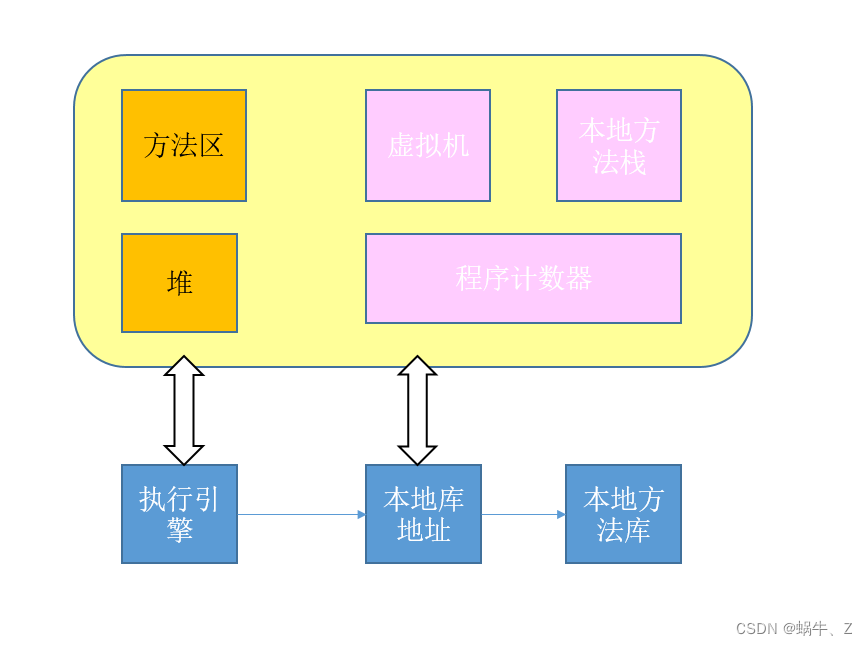
堆(Heap):堆是java虚拟机所管理的内存中最大的一块内存区域,也是被各个线程共享的内存区域,该内存区域存放了对象实例及数组
方法区(Method Area):它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
栈(Stack): 是用于虚拟机执行时方法调用和方法执行时的数据结构,它是虚拟栈的基本元素,栈帧由局部变量区、操作数栈等组成
本地方法栈(Native Stack):本地方法栈则是为虚拟机使用到的Native 方法服务
程序计数器(PC Register):记录的是正在执行的JVM字节码指令的地址;如果正在执行的是一个Natvie(本地方法),那么这个计数器的值则为空(Underfined)
垃圾回收算法:
- 标记-清除算法:
标记-清除算法分为“标记”和“清除”两个阶段,首先通过可达性分析,标记出所有需要回收的对象,然后统一回收所有被标记的对象。
标记-清除算法有两个缺陷,一个是效率问题,标记和清除的过程效率都不高,另外一个就是,清除结束后会造成大量的碎片空间。有可能会造成在申请大块内存的时候因为没有足够的连续空间导致再次 GC - 复制算法
将内存分成两块,每次申请内存时都使用其中的一块,当内存不够时,将这一块内存中所有存活的复制到另一块上。然后将然后再把已使用的内存整个清理掉。
复制算法解决了空间碎片的问题。但是也带来了新的问题。因为每次在申请内存时,都只能使用一半的内存空间。内存利用率严重不足。
- 标记-整理算法
标记-整理算法的“标记”过程与“标记-清除算法”的标记过程一致,但标记之后不会直接清理。而是将所有存活对象都移动到内存的一端。移动结束后直接清理掉剩余部分
- 分代收集算法
分代收集是将内存划分成了新生代和老年代。分配的依据是对象的生存周期,或者说经历过的 GC 次数。对象创建时,一般在新生代申请内存,当经历一次 GC 之后如果对还存活,那么对象的年龄 +1。当年龄超过一定值,如果对象还存活,那么该对象会进入老年代
63.apk加固原理,加壳脱壳
目前常见的是对dex进程加密,在启动的时候,通过解密工具进行还原到正常的。
还有一种对包整体加,然后通过classLoader进行还原。
64.pid与uid的区别
pid是进程ID,PID是进程的身份标志,系统给每个应用分配独一无二的PID(一个应用可能有多个进程,每个进程有唯一的PID)
进程终止后PID会被系统回收,再次打开应用会重新分配一个PID。
UID在linux中是用户的ID,用于权限的管理。在android中,由于android是单用户系统,所以uid被用于实现数据共享。
65.Java中==和equals的区别?
==:判断是内存地址
equals:比较的是字符串
66.ThreadLocal作用是什么,用在什么场景?
ThreadLocal是一个线程内部的数据存储类,通过它可以在指定的线程中存储数据,数据存储以后,只能在指定的线程中获取存储的数据,对于其他线程来说则是无法获取到的
用在什么场景:
一、某些数据是以线程为作用域并且不同线程具有不同的数据副本。比如 Handler,它需要获取当前线程的Looper,Looper的作用域就是线程并且不同线程对应不同的Looper,此时可以通过ThreadLocal实现Looper在线程中的存取。
二、复杂逻辑下的对象传递。比如监听器的传递,采用ThreadLocal可以让监听器作为线程内的全局对象存在,在线程内部可以通过get方法获取到监听器。
67.Android源码中你认为有哪些方面设计的很优秀的地方
看过Android体系图的我们了解,android从架构设置来看,是层层剥离,针对涉及安全问题的,并没有暴露出所有,而是通过中间层进行转发。这样做的好处是即保证了整个系统的安全,也扩展了其他层对系统的依赖。
68.GC分代回收介绍*
69.http弱网优化
什么叫弱网?
目前针对弱网没有明确说法,最直接的理解就是网络不稳定,受外界干扰与影响,比如信号不好,wifi距离远或者墙体遮挡等。这种现象最直接的表现就是丢包或者网络延迟。
弱网状态下的优化
1 使用QUIC进行弱网优化
QUIC是一种udp协议,由google发明,实现了TCP+TLS+HTTP/2,它还有一个更加响亮的名称: Http/3,Cronet库对其进行了支持。
在弱网下切到QUIC库,正常使用常规网络库
2 复合连接
复合连接,即多条连接。它解决的场景是为了多个IP地址的连接选取问题
3 其他
减少资源传送,重连,合并资源请求,使用缓存兜底,在加载过程中给出动画提示。
70.序列parcelable,serializable区别
两者都是序列化,serializable是Java自带的序列化,parcelable是Android特有的,parcelable的好处是会对数据按顺序进行序列化
paracleable的数据传递效率更高,Parcelable是通过IBinder通信的消息的载体,Serializable序列化实际上是用到了反射技术,反射会产生大量的临时对象,进而引起频繁的GC。
serializable的序列化不受变量位置影响,是把整个对象序列化。parcelable是可以对部分进行序列化,读写的顺序要一直,否则在反序列化会出错。
71.View和Surfaceview 的区别
一是,如果屏幕刷新频繁,onDraw方法会被频繁的调用,onDraw方法执行的时间过长,会导致掉帧,出现页面卡顿。而SurfaceView采用了双缓冲技术,提高了绘制的速度,可以缓解这一现象。
二是,view的onDraw方法是运行在主线程中的,会轻微阻塞主线程,对于需要频繁刷新页面的场景,而且onDraw方法中执行的操作比较耗时,会导致主线程阻塞,用户事件的响应受到影响,也就是响应速度下降,影响了用户的体验。而SurfaceView可以在自线程中更新UI,不会阻塞主线程,提高了响应速度。
72.是否可以在子线程更新UI?
可以,在onResume之前,可以在子线程刷新,因为在View的创建中,WindowManager检查view更新的时候会回调onResume,在之前虽然view展示了,但是只是创建,并且view是无法获取到宽与高,即使你在onResume之前创建了view,并且在子线程更新ui,这个时候view暂时不受windowmanagerService的控制。
73.屏幕旋转时的Activity生命周期
- 不设置Activity的android:configChanges时,切屏会重新调用各个生命周期,切横屏时会执行一次,切竖屏时会执行两次;
- 设置Activity的android:configChanges="orientation"时,切屏还是会重新调用各个生命周期,切横、竖屏时只会执行一次;
- 设置Activity的android:configChanges="orientation|keyboardHidden"时,切屏不会重新调用各个生命周期,只会执行onConfigurationChanged方法。
74.onNewIntent的调用时机
当launchMode为singleTask的时候,如果创建的Activity已经处于栈中时,此时不会创建新的Activity,而是将存在栈中的Activity上面的其他Activity所有销毁,使它成为栈顶,这时会调用onNewIntent方法
当ActivityA已经启动过,处于当前应用的Activity堆栈中;当ActivityA的LaunchMode为SingleTop时,如果ActivityA在栈顶,且现在要再启动ActivityA,这时会调用onNewIntent方法
当ActivityA的LaunchMode为SingleInstance,SingleTask时,如果已经ActivityA已经在堆栈中,那么此时会调用onNewIntent方法
当ActivityA的LaunchMode为Standard时,由于每次启动ActivityA都是启动新的实例,和原来启动的没关系,所以不会调用原来ActivityA的onNewIntent方法,仍然调用的是onCreate方法
75.本地广播和全局广播有什么差别
BroadcastReceiver是针对应用间、应用与系统间、应用内部进行通信的一种方式
LocalBroadcastReceiver仅在自己的应用内发送接收广播,也就是只有自己的应用能收到,数据更加安全广播只在这个程序里,而且效率更高。
BroadcastReceiver 使用
1.制作intent(可以携带参数)
2.使用sendBroadcast()传入intent;
3.制作广播接收器类继承BroadcastReceiver重写onReceive方法(或者可以匿名内部类啥的)
4.在java中(动态注册)或者直接在Manifest中注册广播接收器(静态注册)使用registerReceiver()传入接收器和intentFilter
5.取消注册可以在OnDestroy()函数中,unregisterReceiver()传入接收器
LocalBroadcastReceiver 使用
LocalBroadcastReceiver不能静态注册,只能采用动态注册的方式。
在发送和注册的时候采用,LocalBroadcastManager的sendBroadcast方法和registerReceiver方法
76.View的绘制流程
View的绘制流程:OnMeasure()——>OnLayout()——>OnDraw()
各步骤的主要工作:
OnMeasure():
测量视图大小。从顶层父View到子View递归调用measure方法,measure方法又回调OnMeasure。
OnLayout():
确定View位置,进行页面布局。从顶层父View向子View的递归调用view.layout方法的过程,即父View根据上一步measure子View所得到的布局大小和布局参数,将子View放在合适的位置上。
OnDraw():
绘制视图:ViewRoot创建一个Canvas对象,然后调用OnDraw()。六个步骤:①、绘制视图的背景;②、保存画布的图层(Layer);③、绘制View的内容;④、绘制View子视图,如果没有就不用;⑤、还原图层(Layer);⑥、绘制滚动条。
77.Android中三种动画,特点和区别是什么
Android 中的动画有帧动画,补间动画,属性动画。
- 帧动画:一张张图片不断的切换,形成动画效果,类似小时候的电影。很多应用的loading是采用这种方式。
- 补间动画:对某个View进行一系列的动画的操作,如淡入淡出(Alpha),缩放(Scale),平移(Translate),旋转(Rotate)等四种模式
- 属性动画:
作用对象进行了扩展:不只是View对象,甚至没对象也可以,不再局限于 视图View对象
实现的动画效果:可自定义各种动画效果,不再局限于4种基本变换:平移、旋转、缩放 & 透明度
78.缓存机制LruCache和DiskLruCache
LruCache
标识最近至少缓存机制,他的内部实现是通过LinkHashMap来完成,创建的扩容因子为0.75,他的使用规则是最近至少使用,所有在存储的时候采用了链式存储,当前新增的添加在链的尾部,不用的从头部删除。主要存储在内存中
DiskLruCache
依赖库:implementation 'com.jakewharton:disklrucache:2.0.2'
持久最少使用缓存机制。是用来存储在设备硬件里的,存储本地磁盘文件中。
创建对象:
DiskLruCache.open(null,1,10,1000);
File directory:存储文件 int appVersion:版本号 int valueCount:存储文件多少行(String valueCountString = reader.readLine();) long maxSize:存储对象的最大size,如果大于这个对象,讲采用线程池来完成
这个也是通过edit来提交缓存的对象。
待续*******************************



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









