









本节知识点:
1.
栈的知识(我觉得栈是本节很头疼的一个问题):
对于栈的问题,首先我们通过几个不同的角度来看(因为思维有些小乱所以我们通过分总的形式进行阐述):
a.sp堆栈指针,相信学过51单片机,学过arm裸机的人都知道这个堆栈指针。我们现在从51单片机的角度来看这个堆栈指针寄存器。这个堆栈指针的目的是什么?是用来
保护现场(子函数的调用)和保护断点(中断的处理)的,所以在处理中断前,调用子函数前,都应该把现场和返回地址压入栈中。而且
堆栈还会用于一些临时数据的存放。51中的sp指针再单片机复位的时候初值为0x07。
常常我们会把这个sp指针指向0x30处,因为
0x30~0x7f是用户RAM区(专门为堆栈准备的存储区)。然后要引入一个
栈顶和
栈底的概念。
栈操作的一段叫栈顶(这里是sp指针移动的那个位置,sp也叫栈顶指针),
sp指针被赋初值的那个地址叫栈底(这里是0x30是栈底,因为栈顶永远会只在0x30栈底的一侧进行移动,不会在两层移动)。而且51单片机的sp是向上增长的,叫
做向上增长型堆栈(栈顶指针sp向高地址处进行增长)。因为PUSH压栈操作,是sp指针先加1(指向的地址就增大一个),再压入一个字节,POP弹出操作,先弹出一个字节,sp再减1(指向的地址就减少一个)。看PUSH和POP的过程,可见是一个
满堆栈(满堆栈的介绍在后面)。小结一下:
51的堆栈是一个向上增长型的满堆栈。
b.对于arm来说,大量的分析过程都与上面相同。只是堆栈不再仅仅局限于处理中断了,而是处理异常。
arm的堆栈有四种增长方式(具体见d)。
注意:在arm写裸机的时候,那个ldr sp, =8*1024 其实是在初始化栈底。sp是栈顶指针,当没有使用堆栈的时候,栈顶指针是指向栈底的。当数据来的时候,每次都是从栈顶进入的(因为栈的操作入口在栈顶),然后sp栈顶指针指向栈顶,慢慢远离栈底。说这些是想好好理解下什么是栈顶,什么是栈底。
c.对于8086来说,它的栈的生长方向也是从高地址到低地址,每次栈操作都是以字(两个字节)为单位的。压栈的时候,sp先减2,出栈的时候,sp再加2。可见
8086的堆栈是一个向下增长型的满堆栈。
d.总结下:
(1).当堆栈指针sp指向,最后一个压入堆栈的数据的时候,叫满堆栈。
(2).当堆栈指针sp指向,下一个要放入数据的空位置的时候,叫空堆栈。如下图:
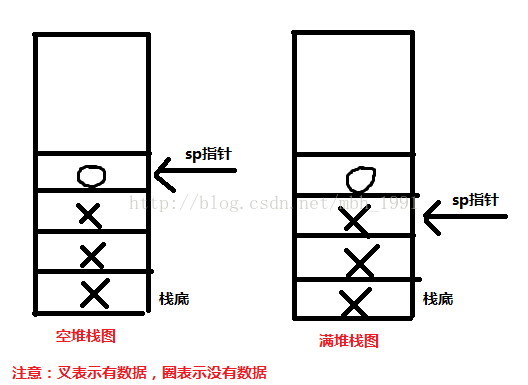
(3).当堆栈由低地址向高地址生长的时候,叫向上生长型堆栈即递增堆栈。
(4).当堆栈由高地址向低地址生长的时候,叫向下生长型堆栈即递减堆栈。如图:
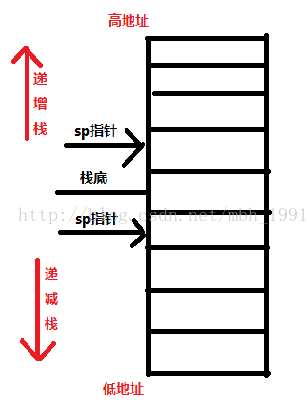
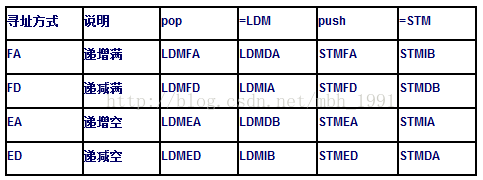
(5). 所以说arm堆栈支持四种增长方式:满递减栈(
常用的ARM,Thumb c/c++编译器都使用这个方式,也就是说如果你的程序中不是纯汇编写的,有c语言就得使用这种堆栈形式)、满递增栈、空递减栈、空递增栈。这四种方式分别有各自的压栈指令,出栈指针,如下图:
e.对于裸机驱动程序(51、ARM)没有操作系统的,编译器(keil、arm-linux-gcc等),会给sp指针寄存器一个地址。然后一切的函数调用,中断处理,这些需要的现场保护啊,数据啊都压入这个sp指向的栈空间。(arm的.s文件是自己写的,sp是自己指定的,编译器会根据这个sp寄存器的值进行压栈和出栈,但是压栈和出栈的规则是满递减栈的规则,因为arm-linux-gcc是这个方式的,所以在汇编调用c函数的时候,汇编代码必须使用满递减栈的那套压栈出栈指令)。这种没有操作系统的裸机驱动程序,只有一个栈空间,就是sp指针指向的那个栈空间。
f.对于在操作系统上面的程序,里面涉及内存管理、虚拟内存、编译原理的问题。首先说不管是linux还是windows的进程的内存空间都是独立的,linux是前3G,windows是4G,这都是虚拟内存的功劳。那编译器给程序分配的栈空间,在程序运行时也是独立的。每一个进程中的栈空间,应该都是在使用sp指针(但是在进程切换的过程中,sp指针是怎么切换的我就不清楚了,这个应该去看看操作系统原理类的书)Ps:对于x86的32位机来说不再是sp和bp指针了,而是esp和ebp两个指针。有人说程序中的栈是怎么生长的,是由编译器决定的,有人说是由操作系统决定的!!!
我觉得都不对,应该是由硬件决定的,因为cpu已经决定了sp指针的压栈出栈方式。只要你操作系统在进程运行的过程中,使用的这个栈是sp栈指针指向的(即使用了sp指针),而不是自己定义的一块内存(与sp指针无关的话) Ps:实际中进程使用的是esp和ebp两个指针,这里仅仅用sp是想说明那个意思而已! 操作系统使用的栈空间就必须符合sp指针的压栈和出栈方式,也就是遵循了cpu决定的栈的生长方式。编译器要想编译出能在这个操作系统平台上使用的程序,也必须要遵守这个规则,所以来看这个栈的生长方式是由cpu决定的。这也是为什么我用那么长的篇幅来解释sp指针是怎么工作的原因!
g.要记住,由于操作系统有虚拟内存这个东东,所以不要再纠结编译器分配的空间在操作系统中,进程执行的时候空间是怎么用的了。编译器分配的是什么地址,进程中使用这个变量的虚拟地址就是什么!是对应的。当然有的时候,
编译器也会耍些小聪明。不同编译器对栈空间上的变量分配的地址可能不一样,但方向一定是一样的(
因为这个方向是cpu决定,编译器是无权决定的,是sp指针压栈的方向),如图:
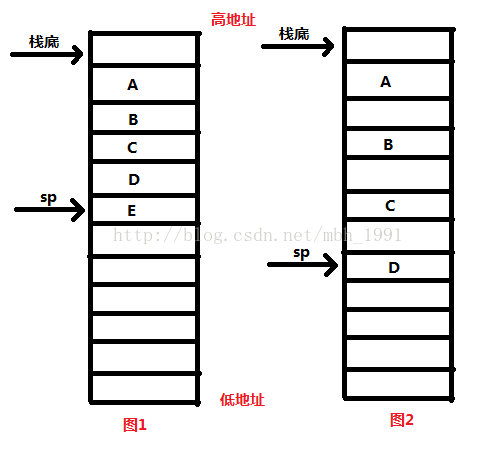
图1和图2的共同点是:都是从高地址处到低地址处,因为sp指针把A、B、C变量压入栈的方向就是从高到低地址的。这个是什么编译器都不会变的。
图1和图2的不同点是:图2进行了编译器的小聪明,它在给A,B,C开辟空间的时候,不是连续开辟的空间,有空闲(其实依然进行了压栈操作只是压入的是0或者是ff),这样变量直接有间隙就避免了,数组越界,内存越界造成的问题。
切记在获取A、B、C变量的时候,不是通过sp指针,而是通过变量的地址获得的啊,sp只负责把他们压入栈中,即给他们分配内存。
h.说了那么多栈的原理,现在我们说说栈在函数中究竟起到什么作用:
保存活动记录!!!如图:
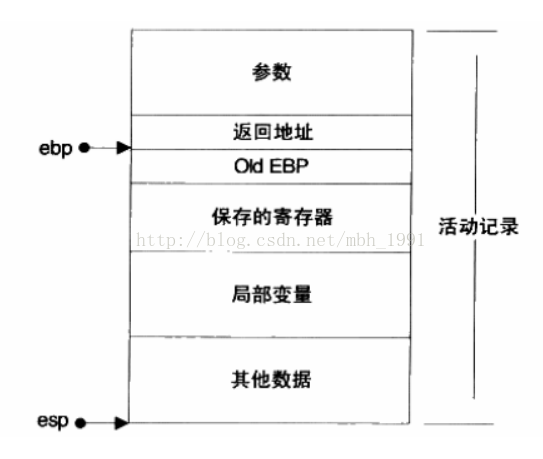
注意:活动记录是什么上面的这个图已经说的很清楚了,如果再调用函数,这个活动记录会变成什么样呢?
会在这个活动记录后面继续添加活动记录(这个活动记录是子函数的活动记录),增加栈空间,当子函数结束后,子函数的活动记录清除,栈空间继续回到上图状态!
Ps:活动记录如下:

i.
函数的调用行为:
函数的调用行为中有一个很重要的东西,叫做调用约定。调用约定包含两个约定。
第一个是:参数的传递顺序(这个不是固定的,是在编译器中约定好的),从左到右依次入栈:__stdcall、__cdecl、__thiscall (这些指令,直接写在函数名的前面就可以,但是跟编译器有点关系,可能会有的编译器不支持会报错)
从右到左依次入栈:__pascal、__fastcall
第二个是:堆栈的清理(这段代码也是编译器自己添加上的):调用者清理
被调用者函数返回后清理
注意:一般我们都在同一个编译器下编译不会出这个问题。 但是如果是调用动态链接库,恰巧编译动态链接库的编译器跟你的编译器的默认约定不一样,那就惨了!!!或者说如果动态链接库的编写语言跟你的语言都不一样呢?
j.这里要声明一个问题:就是栈的增长方向是固定的,是cpu决定的。
但是不代表说你定义的局部变量也一定是先定义的在高地址,后定义的在低地址,局部变量之间都是连续的(这个在上面已经说过了是编译器决定的),还有就是栈的增长方向也决定不了参数的传递顺序(这个是调用约定,通过编译器的手处理的)。下面让我们探索下再dev c++中,局部变量的地址问题。
#include <stdio.h>
void fun()
{
int a;
int b;
int c;
printf("funa %p\n",&a);
printf("funb %p\n",&b);
printf("func %p\n",&c);
}
void main()
{
int a;
int b;
int c;
int d;
int e;
int f;
int p[100];
printf("a %p\n",&a);
printf("b %p\n",&b);
printf("c %p\n",&c);
printf("d %p\n",&d);
printf("e %p\n",&e);
printf("f %p\n",&f);
printf("p0 %p\n",&p[0]);
printf("p1 %p\n",&p[1]);
printf("p2 %p\n",&p[2]);
printf("p3 %p\n",&p[3]);
printf("p4 %p\n",&p[4]);
printf("p10 %p\n",&p[10]);
printf("p20 %p\n",&p[20]);
printf("p30 %p\n",&p[30]);
printf("p80 %p\n",&p[80]);
printf("p90 %p\n",&p[90]);
printf("p100 %p\n",&p[100]);
fun();
}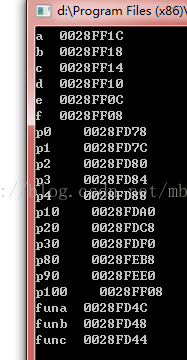
通过上面的运行结果,可以分析得出:在同一个函数中, 先定义的变量在高地址处,后定义的变量在低地址处,且他们的地址是相连的中间没有空隙。 定义的数组是下标大的在高地址处,下标小的在低地址处(由此可以推断出malloc开辟出的推空间,也应该是下标大的在高地址处,下标小的在低地址处)。 子函数中的变量,跟父函数中的变量的地址之间有很大的一块空间,这块空间应该是两个函数的其他活动记录,且父函数中变量在高地址处,子函数中的变量在低地址处。
k.下面来一个栈空间数组越界的问题,让大家理解一下,越界的危害,代码如下(猜猜输出结构):
#include<stdio.h>
/*这是一个死循环*/
/*这里面有数组越界的问题*/
/*有栈空间分配的问题*/
int main()
{
int i;
// int c;
int a[5];
int c;
printf("i %p,a[5] %p\n",&i,&a[5]); //观察栈空间是怎么分配的 这跟编译器有关系的
printf("c %p,a[0] %p\n",&c,&a[0]);
for(i=0;i<=5;i++)
{
a[i]=-i;
printf("%d,%d",a[i],i);
}
return 1;
}
注意:不同编译器可能结果不一样,比如说vs2008就不会死循环,那是因为vs2008耍了我上面说的那个小聪明(就是局部变量和数组直接有间隙不是相连的,就避开了越界问题,但是如果越界多了也不行),建议在vc6和dev c++中编译看结果。
l.最后说说数据结构中的栈,其实数据结构中的栈就是一个线性表,且这个线性表只有一个入口和出口叫做栈顶,还是LIFO(后进先出的)结构而已。
l.最后说说数据结构中的栈,其实数据结构中的栈就是一个线性表,且这个线性表只有一个入口和出口叫做栈顶,还是LIFO(后进先出的)结构而已。
对栈的总结:之前就说过了那么多种栈的细节,现在在宏观的角度来看,其实栈就是一种线性的后进先出的结构,只是不同场合用处不同而已!
2.堆空间:堆空间弥补了栈空间在函数返回后,内存就不能使用的缺陷。是需要程序员自行跟操作系统申请的。
3.静态存储区:
程序在编译期,静态存储区的大小就确定了
4.对于程序中的内存分布:请看这篇文章
<c语言中的内存布局>
5.对于内存对齐的问题:请看这篇文章
<C语言深度解剖读书笔记(3.结构体中内存对齐问题)>
6.使用内存的好习惯:
a.定义指针变量的时候,最好是初始化为NULL,用完指针后,最好也赋值为NULL。
b.在函数中使用指针尽可能的,去检测指针的有效性
c.malloc分配的时候,注意判断是否分配内存成功。
d.malloc后记得free,防止内存泄漏!
e.free(p)后应该p=NULL
f.不要进行多次free
g.不要使用free后的指针
h.牢记数组的长度,防止数组越界
7.内存常见的六个问题:
a.野指针问题 :一个指针没有指向一个合法的地址
b.为指针分配的内存太小
c.内存分配成功,但忘记初始化,memset的妙用
e.内存越界
f.内存泄漏
g.内存已经被释放 还仍然在使用(栈返回值问题)















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









